Emergent temporal abstractions in autoregressive models enable hierarchical reinforcement learning
Abstract: Large-scale autoregressive models pretrained on next-token prediction and finetuned with reinforcement learning (RL) have achieved unprecedented success on many problem domains. During RL, these models explore by generating new outputs, one token at a time. However, sampling actions token-by-token can result in highly inefficient learning, particularly when rewards are sparse. Here, we show that it is possible to overcome this problem by acting and exploring within the internal representations of an autoregressive model. Specifically, to discover temporally-abstract actions, we introduce a higher-order, non-causal sequence model whose outputs control the residual stream activations of a base autoregressive model. On grid world and MuJoCo-based tasks with hierarchical structure, we find that the higher-order model learns to compress long activation sequence chunks onto internal controllers. Critically, each controller executes a sequence of behaviorally meaningful actions that unfold over long timescales and are accompanied with a learned termination condition, such that composing multiple controllers over time leads to efficient exploration on novel tasks. We show that direct internal controller reinforcement, a process we term "internal RL", enables learning from sparse rewards in cases where standard RL finetuning fails. Our results demonstrate the benefits of latent action generation and reinforcement in autoregressive models, suggesting internal RL as a promising avenue for realizing hierarchical RL within foundation models.


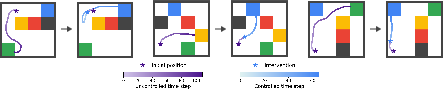
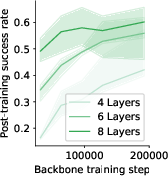
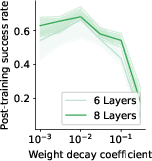
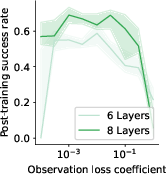

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a new way to help AI models learn long, complicated tasks more efficiently. Instead of making the model try new things one tiny step at a time (like typing a sentence word by word), the authors teach the model to explore and act using bigger, meaningful chunks of behavior (like “go to the blue square” or “walk to the door”). They do this by adding a “metacontroller” that can steer the model’s internal activity, letting the model discover and use higher-level actions that last for many steps. This makes learning faster, especially when rewards are rare.
The big questions the researchers asked
- Do AI models that predict the “next action” naturally learn hidden ideas about bigger goals (like subgoals) inside their internal activity?
- Can we steer those internal activities with simple tools to make the model follow long-term plans?
- Can a metacontroller, trained without labeled examples, discover and sequence these long, meaningful actions on its own?
- Will doing “reinforcement learning” inside the model’s internal activity (instead of at the token-by-token output) make learning much more efficient on hard tasks with sparse rewards?
How did they study it?
Setting: training a base model
- The team trained standard “autoregressive” models (these make predictions one step at a time) on sequences from agents moving in two kinds of worlds:
- A simple gridworld with colored locations and walls.
- A physics-based robot world (MuJoCo “ant”) where a four-legged robot must walk to colored spots using joint movements.
- The base models learned to predict the next action (and sometimes the next observation) from past observations and actions, without being told the agent’s goals or rewards. Think of this as watching lots of examples and learning the patterns.
Words in everyday language:
- Autoregressive model: like someone writing a story one word at a time, predicting the next word from the previous ones.
- Token-by-token: changing things one tiny unit at a time (a word, an action) rather than using bigger steps.
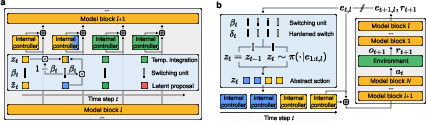
Steering the model with a simple controller
- The authors looked inside the model’s “residual stream” — a flow of internal information that runs through the layers (you can imagine it like the model’s running thoughts).
- They added a simple, linear “controller” (think of it like a steering wheel) at the middle layer. This controller nudges the residual stream in a way that pushes the model toward specific subgoals (like “head to the blue square”).
- With the right nudges, the model can follow long plans by chaining subgoal-specific controllers in sequence — and this worked even on new tasks that combine subgoals in orders the model hadn’t seen.
