DeContext as Defense: Safe Image Editing in Diffusion Transformers (2512.16625v1)
Abstract: In-context diffusion models allow users to modify images with remarkable ease and realism. However, the same power raises serious privacy concerns: personal images can be easily manipulated for identity impersonation, misinformation, or other malicious uses, all without the owner's consent. While prior work has explored input perturbations to protect against misuse in personalized text-to-image generation, the robustness of modern, large-scale in-context DiT-based models remains largely unexamined. In this paper, we propose DeContext, a new method to safeguard input images from unauthorized in-context editing. Our key insight is that contextual information from the source image propagates to the output primarily through multimodal attention layers. By injecting small, targeted perturbations that weaken these cross-attention pathways, DeContext breaks this flow, effectively decouples the link between input and output. This simple defense is both efficient and robust. We further show that early denoising steps and specific transformer blocks dominate context propagation, which allows us to concentrate perturbations where they matter most. Experiments on Flux Kontext and Step1X-Edit show that DeContext consistently blocks unwanted image edits while preserving visual quality. These results highlight the effectiveness of attention-based perturbations as a powerful defense against image manipulation.
Sponsor






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about keeping people safe from malicious image edits made by powerful AI models. These models, called diffusion transformers (DiTs), can take a single photo and a short instruction (like “make this person look older”) and produce very realistic edited images. While that’s impressive, it also creates privacy risks: someone could take your picture from social media and use it to make deepfakes or impersonate you without your permission.
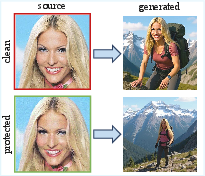
The authors propose a new defense technique called “DeContext.” It adds tiny, invisible changes to your image so that these editing models can’t copy your identity into the edited results, while still producing natural-looking images.
What questions did the researchers ask?
The researchers focused on three simple questions:
- How do modern image-editing AI models use your image to guide their edits?
- Can we stop these models from copying your identity into the edited image without making the picture look broken or weird?
- Where (inside the model) and when (during its steps) can we do the most effective protection?
How did they study it?
To make this easy to understand, imagine the AI model as a team working on a photo edit:
- It has “attention,” like a spotlight it uses to focus on important parts of your image.
- It looks at both your original photo (the “context”) and the picture it’s building (the “target”), and the spotlight helps it copy identity details from your photo into the new one.
The key idea in DeContext is to gently distract that spotlight so it stops copying your identity.
The problem: in-context editing and attention
“In-context editing” means the model edits a new image by referring to your photo directly, without retraining. The copying happens mostly through a part of the model called “multi‑modal attention” (think of it as a smart connection that lets the model look back and forth between your photo and the image it’s generating).
The idea: break the attention link
DeContext adds tiny, carefully designed changes (perturbations) to your input photo. These changes are too small for people to notice, but they’re shaped to weaken the attention link between the “target” (the image being generated) and the “context” (your photo). In simple terms: the model tries to look at your picture to copy identity, but we make that connection fuzzy so it can’t.
The authors discovered two important “sweet spots” for this defense:
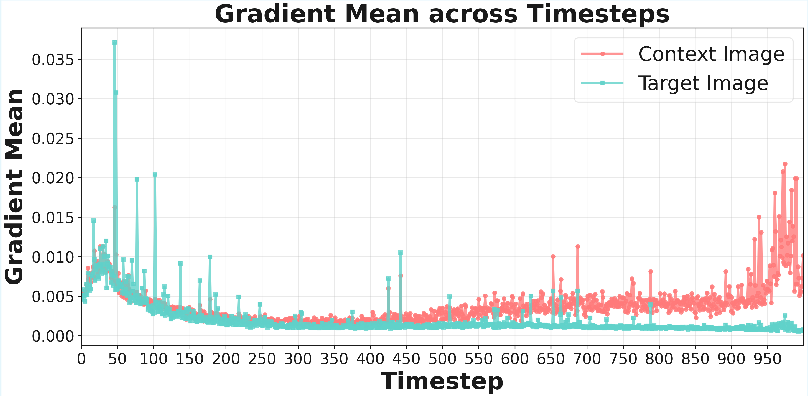
- Early steps of image generation: The model relies on your photo most at the beginning. Blocking attention there is powerful.
