- The paper introduces an efficient VLN architecture using progressive and recursive memory to significantly reduce token overhead and training compute.
- It enhances navigation by fusing 3D geometric context into 2D visual features and employing a dynamic DAgger policy to cut exploration overhead.
- Empirical results demonstrate state-of-the-art success rates on R2R-CE and RxR-CE benchmarks with markedly lower compute requirements compared to previous models.
Efficient-VLN: A Training-Efficient Vision-Language Navigation Model
Introduction
Efficient-VLN proposes a highly efficient architecture for Vision-Language Navigation (VLN) using Multimodal LLMs (MLLMs). The motivation originates from the impractical computational demands imposed by existing MLLM-based VLN methods, especially in processing long-horizon historical observations and the inefficiency of standard DAgger-based data aggregation. Efficient-VLN addresses two main sources of overhead: (1) the quadratic complexity of encoding long token sequences and (2) extensive exploration steps required to gather error-recovery data via DAgger. The architecture incorporates novel memory representations and an adaptive exploration policy, resulting in a substantial reduction of resource requirements while achieving state-of-the-art navigation accuracy.
Efficient-VLN demonstrates strong empirical results, with a reported 64.2% success rate (SR) on the R2R-CE benchmark and 67.0% SR on RxR-CE using only RGB inputs and 282 H800 GPU hours—a fraction of the compute used by other SOTA models.
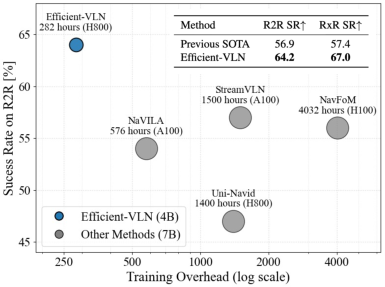
Figure 1: Efficient-VLN outperforms prior methods on success rate and compute cost, with results visualized by success rate vs. GPU hours and model size.
Efficient Memory Representations
A key architectural contribution is the introduction of two efficient memory schemes, both designed to reduce token overhead for long navigation trajectories.
Progressive Memory Representation: This paradigm encodes the intuition that recent observations deserve higher fidelity than distant ones. The system applies spatial compression to historical observations, allocating more tokens for recent frames and fewer for temporally distant frames, akin to variable-resolution history summarization. This compression strategy ensures a strict bound on the number of memory tokens, dramatically lowering sequence length without significant loss in task performance, especially for long-horizon tasks like RxR-CE.
Recursive Memory Representation: Inspired by recursive state updating, this variant maintains a fixed-size set of learnable tokens, with a dynamic update rule operating on the KV cache of the transformer backbone. Rather than concatenating the full history, recursive memory tokens are updated at every step by integrating new observations and previous memory states. This approach significantly curbs both memory and compute, but empirical analysis reveals that progressive memory is preferable for very long trajectories, whereas recursive memory suffices for shorter paths.
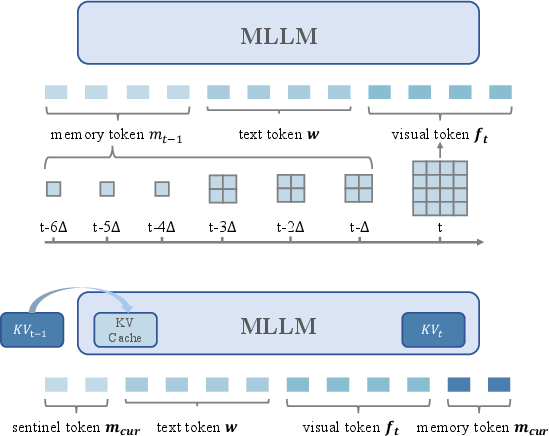
Figure 2: (Top) Progressive memory dynamically compresses observations by recency; (Bottom) Recursive memory uses a KV cache to propagate memory state across timesteps.
Comprehensive ablation confirms the superiority of progressive compression for long-horizon navigation, especially as the number of preserved historical frames (with higher fidelity for recent) increases. The recursive KV-cache mechanism provides competitive results for short paths but degrades for extended histories due to information bottlenecking and gradient propagation challenges across long sequences.
Geometry-Enhanced Visual Representation
Efficient-VLN enriches 2D visual features with 3D geometric context by leveraging a streaming 3D geometry encoder (StreamVGGT) that predicts geometry from RGB input. This design fuses 3D structure into token representations without requiring explicit depth sensors or 3D maps, bridging the previously observed gap in geometry-informed VLN. The 3D geometry features are aligned with 2D appearance embeddings via a lightweight MLP and are fused through element-wise addition, improving spatial awareness and localization—capabilities crucial for robust navigation without sacrificing computational efficiency.
Dynamic Mixed Policy for Efficient Data Aggregation
Existing DAgger-based approaches typically balance between oracle and learned policy via a constant mixing ratio, which leads to an unfavorable trade-off: more exploration yields diverse error-recovery data but incurs long and computationally expensive trajectories. Conversely, less exploration shortens paths at the expense of coverage.
