StoryMem: Multi-shot Long Video Storytelling with Memory
Abstract: Visual storytelling requires generating multi-shot videos with cinematic quality and long-range consistency. Inspired by human memory, we propose StoryMem, a paradigm that reformulates long-form video storytelling as iterative shot synthesis conditioned on explicit visual memory, transforming pre-trained single-shot video diffusion models into multi-shot storytellers. This is achieved by a novel Memory-to-Video (M2V) design, which maintains a compact and dynamically updated memory bank of keyframes from historical generated shots. The stored memory is then injected into single-shot video diffusion models via latent concatenation and negative RoPE shifts with only LoRA fine-tuning. A semantic keyframe selection strategy, together with aesthetic preference filtering, further ensures informative and stable memory throughout generation. Moreover, the proposed framework naturally accommodates smooth shot transitions and customized story generation applications. To facilitate evaluation, we introduce ST-Bench, a diverse benchmark for multi-shot video storytelling. Extensive experiments demonstrate that StoryMem achieves superior cross-shot consistency over previous methods while preserving high aesthetic quality and prompt adherence, marking a significant step toward coherent minute-long video storytelling.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
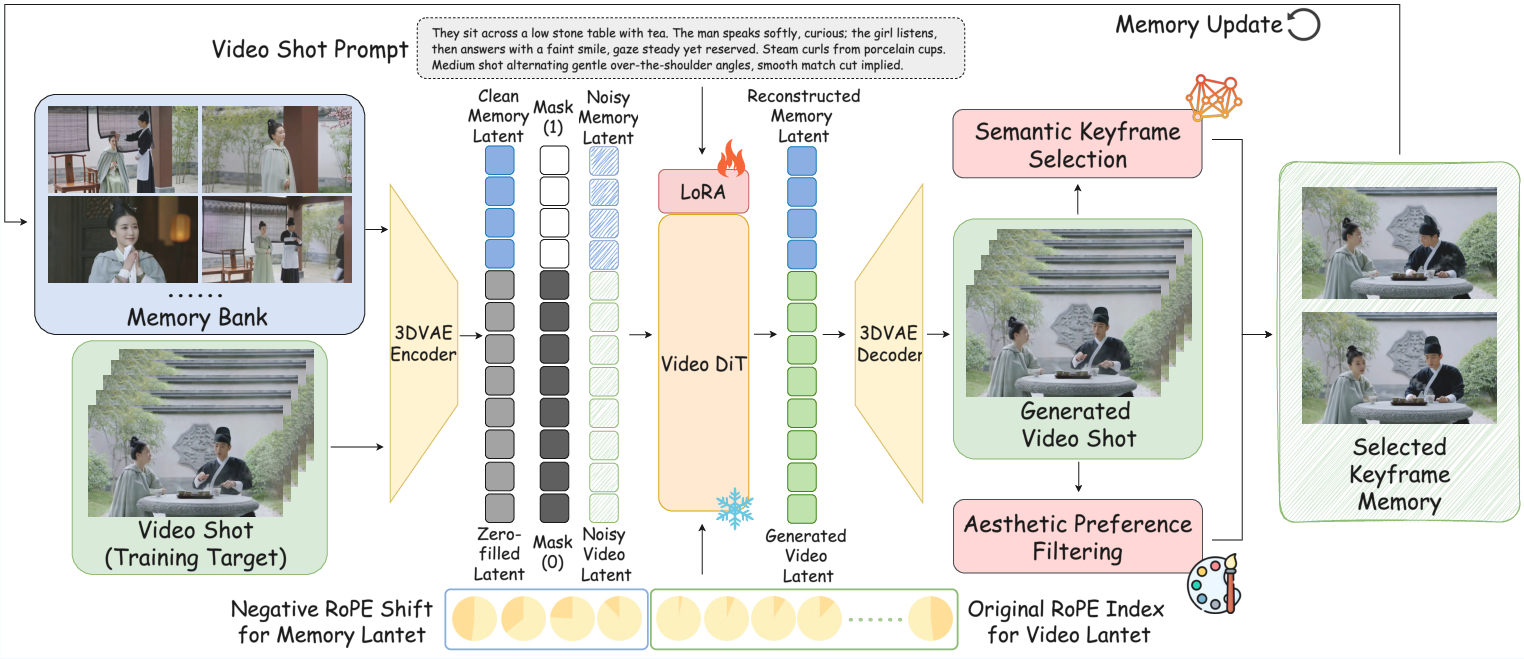
This paper introduces StoryMem, a new way to make long, multi-shot videos (like short films made of several scenes) that stay consistent over time. The goal is to keep the same characters, outfits, places, and style across all shots, while still looking visually great and following the script. Instead of training a massive new model, StoryMem reuses powerful single-shot video models and adds a “visual memory” so the model remembers important details from previous shots.
