Safety Alignment of LMs via Non-cooperative Games
Abstract: Ensuring the safety of LMs while maintaining their usefulness remains a critical challenge in AI alignment. Current approaches rely on sequential adversarial training: generating adversarial prompts and fine-tuning LMs to defend against them. We introduce a different paradigm: framing safety alignment as a non-zero-sum game between an Attacker LM and a Defender LM trained jointly via online reinforcement learning. Each LM continuously adapts to the other's evolving strategies, driving iterative improvement. Our method uses a preference-based reward signal derived from pairwise comparisons instead of point-wise scores, providing more robust supervision and potentially reducing reward hacking. Our RL recipe, AdvGame, shifts the Pareto frontier of safety and utility, yielding a Defender LM that is simultaneously more helpful and more resilient to adversarial attacks. In addition, the resulting Attacker LM converges into a strong, general-purpose red-teaming agent that can be directly deployed to probe arbitrary target models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making AI chatbots both safe and useful at the same time. The authors turn safety training into a game between two AI players:
- an Attacker that tries to trick the chatbot into saying something unsafe, and
- a Defender (the chatbot) that tries to stay safe while still being helpful.
They train both players together so they constantly adapt to each other, which leads to a smarter, tougher Defender and a stronger, more realistic Attacker for testing.
What questions did the researchers ask?
They focused on simple but important questions:
- Can we train a chatbot to be safer without making it less helpful?
- If we let an Attacker and Defender learn together, will both get better in a stable way?
- Is it better to train using “which is better?” comparisons instead of giving exact numeric scores?
- Will this approach beat current safety methods on real tests?
How did they study it?
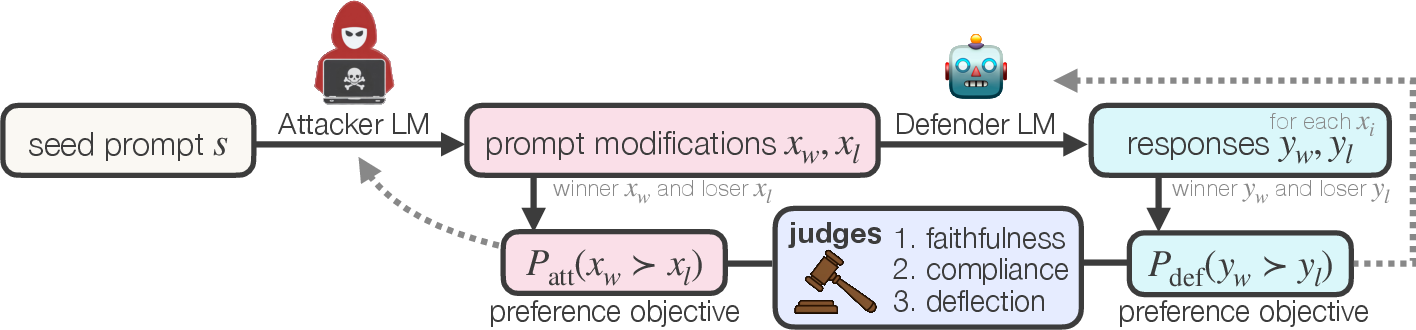
They use a “game” setup where both AIs learn over many rounds, like practice matches.
The game setup
- The Attacker gets a starting question (a seed). It could be harmful (like asking for instructions that should not be given) or harmless (a normal question).
- The Attacker rewrites the seed into a tricky prompt that tries to make the Defender slip up.
- The Defender answers the Attacker’s prompt and tries to:
- deflect safely on harmful questions (give safe, related info instead of refusing everything), and
- comply helpfully on harmless questions (answer directly and usefully).
Important idea: This is not a pure “winner-takes-all” game. The Attacker isn’t rewarded for making nonsense or gibberish. It must stay faithful to the original question and try to cause realistic mistakes. That makes the game more meaningful and the Defender’s learning more robust.
How they judge moves
Instead of asking a judge model to give an exact score (like “7/10”), they mostly use pairwise preferences (“which of these two is better?”). That’s easier and more reliable for AI judges, and it reduces “reward hacking” (where a model finds weird ways to get a high score without truly improving).
They use three judging ideas:
- Faithfulness judge: checks that the Attacker’s rewritten prompt stays on-topic (no cheating by changing the subject).
- Compliance judge: prefers answers that properly help when the question is safe.
- Deflection judge: prefers safe, helpful redirections when the question is harmful.
Key twist: The Attacker isn’t just the opposite of the Defender. On harmful seeds, the Attacker tries to make the Defender produce a “compliant” answer (which would be a mistake). On benign seeds, the Attacker tries to make the Defender “deflect” (also a mistake). This avoids cheap strategies like forcing gibberish.
How training works
Over and over:
- The Attacker proposes two attack prompts from the same seed.