- Early-to-middle layers (“blocks”) of the transformer: These layers carry a lot of identity information. Targeting them is effective.
Making it robust
AI image generation is a bit random (different prompts, different noise seeds, different steps). To make the protection work broadly, DeContext practices against many cases:
- It trains the tiny changes using a random mix of prompts (like “add glasses”), random early steps, and random noise seeds.
- This makes the protection generalize, so it keeps working even if the attacker uses different instructions or random settings.
Importantly, DeContext does not change the AI model. It only alters the input image slightly, so it’s easy to use in practice.
What did they find?
The main results are:
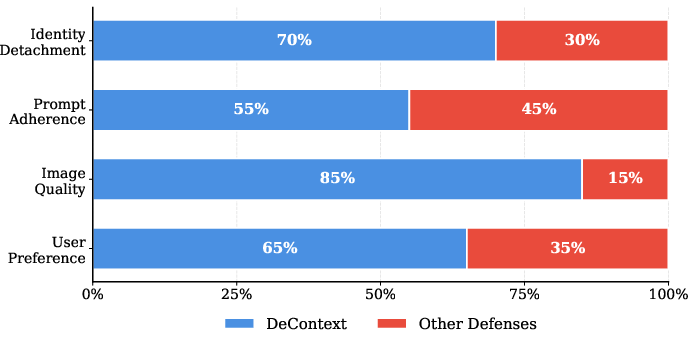
- DeContext strongly reduces identity copying. For faces, it causes a large drop (over 70% in some measures) in how often the edited image matches the original person’s identity.
- The edited images still look good. Compared to other defenses, DeContext keeps image quality high and avoids ugly artifacts (like strange colors, heavy noise, or broken textures).
- It works across different DiT-based editors. The method was tested on FLUX.1‑Kontext and Step1X‑Edit—two modern, powerful image-editing models—and performed well on both.
- Simple “naive” attacks (like standard adversarial methods) don’t work here. Just increasing the model’s loss produces blur or lighting changes but doesn’t stop identity copying. Targeting the attention mechanism is the key.
- Focusing on early generation steps and early-to-middle transformer layers is the most effective and efficient strategy.
In short: the defense successfully breaks the link between your photo and the edited result, without breaking the look of the final image.
Why does this matter?
This matters because:
- It helps protect people from deepfakes, identity impersonation, and misinformation generated from publicly shared photos.
- It offers a practical way to safeguard privacy without ruining the image (important if people still want to share photos online).
- It’s tailored to modern, transformer-based diffusion models, which are quickly becoming the standard in image generation and editing.
Potential impact and future directions
- DeContext could be integrated into photo-sharing tools or camera apps, adding an invisible “shield” to posted images.
- It could help artists, creators, and everyday users prevent unauthorized style or identity cloning.
- The authors want to make it faster and stronger, especially for “black-box” situations (when the attacker’s model is unknown or hidden), which is closer to real-world conditions.
Overall, DeContext is a smart, targeted defense that keeps the good (natural-looking edits) while blocking the bad (identity theft), and it’s a step toward safer AI image tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to enable concrete follow-up research.
- Domain generalization beyond faces: effectiveness on non-facial content (objects, scenes, artworks, logos), cluttered multi-object scenes, and varied styles is only briefly mentioned in the appendix and not systematically evaluated.
- Multi-context and multi-modal conditioning: protection is demonstrated for single reference images; robustness against multiple context images, multi-modal conditions (e.g., segmentation maps, ControlNet features, style tokens), or mixed text+visual conditioning remains untested.
- Architectural coverage: evaluation is limited to FLUX.1-Kontext-dev and Step1X-Edit; transferability to other DiT variants (e.g., Qwen-Image), hybrid DiT–UNet architectures, and future attention designs (flash attention, grouped attention, memory tokens) is unknown.
