DiT360: High-Fidelity Panoramic Image Generation via Hybrid Training
Abstract: In this work, we propose DiT360, a DiT-based framework that performs hybrid training on perspective and panoramic data for panoramic image generation. For the issues of maintaining geometric fidelity and photorealism in generation quality, we attribute the main reason to the lack of large-scale, high-quality, real-world panoramic data, where such a data-centric view differs from prior methods that focus on model design. Basically, DiT360 has several key modules for inter-domain transformation and intra-domain augmentation, applied at both the pre-VAE image level and the post-VAE token level. At the image level, we incorporate cross-domain knowledge through perspective image guidance and panoramic refinement, which enhance perceptual quality while regularizing diversity and photorealism. At the token level, hybrid supervision is applied across multiple modules, which include circular padding for boundary continuity, yaw loss for rotational robustness, and cube loss for distortion awareness. Extensive experiments on text-to-panorama, inpainting, and outpainting tasks demonstrate that our method achieves better boundary consistency and image fidelity across eleven quantitative metrics. Our code is available at https://github.com/Insta360-Research-Team/DiT360.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces DiT360, a new way to create 360° panoramic images (the kind that let you look all around—front, back, left, right, and even up and down). The main idea is to train the model using both panoramic images and regular “perspective” photos (the normal pictures you see every day) so the results look realistic and keep the correct shape and geometry.
Key Objectives
The paper focuses on three simple questions:
- How can we make full 360° images look more like real photos?
- How do we keep the geometry correct, especially at the edges and near the top and bottom where panoramas often get stretched and weird?
- Can we use regular high-quality photos to help improve panorama generation, even though good panoramic datasets are small and limited?
Methods and Approach (explained simply)
To understand the approach, it helps to know a few basic ideas:
What is a diffusion model and a transformer?
- A diffusion model is like taking a clean photo, adding lots of random noise until it looks like TV static, and then training a model to carefully remove the noise step by step to get the photo back. During generation, the model starts from noise and “un-noises” it into a new image.
- A transformer is a type of neural network that’s very good at paying attention to different parts of data. Here, it helps the model keep track of where things are in the image.
DiT360 builds on a Diffusion Transformer (DiT), so it uses both ideas together.
Two kinds of training data