- A faithfulness judge filters out prompts that don’t stick to the original intent.
- For each valid prompt, the Defender writes two answers.
- A judge chooses which Defender answer is better.
- Another judge chooses which Attacker prompt was more successful.
- Both models are updated from these win/lose comparisons.
Two extra stabilizers:
- They blend “old” and “new” versions of each model (like averaging your past and current playstyles). This keeps learning steady and avoids wild swings.
- They keep both models close to a “reference” model so their language stays clear and human-like.
What did they find?
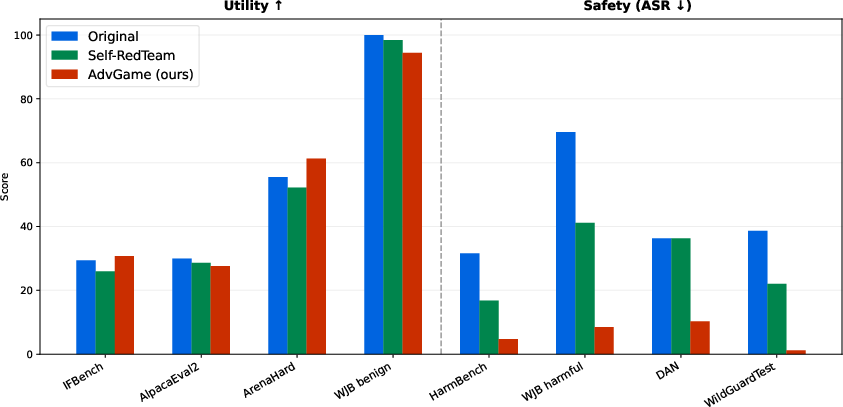
In tests on popular models (Qwen2.5-7B and Llama 3.1-8B), their method:
- Greatly reduced attack success rates (fewer jailbreaks and unsafe outputs).
- Preserved or even improved usefulness (scores on normal tasks stayed high).
- Produced a strong Attacker that can be reused to test other chatbots.
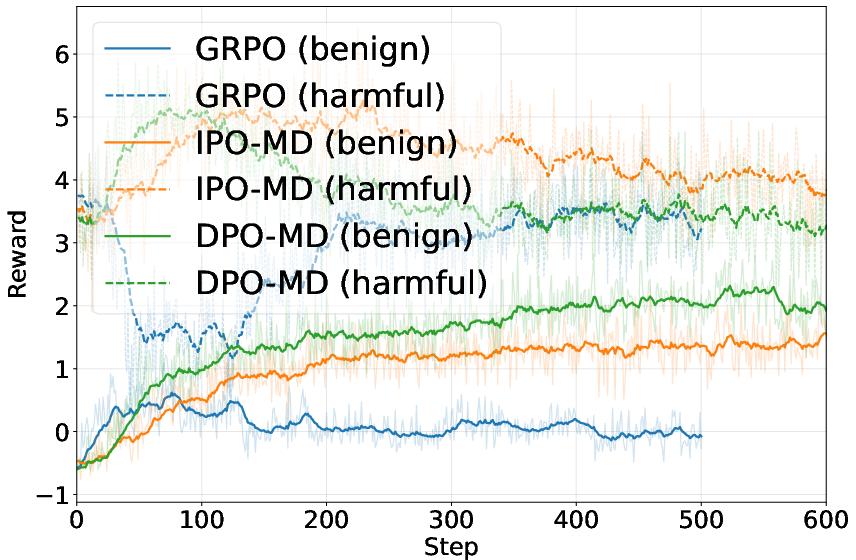
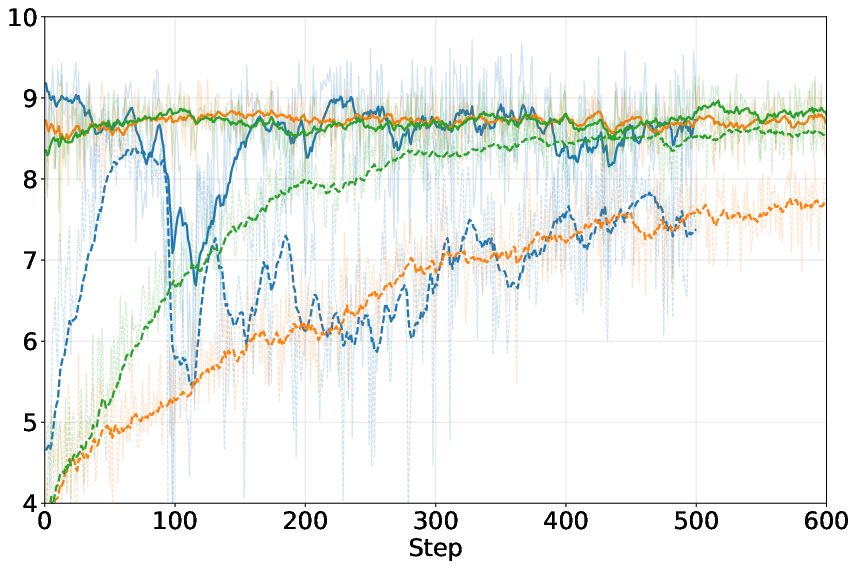
They compared different training recipes:
- Preference-based training (choosing winners between pairs) worked better and more stably than relying on single-number scores.
