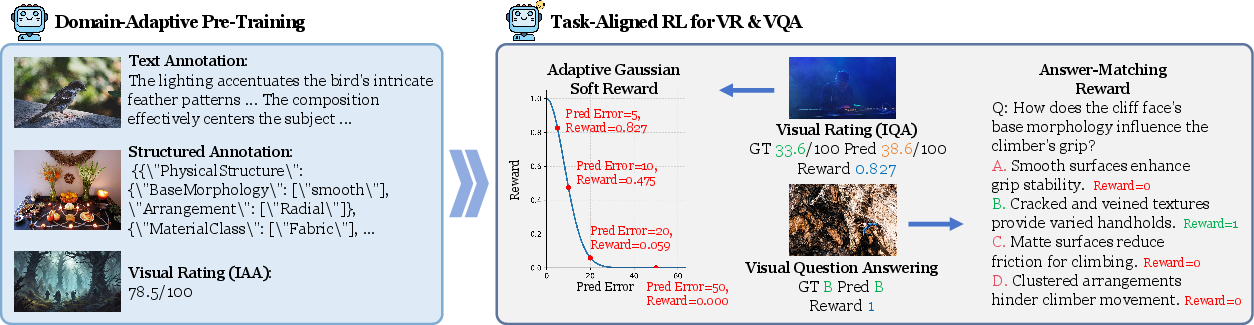
- The paper introduces a unified perceptual framework that fuses image aesthetics, quality, and structure/texture assessments.
- It employs Domain-Adaptive Pre-Training and a task-aligned reinforcement learning strategy to optimize prediction accuracy in both Visual Rating and VQA formats.
- Empirical results demonstrate significant performance gains over state-of-the-art baselines, validating the benchmark’s robustness and practical utility.
UniPercept: Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture
Motivation and Context
Current multimodal LLMs (MLLMs) excel at semantic-level vision-language tasks (e.g., captioning, segmentation, object recognition) by leveraging strong semantic alignment and scene understanding. However, these models consistently underperform on perceptual-level tasks that require fine-grained, human-aligned assessments of how an image actually looks—covering aspects such as aesthetics, fidelity, structure, and texture. These judgments are nontrivial, inherently subjective or subtle, and play a critical role in downstream applications including content creation, subjective evaluation, image enhancement, and controllable generative modeling.
While advanced benchmarks exist for individual perceptual domains—such as aesthetics (IAA), quality (IQA), or partial texture/structure—the field lacks a unified framework encompassing all three perceptual axes. This missing layer significantly hinders model development and diagnostic precision for perceptual-level reasoning in MLLMs.
UniPercept-Bench: A Unified Perceptual Benchmark
UniPercept-Bench is introduced as a comprehensive hierarchical benchmark targeting all three core domains: Image Aesthetics Assessment (IAA), Image Quality Assessment (IQA), and Image Structure and Texture Assessment (ISTA). Each domain is specified by a Domain–Category–Criterion hierarchy, enabling precise, fine-grained, and human-aligned definition of perceptual concepts.
Two task formats underpin the evaluation:
- Visual Rating (VR): Models predict continuous, high-precision scores reflecting human perception for aesthetics, quality, and structure/texture richness.
- Visual Question Answering (VQA): Question-Answer pairs, stratified by the hierarchical taxonomy, require both quantitative reasoning and explanatory consistency within the perceptual domain.
The construction pipeline employs initial QA generation (using MLLMs templated with expert/structured annotations), reject-sampling via a strong judger model, and substantial human refinement.

Figure 1: The taxonomy and QA example design, capturing diverse perceptual-level reasoning.
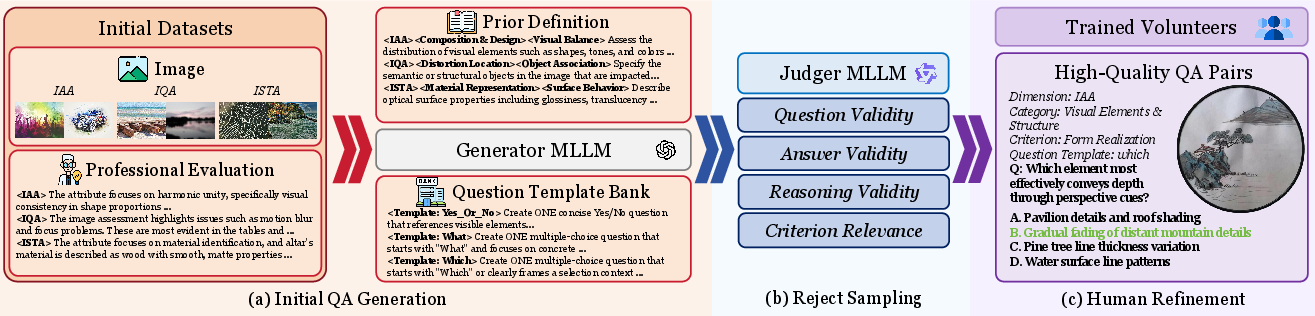
Figure 2: The structured pipeline for QA creation ensures high validity and perceptual alignment.