- Panoramic images (full 360°). These are rare and sometimes blurry, especially at the top and bottom (think of the “north and south poles” on a world map).
- Perspective images (regular photos). These are everywhere and look great, but only show one view at a time.
DiT360 trains with both. That’s the “hybrid” in “hybrid training.”
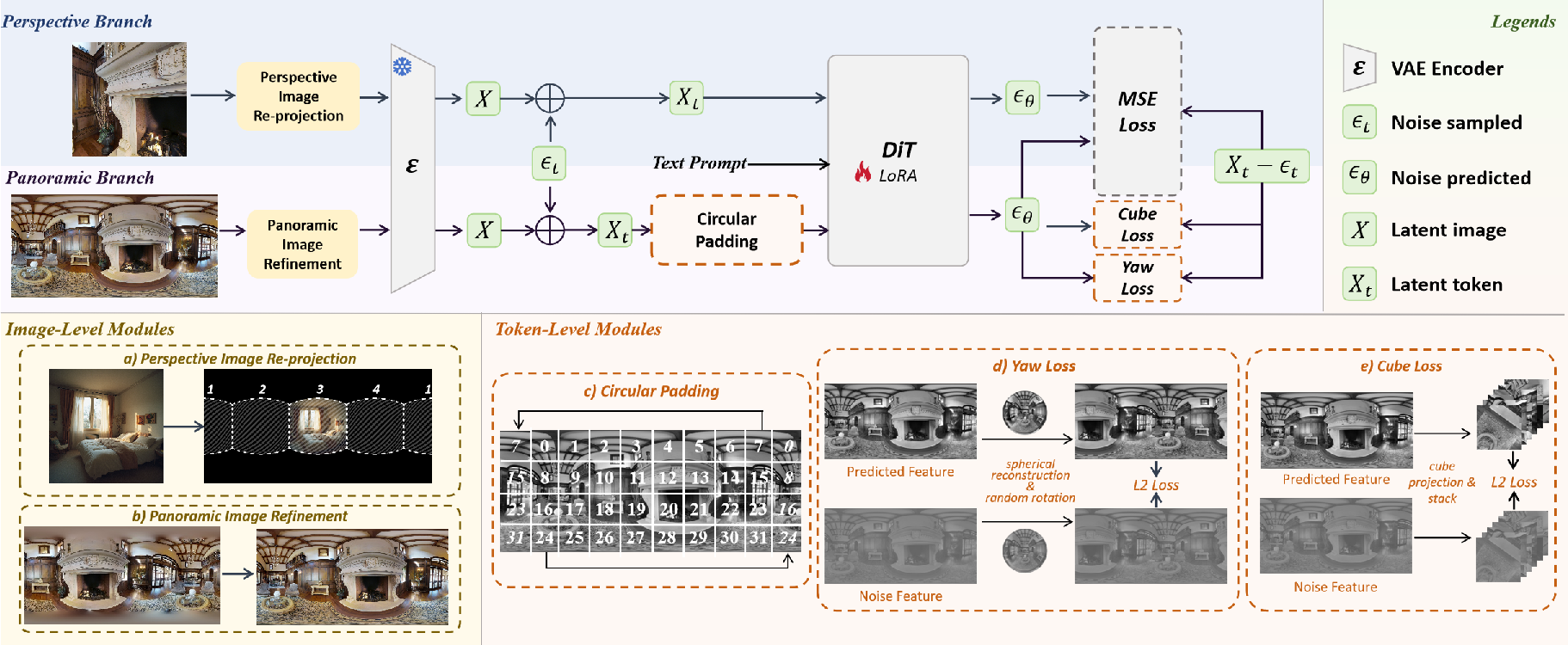
Image-level regularization: cleaning and guiding the pictures
Think of this as improving the images before they become training input:
- Panorama refinement: Panoramas are converted into a “cubemap” (imagine wrapping the scene onto the six faces of a cube, like a Rubik’s cube). The blurry top and bottom faces are fixed using inpainting (a method that fills in missing or damaged areas), then converted back into a nice clean panorama. This reduces the typical blur near the “poles.”
- Perspective guidance: High-quality regular photos are smartly projected into panoramic space (like “printing” a photo onto the side of a globe). This brings in sharp, realistic details to help the model learn how real scenes should look.
Token-level supervision: guiding the model’s “building blocks”
Inside the model, images are turned into “tokens” (think of them like small Lego bricks that represent patches of the image). DiT360 adds special training tricks to make the model handle panoramic geometry better:
- Circular padding: Panoramic images wrap around—0° and 360° are the same place. Circular padding teaches the model to keep the left and right edges perfectly aligned, like wrapping wallpaper smoothly around a cylinder without a visible seam.
- Yaw loss (rotation consistency): If you rotate a panorama left or right (turning your head), the scene should still make sense. This loss tells the model to give consistent results no matter how you rotate the panorama horizontally.
- Cube loss (distortion awareness): Equirectangular panoramas (world-map-like rectangles of the whole 360° scene) stretch things at the top and bottom. To avoid learning bad distortions, the model also learns in cube space (the six cube faces), where shapes look more normal. This helps the model preserve correct details across the whole sphere.
Together, these parts help DiT360 generate panoramas that are both photorealistic and geometrically correct.
Main Findings
- DiT360 produces sharper, more realistic 360° images than previous methods, with fewer weird artifacts.
- It keeps the borders continuous (no visible seam where the left and right edges meet) and handles the top/bottom distortions better.
- In tests across many metrics (like FID, Inception Score, BRISQUE), DiT360 beats other approaches on most scores.
- It also supports inpainting and outpainting (filling in missing regions or expanding an image beyond its borders) without extra fine-tuning.
- The model can generate high-resolution panoramas (for example, 1024×2048) thanks to the help from high-quality perspective photos.