Objectives: What questions does the paper try to answer?
The researchers focused on three simple questions:
- How can we turn a single-shot video model into a storyteller that keeps characters and scenes consistent across many shots?
- Can we do this efficiently, without expensive training on huge long-video datasets?
- How do we choose the “right” memories (keyframes) so the model remembers what matters most?
Methods: How does StoryMem work?
Think of StoryMem like a director with a scrapbook:
- The model makes the video shot by shot.
- After each shot, it saves a few “keyframes” (important frames) into a memory bank—like putting highlights into a scrapbook.
- When creating the next shot, it looks at these saved keyframes to keep things consistent.
Here are the main pieces, explained simply:
1) Video diffusion model (the base engine)
A diffusion model is a generator that starts with random noise and gradually turns it into a realistic video that matches a text prompt. StoryMem uses a high-quality single-shot model (Wan I2V) and adapts it, rather than building a new huge model from scratch.
2) Memory bank (the scrapbook of keyframes)
- The memory stores a small set of frames from past shots: faces, clothes, backgrounds, and style hints.
- These frames are chosen smartly:
- Semantic selection: Use CLIP (an AI that “understands” images and text) to pick frames that are meaningfully different from each other—so the memory isn’t just lots of similar moments.
- Aesthetic filtering: Use an image quality score (HPSv3) to avoid blurry or low-quality frames—so the memories are clear and helpful.
3) Injecting memory into the video model
The saved keyframes are encoded and fed alongside the new shot’s noisy video latents, so the model sees both the “past” and what it needs to generate “now.” Two tricks make this work:
- Latent concatenation: The memory frames are attached to the input so the model can attend to them.
- Negative RoPE shift: The model uses positions in time. Memory frames get “negative timestamps,” telling the model, “These frames happened before.” That way, the model understands memory is earlier context, not part of the current shot.
This design only needs small add-on training (LoRA), which is like adding lightweight adapters to the existing model—much faster and cheaper than training a giant new system.
4) Dynamic memory updates across shots
As each shot is generated, StoryMem:
- Extracts good keyframes using CLIP and the aesthetic filter.
- Keeps a compact memory by mixing:
- Long-term anchors (a few early, important frames that define the core identity/style).
- A sliding window of recent frames (for local continuity).
- Removes old, less useful frames when the memory gets too big.
5) Smooth transitions and customization
- MI2V (Memory + Image-to-Video): If there’s no “scene cut,” StoryMem can reuse the last frame of the previous shot as the first frame of the next, making transitions feel natural.
- MR2V (Memory + Reference-to-Video): You can start with reference images (e.g., a specific character or location), and StoryMem will keep them consistent across shots.
Results: What did they find?
To test StoryMem fairly, the team built ST-Bench, a new benchmark of 30 multi-shot story scripts (300 shot prompts total) with diverse styles and scenes. They compared against:
- Independent single-shot generation (no consistency).
- Keyframe-based pipelines (generate an image for each shot, then turn it into a video).
- A large joint multi-shot model (trained to handle many shots together).
Key findings:
- Best cross-shot consistency: StoryMem beat all other methods by a wide margin at keeping characters and scenes consistent across many shots.
- High visual quality and prompt following: StoryMem preserved strong visual appeal and followed the script well, without sacrificing quality.
- User studies: People preferred StoryMem’s results in most categories, especially for consistency and narrative flow.
Ablation tests (turning off parts of the system) showed:
- Without semantic selection, the model missed important new characters or outfit changes.
- Without aesthetic filtering, the memory included low-quality frames and hurt visuals.
- Without “memory anchors,” long-range consistency faded.