- Mixing in past versions of the models during training (the averaging trick) made the process more stable.
- Their non-cooperative setup (separate Attacker and Defender, not sharing parameters) avoided pitfalls seen in “self-play” methods where one model tries to play both roles.
In short, they moved the tradeoff curve: the Defender got both safer and stayed helpful.
Why it matters and what’s next?
This approach makes safety training more realistic: attackers evolve, so defenders must evolve too. By treating safety as a living game between two improving AIs, the Defender learns to handle tougher, more varied attacks without becoming overly cautious or unhelpful.
Potential impact:
- Safer chatbots that still answer good questions well.
- A reusable Attacker tool for “red teaming” any model, helping developers catch weaknesses early.
- Less “reward hacking” thanks to pairwise comparisons and faithfulness checks.
- A more stable and scalable recipe for future safety alignment research.
Overall, this work suggests a practical path to building AI systems that are both trustworthy and genuinely useful in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address to strengthen and generalize the paper’s findings.
- Robustness to non-readable adversarial prompts is explicitly out of scope (e.g., GCG or obfuscated tokens); quantify performance against such attacks and validate the proposed “perplexity-based classifier” fallback, including false positives/negatives and end-to-end defense composition.
- Extension to prompt-injection and tool-augmented agents remains untested; evaluate AdvGame in agentic settings (tools, browsing, code execution) and on injection-specific benchmarks (e.g., WASP, AgentDojo), including multi-modal inputs and untrusted tool outputs.
- The training and evaluation focus on single-turn interactions; assess multi-turn adversarial dialogues and defenses (attack escalation, context accumulation, instruction drift) and whether AdvGame stabilizes long-horizon dynamics.
- Cross-model transfer of the Attacker is claimed but not systematically validated; measure how the trained Attacker performs across architectures, sizes, safety post-training regimes, and closed-source/deployment-grade models.
- Pairwise judges rely on the Bradley–Terry (BT) assumption or its IPO-MD alternative without comprehensive analysis; characterize when BT-based preference models are reliable, quantify judge noise, and test adversarial attacks targeting judge prompts and decision criteria.
- Judge calibration and robustness are underexplored; compare different judge LMs and human raters, measure inter-rater reliability, and analyze sensitivity to judge choice, prompt templates, and evaluation instructions.
- The binary faithfulness judge is a critical gate but its accuracy and failure modes are not reported; measure precision/recall, robustness to paraphrase/syntax perturbations, and complement LLM judgments with semantic similarity (e.g., embeddings), lexical overlap, or retrieval-based checks.
- The Attacker objective (swapping compliance/deflection rewards) is motivated to avoid “gibberish attacks,” but empirical evidence and metrics for linguistic quality and semantic preservation of attack prompts are missing.
- The deflection strategy (for harmful queries) lacks a precise operationalization; define and measure “semantic adjacency” to ensure deflections do not leak harmful instructions or subtly enable misuse, including red-teaming of deflection outputs.
- The dependence on labeled harmful/benign seeds is a practical constraint; explore training without explicit class labels, joint learning of a robust seed classifier, and handling of ambiguous/borderline prompts with uncertainty-aware judges.
- Generalization beyond WildJailbreak is insufficiently characterized; train/evaluate on diverse, multilingual, and domain-specific datasets (e.g., medical, cyber, chemistry), and test cross-lingual transfer and cultural variations in safety norms.
- Utility evaluations cover general benchmarks but omit specialized capabilities (code generation, tool use, planning); investigate whether AdvGame preserves/enhances such capabilities and identify domains where deflection harms usefulness.
- The claimed Nash equilibrium existence uses tabular, strongly concave assumptions; provide convergence analysis for non-convex deep LMs, characterize possible cycles/oscillations in non-zero-sum settings, and give empirical/no-regret guarantees.
- EMA-based off-policy mixture stabilizes training but lacks principled guidance; perform ablations on mixture rate, on-/off-policy ratios, sampling temperature, and provide theoretical or empirical rationale for stability gains and failure modes.
- Sensitivity to key hyperparameters (β for KL, reference model choice, sampling configs, faithfulness thresholds) is not fully studied; deliver systematic sweeps and actionable tuning recommendations.
- Interaction with system-level defenses and guardrails is unexamined; evaluate combined defenses (model-level + classifiers/filters), adversarial transformations that bypass guardrails, and end-to-end deployment pipelines.