Why this is important: It means we can get more believable, immersive 360° scenes that are both visually stunning and structurally correct.
Implications and Impact
- Better panoramas can improve AR/VR experiences, virtual tours, games, and simulations—anywhere you want to “be inside” an image.
- More accurate geometry and smoother boundaries lead to less motion sickness and a more natural feel in headsets.
- Using regular photo datasets to boost panorama quality is a practical path forward, especially since panoramic datasets are small and messy.
- This hybrid training strategy could inspire similar ideas for 3D scene generation and large virtual environments, making digital worlds look and feel more real.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues and concrete avenues for future work suggested by the paper.
- Data domain coverage and balance:
- The panoramic training set is primarily Matterport3D (indoor) plus Internet perspective images (largely landscapes). How does the method generalize to outdoor 360° panoramas, HDR lighting panoramas, and non-landscape categories? A cross-dataset evaluation (e.g., outdoor 360°, consumer-captured panos) is missing.
- No release or detailed description of the curated panoramic data beyond the inpainting pipeline; reproducibility and benchmarking remain limited without standardized, cleaned 360° datasets.
- Panoramic refinement via inpainting:
- The cubemap inpainting uses a fixed central mask for top/bottom faces (256–768 px for 1024×1024 faces) regardless of actual blur extent. Sensitivity to mask size/shape and adaptive masking has not been studied.
- Potential distribution shift: inpainting with a perspective model may inject model-specific texture priors or erase valid polar structures. No quantitative or human study evaluates structural fidelity at poles pre/post-refinement.
- Alternatives (e.g., deblurring, deconvolution, self-supervised restoration, panoramic-specific inpainting) are not compared.
- Perspective image guidance design:
- Photorealistic guidance is applied only to lateral faces; poles receive no perspective-based supervision. The impact on sky/ceiling and ground realism and structural correctness remains unclear.
- Lack of experiments with up/down perspective sources (e.g., fisheye/upward/downward shots) or specialized datasets for polar guidance.
- Text supervision and prompt alignment:
- The source and quality of text annotations for panoramas are not specified (Matterport3D lacks native captions). How were captions obtained and how does caption quality affect text-image alignment?
- The method slightly underperforms on CLIP Score and Q-Align; strategies to improve prompt adherence under hybrid training are not explored.
- Hybrid training schedule and weighting:
- No sensitivity analysis for the ratio of panoramic vs perspective batches, or for loss weights λ1 (cube loss) and λ2 (yaw loss). Adaptive weighting schemes (e.g., uncertainty- or difficulty-aware) are unexplored.
- The curriculum or mixing strategy over training (early vs late emphasis on domains/losses) is unspecified.
- Token-level supervision choices:
- Auxiliary losses are applied in noise space; there is no controlled comparison against latent-space or image-space supervision. The claimed stability advantage is not empirically validated.
- Yaw-only consistency is enforced; robustness to pitch/roll and full spherical rotations is untested. Spherical equivariant designs or multi-axis rotation consistency remain open.
- Circular padding is width-only (longitude wrap-around). Continuity at the poles (latitude extremes) is not directly addressed; vertical wrap-around or spherical padding is not considered.
- Cube loss and resampling artifacts:
- Cubemap supervision may introduce face boundary seams or sampling distortions depending on the ERP↔cube resampling scheme. The method does not specify anti-aliasing/filtering choices or evaluate their impact.
- No seam-continuity metric or ablation shows whether cube-face transitions improve or degrade with cube loss.
- Positional encoding and spherical geometry:
- The model uses standard RoPE designed for planar grids. Spherical-aware positional encodings (longitude-latitude, wrap-around, pole-aware) are not investigated.
- How positional encoding interacts with circular padding and yaw rotations is not analyzed.
- VAE suitability for ERP:
- The VAE backbone (from Flux) is trained on perspective images; ERP-specific compression artifacts and their effect on polar regions or seams are not assessed.
