C2LLM Technical Report: A New Frontier in Code Retrieval via Adaptive Cross-Attention Pooling
Abstract: We present C2LLM - Contrastive Code LLMs, a family of code embedding models in both 0.5B and 7B sizes. Building upon Qwen-2.5-Coder backbones, C2LLM adopts a Pooling by Multihead Attention (PMA) module for generating sequence embedding from token embeddings, effectively 1) utilizing the LLM's causal representations acquired during pretraining, while also 2) being able to aggregate information from all tokens in the sequence, breaking the information bottleneck in EOS-based sequence embeddings, and 3) supporting flexible adaptation of embedding dimension, serving as an alternative to MRL. Trained on three million publicly available data, C2LLM models set new records on MTEB-Code among models of similar sizes, with C2LLM-7B ranking 1st on the overall leaderboard.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces C2LLM, a new way to turn computer code and questions about code into numbers (called “embeddings”) so that a search system can quickly find the most relevant code. Think of it like building a super-smart search engine for programmers: you type a question like “read all lines from a JSONL file in Python,” and it finds the right code snippet among millions.
What were the researchers trying to find out?
They wanted to answer three simple questions:
- How can we make code search work better than current methods?
- Can we combine the strengths of big code-focused LLMs with a smarter way to “summarize” long code into a single vector?
- Can we produce embeddings that are both high-quality and compact (small-sized) so they work well in real-world databases?
How did they do it? The key idea and approach
First, a few quick translations:
- Embedding: Turning text or code into a list of numbers (like coordinates) so a computer can compare them easily.
- Token: A small piece of text or code, like a word or symbol.
- Pooling: Combining all the token pieces into a single summary vector for the whole input.
Most systems use one of two common pooling tricks:
- Mean pooling: Average everything together. Simple, but it treats all parts as equally important.
- EOS pooling: Use the last token’s representation as the whole summary. Fast, but it can “squeeze” too much information into one final spot, especially bad for long code files.
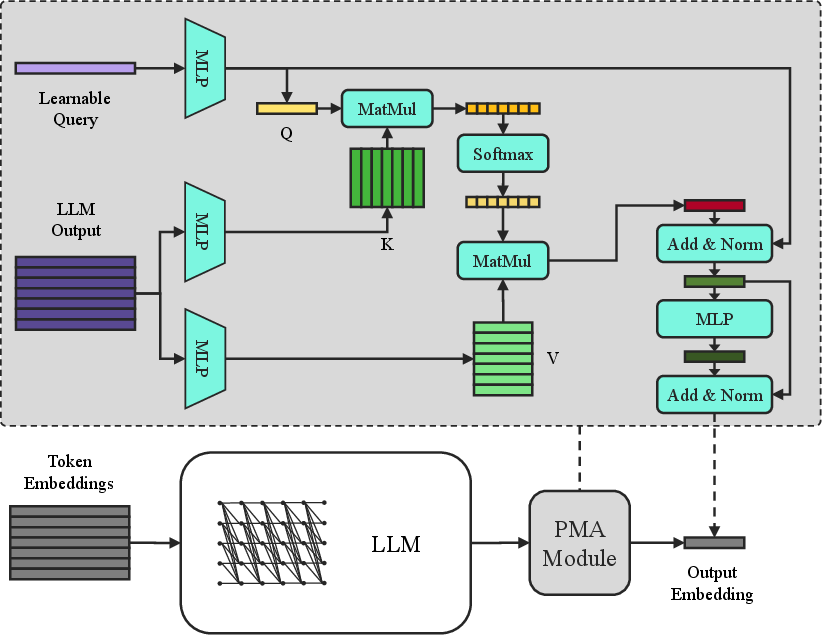
C2LLM introduces a smarter pooling layer called PMA (Pooling by Multihead Attention). Here’s an everyday analogy:
- Imagine a teacher (the PMA module) who looks at the entire class (all tokens in the code) and decides which students (tokens) are most important to pay attention to. The teacher then writes a one-paragraph summary that captures the key points. That summary is the embedding.
More specifically:
- They start with a strong code-focused LLM (Qwen2.5-Coder) that reads code left-to-right, like a storyteller (this is called “causal attention”).
- Then they add a tiny “cross-attention” layer with a single learnable query (the teacher) that looks at every token’s features and combines them into one smart summary vector.
- Bonus: This layer can also shrink the size of the embedding (like compressing a photo) without losing much important information, so it fits better into large vector databases.