The resulting dataset outstrips prior benchmarks in both coverage and annotation quality, providing tasks that are substantially more granular and challenging—especially in the underexplored ISTA domain.
UniPercept: Model Architecture and Training
Built atop InternVL3-8B, UniPercept incorporates a two-stage process:
Ablation studies confirm that both Domain-Adaptive Pre-Training and the soft reward formulation are essential; removing either leads to marked drops in both rating precision and question-answering accuracy. Moreover, multi-task (VR+VQA) and multi-domain (IAA+IQA+ISTA) training regimes yield significant mutual reinforcement, improving generalization and robustness beyond their individual components.
Empirical Results
Evaluation on UniPercept-Bench and cross-benchmarks indicates that UniPercept achieves state-of-the-art results compared with both proprietary giants (GPT-4o, Llama-4-Scout, Gemini-2.5-Pro) and specialized open-source models. Strong numerical outcomes include:
- Visual Rating (VR): UniPercept attains (SRCC+PLCC)/2 scores of 0.590/0.586 (IAA), 0.824/0.827 (IQA), and 0.778/0.767 (ISTA), universally outperforming all baselines.
- VQA: Accuracies reach 76.6% (IAA), 81.1% (IQA), and 84.2% (ISTA), all substantially higher than previous bests.
Performance analysis demonstrates that while IQA is typically easiest (being more objective), IAA remains highly challenging due to subjectivity, and ISTA (with objective, physically grounded cues) is the best aligned to vision-language pretraining—the main limitation for generalist models is reasoning over local, fine-grained structure.
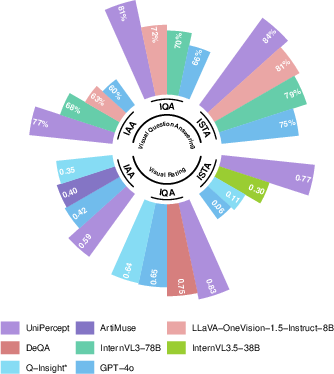
Figure 4: Radar plot visualizing UniPercept's superlative performance across VR and VQA in all perceptual domains.
Applications and Impact
Reward Modeling for Generative Alignment
UniPercept is directly deployable as a plug-and-play reward function for RL-based post-training of text-to-image models. Explicit optimization for IAA/IQA/ISTA via UniPercept signals leads to targeted perceptual improvements (aesthetics, clarity, richness) in the generated outputs. Combining all reward branches yields optimal holistic perceptual gains.

Figure 5: FLUX.1-dev post-training with UniPercept reward. Each reward axis guides the model towards distinct visual attributes; the combined signal achieves maximal improvement.
Evaluation and Dataset Analysis
Beyond RL, UniPercept offers unified perceptual metrics enabling direct comparative scoring of generative models or datasets. Analysis reveals the large performance gap in ISTA and IAA for current T2I baselines, while the best commercial and advanced open-source models converge on strong IQA but are still limited in aesthetics and structure. These metrics facilitate diagnostic understanding of both image models and datasets with respect to human perceptual factors.

Figure 6: Visualization of the independence among perceptual domains; high quality does not necessarily imply strong aesthetics or texture.
Image Profiling
UniPercept can generate detailed multi-dimensional profiles for arbitrary images, supporting applications in content selection, curation, or automated perceptual tagging.