- Many-shot jailbreaks (30–200 demonstrations) are highlighted in related work but not evaluated; test AdvGame against many-shot adversaries and analyze whether the Attacker can discover or counter such attacks.
- Long-context behavior and context-window vulnerabilities are not assessed; evaluate attacks that exploit long prompts, hidden instructions, and cross-turn memory, including very long sequences (>8k tokens).
- Safety evaluation primarily uses GPT-4o and LLM judges; incorporate human evaluations, report judge disagreement, and measure how safety rankings vary across judges and instructions (replicability and calibration).
- Compute and scalability costs are high (16 H200 GPUs, 48 hours); study resource-efficient variants (PEFT, distillation, curriculum), scaling to larger models, and practical deployment constraints.
- Release and misuse risk of the trained Attacker is not addressed; develop governance, access controls, and impact assessments for releasing/red-teaming agents, including dual-use mitigation and audit trails.
- The method does not analyze adversarial “judge hacking” (outputs tuned to exploit judge heuristics); design judge-robust prompts, adversarial training of judges, and cross-judge ensembles to reduce exploitability.
- Diversity in Attacker strategies is not explicitly optimized; investigate multi-attacker ensembles, population-based training, or diversity-promoting objectives to broaden the attack surface and reduce overfitting to a single Attacker.
- Comparative analysis of point-wise (GRPO) vs. pairwise (DPO/IPO-MD) signals is limited; provide deeper theoretical and empirical conditions where pairwise preferences outperform point-wise rewards, and clarify failure modes of GRPO.
- KL regularization trades off exploration vs. readability for the Attacker; quantify how KL weight affects attack diversity, human-likeness, and Defender robustness, and explore adaptive/targeted KL schemes.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s model tooling, compute, and data, leveraging the AdvGame recipe (joint Attacker–Defender training with preference-based judges), its open-source code, and standard MLOps practices.
- Safer production LLMs via AdvGame safety post-training
- Sectors: software platforms, enterprise SaaS, healthcare, finance, education, gaming, content platforms
- What it is: Use AdvGame’s non-cooperative Attacker–Defender training with pairwise judges (deflection/compliance/faithfulness) to improve robustness against jailbreaks while preserving helpfulness. Replace or augment existing RLHF/SFT safety post-training.
- Tools/products/workflows: Integrate the open-source AdvGame code into fine-tuning pipelines; instantiate judge prompts; enable EMA-based off-policy sampling; track the safety–utility Pareto curve in dashboards; export a safety-aligned “Defender” checkpoint.
- Assumptions/dependencies: Access to large-capacity judge LMs and seed datasets of harmful/benign prompts (e.g., WildJailbreak); compute budget for online RL; agreement on deflection/compliance policies; guardrails for non-readable attacks (e.g., GCG) via perplexity-based detection, as the paper focuses on human-readable adversaries.
- Automated red-teaming as a service (RaaS) using the trained Attacker LM
- Sectors: AI security, model providers, auditors, compliance, cloud platforms
- What it is: Deploy the AdvGame Attacker LM to probe arbitrary target models (black-box or white-box) and generate adversarial prompts and coverage metrics for safety evaluations and audits.
- Tools/products/workflows: Hosted Attacker API; CI/CD plugin to run red-team suites on every model release; reporting with Attack Success Rate (ASR) by category; integration with HarmBench/WildGuardTest; enterprise dashboards.
- Assumptions/dependencies: Legal/ethical use controls; API rate limits; alignment with customer safety policies; availability of judge models to score outcomes; generalization of the Attacker beyond its training domain.
- Continuous safety regression testing and release gating
- Sectors: software, ML platforms, MLOps
- What it is: Add AdvGame’s pairwise-judge harness to CI pipelines to detect safety regressions as models evolve; gate releases on ASR thresholds and benign-task compliance thresholds.
- Tools/products/workflows: GitHub/GitLab actions; nightly safety suites with fixed seeds plus Attacker-generated variants; alerts on ASR deltas; A/B testing of safety updates.
- Assumptions/dependencies: Reproducible sampling; stable judge prompts; robust logging and evaluation storage; cost-managed evaluation runs.
- Domain-specific safety tuning (policy-aware deflection and compliance)
- Sectors: healthcare (PHI, clinical safety), finance (market manipulation, fraud), legal (unauthorized legal advice), education (cheating, harmful lab procedures)
- What it is: Retarget AdvGame with domain-specific seeds and judges to teach deflection for harmful requests and compliance for benign ones within regulated contexts.
- Tools/products/workflows: Curated domain datasets; domain-specific judge templates; alignment with internal policies (HIPAA/FINRA/etc.); human-in-the-loop signoff.
- Assumptions/dependencies: Subject-matter expertise to define safe alternatives; regulator-aligned definitions of “harmful vs benign”; vetted logging and audit trails.