How they trained it:
- They used “contrastive learning,” which is like a matching game: pull together pairs that belong together (a question and its correct code) and push apart pairs that don’t match.
- They trained on 3 million examples from many code-related datasets (coding problems, Q&A pairs, code-to-code matches, text-to-SQL, and more).
- They used efficiency tricks like LoRA (a way to fine-tune big models cheaply) and FlashAttention2 (a faster attention algorithm) to make training practical.
- They also used “hard negatives” (tricky wrong answers that look similar) to make the model sharper at telling close matches apart.
What did they find, and why does it matter?
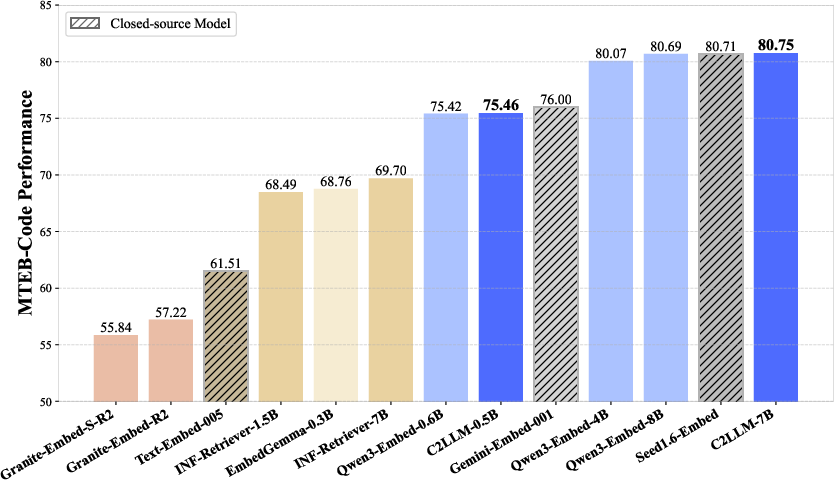
Main results on the MTEB-Code benchmark (a respected leaderboard for code retrieval):
- Their larger model, C2LLM-7B, reached the number 1 spot overall.
- Their smaller model, C2LLM-0.5B, became the best among models under 1 billion parameters and ranked 6th overall—even beating some much bigger models.
Why this is important:
- PMA helps the model focus on the most important parts of code, instead of averaging everything or relying on the last token.
- It keeps the original strengths of the code LLM while removing the “information bottleneck” of older pooling methods.
- It can produce compact embeddings, which means faster and cheaper search in real-world systems, without complicated extra training steps.
What’s the bigger impact?
- Better developer tools: Code search becomes more accurate, helping programmers find answers and reuse code faster.
- Smarter code assistants and agents: Systems that write, fix, or understand code can plan better by quickly finding the right snippets.
- Scales to real life: The ability to create small, high-quality embeddings means companies can store and search billions of code pieces efficiently.
- Open research: The models are released for the community, encouraging progress in code retrieval and related areas.
In short, C2LLM shows that a small but smart “attention-based pooling” step can make a big difference for code search—making it faster, more accurate, and more practical at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves missing, uncertain, or unexplored.
- Lack of ablation studies on PMA design choices:
- Effect of number of heads (e.g., 8/16/32), single vs multiple learnable queries, residual/LN placement, and feedforward width on retrieval performance and stability.
- Comparative efficacy of PMA vs EOS pooling vs mean pooling vs NV-Embed’s latent attention under identical training settings.
- Sensitivity to embedding dimension (e.g., 256/512/1024) and its trade-off with index size, latency, and accuracy.
- No analysis of sequence length limits:
- Impact of longer inputs beyond the 1024-token cap (typical code files span thousands of tokens) on retrieval recall and representation fidelity.
- Chunking strategies (overlap size, stride, chunk-level pooling) and their effect on end-to-end repository retrieval quality.
- Missing efficiency and systems metrics:
- Index build time, query latency, throughput, memory footprint, and GPU/CPU inference cost for 0.5B vs 7B models at various embedding dimensions.
- Compatibility and performance within common ANN setups (HNSW, IVF-PQ, ScaNN/FAISS), including recall–latency curves.
- Unclear real-world generalization:
- Performance on large-scale, real-world enterprise codebases (private repos, monorepos), including deduplication and near-duplicate robustness.
- Robustness to domain shift (e.g., internal coding styles, legacy code, proprietary frameworks).
- Data overlap and evaluation integrity:
- Whether training data overlaps with MTEB-Code tasks (e.g., CodeSearchNet variants), and the impact of potential leakage on reported scores.