Words in everyday language:
- Residual stream: the model’s internal shared workspace where information gets updated layer by layer.
- Linear controller: a simple rule that tweaks the internal activity in a straight-line way—no fancy nonlinearity—like turning a knob.
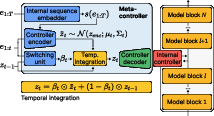
A metacontroller that discovers “plans” on its own
- Instead of giving the controller labeled subgoal instructions, they trained a “metacontroller” that:
- Reads the model’s internal activity.
- Proposes a compact “controller code” (a short vector) that the controller turns into a steering action.
- Uses a “switching gate” (a value between 0 and 1) to decide when to keep the current plan and when to switch to a new one.
- During training, the metacontroller is “non-causal”: it can look at the whole sequence (past and future) to learn good codes and switching patterns. This helps it discover which parts of behavior naturally belong together (like “walk to blue” as one unit).
- A regularizer (called a KL term) encourages the metacontroller to keep its codes simple and reusable, which leads to clear, sparse switching at meaningful points (like when reaching a subgoal).
Words in everyday language:
- Metacontroller: a coach that chooses the plan the controller should follow.
- Non-causal during training: the coach studies the full recording of a play (start to finish) to learn how to segment it into logical chunks.
- Switching gate: a dimmer switch that decides whether to stick with the current plan or change to a new one.
- KL divergence / variational inference: tools that gently push the coach to prefer simple, general codes, rather than memorizing every detail.
Internal reinforcement learning
- Standard RL on these tasks often fails because rewards happen only if the entire sequence of subgoals is completed — so random token-level exploration almost never gets lucky.
- The authors instead do RL “inside” the model:
- Treat the model’s internal activity as the observation.
- Treat the metacontroller’s outputs (the controller codes) as the actions.
- Learn to sequence abstract actions directly in this internal space.
- This “internal RL” reduces the search space dramatically: instead of trying every tiny action sequence, the model tries combinations of larger, meaningful actions.
What did they find?
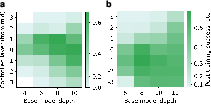
- The base models naturally learned internal beliefs about subgoals. Even without labels, a simple probe could read the current subgoal from mid-to-late layers of the residual stream.
- A simple mid-depth linear controller could reliably steer the model to complete long, multi-step tasks by composing subgoal controllers — including new combinations not seen in training.
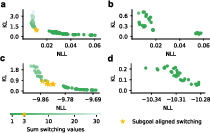
- The metacontroller, trained without subgoal labels, discovered clear, temporally-abstract actions and learned when to switch between them. Its switching gate aligned almost perfectly with real subgoal changes.
- Freezing the base model while training the metacontroller led to clean, subgoal-aligned switching. Co-training both together often collapsed to poor behavior (like switching only once), showing the value of starting from a strong, fixed base model.
- Internal RL was far more efficient than standard RL finetuning (and beat a strong hierarchical baseline called CompILE). It solved tasks with sparse rewards where token-level RL basically failed.
Why this is important:
- It shows that big sequence models already contain useful, high-level structures inside their “thought process.”
- Steering these internal structures unlocks fast, structured exploration and better learning on complex tasks.
Why it matters
- Faster learning on hard problems: Acting with “plans” instead of tiny steps makes it much easier to find good strategies when rewards are rare.
- Better generalization: Because abstract actions are reusable, the model can combine them to handle new tasks it hasn’t seen before.
- A path to hierarchical AI: This approach builds practical “skills” and “meta-skills” inside foundation models, moving toward agents that plan and act at multiple timescales.
- Potential for language and other domains: The same idea—discovering and reinforcing abstract actions inside a model’s internal activity—could help LLMs plan better, write multi-step solutions, and explore new behaviors safely and efficiently.
In short
The paper shows that:
- Autoregressive models secretly learn high-level ideas about goals and subgoals inside their internal activity.
- A simple controller and a smart metacontroller can turn these hidden ideas into reusable, long-lasting actions.