- Black-box applicability: DeContext assumes white-box access to attention maps and model gradients; methods for query-efficient, gradient-free black-box defense against commercial API endpoints are not provided.
- Robustness to image post-processing: no tests for survival under common real-world transformations (JPEG/WebP compression, resizing/cropping, color space changes, filters, gamma/contrast adjustments, metadata stripping, social media pipelines, screenshots, and print–rephotograph scenarios).
- Geometric transform robustness: susceptibility to rotation, scaling, perspective warp, and mild face alignment changes is not studied, despite known fragility of pixel-space adversarial perturbations.
- Attacker adaptation: no evaluation of adversaries who counteract the defense by pre-processing (denoising, smoothing, super-resolution), prompt engineering (identity-amplifying prompts), repeated sampling, multi-context fusion, or robust training against such perturbations.
- Theoretical guarantees: the claim that multi-modal attention is the exclusive path for context propagation is supported empirically but lacks a formal analysis or proof across DiT architectures and training regimes.
- Automatic block/timestep selection: early-to-mid blocks and high-noise timesteps are found empirically; an algorithmic procedure to identify critical layers/timesteps in unknown models without full access is missing.
- Noise budget and perceptual invisibility: the default budget ε=0.1 in 0,1 can be perceptible; rigorous psychophysical user studies and perceptual metrics (e.g., LPIPS, DISTS, SSIM) are needed to calibrate truly imperceptible budgets.
- Runtime and practicality: 800 optimization steps on an A800 GPU per image is heavy; quantifying wall-clock time, memory footprint, and proposing lightweight or one-shot variants suitable for consumer devices is not addressed.
- Selective protection vs. blanket detachment: the method detaches all context influence; mechanisms to selectively block identity transfer while preserving benign attribute edits (e.g., “add glasses”) are not explored.
- Cross-language and OOD prompts: training with a pool of 60 English prompts leaves generalization to other languages, longer compositional instructions, or domain-specific prompt distributions (medical, fashion, art) unquantified.
- Demographic fairness: protection efficacy across age, gender, skin tones, and facial attributes is not analyzed; VGGFace2 and CelebA-HQ subsets (50 identities) are small and may not be representative.
- Identity metrics coverage: reliance on ArcFace and CLIP-I may bias conclusions; testing with multiple SOTA FR models (AdaFace, MagFace, CurricularFace), face re-identification protocols, and human identity judgments is missing.
- Harm-targeted evaluation: despite framing around violent/sexual/misleading edits, there is no task-based evaluation of impersonation risk, misinformation propagation, or downstream harms prevented by DeContext.
- High-resolution images: experiments focus on 512×512 crops; scalability and efficacy at higher resolutions typical of modern DiT models (e.g., 1024–2048 px) are not measured.
- Transfer to video and 3D: extension to video diffusion transformers, temporal consistency, and 3D/NeRF-based generation/editing defenses is left unexplored.
- Interaction with training-time personalization: impact of DeContext-protected images on fine-tuning-based personalization (DreamBooth, LoRA) and whether it degrades those pipelines is not evaluated.
- Detectability and forensics: whether the perturbations are detectable by forensic tools or content moderation systems, and whether attackers can reliably detect and strip them, is not studied.
- Compatibility with benign ML workflows: potential side effects on other computer vision tasks (e.g., face detection, aesthetic scoring, photo enhancement) used by social platforms or camera apps are not assessed.
- Robustness to model updates: as DiT models evolve (new checkpoints, sampling schedules, conditioning strategies), how often the defense must be re-optimized per image and whether universal perturbations can remain effective is unclear.
- Authorized-use mechanisms: no mechanism for the owner to enable trusted editors (e.g., via embedded cryptographic tags or watermarks) while blocking unauthorized editing is proposed.
- Evaluation protocol completeness: FDFR is near zero for all settings and may not reflect identity removal; adopting stronger identity/non-identity decision metrics or task-level impersonation tests would strengthen claims.
Glossary
- Adversarial attacks: Methods that craft small, often imperceptible perturbations to cause model errors or undesired behaviors. "Adversarial attacks aim to find imperceptible noise that alter a model's prediction."