Efficient-VLN introduces a dynamic mixed policy in DAgger, where the probability (β) of using the oracle increases as the trajectory progresses, starting with learned policy for initial steps and shifting to oracle for convergence. This schedule enables more efficient collection of recovery data without the explosion in trajectory length seen with aggressive exploration.
Extensive evaluation shows a 56% reduction in exploration overhead relative to constant-ratio baselines, while attaining higher SR and SPL.
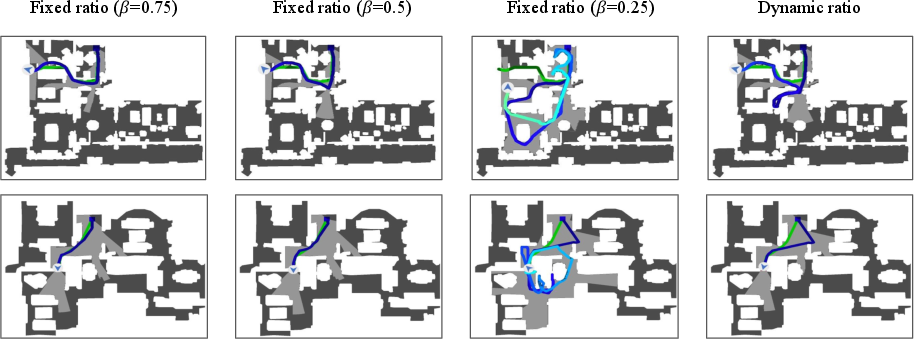
Figure 3: DAgger-generated trajectories with different exploration policies, visualizing the trade-off between coverage and trajectory length.
Training Pipeline and Acceleration
The overall pipeline leverages a two-stage training scheme:
- Initial training on standard VLN datasets (R2R-CE, RxR-CE) to acquire baseline navigation capability.
- Targeted augmentation with ScaleVLN-150K for generalization, multimodal QA sets for instruction comprehension, and DAgger-generated correction data for error recovery.
Further acceleration is achieved through sequence packing—concatenating token sequences from multiple consecutive steps and structuring cross-attention sparsity via block-sparse attention, efficiently utilizing the GPU and supporting recursive memory updates with backpropagation across step boundaries. Empirically, this reduces effective training wall time by over 40%.
Empirical Results and Memory Analysis
Efficient-VLN establishes new state-of-the-art results for both R2R-CE and RxR-CE, with the following strong numerical claims:
- 64.2% SR on R2R-CE and 67.0% on RxR-CE with just 282 H800 hours, a significant reduction compared to models like StreamVLN (1500 A100 hours) and NavFoM (4032 H100 hours).
- The progressive memory strategy demonstrates monotonic gains in long-horizon tasks as window size increases.
- Dynamic DAgger policy yields improved SPL and SR, without the overhead seen with low β constant-ratio baselines.
Ablation experiments further support these findings, showing that the progressive memory representation is most effective with a moderate window size (6-12 frames), and the inclusion of 3D geometric features improves navigation metrics by 3-5 SR points.
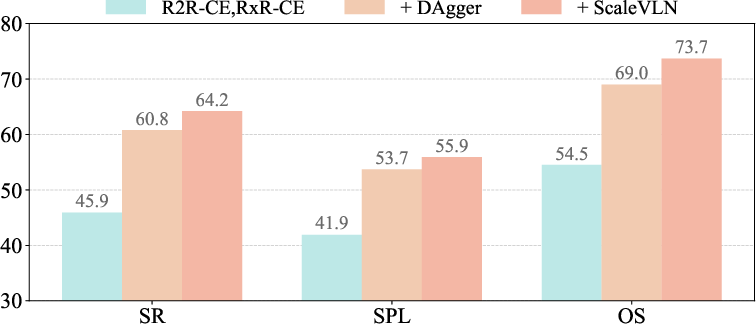
Figure 4: Ablation study illustrating the additive effect of error-recovery trajectories and ScaleVLN data on R2R-CE metrics.
Implications and Future Directions
The results demonstrate that task-specific memory and data aggregation strategies can close the performance gap between resource-constrained and resource-intensive models in VLN. Efficient-VLN validates that explicit geometry representations and memory compression schemes are critical for scaling VLN models under realistic compute limitations. The approach points towards practical, scalable frameworks for embodied vision-language agents—particularly in domains where dense 3D sensing is unavailable and computational resources are limited.
Future directions include further architectural optimization of the progressive memory schedule, dynamic windowing conditioned on observation novelty, extension to multi-agent or interactive tasks, and broader integration with diverse embodied perception-action tasks beyond indoor navigation. Exploration of continual learning or lifelong navigation, where memory mechanisms must adapt to nonstationary and incremental environments, is also warranted.
Conclusion
Efficient-VLN advances the efficiency frontier in VLN by introducing progressive and recursive memory mechanisms, geometry-enhanced perception, and a dynamic data aggregation regime. The model achieves state-of-the-art navigation results on challenging benchmarks using orders-of-magnitude less compute than previous MLLM-based systems. The findings establish efficient memory and adaptive policy strategies as key levers in embodied AI, facilitating broader scalability and deployability of language-guided navigation agents.
Reference: "Efficient-VLN: A Training-Efficient Vision-Language Navigation Model" (2512.10310)