Implications: Why does this matter, and what’s next?
StoryMem shows that we can get coherent, minute-long storytelling by adding smart memory to existing single-shot video models, instead of building enormous multi-shot models from scratch. This makes long-form video generation:
- More consistent: Characters, outfits, and environments stay the same across shots.
- More efficient: Small, lightweight fine-tuning (LoRA) instead of huge retraining.
- More flexible: Works with reference images and smoother transitions; can be guided by creators or story scripts.
Who can benefit?
- Filmmakers and creators making short films, trailers, ads, or vlogs.
- Game studios and animation teams needing consistent cutscenes.
- Educators and storytellers creating visual narratives with controllable style and continuity.
Limitations and future ideas:
- Complex scenes with many similar-looking characters can still confuse the memory; stronger “entity-aware” memory (like tracking named characters) could help.
- Very big camera or scene changes can make transitions less smooth; better transition modeling is a next step.
Overall, StoryMem is a practical, creative way to bring coherent storytelling to AI video generation—making long, multi-shot videos feel more like real movies.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Lack of computational analysis: no report of training/inference latency, GPU memory footprint, throughput, or scaling behavior as memory length and video duration grow.
- Unexplored sensitivity of the negative RoPE shift: the choice of offset and the assignment of negative temporal indices are heuristic; no ablation on , index spacing strategies, or learned positional encodings.
- Missing comparison of conditioning mechanisms: latent concatenation was chosen, but cross-attention to memory, feature fusion, or retrieval-augmented conditioning were not evaluated.
- No explicit control of memory–prompt trade-off: how the model resolves conflicts between stored memory and new per-shot instructions (e.g., outfit changes) is not specified or tunable.
- Deterministic memory update is heuristic-only: the CLIP-based selection + HPSv3 filtering lacks a learned policy; no exploration of end-to-end trainable memory controllers or reinforcement learning for what to remember/forget.
- Memory capacity and forgetting strategy are under-studied: the “memory sink + sliding window” design has no analysis of capacity effects, long-horizon drift, or catastrophic forgetting across minute-long sequences.
- Ambiguity in multi-character scenarios: identity disambiguation, entity tracking, and per-entity memory representations are not addressed (acknowledged as a limitation), suggesting the need for structured, entity-aware memory (names, embeddings, attributes, relations).
- Scene transition modeling is minimal: MI2V reuses the last frame or relies on script-provided scene-cut indicators; no automatic cut detection, motion continuity synthesis, or cross-shot blending strategies are studied.
- No evaluation beyond “minute-long”: upper bounds on video duration, quality degradation curves with length, and robustness to very long narratives remain unknown.
- Limited generality across base models: StoryMem is only demonstrated on Wan2.2-I2V/T2V; portability to other video diffusion backbones (e.g., SVD, HunyuanVideo, CogVideoX) is untested.
- Training data curation details are sparse: the grouping of “visually related short clips” and “single-subject multi-scene videos” lacks reproducible criteria, annotations, or public release; potential data biases and contamination are not analyzed.
- ST-Bench scope and availability: the benchmark (30 scripts, 300 prompts) generated by GPT-5 may be limited in diversity and reproducibility; it is unclear whether it is fully public, extensible, or contains standardized identity/scene annotations for fairness and consistency testing.
- Metrics miss identity-level verification: cross-shot consistency uses ViCLIP similarity; face recognition, outfit/attribute persistence, and background structural metrics (e.g., identity trackers, garment classifiers, scene graph consistency) are absent.
- Narrative coherence remains under-quantified: evaluation focuses on aesthetics and text-video similarity; formal measures of story arcs, pacing, causality, and continuity (e.g., beat alignment, event consistency) are not included.
- Robustness to difficult conditions not tested: occlusions, crowds, fast camera motion, lighting/exposure shifts, complex interactions, and non-rigid deformations are not systematically evaluated.
- Error accumulation across shots is not analyzed: how memory selection mistakes propagate (e.g., including blurred frames or wrong identities) and how to recover from memory corruption is unknown.
- No fairness/safety assessment: CLIP and HPSv3 may encode aesthetic or cultural biases; the framework’s impact on representation fairness, content policy, and privacy (beyond a consent note in MR2V) is unexamined.