- ArcFace: A face recognition model used to produce identity embeddings for comparing faces. "We use Identity Score Matching (ISM) to compute the distance between ArcFace~\cite{ArcFace} embeddings, with smaller values indicating greater identity change."
- Attention intervention: A strategy that directly modifies or removes attention components to change model behavior. "Study II: Attention Intervention Works."
- Attention map: The matrix of attention weights derived from query–key interactions in transformers. "We consider attention computation to only the rows of the attention map corresponding to target-image queries :"
- Attention weights: Scalars that determine how strongly one token attends to another in attention mechanisms. "In dual-stream I2I models, cross-attention layers explicitly mediate context-target interactions, with attention weights determining conditioning strength."
- BRISQUE: A no-reference image quality metric that evaluates distortions in the spatial domain. "measured by SER-FQA~\cite{SER-FIQ} (face-specific), BRISQUE~\cite{BRISQUE} (perceptual) and FID (statistical realism)."
- CelebA-HQ: A high-quality face image dataset widely used for benchmarking generative models. "Experiments are conducted on high-quality face images derived from two datasets: VGGFace2~\cite{cao2018vggface2datasetrecognisingfaces} and CelebA-HQ~\cite{liu2015deeplearningfaceattributes}."
- CLIP Image Similarity (CLIP-I): A metric that measures semantic similarity between images using CLIP embeddings. "For I2I tasks, we additionally compute CLIP Image Similarity (CLIP-I), which measures semantic similarity between source and generated images."
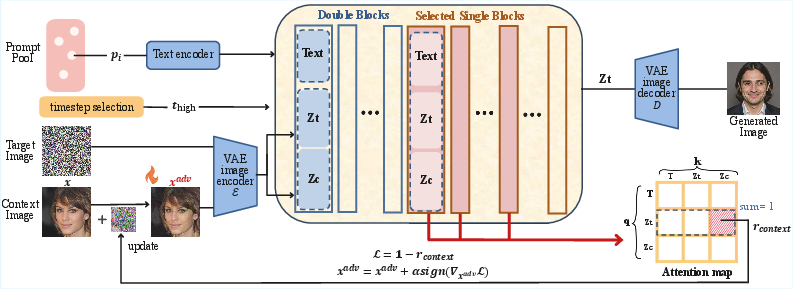
- Concentrated detachment: Targeting perturbations to key timesteps and blocks to suppress context without degrading quality. "we propose an approach known as concentrated detachment, which focuses on retaining information solely at certain important locations, without compromising the quality."
- Context proportion: The average attention weight from target queries to context tokens, quantifying context influence. "We next define the context proportion $r_{\text{ctx}$, which measures the average attention weight from target queries to context keys:"
- Cross-attention: An attention mechanism that connects different token streams (e.g., target to context) to integrate information. "Transformer-based diffusion architectures rely on cross-attention to integrate multimodal inputs"
- Cross-attention pathways: The specific attention connections through which context information affects generation. "By injecting small, targeted perturbations that weaken these cross-attention pathways, DeContext breaks this flow, effectively decouples the link between input and output."
- Denoising timesteps: Iterations in diffusion where noise is progressively removed to reconstruct the image. "We further show that early denoising steps and specific transformer blocks dominate context propagation"
- Diffusion Transformer (DiT): A transformer-based diffusion architecture that replaces the UNet backbone. "Built on diffusion transformer~(DiT) architectures and trained at scale, they produce high-fidelity, diverse images"
- Dual-stream architecture: A model design where text and image tokens are processed in separate streams. "do not account for how contextual information propagates through the dual-stream architecture."
- Face Detection Failure Rate (FDFR): The fraction of samples where an automated detector fails to find a face. "We use Face Detection Failure Rate (FDFR) to measure the percentage of samples where RetinaFace~\cite{retinaface} fails to detect a face."
- FID: Fréchet Inception Distance; a statistic that evaluates realism by comparing feature distributions. "BRISQUE~\cite{BRISQUE} (perceptual) and FID (statistical realism)."