- Formal control of contamination and an audit of dataset provenance and licensing.
- Limited failure-case analysis:
- Why performance is relatively low on CodeTransOcean-DL (e.g., 34.13) and CosQA; categorize error types (syntax mismatch, semantics, cross-language misalignment).
- Analysis of retrieval errors in multi-turn CodeFeedback (e.g., context-tracking failures, spurious attention to non-salient tokens).
- Missing robustness and safety evaluation:
- Adversarial or noisy queries (paraphrases, misspellings, prompt injection) and robustness tests.
- Security considerations (e.g., retrieval of insecure or vulnerable code patterns) and mitigations.
- Incomplete multilingual and multi-language coverage:
- Systematic evaluation across more programming languages (beyond Python/C++) and DSLs (e.g., SQL variants, configuration languages).
- Cross-language code retrieval at scale (e.g., Python→Java, JS→TypeScript) and strategies to improve semantic equivalence mapping.
- PMA interpretability and token salience:
- Whether PMA attention weights correlate with syntactic/semantic landmarks (function signatures, key logic) and how that affects retrieval outcomes.
- Techniques for explaining retrieved results via attention maps or token-level contributions.
- Training strategy sensitivity:
- Ablations on temperature , number of hard negatives , negative mining policy, curriculum grouping (by dataset and language), and global in-batch negative scope.
- Effect of LoRA rank/alpha and which LLM layers are adapted; contribution of PMA-only vs backbone adaptation.
- Checkpoint merging rationale:
- Empirical evidence that weighted merging of four checkpoints improves generalization vs single-best checkpoint; sensitivity to weights and merge timing.
- Dimensionality adaptation claims vs MRL:
- Head-to-head comparison with multi-resolution learning (MRL) on performance, cost, and index efficiency; when PMA-based reduction matches or lags MRL.
- Impact of padding and causal setup:
- Consequences of left-padding for causal attention on representation quality; experiments comparing left vs right padding and packed sequences.
- Interaction with reranking pipelines:
- Evaluation of C2LLM embeddings in two-stage retrieval (bi-encoder + cross-encoder reranker) and late-interaction methods (e.g., ColBERT) for code search.
- Coverage of retrieval tasks beyond MTEB-Code:
- Bug localization, code clone detection, patch retrieval, API usage retrieval, and repository-level search; measuring transferability of PMA embeddings to these scenarios.
- Deployment guidance gaps:
- Best practices for embedding ingestion (tokenization, prompt template usage vs raw inputs), deduplication strategies, and index maintenance in CI/CD environments.
- Model backbone generality:
- Whether PMA benefits transfer to other code LLM backbones (e.g., Llama/Mistral/StarCoder) and smaller/larger scales; potential backbone–PMA interactions.
- Quantization and compression:
- Effects of FP16/bfloat16/INT8/INT4 on embedding fidelity and retrieval accuracy; post-training vs quantization-aware training for PMA and backbone.
- Legal and ethical considerations:
- License compliance across training data, handling of copyleft code, and guidance for enterprise deployment to avoid legal risk.
- Reproducibility detail gaps:
- Exact data preprocessing pipelines, deduplication, language distribution, prompt template use at inference time, and seeds; releasing scripts for end-to-end replication.
- Benchmark significance and variance:
- Statistical significance of leaderboard gains, confidence intervals across multiple training/evaluation seeds, and sensitivity to evaluation protocol settings.
- Hybrid and multimodal retrieval:
- Joint embeddings for code, ASTs, docstrings, comments, and execution traces; whether PMA can aggregate multi-view representations effectively.
- Continual and online learning:
- Strategies for updating embeddings with evolving codebases (incremental training, adapter updates) without catastrophic forgetting.
- Security hardening and privacy:
- Mechanisms to prevent leakage of sensitive code during training/inference, and privacy-preserving retrieval (e.g., federated or encrypted embeddings).
Practical Applications
Immediate Applications
The following applications can be deployed now using the released C2LLM-0.5B and C2LLM-7B models, the PMA-based embedding method, and standard retrieval infrastructure (vector databases, indexing pipelines, and APIs).
- Software: Developer code search and discovery in large monorepos
- Use case: Index internal and external repositories; enable natural-language queries like “open a jsonl file in Python and read all lines” to retrieve the most relevant code snippets across millions of files.
- Tools/products/workflows: VS Code/JetBrains extensions, CLI search tools, enterprise “Code Search API” backed by embeddings stored in FAISS/Milvus/pgvector.