- Panoramic- or spherical-aware VAEs, or training the VAE on ERP/cubemap data, are not explored.
- Evaluation metrics and fairness:
- Several metrics (e.g., CLIP Score, Q-Align) are perspective-centric; missing are panorama-specific metrics such as spherical LPIPS, seam continuity scores, or pole-distortion error. A seam quality metric would directly measure the claimed boundary improvements.
- Comparisons may be confounded by disparate training data scales (e.g., synthetic corpora vs curated real data). A controlled “same data, same budget” comparison is absent.
- Inpainting/outpainting evaluation:
- Inpainting/outpainting are enabled via inversion but lack quantitative benchmarks (e.g., mask-varying FID/LPIPS, content preservation, boundary coherence) and detailed user studies for editing quality.
- Resolution scaling and efficiency:
- Training is at 1024×2048; behavior at higher resolutions (e.g., 2K–8K width) is not evaluated. Scaling laws, memory/time trade-offs, and tiling/latent stitching strategies remain open.
- Computational overhead of cube/yaw operations and circular padding on training/inference speed is not reported.
- 3D structure and geometry correctness:
- No explicit use of depth/layout priors or 3D constraints; geometric fidelity is inferred indirectly. Evaluation with depth/normal/layout estimators (and error metrics) could validate 3D consistency.
- Temporal extension:
- The approach targets static panoramas; extensions to panoramic video with temporal consistency losses and motion-aware spherical priors are unexplored.
- Controllability and conditioning:
- There is no mechanism to control global orientation (e.g., compass-aligned yaw) or horizon level at inference. Introducing explicit control tokens or camera metadata could improve editability and consistency.
- Failure modes and robustness:
- Failure cases (e.g., repeated patterns, pole artifacts, color shifts across seams) are not systematically cataloged or quantified. Stress tests for extreme prompts, unusual viewpoints, or camera miscalibration are missing.
- Safety, bias, and licensing:
- Internet perspective images may introduce biases; no bias/safety analysis is presented. Licensing and redistribution of curated/refined panoramas are unspecified, affecting reproducibility.
- Generality across backbones and representations:
- The method is tied to a DiT/Flux backbone with LoRA; portability to UNet LDMs or other DiTs is not shown.
- Outputs are ERP only; generating native cubemap or spherical latent outputs (or switching representation at inference time) is not supported or evaluated.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now, leveraging the paper’s released code, training recipe, and demonstrated tasks (text-to-panorama, inpainting, outpainting).
- Photorealistic 360° skyboxes and backgrounds for games, film/VFX, and XR
- Sectors: media/entertainment, software, gaming, XR
- What: Generate HDRI-like panoramic domes and skyboxes from text or style references to light and backdrop scenes in Unreal Engine, Unity, Blender, or Nuke.
- Tools/workflows: A Blender/Unreal plugin that calls DiT360 to produce ERP or cubemap HDR backgrounds; batch generation for look-dev; prompt-to-panorama libraries.
- Assumptions/dependencies: May need HDR conversion or tonemapping beyond the paper’s default outputs; GPU availability for high-res generation; licensing for commercial use of weights.
- Panoramic restoration, inpainting, and outpainting for 360° archives
- Sectors: media digitization, real estate, cultural heritage, mapping
- What: Clean and complete legacy panoramas (e.g., polar blur, stitching seams, missing areas) using the paper’s ERP→cubemap inpainting pipeline and circular-padding boundary continuity.
- Tools/workflows: Batch CLI for panoramic refinement of Matterport/YouTube 360 content; integration into DAM/MAM systems; automated horizon-aware pre-processing.
- Assumptions/dependencies: Accurate horizon/pose metadata improves results; inpainting quality depends on the chosen editor (e.g., Flux inpainting); output QA for sensitive archives.
- Rapid authoring of 360 virtual tours and immersive classroom content
- Sectors: education, tourism/marketing, events
- What: Create realistic 360 scenes for school lessons, museum previews, hotel/tour venue marketing without location captures.