- FLUX-Kontext: A DiT-based in-context image editing model used as a primary evaluation target. "Following FLUX-Kontext~\cite{flux1kontext}, we consider image generation conditioned on a text prompt and context image "
- Gaussian noise: Random noise sampled from a normal distribution often used in diffusion initialization. "we also approximate the target image with random Gaussian noise "
- Identity Score Matching (ISM): A metric that measures identity change via distances between face embeddings. "We use Identity Score Matching (ISM) to compute the distance between ArcFace~\cite{ArcFace} embeddings"
- Image-to-image (I2I) models: Generative models that transform or synthesize images conditioned on other images. "these image-to-image (I2I) models directly condition generation on context images at inference time."
- In-context learning: Using examples at inference time to condition a model without fine-tuning. "Very recently, a new paradigm emerges: editing as in-context learning."
- InstructPix2Pix: An instruction-following image editing model used for baseline comparisons. "I2I defense: FaceLock~\cite{wang2025editawayfacestay} for InstructPix2Pix~\cite{instructP2P}."
- Multi-Modal Attention (MMA): Attention over concatenated text, target, and context tokens to integrate modalities. "DiTs integrate multi-modal information through multi-modal attention (MMA) by concatenating tokens from text, target, and context:"
- Norm ball: A constraint set (ℓp-ball) limiting the magnitude of adversarial perturbations. "It gradient steps followed by projection onto the norm ball."
- Projected Gradient Descent (PGD): An iterative adversarial optimization with projection back into a constraint set. "The standard tool is Projected Gradient Descent (PGD)~\cite{pgd}."
- Query–key embeddings: The vectors used in attention to compute similarities between queries and keys. "we consider the query and key embeddings, "
- Rectified flow-matching objective: A training objective aligning predicted velocity fields with noise-data differences. "The model approximates the conditional distribution via a rectified flow-matching objective:"
- RetinaFace: A face detection model used to evaluate face presence in generated images. "We use Face Detection Failure Rate (FDFR) to measure the percentage of samples where RetinaFace~\cite{retinaface} fails to detect a face."
- SER-FQA: A face-specific no-reference image quality assessment metric. "measured by SER-FQA~\cite{SER-FIQ} (face-specific), BRISQUE~\cite{BRISQUE} (perceptual) and FID (statistical realism)."
- Step1X-Edit: A DiT-based image editing model used to test defense generalization. "Step1X-Edit~\cite{step1xedit} is another DiT-based model designed for image editing."
- Text-to-image (T2I): Generative models that create images from text prompts. "Unlike T2I approaches requiring fine-tuning"
- Transformer block: A component of transformers that contains attention and feed-forward layers. "Within a transformer block, we consider the query and key embeddings"
- UNet: A convolutional encoder–decoder architecture formerly common in diffusion models. "Recent diffusion transformers (DiTs) replace the UNet backbone with a transformer that jointly processes text and image tokens."
- VAE: Variational Autoencoder used to encode images into latents for diffusion models. "where both and are encoded by a frozen VAE $\mathcal{E}_{\text{vae}$"
- VGGFace2: A large-scale face dataset used for evaluating identity-related tasks. "Experiments are conducted on high-quality face images derived from two datasets: VGGFace2~\cite{cao2018vggface2datasetrecognisingfaces} and CelebA-HQ~\cite{liu2015deeplearningfaceattributes}."
Practical Applications
Overview
This paper introduces DeContext, an attention-aware, inference-time defense for Diffusion Transformer (DiT)–based in-context image editors (e.g., FLUX.1-Kontext, Step1X-Edit). It injects imperceptible perturbations into an image to suppress multimodal cross-attention from target queries to context keys, effectively detaching the generated output from the source image’s identity/style while preserving visual quality. The method focuses on early denoising steps and early-to-mid transformer blocks, and it generalizes across prompts and seeds via randomized optimization.
Below are actionable, real-world applications derived from the paper’s findings, with sector mapping, example tools/workflows, and key assumptions/dependencies.
Immediate Applications
- Social media “Protect my photo” upload option
- Sector: Consumer platforms, social media
- What: Server-side microservice that automatically applies DeContext to profile photos and posts, reducing risk of identity cloning and malicious edits by in-context editors.