- Doing reinforcement learning inside the model’s internal space makes learning on tough, sparse-reward tasks work much better than standard methods.
- This opens a promising route to building AI that learns and plans using hierarchies of skills, not just step-by-step trial and error.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete, actionable gaps and open questions left unresolved by the paper. Each item highlights what is missing, uncertain, or unexplored, and suggests directions future research could pursue.
- External validity beyond navigation/control: The approach is only validated on gridworld and MuJoCo ant pinpad tasks; it remains unknown whether internal RL and metacontroller-discovered abstractions transfer to LLMs, code generation, mathematical reasoning, robotics manipulation, or multimodal tasks.
- Scaling to foundation model regimes: The feasibility, memory footprint, latency, and stability of future-conditioned metacontrollers and residual-stream control for 10B–1T+ parameter models are not assessed; practical protocols for layer selection, controller rank, and two-pass inference on production LLMs are missing.
- Inference-time causality and latency: The metacontroller is trained non-causally with access to future sequence information via a sequence embedding s(e_{1:T}). How to deploy in streaming/real-time settings without future context, and with acceptable latency (single-pass or receding-horizon schemes), is not specified.
- Generality of mid-depth control: The finding that mid-depth residual stream control works best is empirical and environment-specific; no systematic characterization across architectures (Transformers vs SSMs), depths, widths, attention patterns, or task types is provided.
- Controller parameterization design space: The paper uses additive, low-rank linear controllers U_t e_{t,l}. It is unclear whether other parameterizations (bias-only, multiplicative, multi-layer steering, gating, nonlinear controllers, multi-layer LoRA stacks) would offer better stability, interpretability, or performance.
- Multi-layer and multi-site control: The effects of controlling multiple layers simultaneously, or steering attention blocks, MLPs, or normalization statistics, are untested; guidelines for where to read from and write to the model are absent.
- Sensitivity to hyperparameters: There is no thorough sensitivity analysis for key hyperparameters (KL weight α, observation loss weight λ, controller rank, controlled layer l, sequence embedding architecture, optimizer, batch size, learning rates); robustness across seeds and regimes is unclear.
- Prior choice over abstract actions: The metacontroller trains with an unconditional Gaussian prior over controller codes. The trade-offs versus conditional/structured priors (e.g., autoregressive priors over abstract actions, mixture priors, discrete priors) and their impact on compositionality, dependencies, and exploration are not explored.
- Termination/option semantics: The switching gate β_t behaves quasi-binary but lacks explicit constraints or guarantees; formal option semantics (initiation sets, termination conditions, intra-option policies, off-policy learning) are not characterized or enforced.
- Degenerate switching and failure modes: While rate–distortion analysis shows degeneracies under co-training, the failure modes under frozen-base training (e.g., oscillatory switching, premature persistence, collapse to single controller) are not cataloged or mitigated.
- Role of world-modeling loss: The contribution of the auxiliary next-observation prediction loss (weighted by λ) to learning abstractions is only briefly referenced; ablations quantifying its necessity and optimal scaling are missing.
- Dataset dependence and demonstration quality: The method relies on behavioral datasets D and D_* from expert policies; the effects of dataset size, coverage, subgoal diversity, suboptimal or noisy demonstrations, and partial labels on abstraction discovery and internal RL are not quantified.
- Distribution shift robustness: Generalization is shown for longer sequences and unseen subgoal orders within the same environment; robustness to shifts in geometry, dynamics (e.g., altered MuJoCo physics), new subgoal sets/colors, distractor types, observation noise, or adversarial obstacles is untested.
- Non-hierarchical or weakly hierarchical tasks: It is unknown how the approach behaves when the task lacks clear temporal abstractions (no subgoal structure) or exhibits entangled dependencies; whether the metacontroller converges to useful abstractions or degrades performance is not studied.
- Comparative baselines: Beyond GRPO and CompILE, the paper does not benchmark against strong hierarchical RL baselines (e.g., option-critic, HIRO, HAC, COACH, V-MPO with options, skill discovery methods like DIAYN/VALOR); fair, apples-to-apples comparisons under sparse rewards are needed.