- Hyperparameter sensitivity is unreported: thresholds for CLIP similarity, HPSv3 scores, per-shot keyframe limits, and memory sink size lack systematic tuning studies.
- Limited ablations: while semantic selection, aesthetic filtering, and memory sink are ablated, there is no ablation of the negative RoPE shift, LoRA rank/placement, memory length during training, or MI2V vs. M2V effects.
- No automatic scene-cut inference: reliance on script indicators limits usability; learning cut detection or continuity planning from video/text signals is an open direction.
- Lack of controllable weights for memory frames: importance weighting, per-entity prioritization, and dynamic attention to memory segments are not provided.
- No integration with structured story plans: alignment to shot lists, camera staging, and cinematographic constraints (e.g., shot scales, lens choices) is not modeled or evaluated.
- Handling of intentional changes is unclear: mechanisms to support planned character transformations (hair, clothing, aging) while preserving identity are not articulated.
- Limited analysis of non-causal motion artifacts: acknowledged qualitatively; no quantitative measure or mitigation strategy (e.g., motion priors, continuity losses) is presented.
- Open question on learning memory positional semantics: can the model learn where and how to place memory in temporal space (instead of fixed negative indices) to optimize attention and retrieval?
- Unexplored hybrid memory modalities: combining visual keyframes with text/entity graphs, audio cues, or scene layouts for richer, disambiguated memory has not been attempted.
- No study of retrieval efficiency: as the memory grows, optimal selection and fast encoding/retrieval (e.g., ANN indices, cache reuse) are not investigated.
- Reproducibility of the user study: participant counts, sampling, statistical tests, and datasets used for the human evaluation are not fully specified, hindering replication.
- Limited exploration of personalized MR2V: generalization to varied references (cartoon, stylized, multi-person), identity locking strength, and privacy-preserving identity controls are not evaluated.
Practical Applications
Immediate Applications
Below is a concise set of actionable, sector-linked use cases that can be deployed now, leveraging the StoryMem paradigm (M2V/MI2V/MR2V), memory bank workflows, and ST-Bench.
- Film/TV and Advertising pre-visualization
- Sector: Media & Entertainment, Advertising
- Use case: Generate minute-long, multi-shot previz sequences that preserve character, set, and style continuity for directors and agencies.
- Tools/products/workflows: “StoryMem Previz” plugin for Adobe Premiere/DaVinci Resolve; shot-list import; per-shot prompts with scene-cut indicators; automatic keyframe memory banking using CLIP + HPSv3; LoRA fine-tuned I2V model deployment.
- Assumptions/dependencies: Access to a high-quality single-shot base model (e.g., Wan2.2-I2V), GPU/cloud inference, proper licensing, and consent for any reference assets.
- Consistent brand character campaigns
- Sector: Marketing, Finance (cost optimization)
- Use case: Produce multi-shot ad variants across different scenes with a consistent brand mascot or spokesperson.
- Tools/products/workflows: “Brand StoryMem Studio” with MR2V for reference initialization; brand guideline prompt templates; memory sink to lock brand identity.
- Assumptions/dependencies: IP rights for characters, content safety guardrails, scene-cut configuration for natural transitions.
- Game studios: cinematic trailers and cutscenes
- Sector: Gaming, Software
- Use case: Rapidly prototype coherent narrative trailers or cutscenes with stable characters and worlds.
- Tools/products/workflows: Unreal/Unity connector; MR2V with character model references; shot-by-shot generation with memory updates.
- Assumptions/dependencies: Legal use of character references, sufficient compute, integration with game asset pipelines.
- Social media creators: multi-shot vlogs and mini-stories
- Sector: Consumer Apps, Creator Economy
- Use case: Produce coherent travel, lifestyle, and storytelling videos with consistent identity across scenes.
- Tools/products/workflows: Mobile/cloud app; MR2V memory initialized from user photos; MI2V continuity for non-cut transitions.
- Assumptions/dependencies: Privacy consents for personal references, watermarking, content moderation.
- E-learning: coherent instructor avatars and lesson series
- Sector: Education, EdTech
- Use case: Generate lesson modules where the instructor avatar, visual style, and learning environment remain consistent across shots/lectures.