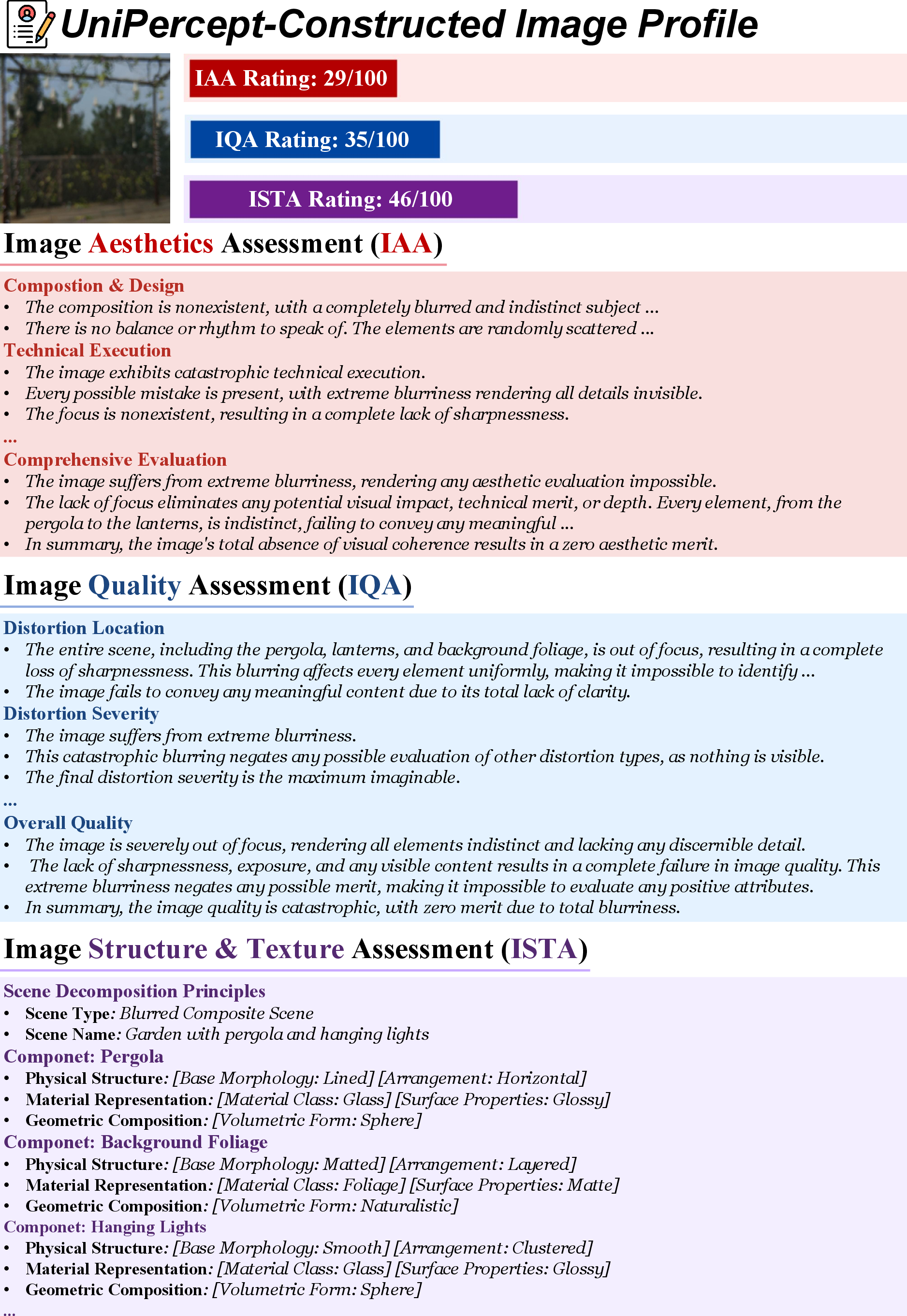
Figure 7: Example of a UniPercept-constructed image profile, providing explicit quantified judgments across all dimensions.
Theoretical and Practical Implications
The unified perceptual-level paradigm reframes image understanding away from purely semantic or categorical axes and toward a closer alignment with human assessment. It exposes fundamental gaps in current models: high performance on semantics does not equate to perceptual fidelity or appeal. The demonstrated generalization from multi-domain, multi-task training also points toward architectures that more effectively bridge low-level and high-level vision-language representations.
Practical advances include robust perceptual evaluation schemes for generative models, credible reward schemes enabling controllable and interpretable model improvement, and emergent capacity for automated dataset diagnosis at the perceptual level. These tools catalyze new research toward controllable and human-centric visual AI.
Conclusion
This work establishes a unified foundation for perceptual-level image understanding. UniPercept-Bench systematizes benchmarks for aesthetics, technical quality, and structure/texture—enabling holistic evaluation and training. UniPercept itself stands as an effective multi-domain, multi-task baseline, delivering strong cross-domain generalization, robust reward modeling, and practical diagnostic capabilities. These advances collectively lay groundwork for the next generation of perceptually-grounded multimodal models and practical applications.
Reference: "UniPercept: Towards Unified Perceptual-Level Image Understanding across Aesthetics, Quality, Structure, and Texture" (2512.21675)