- Assumptions/dependencies: Chunking long files to ≤1024 tokens, vector DB integration, privacy and access controls, GPU/CPU capacity for 0.5B (edge/on-prem) or 7B (centralized).
- Software: Retrieval-Augmented Generation (RAG) for code assistants and agents
- Use case: Enhance autonomous code agents (e.g., SWE-Agent, OpenHands) with high-precision retrievers to fetch relevant functions, tests, docs, and diffs before editing.
- Tools/products/workflows: Retrieval middleware for agent frameworks, prompt templates aligned with training tasks (CodeFeedback, CodeSearchNet), re-ranking pipeline.
- Assumptions/dependencies: Agent orchestration, prompt alignment, latency budget; careful chunking and caching.
- Software: Code review assistance via “diff retrieval”
- Use case: Retrieve similar historical diffs to suggest best-practice changes, refactoring patterns, and regression fixes.
- Tools/products/workflows: PR bot that embeds proposed changes and compares to a library of past diffs (CodeEditSearch), comments with curated examples.
- Assumptions/dependencies: CI/CD integration, storage of past diffs, organizational policy compliance.
- Software: Duplicate bug/issue detection and triage
- Use case: Match new bug reports to existing issues and related code snippets to accelerate triage and reduce duplicates.
- Tools/products/workflows: Issue tracker plugin that embeds tickets and code; nearest-neighbor search; cross-linking to StackOverflow-like internal KB.
- Assumptions/dependencies: Access to issue text and relevant code contexts; data governance.
- Software/Documentation: Code-to-docstring and doc-to-code retrieval
- Use case: Retrieve matching docstrings for code (and vice versa) to improve documentation coverage and accuracy.
- Tools/products/workflows: Sphinx/Doxygen plugin, documentation QA workflow, embedding-powered “find missing docs” utility.
- Assumptions/dependencies: Consistent doc conventions; language coverage; chunking functions/methods.
- Data/Analytics/Finance: Natural-language to SQL retrieval
- Use case: Analysts type a question (“Top 10 customers by monthly spend”) and retrieve semantically appropriate SQL templates (SyntheticText2SQL).
- Tools/products/workflows: BI assistant, SQL template library, guarded execution with schema-aware validation.
- Assumptions/dependencies: Schema alignment, query safety, human-in-the-loop validation.
- Education: Example-driven programming learning
- Use case: Students search for relevant solutions (APPS) or cross-language equivalents (CodeTransOcean) to learn patterns and idioms.
- Tools/products/workflows: Learning platforms that surface multiple semantically-equivalent solutions; “show me the C++ version of this Python snippet.”
- Assumptions/dependencies: Academic honor code enforcement; licensing of example corpora.
- Knowledge management: StackOverflow/Forum QA retrieval for internal teams
- Use case: Embed internal Q&A and external FAQs to quickly retrieve answers with code snippets.
- Tools/products/workflows: Internal KB search, enterprise Q&A portal indexed with C2LLM embeddings.
- Assumptions/dependencies: Content curation, licensing for external sources, privacy filters.
- Software security: Rapid retrieval of known vulnerable patterns
- Use case: Search codebases for semantically similar instances of known CVE patterns or unsafe API usage.
- Tools/products/workflows: Security scanning workflow combining pattern-based matching and embedding-based similarity.
- Assumptions/dependencies: A curated library of vulnerability exemplars; false-positive management; secure handling of sensitive code.
- Infrastructure: Compact embeddings for vector databases without MRL
- Use case: Reduce storage/computation by adapting embedding dimension via PMA instead of multi-resolution learning.
- Tools/products/workflows: Embedding services configurable to 256–1024 dimensions; quantization and ANN indexing strategies.
- Assumptions/dependencies: Empirical tuning of dimension vs. recall; hardware-aware optimization.
- Research/Academia: Benchmarking and methods transfer
- Use case: Adopt PMA pooling in code embedding experiments; reproduce MTEB-Code results; compare against mean/EOS pooling.
- Tools/products/workflows: Open checkpoints, training scripts, and evaluation harnesses; course labs on retrieval techniques.
- Assumptions/dependencies: Access to datasets; adherence to model/data licenses.
Long-Term Applications
These applications are promising but need additional research, scaling, domain adaptation, or rigorous validation before broad deployment.
- Software: Autonomous large-scale refactoring agents
- Use case: Agents that retrieve patterns across entire codebases to refactor APIs, upgrade dependencies, and enforce architecture guidelines.