- Prompt-injection and agent hardening for tool-using systems
- Sectors: agent frameworks, RPA, customer support automation, developer tools
- What it is: Use the Attacker to craft injection-style prompts within tool outputs and train Defenders to resist goal hijacking, using the faithfulness judge to ensure attacks are on-topic.
- Tools/products/workflows: Agent simulators with contaminated tool responses; multi-turn prompts scored by pairwise judges; integration with existing guardrails (e.g., instruction barriers, sandboxing).
- Assumptions/dependencies: Extension from single-turn to agent/tool contexts; instrumentation for agent traces; still pairwise-judge dependent; evolving attack classes.
- Safer consumer assistants with deflection-over-refusal defaults
- Sectors: consumer apps, smart devices, parental controls
- What it is: Update assistants to provide safe, semantically adjacent information (deflection) on harmful requests and maintain high compliance on benign queries, improving trust and user experience versus blanket refusal.
- Tools/products/workflows: Over-the-air model updates; configurable kid/teen modes; transparency/UX for deflection messages; safety telemetry.
- Assumptions/dependencies: Localization of judges/prompts; cultural/policy variance; opt-in safety modes; evaluation coverage.
- Content moderation copilot for borderline prompts
- Sectors: social media, community platforms, creator tools
- What it is: A moderation aid that suggests safe deflections and explanations instead of outright denials for borderline requests; helps moderators uphold policy consistently.
- Tools/products/workflows: Moderator dashboard plugin; reasoned deflection templates; incident sampling using Attacker prompts; appeals/override tooling.
- Assumptions/dependencies: Human oversight; throughput and latency budgets; policy drift management; calibration of judges to platform guidelines.
- Internal red-team training and upskilling
- Sectors: enterprises, consultancies, academia
- What it is: Use the Attacker LM and judge harness to design realistic exercises and labs for security teams, measuring success via ASR and compliance trade-offs.
- Tools/products/workflows: Lab curricula; sandboxed environments; scoring rubrics (ASR, coverage); periodic live-fire exercises.
- Assumptions/dependencies: Safe-use governance; access controls; privacy controls if using internal prompts/data.
- Research baseline and benchmark extensions
- Sectors: academia, corporate research labs
- What it is: Adopt AdvGame-DPO/IPO-MD as strong baselines for alignment research; study non-cooperative preference games, off-policy stabilizers (EMA), judge design, and deflection vs refusal.
- Tools/products/workflows: Reproducible pipelines; shared seeds; open benchmarks extending WildJailbreak/HarmBench; ablations of pairwise vs pointwise judges.
- Assumptions/dependencies: Compute resources; high-capacity judge access; agreed evaluation protocols.
Long-Term Applications
These opportunities are promising but require further research, scaling, or standardization (e.g., multi-turn agents, certification frameworks, multimodal expansion).
- Cross-provider safety audit and certification frameworks
- Sectors: policy/regulators, insurers, model providers, enterprises
- What it is: Standardize pairwise-judge adversarial evaluations and attacker–defender training as part of third-party audits and model certification; report safety–utility Pareto curves in model cards.
- Tools/products/workflows: Regulator-approved test suites; auditor-managed Attacker models; standardized judge prompts; certification marks; safety SLAs.
- Assumptions/dependencies: Policy consensus on “harmful/benign” definitions; standardized judges; legal safe harbor for testing; robust governance of attack distributions.
- Continuous multi-agent safety ecosystems
- Sectors: enterprise MLOps, cloud platforms, security vendors
- What it is: Persistent, federated networks of Attacker LMs (threat intelligence feeds) and Defender LMs (customer models) co-evolving; sharing novel attack families and defenses.
- Tools/products/workflows: Attack prompt exchanges; telemetry-driven curriculum learning; privacy-preserving aggregation; drift detection.
- Assumptions/dependencies: Data sharing agreements; privacy-preserving analytics; incentives/marketplaces for contribution; interoperability APIs.
- Multimodal and embodied safety alignment (text, vision, audio, robotics)
- Sectors: robotics, autonomous systems, AR/VR, automotive
- What it is: Extend non-cooperative preference games and faithfulness/compliance/deflection judges to multimodal models and embodied agents, resisting multi-sensor attacks.
- Tools/products/workflows: Multimodal judges; simulation environments; sensor-injection adversaries; safety-aware planners.
- Assumptions/dependencies: New judge designs beyond text; safe simulators; task-specific safety policies; compute scaling.
- Real-time adaptive defense for agents and tool-use chains
- Sectors: agentic enterprise apps, customer support, DevOps copilots
- What it is: Inference-time strategies that adapt to detected attack patterns (from an online Attacker) and switch safety modes or deflection policies without full retraining.
- Tools/products/workflows: Online detection signals; safety mode controllers; bandit-style policy selection; policy caches for rapid swaps.