- Sample efficiency and horizon contraction claims: While claiming orders-of-magnitude speedups, the paper lacks formal analysis or standardized metrics quantifying effective horizon reduction, sample complexity bounds, or variance reduction in credit assignment.
- Policy learning details for internal RL: The internal RL algorithmic choices (on/off-policy, actor–critic vs bandit-style, exploration strategy over controller codes, reward shaping or returns normalization, credit assignment across β_t switches) are insufficiently specified for reproducibility.
- Interaction with external RLHF pipelines: It is unclear how internal RL integrates with standard RLHF or RLAIF pipelines, and whether internal exploration complements or conflicts with token-level reinforcement signals in practice.
- Preservation of pretrained capabilities: The impact of residual-stream interventions on base-model behavior outside the target tasks (catastrophic interference, capability drift, safety) is not evaluated; frameworks for constraining or regularizing controllers to preserve general performance are needed.
- Safety and control constraints: Mechanisms to bound, certify, or regularize internal interventions (e.g., norm constraints on U_t, trust-region updates, projection to safety sets, monotonicity constraints) are absent; potential for unintended behaviors is not analyzed.
- Interpretability of discovered abstractions: Beyond linear probing and β_t alignment, tools to label, visualize, and causally verify the learned controllers (e.g., path patching, causal scrubbing, counterfactual interventions) are limited; mapping controller codes to human-interpretable skills remains open.
- Theoretical framing of internal RL: A formal MDP/POMDP model for “base model as environment,” conditions for Markovianity of residual activations, and convergence/optimality guarantees for policies over internal controllers are not provided.
- Rate–distortion phenomenon: The observed horizontal gap and slope discontinuity in the rate–distortion curve under frozen-base control lack a rigorous theoretical explanation; conditions under which subgoal-aligned switching emerges and persists should be characterized.
- Transfer across architectures: Differences between SSMs and Transformers (and within each family) are only partially discussed; systematic cross-architecture studies on abstraction emergence, controllability, and internal RL efficacy are missing.
- Planning over abstract actions: The metacontroller sequences controllers reactively; integration with explicit planners (e.g., MCTS or search over abstract action graphs) to exploit the learned abstractions for faster task solving is unaddressed.
- Multi-agent and interactive settings: The approach has not been evaluated where other agents, changing goals, or social dynamics affect abstraction discovery and internal control.
- Evaluation breadth and metrics: Success-rate is the main metric; richer evaluation (learning curves, time-to-success, variance across seeds, robustness stress tests, ablations per component, computational cost) would strengthen the conclusions.
- Practical deployment workflows: End-to-end recipes (data collection, pretraining, metacontroller training, internal RL finetuning, monitoring) and engineering considerations (checkpointing, serving, fallback strategies) are not specified, limiting immediate applicability.
Glossary
- Causal model intervention: An interpretability technique that studies cause-and-effect by intervening on internal model variables to observe changes in outputs. "causal model intervention"
- CompILE: A variational method for learning and segmenting sequences into reusable sub-tasks from demonstrations, used as a hierarchical RL baseline. "Hyperparameters for CompILE training on the gridworld environment."
- Compositional generalization: The ability to recombine learned components (e.g., subgoals or controllers) in new ways to solve unseen tasks. "Compositional generalization in the residual stream."
- Future-conditioning: Training a non-causal encoder with access to information from the entire sequence to guide current decisions, enabling discovery of long-range structure. "future-conditioning: during training, the metacontroller is non-causal, and is conditioned on a sequence embedding obtained by performing a first pass through the entire sequence."
- GRPO: A reinforcement learning algorithm designed for sparse-reward settings that leverages group-relative preference optimization. "GRPO algorithm"
- Gumbel softmax: A differentiable approximation to categorical sampling that enables learning over discrete choices via continuous relaxation. "Gumbel softmax temperature for "
- Hawk (state space model): A specific efficient state-space model architecture used as the backbone for sequence modeling of actions and observations. "Hyperparameters for Hawk state space model layers."