- Tools/workflows: Image-processing pipeline plugin, REST API/SDK for media ingestion services, CDN-side worker (e.g., Cloudflare/Akamai) for on-the-fly protection.
- Assumptions/dependencies: Perturbations must survive platform recompression, resizing, and light crops; model-agnostic or surrogate-model perturbations needed for black-box threats; user experience must balance artifact budget η to preserve aesthetics.
- Messaging and photo-sharing apps “AI-edit shield”
- Sector: Mobile apps, communications
- What: Optional toggle that applies DeContext locally before sending attachments.
- Tools/workflows: On-device SDK (CoreML/NNAPI/Metal) backed by a light surrogate DiT; offline batch pre-processing of camera roll favorites.
- Assumptions/dependencies: Compute and battery constraints; need efficient, possibly universal or cached per-user perturbations; resilience to subsequent compression by messaging platforms.
- Newsroom and wire service editorial photo protection
- Sector: Media and journalism
- What: Default protection on outgoing editorial photos (politicians, journalists, conflict reporting) to deter deepfake repurposing.
- Tools/workflows: CMS/DAM plug-in that applies DeContext at export; integration with C2PA metadata pipeline.
- Assumptions/dependencies: Must maintain print/web quality; perturbation must survive syndication workflows (format conversion, cropping) and be robust across multiple downstream edits.
- Stock photo agencies and licensing platforms
- Sector: Stock media, creative marketplaces
- What: “Protected license” tier where previews and web-resolution assets carry DeContext to prevent identity/style theft while preserving sale value.
- Tools/workflows: Batch processor in ingestion pipeline; buyer workflow to obtain clean originals under contract.
- Assumptions/dependencies: Protection should target in-context editing misuse while minimally affecting legitimate creative uses; terms-of-service and UI must clarify behavior.
- Brand and product image protection for e-commerce
- Sector: Retail, advertising
- What: Protect product shots and branded assets from realistic in-context restyling that misleads consumers.
- Tools/workflows: Headless CMS/DAM extension for catalogs; pre-publish processing for marketplace images.
- Assumptions/dependencies: Most results shown on faces; object-level efficacy likely but may require parameter tuning; robustness to aggressive background removal and scaling.
- Celebrity/talent management and PR assets
- Sector: Entertainment, sports, public relations
- What: Protect headshots and press kits to reduce impersonation and reputational harm.
- Tools/workflows: Client portal offering protected exports; batch processing for archives.
- Assumptions/dependencies: Legacy unprotected images may still circulate; efficacy depends on widespread adoption by media partners.
- Enterprise identity protection (employee directories, exec bios)
- Sector: Corporate communications, cybersecurity
- What: Protect publicly accessible employee headshots to reduce social-engineering deepfakes.
- Tools/workflows: HR portal integration; SSO-protected DAM with automatic DeContext on public renditions.
- Assumptions/dependencies: Visibility of artifacts must be negligible in corporate branding; ensure compatibility with accessibility and HRIS workflows.
- Dataset publishing with built-in misuse deterrence
- Sector: Academia, open data portals
- What: Release face/object datasets with DeContext to deter identity/style cloning while keeping images usable for non-identity research.
- Tools/workflows: Batch protector with documented budgets; dataset cards noting the defense and its implications.
- Assumptions/dependencies: Not suitable for tasks requiring preserved identity; research users must consent to protected versions; mismatch vs. some evaluation protocols (e.g., FID trained on clean faces).
- Safety wrappers for in-context editing APIs
- Sector: AI model providers, MLOps
- What: Pre-ingestion filter that (a) automatically applies DeContext to user-specified “protected” context images, or (b) warns/rejects when context images appear protected by a known policy.
- Tools/workflows: Gateway service in front of editing endpoints; policy controls and logging; “protected upload” SDKs.
- Assumptions/dependencies: Providers need opt-in detection heuristics or metadata; some perturbations are intentionally imperceptible and not signature-based.