- Sector: Software engineering
- Dependencies: Robust planning/editing, strong test coverage, rollback strategies, reliable semantic equivalence detection.
- Policy/Compliance: Licensing and IP compliance via semantic retrieval
- Use case: Detect code that is semantically similar to OSS with incompatible licenses; automate attribution and compliance checks.
- Sector: Legal/compliance
- Dependencies: High-precision similarity thresholds, authoritative license metadata, human review loops; risk management for false positives.
- Security: Semantics-aware supply-chain assurance and SBOM augmentation
- Use case: Enrich SBOMs with semantically retrieved code fragments and security-relevant implementations, improving visibility across dependencies.
- Sector: Cybersecurity
- Dependencies: Integration with SBOM standards (SPDX/CycloneDX), scalable indexing of transitive dependencies, policy alignment.
- Healthcare: Retrieval of domain-specific clinical code frameworks and pipelines
- Use case: Find HIPAA-compliant data processing code templates, medical device firmware patterns, and clinical workflow scripts.
- Sector: Healthcare IT/medtech
- Dependencies: Domain adaptation, strict privacy/compliance controls, curated domain corpora; certification processes.
- Finance: Retrieval of regulatory-compliant financial analytics code
- Use case: Surface vetted algorithm implementations (e.g., risk models, fraud heuristics) under regulatory constraints.
- Sector: Finance/fintech
- Dependencies: Domain-specific evaluation, auditability, explainability, data governance.
- Robotics/IoT: Code retrieval tied to sensor/actuator logs
- Use case: Retrieve control code relevant to specific error states or telemetry patterns; accelerate debugging in embedded systems.
- Sector: Robotics/embedded
- Dependencies: Multimodal alignment (logs+code), real-time constraints, platform-specific corpora.
- Education: Cross-language curriculum builders with semantic mapping
- Use case: Automatically assemble learning paths by retrieving equivalent code solutions across languages and paradigms.
- Sector: Education/EdTech
- Dependencies: Pedagogical curation, bias and plagiarism safeguards, broader language coverage.
- MLOps: Continuous code observability with streaming embeddings
- Use case: Real-time indexing of evolving repos; anomaly detection in code changes via embedding drift.
- Sector: Software operations
- Dependencies: Scalable streaming pipelines, efficient re-embedding strategies, alerting and SLOs.
- Multi-domain expansion: Massively multilingual, multi-domain embeddings
- Use case: Unified retriever that spans niche languages, frameworks, and domains (as envisioned in future CodeFuse releases).
- Sector: Cross-industry
- Dependencies: Diverse high-quality data, domain-specific fine-tuning, fairness and robustness evaluation.
- Hardware co-design: Embedding-hardware optimization for edge devices
- Use case: Co-optimize PMA-based embedding dimensions with hardware accelerators to enable on-device code search.
- Sector: Edge computing
- Dependencies: Accelerator support, quantization-aware training, energy and latency constraints.
- Method transfer: PMA pooling generalized to non-code artifacts
- Use case: Apply PMA pooling to text, logs, configs, UI specs for holistic software artifact retrieval.
- Sector: Software/product engineering
- Dependencies: Task-specific finetuning, cross-artifact alignment, multi-modal benchmarks.
Notes on feasibility across applications:
- Model size vs. deployment context: C2LLM-0.5B is suited for on-prem/edge or latency-sensitive search; C2LLM-7B for centralized, high-accuracy services.
- Input length handling: The current 1024-token limit implies chunking and careful windowing for very large files; long-file strategies (sliding windows, hierarchical indexing) may be needed.
- Data coverage: Performance may vary by language/framework; domain-specific finetuning improves reliability.
- Licensing and governance: Adoption depends on model and dataset licenses, organizational policies, and compliance requirements.
- Evaluation and safety: High-stakes domains (security, healthcare, finance) require rigorous evaluation, human oversight, and audit trails before operational use.