- Hierarchical RL: A reinforcement learning framework that operates over multiple temporal levels using temporally-extended actions or subroutines. "hierarchical RL"
- Hypernetwork: A neural network that generates parameters (e.g., a controller’s weights) for another network, enabling dynamic, context-dependent control. "a recurrent hypernetwork"
- In-context learning: The ability of autoregressive models to infer latent variables and adapt to tasks from context within a sequence without parameter updates. "in-context learning"
- Internal RL: Reinforcement learning performed within a model’s internal activation space (e.g., residual stream), treating the base model as part of the environment. "internal RL"
- Kullback-Leibler divergence: An information-theoretic measure of how one probability distribution diverges from a reference distribution, often used as a regularizer. "Kullback-Leibler divergence"
- Linear probing: A technique to assess whether information is linearly decodable from internal representations by training simple linear classifiers on activations. "linear probing"
- LoRA finetuning: A parameter-efficient finetuning approach using low-rank updates to adapt large models with minimal additional parameters. "LoRA finetuning"
- Metacontroller: A higher-order network that reads model activations and outputs controllers to steer internal states, discovering and sequencing abstract actions. "metacontroller"
- MuJoCo: A physics simulation platform used for continuous control tasks, such as controlling a quadrupedal ‘ant’ robot. "MuJoCo physics simulator"
- Options: Temporally-abstract, reusable subroutines in hierarchical RL that encapsulate extended sequences of actions with initiation and termination conditions. "sometimes called ``options''"
- Rate-distortion analysis: An information-theoretic tool that studies the trade-off between representation complexity (rate) and reconstruction or prediction error (distortion). "rate-distortion analysis"
- Residual stream: The sequence of activation vectors passed through layers (often in transformer-like models) that can be read from and written to for control. "residual stream activations"
- Residual stream controller: A mechanism that linearly modifies residual stream activations to steer a base model toward desired behavior or subgoals. "a low-rank linear residual stream controller"
- State-space model (SSM): A sequence modeling architecture that represents dynamics via latent states evolving over time with input-dependent transitions. "state-space models (SSMs)"
- Temporal abstraction: Representing and acting over extended time horizons using high-level actions that persist across multiple timesteps. "temporal abstraction"
- Variational bottleneck: A constraint in variational models that limits information flow through latent variables, encouraging compact, generalizable representations. "variational bottleneck"
- Variational inference: A method for approximating complex posterior distributions by optimizing a tractable surrogate objective (e.g., ELBO) over latent variables. "variational inference"
Practical Applications
Immediate Applications
The following applications can be pursued now with modest engineering effort, especially in settings where you control or can instrument the internal activations of pretrained autoregressive models and have access to behavioral logs or simulations with hierarchical structure.
- Hierarchical skill discovery for robotics labs and simulation environments
- Sector: robotics, software
- Use case: Unsupervised discovery of reusable “macro-actions” (options) from demonstration logs, then sequencing them via the metacontroller to rapidly solve sparse-reward tasks in simulators (e.g., MuJoCo, Isaac Gym).
- Tools/products/workflows: Residual-stream controller modules (LoRA-style low-rank linear controllers) inserted mid-depth in existing policy networks; a metacontroller training pipeline with a future-conditioned encoder; internal RL loop treating the base model as the environment.
- Assumptions/dependencies: Access to pretrained autoregressive action models and their residual streams; demonstration datasets with compositional subgoals; tasks exhibit hierarchical structure; ability to freeze the base model during metacontroller training.
- Faster exploration in RL agents for games and structured benchmarks
- Sector: software (RL), education/research
- Use case: Improve sample efficiency on long-horizon tasks where vanilla policy gradients fail due to sparse rewards (gridworlds, puzzle games, robot navigation mazes).
- Tools/products/workflows: Internal RL wrappers around existing agents; abstract action sequencer composed from learned controllers; evaluation harness comparing token-level RL vs internal RL.
- Assumptions/dependencies: Hierarchical task decomposition exists; access to model internals; offline logs with demonstrations to pretrain next-action models.