- Tools/workflows: Web authoring tool that generates themed panoramas from prompts and stitches them into clickable tours; LMS integration for classroom modules.
- Assumptions/dependencies: Style/brand safety controls; accessibility and age-appropriate content filters; GPU-backed cloud service.
- Interior staging and concept visualization for real estate
- Sectors: real estate, architecture/interior design
- What: Generate showable 360 room concepts from textual briefs; outpaint 180° shots from consumer cameras (e.g., Insta360) to full 360°.
- Tools/workflows: Realtor plugin that expands partial panoramas, removes unwanted objects, and harmonizes seams; viewer apps supporting ERP or cubemap.
- Assumptions/dependencies: Avoid misleading representations (disclosures); consistent EXIF orientation improves outpainting.
- Simulation textures for robotics and embodied AI environments
- Sectors: robotics, autonomy, simulation software
- What: Populate simulators (e.g., Isaac/Omniverse, Habitat) with varied, photorealistic 360 backgrounds to diversify visual domain exposure.
- Tools/workflows: Generator that outputs curated domes by scenario (warehouse, home, outdoor) for domain randomization; dataset packs of ERPs/cubemaps.
- Assumptions/dependencies: Appearance realism ≠ physical correctness (no dynamics or depth by default); label-generation requires additional tools.
- Data augmentation for panoramic perception (segmentation, detection, V&L navigation)
- Sectors: academia, robotics
- What: Expand limited 360 datasets with synthetic but realistic panoramas to train ERP/CP-based perception models; improve boundary and polar-region robustness.
- Tools/workflows: Panoramic dataset synthesis pipeline; plug-in losses (yaw/cube) to train DiT backbones for ERP tasks; ERP/CP projections for downstream labeling.
- Assumptions/dependencies: Distribution shift must be measured; annotations require auto-labelers or human QA; avoidance of evaluation contamination.
- Boundary seam repair utility for existing ERP assets
- Sectors: software tooling, content operations
- What: Fix visible seams at 0°/360° longitudes with the paper’s position-aware circular padding and training heuristics.
- Tools/workflows: Seam-fixing CLI/API; batch repair of content libraries; integration into stitching/postprocessing pipelines.
- Assumptions/dependencies: Inputs should be true ERPs; extreme distortions or misaligned horizons may need human-in-the-loop review.
- 180° to 360° expansion for consumer cameras and telepresence backdrops
- Sectors: consumer electronics, creator tools, conferencing
- What: Outpaint hemispherical captures into full spheres, or generate professional-looking 360 virtual backgrounds.
- Tools/workflows: Companion app for 360 cameras; conferencing background marketplace with text-guided generation; mobile-friendly upscaling.
- Assumptions/dependencies: Compute limits on mobile; safety and style constraints for corporate environments.
- Research baselines and training components for panoramic generative modeling
- Sectors: academia, open-source software
- What: Reuse yaw loss, cube loss, and circular padding as drop-in components for geometry-aware training in DiT/LDM pipelines.
- Tools/workflows: PyTorch modules; evaluation harness for FID/BRISQUE/FAED on ERPs and cubemaps; ablation-ready scripts.
- Assumptions/dependencies: DiT-based backbones (e.g., Flux) preferred; careful metric adaptation for panoramas.
Long-Term Applications
These rely on further research or engineering (e.g., temporal modeling, controllability, sensor realism, efficiency) before wide deployment.
- Omnidirectional video generation for film/XR/telepresence
- Sectors: media/entertainment, XR, communications
- What: Extend from images to temporally consistent 360 video for virtual production, live event re-creations, and immersive telepresence backdrops.
- Tools/workflows: Panoramic video diffusion with temporal attention; editing/inpainting across frames; streaming-friendly codecs.
- Assumptions/dependencies: Strong temporal coherence and motion realism; scalable inference; watermarking for provenance.
- Surround-view synthetic data at scale for autonomous driving and mobile robots
- Sectors: automotive, robotics
- What: Generate richly varied 360 scenes to pretrain perception, planning, and surround-view models; simulate rare long-tail conditions.