Glossary
- Adaptive Cross-Attention Pooling: A pooling approach that uses cross-attention to aggregate sequence information into embeddings. "A New Frontier in Code Retrieval via Adaptive Cross-Attention Pooling"
- Bidirectional attention: Attention that looks both forward and backward in a sequence, unlike causal attention. "mean pooling is often paired with bidirectional attention"
- Causal attention: Unidirectional attention where each token attends only to previous tokens, matching autoregressive LLM pretraining. "C2LLM preserves the causal attention of its backbone LLM"
- Causal pretraining: Training LLMs with a causal (left-to-right) objective that conditions on past tokens only. "departing from the causal pretraining recipe of leading code LLMs"
- Causal representations: Internal features learned under a causal objective that reflect left-to-right dependencies. "utilizing the LLM's causal representations acquired during pretraining"
- Code agents: Autonomous systems that plan, search, and edit code iteratively to accomplish tasks. "emerging code agents - autonomous systems that iteratively plan, search, and edit code to accomplish complex programming tasks"
- Code retrieval: Finding relevant code snippets from large codebases based on a query. "Code retrieval is not only essential for interactive developer search engines"
- Contrastive learning: An objective that pulls related pairs together and pushes unrelated ones apart in embedding space. "Our optimization strategy centers on contrastive learning."
- Contrastive losses: Loss functions used in contrastive learning for both in-batch and hard-negative settings. "both in-batch and hard-negative contrastive losses."
- Cross-attention: An attention mechanism where a query attends over separate key/value inputs, used for pooling. "PMA consists of a cross-attention layer with a single learnable query vector"
- Dimensionality adaptation: Adjusting the embedding size independent of the LLM hidden size to meet deployment constraints. "providing support for dimensionality adaptation"
- Embedding dimension: The size of the output vector representing a sequence or token. " is the output embedding dimension."
- EOS-based sequence embeddings: Representations derived from the end-of-sequence token, potentially bottlenecking information. "breaking the information bottleneck in EOS-based sequence embeddings"
- EOS token representation: Using the end-of-sequence token’s embedding as the sequence representation. "taking the EOS token representation as sequence embeddings"
- Flash Attention 2: An optimized attention implementation improving speed and memory efficiency. "we utilize Flash Attention 2~\citep{2024FlashAttention2} across all training stages."
- Global batch strategy: Synchronizing samples across distributed processes to enlarge negative pools for contrastive training. "we implement a global batch strategy to synchronize samples across all distributed processes"
- Hard negatives: Challenging non-matching examples used to strengthen contrastive training. "we incorporate hard negatives for each query."
- Hidden states: The per-token internal representations produced by the LLM. "takes the LLM's last hidden states as key/value"
- Information bottleneck: A compression point that restricts how much information can pass into the final representation. "creating an information bottleneck"
- Key/Value (KV): The pairs in attention mechanisms that are attended to by queries. "takes the LLM's last hidden states as KV"
- Latent attention layer: An added attention module that uses latent vectors as keys/values to pool LLM outputs. "introduced a latent attention layer on top of the LLM"
- Layer normalization (LN): A normalization technique applied within transformer blocks for training stability. "with residual connections and layer normalization (LN)"
- Learnable query: A parameterized query vector that attends over token representations to perform pooling. "a single learnable query vector"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method for large models. "The fine-tuning process is made efficient through the use of LoRA"
- Mean pooling: Averaging token embeddings to produce a sequence embedding. "either adopt mean pooling over the outputs of an LLM"
- Multihead Attention: An attention mechanism using multiple parallel heads to capture diverse relations. "Pooling by Multihead Attention (PMA) module"
- MRL: A specialized training objective for learning compact embeddings; referenced as an expensive approach to dimensionality reduction. "providing an alternative to MRL"
- MTEB-Code: A benchmark leaderboard for evaluating code-related embedding and retrieval models. "MTEB-Code leaderboard."
- PMA (Pooling by Multihead Attention): A cross-attention pooling module that aggregates all tokens into a single embedding. "Pooling by Multihead Attention (PMA) module"
- Query vector: The vector in attention that queries keys/values to compute weighted aggregates. "the learnable query vector "
- ReLU: Rectified Linear Unit; a common activation function in neural networks. "E{1\times d} = \text{LN}(\text{ReLU}(\tilde OW_o) + \tilde O)."
- Residual connections: Skip connections that add inputs to outputs within blocks to aid optimization. "with residual connections and layer normalization (LN)"
- Temperature scaling factor: A parameter that scales logits to control softmax sharpness in contrastive objectives. "We apply a temperature scaling factor of "
- Token embeddings: Vector representations of individual tokens used as inputs to sequence models. "generating sequence embedding from token embeddings"
- Vector databases: Storage systems optimized for indexing and retrieving high-dimensional embeddings. "making it ideal for real-world large-scale vector databases."
- Weighted merge of checkpoints: Combining multiple trained checkpoints with weights to improve stability and generalization. "performing a weighted merge of four checkpoints"
Collections
Sign up for free to add this paper to one or more collections.