- LLM-based agents with macro-action steering in tool-use workflows
- Sector: software, productivity
- Use case: In agent frameworks, replace purely token-level exploration with internal controller scheduling (e.g., “search-and-summarize,” “write-and-test,” “query-and-filter” macro-actions), leading to fewer trials needed to reach sparse success signals (e.g., a correct program passes tests).
- Tools/products/workflows: Plugin that reads/writes mid-depth residual stream of LLMs; unsupervised option discovery from agent execution traces; internal RL with sparse task-level rewards (e.g., binary pass/fail).
- Assumptions/dependencies: Access to LLM internals (or steering APIs); logs of multi-step tool-use; macro-actions produce consistent activation patterns; base model frozen during metacontroller training.
- Recommendation and experimentation systems with multi-step interaction options
- Sector: software (recsys), marketing
- Use case: Discover and schedule multi-step interaction strategies (e.g., “educate→trial→convert” sequences) to improve sparse conversion events with fewer experiments.
- Tools/products/workflows: Offline pretraining on user-session logs; abstract option controllers that encode interaction phases; internal RL agents performing exploration at option level.
- Assumptions/dependencies: Sufficiently rich logs that expose interaction phases; safe exploration policies; governance for activation-level steering.
- Mechanistic interpretability and diagnostics of pretrained action models
- Sector: academia (AI research), software
- Use case: Use linear probes and causal interventions to reveal emergent subgoal representations in residual streams and identify optimal control layers (mid-depth) for steering.
- Tools/products/workflows: Probing toolbox; rate–distortion evaluation across KL weights to select bottleneck strength; controller insertion testing harness.
- Assumptions/dependencies: Access to internal activations; reproducible training data; agreement on evaluation metrics for temporal abstraction (segmentation, compositional generalization).
- Curriculum and tutoring systems for multi-step problem solving in controlled domains
- Sector: education
- Use case: Discover and schedule subgoal-aligned explanation modules (macro-actions) in math or coding exercises, optimizing sparse final correctness signals.
- Tools/products/workflows: Option discovery from step-by-step solution traces; controller scheduling guided by internal RL; mid-depth steering of educational LLMs.
- Assumptions/dependencies: Domain tasks exhibit hierarchical structure; interpretable macro-actions correspond to instructional steps; access to model internals or compliant APIs.
- Industrial process automation in simulated or sandboxed environments
- Sector: operations, manufacturing
- Use case: In sandboxed process simulations, discover and compose macro-actions (e.g., “pre-heat→mix→cool→inspect”) to reach sparse quality targets more efficiently than token-level control.
- Tools/products/workflows: Unsupervised macro-action discovery from operator logs; activation-level control modules; compositional scheduling via the metacontroller.
- Assumptions/dependencies: Detailed logs of skilled operation; safe simulation for internal RL; base models reflect process dynamics via next-observation/action pretraining.
Long-Term Applications
These applications will require further research, scale, access to proprietary model internals, robust safety guarantees, and/or standardization before deployment in production or safety-critical settings.
- General-purpose hierarchical assistants that reliably achieve long-horizon goals
- Sector: software, daily life
- Use case: Personal assistants that internally schedule macro-actions (trip planning, home projects, budgeting) and learn from sparse success signals (task completion), reducing failure modes of token-level agents.
- Tools/products/workflows: Standardized “hierarchical controller layers” for foundation models; cross-task option libraries; internal RL optimized for sparse outcome feedback.
- Assumptions/dependencies: Broad, high-quality execution logs; safe, controllable APIs for residual-stream steering; robust compositional generalization beyond training distributions; user-level safety and consent frameworks.
- Safety-critical robotics (warehousing, healthcare, autonomous driving)
- Sector: robotics, healthcare, transportation
- Use case: Macro-action scheduling (pick/place routes, triage protocols, tactical maneuvers) that improves sample efficiency and reliability under sparse reward structures (e.g., mission success).
- Tools/products/workflows: Certified controller insertion layers; formally verified switching policies; redundancy and fail-safe mechanisms; alignment audits for activation-level control.