- Tools/products/workflows: “Lesson Generator” with per-shot prompts; MI2V for natural transitions; memory bank management for course-level consistency.
- Assumptions/dependencies: Preventing misuse (deepfakes), provenance/watermarking, educational QA.
- Enterprise training scenarios
- Sector: Enterprise Training, HR
- Use case: Create consistent multi-shot role-play scenarios (e.g., customer support, safety drills) with recurring actors and settings.
- Tools/products/workflows: Scenario scripts; MR2V for actor references; memory sink + sliding window to balance long-term anchors and local dependencies.
- Assumptions/dependencies: Employee consent for references, compliance and record-keeping.
- Newsrooms and explainer videos
- Sector: Media, Information Services
- Use case: Build coherent explainer sequences where charts, characters, and visual styles remain stable across segments.
- Tools/products/workflows: Template prompts per segment; memory bank for recurring visual assets; automated consistency checker (CLIP/HPSv3) to flag drift.
- Assumptions/dependencies: Editorial standards, factual integrity, content safety.
- Virtual production asset continuity
- Sector: Film/TV, Virtual Production
- Use case: Maintain continuity of sets, props, and costumes across iterated previz shots during virtual production planning.
- Tools/products/workflows: On-set shot lists with scene-cut indicators; MR2V for reference props/costumes; memory-based consistency checks.
- Assumptions/dependencies: On-premise GPU capacity, tight integration with virtual production workflows.
- Children’s personalized story videos
- Sector: Consumer, Education
- Use case: Generate multi-shot children’s stories featuring consistent characters and environments, optionally personalized.
- Tools/products/workflows: MR2V with parent-provided references; content filters; aesthetic preference filtering for high-quality frames.
- Assumptions/dependencies: IP rights for characters, strong content safety and age-appropriate policies.
- Post-production consistency checking
- Sector: Media & Entertainment, Software
- Use case: Use the paper’s semantic selection + aesthetic filtering pipeline as a quality assurance tool to detect inconsistencies (identity, wardrobe, set) in multi-shot renders.
- Tools/products/workflows: “Consistency Checker” that audits shot sequences using CLIP/HPSv3 features.
- Assumptions/dependencies: Access to intermediate frames/renders, agreement on thresholds for “acceptable” divergence.
- Academic benchmarking and evaluation
- Sector: Academia, Research
- Use case: Evaluate multi-shot consistency, prompt adherence, and aesthetics using ST-Bench and reported metrics (ViCLIP-based, LAION aesthetic).
- Tools/products/workflows: ST-Bench scripts (30 diverse scripts, 300 shot prompts), reproducible evaluation pipeline.
- Assumptions/dependencies: Consistent metric implementations, dataset availability/licensing.
- Lightweight adaptation of existing single-shot models
- Sector: Software/AI Research
- Use case: Apply LoRA-based fine-tuning plus memory latent concatenation + negative RoPE shifts to extend other single-shot I2V/T2V models for storytelling.
- Tools/products/workflows: Open-source LoRA configs; training on curated short clip groups; M2V inference API.
- Assumptions/dependencies: Compatible 3D VAE/DiT architecture, short clip datasets with coherent semantics.
Long-Term Applications
The following use cases are plausible extensions requiring further research, scaling, integration, or policy development.
- Entity-aware memory for multi-character, multi-object narratives
- Sector: Media & Entertainment, Software/AI
- Use case: Replace “pure visual memory” with structured, entity-centric memory graphs (characters, props, locations) to resolve ambiguity in complex scenes.
- Tools/products/workflows: “Entity Memory Engine” combining VLMs, tracking, and memory graphs; improved negative RoPE strategies; multi-entity LoRA heads.
- Assumptions/dependencies: New datasets with entity annotations, reliable identity tracking, stronger cross-modal grounding.
- Interactive game/VR narrative engines
- Sector: Gaming, XR/VR
- Use case: Real-time story generation where memory evolves with player actions; consistent NPC identities/world states across branching paths.
- Tools/products/workflows: Runtime M2V/MI2V with action/control inputs; streamable memory updates; low-latency inference stacks (FP8/INT4).
- Assumptions/dependencies: Efficient model compression, streaming VAEs, domain-specific controls.