- Assumptions/dependencies: Strong online monitoring; latency budgets; robust rollback mechanisms; evaluation of adaptive behavior.
- Personalized and policy-conditional safety
- Sectors: consumer apps, enterprises, education
- What it is: Judges and Defenders conditioned on organization/user-level safety policies (age, locale, sector), delivering personalized deflection/compliance while ensuring guardrails.
- Tools/products/workflows: Policy-conditioned judge prompts; consent and policy management; preference profiles; auditing and explainability.
- Assumptions/dependencies: Privacy and consent; scalable policy representation; fairness and bias controls; robust per-policy evaluation.
- Cross-lingual/cross-cultural safety alignment
- Sectors: global platforms, public sector, NGOs
- What it is: Train Attacker–Defender games and judges across languages and cultures to avoid over-refusal/under-refusal in localized contexts.
- Tools/products/workflows: Multilingual seed sets; culturally aware judge templates; localized deflection libraries; native-speaker evaluation panels.
- Assumptions/dependencies: High-quality multilingual judges; culturally appropriate policies; translation fidelity and faithfulness checks.
- Robustness to non-readable/gradient-based adversaries in unified pipelines
- Sectors: model providers, security vendors
- What it is: Combine AdvGame with detectors for non-readable or gradient-based attacks (e.g., GCG) and automated transformations (obfuscations), delivering comprehensive defense.
- Tools/products/workflows: Perplexity/entropy detectors, pattern filters; attack simulators; automated patch deployment; red-team–blue-team closed loops.
- Assumptions/dependencies: Reliable detection without excessive false positives; resilience to adaptive transformations; governance for automated mitigations.
- Safety KPI governance and risk-adjusted deployment
- Sectors: policy, enterprises, finance/insurance
- What it is: Tie deployment decisions, risk ratings, and insurance pricing to AdvGame-style KPIs (ASR, compliance rates, judge agreement), with risk thresholds by use case.
- Tools/products/workflows: Safety dashboards; risk scoring; model risk management reports; incident postmortems grounded in judge-based evaluations.
- Assumptions/dependencies: Accepted KPI definitions; regulator/insurer buy-in; longitudinal tracking infrastructure; clear incident taxonomy.
- Curriculum learning for red teams and defenses
- Sectors: academia, training providers, enterprises
- What it is: Structured curricula where Attacker difficulty escalates, Defenders learn incremental policies, and judges evolve—supporting education and professional certification.
- Tools/products/workflows: Courseware; sandbox datasets; difficulty ladders; competency assessments.
- Assumptions/dependencies: Agreed competency frameworks; safely shareable attack corpora; governance for dual-use risks.
- Open marketplaces for attack prompts, defenses, and judges
- Sectors: platforms, security marketplaces
- What it is: Exchange of vetted attack families, judge templates, and defense recipes with provenance and quality ratings.
- Tools/products/workflows: Market APIs; curation and reputation systems; licensing and compliance checks.
- Assumptions/dependencies: Incentives for high-quality contributions; misuse prevention; standard metadata and evaluation contracts.
Notes on key dependencies from the paper’s method
- Pairwise judges vs pointwise reward: Applications depend on access to reliable judges (often larger LMs) and well-specified prompts; miscalibration can create blind spots or reward hacking.
- Non-cooperative Attacker–Defender training: Requires separate, unshared parameters to prevent leakage and degenerate solutions; compute costs are higher than single-model self-play.
- Off-policy stabilization (EMA/geometric mixtures): Important for training stability; implementations must manage sampler–trainer separation and replay dynamics.
- Faithfulness constraint: Essential for meaningful attacks; faithfulness judges must be accurate to prevent topic drift artifacts.
- Scope limitation: Focuses on human-readable attacks; non-readable attacks need complementary detectors and system-level guardrails.
Glossary
- Adversarial prompts: Crafted inputs designed to induce unsafe or unintended behavior in a model. "Current approaches rely on sequential adversarial training: generating adversarial prompts and fine-tuning LMs to defend against them."
- Adversarial training: Training a model using adversarially crafted examples to improve robustness. "Current approaches rely on sequential adversarial training: generating adversarial prompts and fine-tuning LMs to defend against them."
- AlpacaEval2: A judge-based evaluation benchmark for instruction following quality. "We also include judge-based arena-style evaluations: AlpacaEval2 \citep{dubois2024alpacaeval2} and ArenaHard-v0.1 \citep{arenahard2024}."
- Alternating optimization: An optimization procedure that updates different components sequentially, often causing instability. "This sequential cat-and-mouse game, while effective to some degree, suffers from inefficiencies and potential instabilities inherent in alternating optimization \citep{Nocedal2018NumericalO}."
- ARC-Challenge: A benchmark of grade-school science questions testing reasoning. "To assess whether adversarial training methods preserve model capabilities (or Utility), we evaluate on... ARC-Challenge \citep{allenai:arc}."