- Tools/workflows: Scene-graph or layout-conditioned panoramic generation; sensor-model alignment (fisheye, HDR, noise); integration with CARLA/Scenic/Isaac.
- Assumptions/dependencies: Dynamic agents, depth/geometry, weather/time controls; validated sim2real transfer; regulatory acceptance for safety cases.
- City-scale digital twins and urban planning simulations
- Sectors: public sector, AEC, energy/utilities
- What: Generate or augment large-area 360 textures for planning, emergency drills, and infrastructure visualization when capture is infeasible.
- Tools/workflows: GIS- and map-conditioned panorama synthesis; procedural rules for zoning styles; pipeline to mesh/textured twins.
- Assumptions/dependencies: Geospatial consistency, time-of-day and seasonal control; governance for synthetic vs. real imagery use.
- Clinical and therapeutic VR environments (exposure therapy, rehabilitation)
- Sectors: healthcare
- What: Tailored, controllable 360 scenes for graded exposure, relaxation, or cognitive rehab; culturally appropriate and adjustable by clinician.
- Tools/workflows: Therapeutic scenario libraries; clinician-facing parameter panels (crowd density, lighting); outcome-tracking integrations.
- Assumptions/dependencies: Clinical validation and IRB approvals; adverse-stimulus safety; device hygiene and accessibility.
- Immersive education and workforce training at scale
- Sectors: education, enterprise L&D
- What: Curriculum-aligned 360 modules for field training (labs, hazardous sites) without on-site risk; multilingual/localized scenes.
- Tools/workflows: Storyboard-to-panorama authoring; LMS analytics; assessment-linked scene variants.
- Assumptions/dependencies: Pedagogical efficacy studies; content age-rating; authoring guardrails to reduce bias.
- Real-time, on-device 360 generation for headsets and mobile
- Sectors: XR hardware, mobile
- What: Interactive text-to-360 and editing directly on HMDs for live prototyping and user-generated 360 spaces.
- Tools/workflows: Quantized DiT variants; distillation/pruning; attention sparsity; edge-cloud offload.
- Assumptions/dependencies: Significant optimization; battery and thermal constraints; privacy-preserving on-device inference.
- Standardized public pipelines for 360 data curation and governance
- Sectors: policy, standards, open data
- What: Shared protocols for horizon correction, polar artifact handling, aesthetic/ethics filters, and watermarking of synthetic panoramas.
- Tools/workflows: Open-source curation scripts; dataset cards documenting distortions and biases; content provenance standards.
- Assumptions/dependencies: Cross-institution collaboration; alignment with AI content labeling regulations.
- Vision/SLAM and spatial intelligence pretraining using synthetic panoramas
- Sectors: robotics, mapping, AR cloud
- What: Use high-fidelity synthetic 360s to pretrain features for place recognition, loop closure, and panorama-based localization.
- Tools/workflows: Panoramic contrastive/self-supervised objectives; mixed real–synthetic curricula; yaw-robust encoders leveraging yaw loss.
- Assumptions/dependencies: Depth or multi-view consistency may be needed; bias monitoring for real-world generalization.
- Marketplace for personalized 360 environments and branded experiences
- Sectors: consumer apps, marketing/retail
- What: Users and brands publish, buy, and remix 360 environments for metaverse showrooms, virtual events, and social media.
- Tools/workflows: Prompt templates; brand style adapters (LoRA/embeddings); IP-safe asset checks; watermarking and content moderation.
- Assumptions/dependencies: Rights management and attribution; robust safety filters; platform governance.
- Synthetic training for industrial inspections and safety drills
- Sectors: energy, manufacturing, utilities
- What: Generate hazardous-site 360 scenes (confined spaces, chemical plants) to train recognition and procedure compliance without exposure risk.
- Tools/workflows: SOP-guided scene generation; checklists embedded in panoramas; integration with AR guidance.
- Assumptions/dependencies: Domain-specific realism (equipment layouts, signage); expert review; traceability between SOPs and scene elements.