- Automated episodic content (minutes to hours)
- Sector: Entertainment/Streaming
- Use case: Scale from minute-long sequences to full episodes with coherent arcs, recurring characters, and evolving sets.
- Tools/products/workflows: Hierarchical memory (season/episode/scene), curriculum-level prompt planning, editorial feedback loops.
- Assumptions/dependencies: Significant compute, professional oversight, legal/IP clearance, new evaluation standards.
- Persistent digital humans in customer service and marketing
- Sector: Customer Experience, Marketing
- Use case: Digital avatars with long-term memory across campaigns, product explainers, and support content.
- Tools/products/workflows: Identity management, watermarking, provenance tracking; MR2V initialization with brand-approved references.
- Assumptions/dependencies: Ethical guidelines, regulatory compliance, robust impersonation safeguards.
- Curriculum-scale educational video generation
- Sector: Education, EdTech
- Use case: Coherent multi-course series with stable avatars, environments, and pedagogical scaffolding.
- Tools/products/workflows: Syllabus-to-story generation; learning objectives tied to memory anchors; automatic assessment hooks.
- Assumptions/dependencies: Pedagogical validation, accessibility standards, bias and accuracy audits.
- Therapeutic storytelling and personalized mental health content
- Sector: Healthcare, Digital Therapeutics
- Use case: Personalized narratives that evolve across sessions with stable characters and empathetic environments.
- Tools/products/workflows: Clinician-in-the-loop content planning; memory safety constraints; privacy-preserving MR2V.
- Assumptions/dependencies: Clinical trials, informed consent, stringent privacy/compliance (HIPAA/GDPR), harm mitigation.
- Coherent simulation and training for robotics/autonomous systems
- Sector: Robotics, Simulation
- Use case: Generate consistent visual contexts across multi-stage scenarios for synthetic data or operator training.
- Tools/products/workflows: M2V fused with action/pose control; world-state memory; domain randomization within continuity bounds.
- Assumptions/dependencies: Integration with control signals, realism requirements, sim-to-real transfer validation.
- Provenance, watermarking, and content integrity standards
- Sector: Policy, Security, Compliance
- Use case: Embed standards (e.g., C2PA) and provenance logs within memory-conditioned pipelines to deter misuse and enable auditing.
- Tools/products/workflows: “Memory Ledger” for keyframes and references; cryptographic watermarking at shot boundaries.
- Assumptions/dependencies: Industry-wide adoption, interoperable tools, regulatory guidance.
- Energy-efficient long-form video generation
- Sector: Energy, Sustainability, Media Ops
- Use case: Reduce compute relative to holistic multi-shot training via memory-conditioned adaptation; track carbon metrics for production.
- Tools/products/workflows: “Green StoryMem” dashboards; token/computation accounting; model pruning/distillation.
- Assumptions/dependencies: Comparable quality under compression, standardized efficiency benchmarks.
- Community-driven benchmarking and standards
- Sector: Academia, Open Source
- Use case: Evolve ST-Bench into a widely adopted benchmark with human-rated consistency, multi-character stress-tests, and multi-modal prompts (audio/dialog).
- Tools/products/workflows: Public leaderboards, richer metrics (identity consistency, transition naturalness), shared datasets.
- Assumptions/dependencies: Contributor community, licensing clarity, reproducibility.
- Multi-modal integration (dialogue, lip-sync, soundtrack, SFX)
- Sector: Media & Entertainment, AudioTech
- Use case: Align speech and sound design with consistent visual narratives (lip-sync across shots, reoccurring Leitmotifs).
- Tools/products/workflows: Joint audio-visual memory; multi-modal DiT variants; scene-aware sound libraries.
- Assumptions/dependencies: Reliable AV alignment models, new training data, latency optimizations.
- Live generative storytelling for streamers and events
- Sector: Live Entertainment, Creator Economy
- Use case: On-the-fly narrative generation during streams, with evolving memory and coherent visual identity.
- Tools/products/workflows: Caching of memory banks; adaptive inference scheduling; moderation overlays.
- Assumptions/dependencies: Low-latency inference, robust safety filters, audience interactivity integrations.