- Assumptions/dependencies: Rigorous safety and regulatory compliance; robust mapping between activation-level controllers and physical actions; trustworthy termination conditions; domain shift resilience.
- Clinical decision support with protocol-level macro-actions
- Sector: healthcare
- Use case: Discover abstractions for care pathways (diagnose→test→treat→monitor) and optimize sparse clinical outcomes (e.g., remission rates) via internal RL in decision-support systems.
- Tools/products/workflows: Pretraining on longitudinal EHRs and guideline-driven logs; interpretable macro-actions aligned with medical protocols; human-in-the-loop scheduling and oversight.
- Assumptions/dependencies: Strong clinical validation; privacy-preserving activation-level control; extensive bias and safety audits; clear accountability and clinician control.
- Financial strategy agents using temporally-abstract trading and risk options
- Sector: finance
- Use case: Macro-action discovery for trading regimes (e.g., “accumulate→hedge→rebalance”) with sparse reward structures linked to longer-term outcomes.
- Tools/products/workflows: Internal RL on historical market logs; certified guardrails for activation-level steering; robust out-of-distribution monitoring.
- Assumptions/dependencies: Regulatory compliance; risk management; tolerance to distribution shifts; explainability and auditability of macro-actions.
- Energy and building management with multi-step control policies
- Sector: energy
- Use case: Learn macro-actions like “pre-cool,” “peak-shave,” “shift load” and schedule them to achieve sparse outcomes (e.g., monthly energy cost targets, demand response events).
- Tools/products/workflows: Option discovery from BMS logs; metacontroller scheduling across timescales; integration with digital twins; internal RL with safety constraints.
- Assumptions/dependencies: Accurate dynamics modeling; compliance with grid and building regulations; robust causal mapping from internal controllers to actuations.
- Standardized activation-level steering interfaces and governance
- Sector: policy, AI standards
- Use case: Define best practices, APIs, and safety protocols for residual-stream control, including disclosure, logging, and audit requirements.
- Tools/products/workflows: Reference implementations of controller layers; certification tests (rate–distortion profiles, switching stability); evaluation suites for sparse-reward performance vs safety.
- Assumptions/dependencies: Industry consensus; transparent access to model internals; third-party auditing; alignment with privacy and safety regulations.
- Cross-model option libraries and compositional macro-action marketplaces
- Sector: software ecosystem
- Use case: Share and reuse abstract action modules across foundation models (e.g., standardized “search,” “summarize,” “verify,” “plan” controllers), enabling plug-and-play hierarchical agents.
- Tools/products/workflows: Ontologies for macro-actions; adapters for mid-depth insertion across architectures (Transformer, SSM); internal RL fine-tuning kits.
- Assumptions/dependencies: Interoperability standards; model vendor cooperation; verification of behavior across models and tasks; licensing and IP considerations.
- Large-scale enterprise process optimization via internal RL
- Sector: operations, supply chain
- Use case: Discover process-level macro-actions across departments (procure→manufacture→ship→support), optimizing sparse outcomes (e.g., quarterly KPIs) with hierarchical control.
- Tools/products/workflows: Data pipelines for multi-department logs; activation-level control in enterprise foundation models; governance and audit trails for macro-action scheduling.
- Assumptions/dependencies: Comprehensive, high-quality logs; strong change management; robust evaluation and monitoring; alignment with organizational policies and compliance.
Notes across applications:
- The approach assumes pretrained autoregressive models implicitly encode temporally-abstract actions in their residual streams, with controllability strongest mid-depth.
- Freezing the base model is critical for successful unsupervised discovery of subgoal-aligned switching; co-training tends to collapse abstractions.
- Future-conditioned (non-causal) metacontroller training requires access to full sequences, implying suitability for offline training on logged behaviors.
- KL bottleneck must be tuned to encourage compositional generalization and sparse switching aligned with task subgoals.
- Activation-level control introduces new safety, transparency, and governance requirements, especially outside research/simulation contexts.
Collections
Sign up for free to add this paper to one or more collections.