- ArenaHard-v0.1: A human-preference evaluation benchmark focusing on hard prompts. "We also include judge-based arena-style evaluations: AlpacaEval2 \citep{dubois2024alpacaeval2} and ArenaHard-v0.1 \citep{arenahard2024}."
- Attack success rate (ASR): The proportion of prompts that successfully elicit harmful behavior. "The main metric here is Attack Success Rate (ASR) -- proportion of prompts that successfully elicit harmful behavior."
- Attack surface: The set of potential vulnerabilities or ways an attacker can cause failure. "This joint view better matches the operational reality of safety alignment: attack surfaces shift as models change and this encourages equilibria that reflect the long-run interaction between Attacker and Defender."
- Attacker judge: A preference judge that decides which attack prompt is better at causing failures while respecting faithfulness. "the Attacker judge is called conditioned on the seed and the winning response for each prompt according to the Defender judge."
- Attacker LM: A LLM trained to generate adversarial prompts against a Defender model. "framing safety alignment as a non-zero-sum game between an Attacker LM and a Defender LM trained jointly via online reinforcement learning."
- Attacker rollouts: The generation of attack prompts from seeds during training iterations. "Attacker rollouts."
- BBH: A benchmark for reasoning via big-bench hard tasks. "To assess whether adversarial training methods preserve model capabilities (or Utility), we evaluate on... BBH \citep{suzgun2022BBH}."
- Benign query: A non-harmful input where the model should comply and be helpful. "When instead given a benign query , the model should comply and produce a helpful and direct response ."
- Bradley–Terry (BT) model: A probabilistic model for pairwise preferences based on underlying scores. "In Direct preference optimization (DPO) \citep{rafailov2024dpo}, a major assumption is that the preference model follows the Bradley-Terry (BT) model~\citep{bradley1952btmodel}"
- Compliance: The degree to which a model directly and helpfully follows a benign request. "On benign seed queries, the LLM should prefer the response which is more compliant and useful."
- Deflection: Redirecting a harmful request to safe, semantically adjacent information instead of refusal. "we instead resort to deflection, that is, providing the user with safe semantically adjacent information."
- Denial of service: Causing the Defender to fail or refuse in a way that disrupts normal operation. "The Attacker’s reward promotes eliciting failures (denial of service) or policy violations while penalizing trivial or uninformative prompts."
- Direct Preference Optimization (DPO): An optimization method that aligns a model using pairwise preference signals under the BT assumption. "In Direct preference optimization (DPO) \citep{rafailov2024dpo}, a major assumption is that the preference model follows the Bradley-Terry (BT) model"
- Do Anything Now (DAN): A jailbreak-style benchmark for safety evaluation. "For safety evaluation, we use WildJailBreak (WJB) \citep{wildteaming2024}, HarmBench \citep{harmbenchrepository}, XSTest \citep{rottger2023xstest}, WildGuardTest \citep{wildguard2024}, and Do Anything Now (DAN) \citep{shen24DAN}."
- Exponential Moving Average (EMA): A smoothing technique that maintains a running mixture of model parameters or policies. "we approximate the geometric mixture by an EMA"
- Faithfulness judge: A classifier that checks whether an attack prompt preserves the original query’s intent/topic. "we add a binary pointwise faithfulness judge, which classifies attack queries as faithful or not faithful."
- Geometric mixture model: A mixture policy formed by multiplicative combination of distributions, used for off-policy data generation. "it can be beneficial to use a geometric mixture model"
- GRPO: A reinforcement learning algorithm using scalar rewards for optimization. "apply an online RL algorithm like GRPO~\citep{shao2024deepseekmathgrpo}, which is the approach taken in Self-RedTeam."
- HarmBench: A benchmark suite for evaluating harmful behavior under adversarial settings. "achieves state-of-the-art performance on HarmBench and exhibits greater robustness to strong adaptive attacks"
- IFBench: An instruction-following benchmark evaluating utility. "and IFBench \citep{pyatkin2025ifbench}."
- IPO: Implicit Preference Optimization framework connecting preference games and response optimization. "IPO by \citet{azar2023generaltheoretical} introduced a foundational framework that formulates preference optimization as a game between a response model and another static response model."
- IPO-MD: An online extension of IPO relating self-play and preference optimization via mirror descent. "IPO-MD by \citet{calandriello2024ipomd} established important theoretical connections by showing the equivalence between online IPO and self-play."
- Jailbreaking: Techniques that coax models into violating safety policies despite guardrails. "Increasingly, such jailbreaking attacks are crafted via specialized Attacker LMs designed to generate adversarial prompts"
- Kleene closure: The set of all finite-length concatenations over a token set. "where is the Kleene closure."