Global assumptions and dependencies affecting feasibility
- Technical: Availability of high-quality single-shot base models (e.g., Wan2.2), LoRA fine-tuning capacity, compatible DiT/3D VAE architectures, GPU or efficient cloud inference, reliable CLIP/HPSv3 signals, negative RoPE shift compliance.
- Data: Access to curated short video groups with coherent semantics; consented reference images for MR2V; entity annotations for advanced memory.
- Legal/ethical: IP rights, watermarking/provenance, deepfake safeguards, privacy (especially for personalized MR2V), content moderation standards.
- Limitations noted by the paper: Ambiguity in complex multi-character scenarios; imperfectly smooth transitions under large motion changes; need for entity-aware memory and improved transition modeling in future work.
Glossary
- 3D Rotary Position Embedding (RoPE): A positional encoding technique extended to three dimensions to represent spatial-temporal coordinates in transformers. "3D Rotary Position Embedding (RoPE)"
- 3D VAE: A three-dimensional Variational Autoencoder that encodes video frames into latent representations with spatial-temporal compression. "3D VAE~\cite{vae} encoder ."
- Aesthetic Preference Filtering: A post-selection step that removes low-quality frames from memory using an aesthetic scoring model. "aesthetic preference filtering,"
- Aesthetic Quality: A metric assessing visual appeal (e.g., realism, color harmony) of generated videos. "Aesthetic Quality is measured using the LAION aesthetic predictor adopted in VBench"
- Agentic: Refers to pipeline designs that employ autonomous agents to coordinate multi-stage generation tasks. "extend image pipelines to videos through an agentic, keyframe-based framework."
- Autoregressive form: A factorization where each shot is generated conditioned on previously generated content and current inputs. "in an autoregressive form,"
- Binary Mask: A tensor marking which frames or regions are fixed versus generated in conditional diffusion. "A binary mask indicates which frames are preserved or generated"
- CLIP: A multimodal model that provides semantic embeddings for images and text used for keyframe selection and memory comparison. "compute CLIP~\cite{clip} embeddings"
- Conditional Latent: A latent tensor that encodes conditioning frames (e.g., memory frames or first images) for diffusion. "into a conditional latent ."
- Cosine Similarity: A similarity measure between feature vectors used to select distinct keyframes. "via cosine similarity."
- Cross-Attention: Transformer mechanism that conditions generation on external inputs (e.g., text) by attending across modalities. "and cross-attention for text conditioning"
- Cross-shot Consistency: Measures how well visual attributes (e.g., identity, scene) remain consistent across different shots. "Cross-shot Consistency is computed as the mean ViCLIP similarity across all shot pairs."
- Decoupled Pipeline: A two-stage approach that generates keyframes first and then expands them into videos independently. "adopts a keyframe-based decoupled pipeline"
- DiT (Diffusion Transformer): A transformer architecture tailored for diffusion models that predicts velocity fields over latents. "uses diffusion transformer (DiT) as the velocity prediction network ."
- Diffusion Process: The iterative stochastic procedure that transforms noise into data samples via learned dynamics. "The diffusion process operates on the video latents"
- Full Attention: A computationally costly attention scheme over all tokens, used to jointly model multi-shot sequences. "employs full attention with interleaved 3D RoPE"
- HPSv3: An aesthetic reward model used to filter memory frames for clarity and visual reliability. "using the HPSv3~\cite{hpsv3} as aesthetic reward model"
- Image-to-Video (I2V): A paradigm that expands a single image or keyframe into a video clip using diffusion. "image-to-video (I2V) models."
- In-context image models: Image generators/editors that leverage context (e.g., references) provided in the prompt or input. "using in-context image models"
- Interleaved 3D RoPE: A variant of RoPE arranged to encode spatial-temporal axes for cross-shot attention in transformers. "interleaved 3D RoPE~\cite{Su2021RoPE}"
- Keyframe: A representative frame that captures salient visual content (e.g., characters or scenes) used as memory. "keyframes from historical generated shots."
- LAION aesthetic predictor: A learned scorer for estimating aesthetic quality, used in benchmarks like VBench. "using the LAION aesthetic predictor adopted in VBench"
- Latent Concatenation: Conditioning technique that concatenates memory and current-shot latents for joint processing. "via latent concatenation and negative RoPE shifts"
- Latent Video Diffusion Model: A diffusion model that operates in a compressed latent space rather than raw pixel space. "a latent video diffusion model"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects small trainable updates. "with only LoRA fine-tuning."