Glossary
- Ablation study: A systematic evaluation that removes or adds components to measure their individual contributions. "Ablation study of different model components on text-to-panorama generation."
- Attention layers: Transformer modules that compute attention weights to integrate context across tokens. "with LoRA incorporated into the attention layers."
- BRISQUE: A no-reference image quality metric that assesses naturalness and distortions. "like FID, Inception Score, and BRISQUE."
- Circular padding: A wrap-around padding technique that copies edge content to preserve continuity across boundaries. "circular padding for boundary continuity,"
- CLIP Score: A metric that measures text–image alignment using the CLIP model’s embeddings. "CLIP Score"
- Cube loss: An auxiliary loss computed in the cubemap space to supervise distortion patterns and fine details. "cube loss for distortion awareness."
- Cube mapping: A representation of spherical panoramas as six planar faces to reduce distortion. "adopts cube mapping, which better aligns with the spherical geometry of panoramic images;"
- Cubemap: A six-face panoramic image representation corresponding to the faces of a cube. "The ERP panorama is converted into a cubemap,"
- Diffusion Transformer (DiT): A transformer-based diffusion architecture that denoises latent image tokens conditioned on text. "Revisit Diffusion Transformer (DiT)."
- Equirectangular projection (ERP): A 2D panoramic format mapping spherical coordinates to a rectangular image. "based on equirectangular projection (ERP)"
- FAED: An autoencoder-based metric used for evaluating panorama generation quality. "FAED~\citep{faed}"
- FID: Fréchet Inception Distance; a distributional measure of realism between generated and real images. "FID, Inception Score, and BRISQUE."
- Flow-based scheduler: A denoising schedule derived from rectified flow that controls the diffusion process over timesteps. "flow-based scheduler to progressively denoise the latent representation,"
- Inception Score: A metric evaluating generative image quality via classifiability and diversity using a pretrained Inception network. "FID, Inception Score, and BRISQUE."
- Inpainting: Filling in masked or missing regions of an image with plausible content. "inpainting and outpainting"
- Latent Diffusion Model (LDM): A diffusion approach that operates in the VAE’s latent space for efficient high-resolution generation. "Latent Diffusion Model (LDM)"
- Latent space: A compressed feature space (e.g., VAE latents) where diffusion denoising and supervision can be applied. "denoising in the latent space"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adapters into pretrained layers. "with LoRA incorporated into the attention layers."
- Matterport3D: A large, real-world panoramic dataset frequently used for training and evaluation. "Matterport3D validation set,"
- Mean squared error (MSE): A standard L2 regression loss used for supervising predicted noise or pixels. "mean squre error (MSE) loss"
- Narrow field of view (NFoV): A limited perspective crop or viewpoint used in outpainting-based panorama reconstruction. "narrow field of view (NFoV)"
- NIQE: Naturalness Image Quality Evaluator; a no-reference metric for image quality assessment. "NIQE"
- Outpainting: Extending an image beyond its current borders to synthesize new content consistently. "outpainting-based methods"
- Perspective image guidance: Using high-quality perspective images reprojected into panoramic space to improve photorealism. "perspective image guidance"
- Polar distortion: Severe geometric stretching near the top and bottom (poles) of ERP panoramas. "ensuring correct polar distortion"
- Q-Align: A quality assessment framework (with branches like quality and aesthetic) used to evaluate generated images. "quality branch of Q-Align"
- Reparameterized noise: Noise transformed via reparameterization used as targets/predictions in diffusion training. "reparameterized predicted noise"
- Rotary Positional Embeddings (RoPE): Positional encodings that inject coordinate-dependent rotations into token embeddings. "Rotary Positional Embeddings (RoPE)"
- Token-level supervision: Applying losses directly on latent tokens or noise predictions to enforce geometric and perceptual constraints. "token-level supervision in the latent space"
- Yaw loss: A loss enforcing consistency of predictions under rotations around the vertical (yaw) axis. "yaw loss for rotational robustness"
Collections
Sign up for free to add this paper to one or more collections.