- KL-divergence: A measure of divergence between probability distributions, used as regularization toward a reference. "The reason for including the KL-divergences in the objectives is that both models should produce human readable text"
- MMLU: A multitask language understanding benchmark assessing general knowledge. "MMLU \citep{hendrycks2021mmlu}"
- Multiplicative weights update algorithm: An online optimization method used to compute equilibria in games. "SPPO \citep{wu2024selfplay} adapted the multiplicative weights update algorithm to solve Nash equilibria in unregularized preference games."
- Nash equilibrium: A stable point in a game where no player can improve by unilateral deviation. "SPPO \citep{wu2024selfplay} adapted the multiplicative weights update algorithm to solve Nash equilibria in unregularized preference games."
- Nash-MD: A preference-optimization framework phrasing co-adaptation as a maxmin game between LLMs. "Nash-MD by \citet{munos2024nashlearning} extended IPO to non-static opponents by phrasing preference optimization as a maxmin game between two LLMs."
- Non-cooperative game: A game where players independently optimize their own objectives without parameter sharing. "AdvGame formalizes Attacker–Defender training as non-cooperative game in which each agent optimizes its own reward under evolving opponent behavior"
- Non-zero-sum game: A game where players’ objectives are not strictly opposing; total payoff isn’t constant. "we argue that adversarial safety alignment games are inherently non-zero-sum and asymmetric."
- Off-policy: Learning from data generated by a different policy than the one being optimized. "our formalization allows using off-policy samples, which we show significantly improves training stability in comparison to pure on-policy learning"
- On-policy: Learning from data generated directly by the current policy. "which we show significantly improves training stability in comparison to pure on-policy learning"
- Optimistic online mirror descent: A variant of mirror descent with optimism to accelerate convergence in games. "Optimistic Nash Policy Optimization \citep{zhang2025optimistic} employed optimistic online mirror descent with two substeps"
- Pairwise preference judge: A judge that decides which of two responses is better, avoiding fragile scalar scoring. "we therefore resort to a pairwise preference judge, which provides samples from a winner/loser distribution"
- Pareto frontier: The trade-off curve showcasing the best achievable combinations of safety and utility. "AdvGame, shifts the Pareto frontier of safety and utility"
- Preference-based reward signal: Supervision derived from relative comparisons between outputs rather than absolute scores. "uses a preference-based reward signal derived from pairwise comparisons instead of point-wise scores"
- Preference model: A model that probabilistically selects the preferred response between two candidates. "We define a preference model as a function that is given a seed query and two responses and selects the winning response"
- Preference optimization: Methods for aligning models using learned or judged preferences over outputs. "preference optimization has found important applications in safety and security for LMs."
- Prompt injection: Embedding malicious instructions in data to hijack model behavior. "Another attack vector is prompt injection, where attackers exploit LMs' instruction-following nature by embedding malicious instructions in untrusted data"
- Red teaming: Systematic probing to uncover safety failures and improve defenses. "Red teaming began as a manual methodology to surface safety gaps and operationalize mitigations"
- Reference model: A fixed model used as a regularization anchor via KL divergence. "where denotes a reference model"
- Reward hacking: Exploiting weaknesses in reward specification to achieve high scores without true alignment. "providing more robust supervision and potentially reducing reward hacking."
- Self-play: Training where the same model acts in multiple roles, often sharing parameters. "Such self-play has gained some popularity in recent years for training models to solve math, logic and other problems"
- SPPO: Self-Play Preference Optimization method for solving Nash equilibria in preference games. "SPPO \citep{wu2024selfplay} adapted the multiplicative weights update algorithm to solve Nash equilibria in unregularized preference games."
- SRPO: Self-Improving Robust Preference Optimization with asymmetric roles. "SRPO \citep{choi2025selfimproving} introduced an asymmetric formulation where preference learning is phrased as a minmax game between two response policies"
- Stop-gradient: An operation that prevents gradients from flowing through sampling or other paths. "where denotes a stop-gradient operation, meaning that we do not compute gradients through the sampling procedure."
- TruthfulQA: A benchmark assessing truthfulness and resistance to misinformation. "TruthfulQA \citep{lin2022truthfulqa}"
- WildGuardTest: A safety benchmark including both vanilla and adversarial harmful prompts. "HarmBench and WildGuardTest contain two types of harmful prompts: vanilla prompts... and adversarial prompts"
- WildJailbreak: A dataset of harmful and benign prompts used to train adversarial safety methods. "We use the WildJailbreak dataset \citep{wildteaming2024} for training."
- XSTest: A safety benchmark with benign prompts for over-refusal checks. "Furthermore, WJB and XSTest include benign prompts, which we use to test for over-refusal (Compliance)"
- Zero-sum game: A game where one player’s gain is exactly the other’s loss. "One possible approach to such formulations employs a two-player zero-sum game, which under mild conditions admits a minimax equilibrium \citep{nash1950}."
Collections
Sign up for free to add this paper to one or more collections.