- Mask-guided Conditional Diffusion Architecture: A design that uses masks to restrict generation to specific regions or frames. "this mask-guided conditional diffusion architecture"
- Memory Bank: A compact collection of keyframes that stores visual context across shots to enforce consistency. "a compact and dynamically updated memory bank"
- Memory Sink: A long-term anchor region of the memory that preserves global context while newer frames slide over it. "memory-sink + sliding-window strategy"
- Memory-to-Video (M2V): The proposed mechanism that conditions video generation on an explicit visual memory. "Memory-to-Video (M2V) design"
- MI2V: An extension combining memory conditioning with image-to-video for smoother transitions. "extends M2V to MI2V and MR2V"
- MR2V: An extension that initializes memory with user-provided reference images for personalized generation. "extends M2V to MI2V and MR2V"
- Negative Frame Indices: Assigning negative temporal positions to memory frames so they precede the current shot in RoPE. "assigning negative frame indices to memory latents."
- Negative RoPE Shift: A positional encoding adjustment that places memory frames before current frames in the temporal axis. "negative RoPE shift."
- Prompt Adherence: The degree to which generated visuals match the given textual prompts. "prompt adherence"
- Prompt Following: A metric evaluating semantic alignment of generated content with global and per-shot prompts. "Prompt Following is assessed with ViCLIP"
- Rectified Flow: A training formulation for diffusion that predicts velocity fields under a linear interpolation schedule. "under the rectified flow~\cite{Liu2022FlowSA, Lipman2022FlowMF} formulation:"
- Reference-to-Video (R2V): A paradigm that generates videos conditioned on reference images to maintain identity or style. "reference-to-video (R2V) generation"
- RoPE (Rotary Position Embedding): A positional encoding method that rotates embeddings to encode sequence positions. "negative RoPE shifts"
- Scene-cut Indicator: A script-level control that specifies whether the transition between shots is a hard cut or continuous. "include a scene-cut indicator in the story script"
- Self-Attention: Transformer mechanism that models dependencies within a sequence (e.g., within a video). "Each DiT block contains self-attention for intra-video dependency modeling"
- Semantic Keyframe Selection: A strategy to pick diverse, representative frames using semantic embeddings and thresholds. "A semantic keyframe selection strategy"
- Sliding-Window Strategy: A memory management approach that retains recent frames in a limited window while discarding the oldest. "memory-sink + sliding-window strategy"
- Sparse Attention: Efficiency-focused attention that limits interactions to a subset of tokens to reduce cost. "sparse attention~\cite{Cai2025MOC, jia2025moga, meng2025holocine}"
- ST-Bench: A benchmark comprising multi-scene, multi-shot scripts for evaluating story video generation. "we introduce ST-Bench"
- Temporal Positional Indices: Numerical positions assigned to frames for temporal encoding in transformers. "the temporal positional indices are defined as"
- Temporal Stride: The frame downsampling factor used by the 3D VAE when encoding videos. "where denotes the temporal stride of the 3D VAE"
- Text-to-Image (T2I): A generation paradigm that synthesizes images from text prompts, often used for keyframe creation. "text-to-image (T2I) model~\cite{ddpm, ldm}"
- Token Compression: Reducing the number of tokens to improve attention efficiency in long sequences. "via token compression~\cite{Xiao2025CaptainCT}"
- Top-10 Consistency: A consistency metric computed on the ten most relevant shot pairs based on prompt similarity. "a Top-10 Consistency score"
- Velocity Field: The vector field predicted by the diffusion network that guides the transformation from noise to data. "velocity field is parametrized by a neural network ."
- ViCLIP: A video-text model used to measure semantic alignment between generated videos and prompts. "assessed with ViCLIP~\cite{wang2023internvid}"
- Video Diffusion Model: A generative model that creates videos via iterative denoising in latent or pixel space. "video diffusion models"
- Wan2.2-I2V-A14B: A specific high-capacity image-to-video base model used for fine-tuning and evaluation. "Wan2.2-I2V-A14B"
Collections
Sign up for free to add this paper to one or more collections.