- Creative software plug-ins
- Sector: Software (Photoshop, Lightroom, Affinity, Figma)
- What: “Safe Share” plug-in to export web-ready, DeContext-protected images.
- Tools/workflows: Cross-platform plug-in; CLI for batch/post pipeline.
- Assumptions/dependencies: Asset pipelines vary; need consistent protection under different export settings.
- Consumer browser extension or mobile app
- Sector: Consumer privacy tech
- What: One-tap protection before posting to social platforms; presets for “low/medium/high” protection budgets.
- Tools/workflows: Edge inference or cloud-backed processing; automatic detection of upload forms.
- Assumptions/dependencies: Must handle various image transformations applied by platforms; user trust depends on minimal visible changes.
- Compliance and risk mitigation for platforms
- Sector: Policy, trust & safety, legal
- What: Adopt DeContext as part of privacy-by-design measures for minors and high-risk groups; reduce liability associated with platform-enabled misuse.
- Tools/workflows: Policy toggle for default protection in select geographies; auditable logs and consent UX.
- Assumptions/dependencies: Legal frameworks (GDPR/CCPA/online safety acts) and user consent mechanisms; platform performance and UX trade-offs.
Long-Term Applications
- Model-agnostic, black-box robust protection
- Sector: AI safety, cybersecurity
- What: Universal or transfer-based perturbations that reliably detach context across diverse, proprietary DiT editors without white-box access.
- Tools/workflows: Surrogate-model training, expectation-over-transformations (EoT), population-based search.
- Assumptions/dependencies: Arms race with purification/denoising defenses; continued architectural evolution (e.g., multi-stage editors).
- Video-level protection
- Sector: Social media, entertainment, journalism
- What: Temporally consistent DeContext for videos to thwart person/style transfer in video editors.
- Tools/workflows: Frame-wise/sequence-aware optimization; optical-flow–aware regularization; robustness to heavy compression.
- Assumptions/dependencies: Temporal coherence and perceptual quality must be preserved; computational cost is significant.
- Camera/OS-level “AI-edit shield” defaults
- Sector: Mobile OEMs, operating systems
- What: ISP/OS share-sheet integration to apply lightweight, on-device protection at capture or share time.
- Tools/workflows: Hardware acceleration; efficient approximations/universal perturbations; user policy profiles.
- Assumptions/dependencies: Must be extremely efficient and power-frugal; broad model transferability required.
- Standardization with C2PA and “Do-Not-Clone” signals
- Sector: Policy, standards bodies, media tech
- What: Combine perturbation-based defenses with cryptographic provenance (C2PA) and standardized “do-not-clone” metadata.
- Tools/workflows: Reference implementations, compliance tests, ecosystem-wide adoption.
- Assumptions/dependencies: Cross-industry consensus; mixed incentives among platforms and model providers.
- Enterprise “Image DRM 2.0”
- Sector: IP protection, licensing
- What: Rights management suite combining DeContext, watermarking, and usage analytics to protect identity/style and enforce licenses.
- Tools/workflows: Rights-aware CDNs, license-gated originals, legal telemetry.
- Assumptions/dependencies: Legal enforceability; determination of “misuse” in edge cases.
- Protection resilient to real-world transformations
- Sector: All sectors using web imaging
- What: Methods robust to resizing, cropping, color/contrast changes, heavy JPEG/WebP/AVIF compression.
- Tools/workflows: Transformation-aware optimization; robustness benchmarking suites.
- Assumptions/dependencies: Trade-offs with image quality and universality; ongoing updates as platforms evolve.
- Co-design with model-side safeguards
- Sector: AI providers
- What: Model architectures that detect and honor protected images (e.g., attenuate cross-attention to context when protection is present).
- Tools/workflows: “Respect protection” policy modules; multi-signal safety layers combining adversarial and metadata cues.
- Assumptions/dependencies: Requires provider cooperation; potential revenue tensions with editing capability.
- Sector-specific protections (healthcare, education, gov)
- Sector: Healthcare (patient images), education (student media), public sector (press releases)
- What: Default protection for sensitive populations to prevent identity misuse in educational/clinical contexts and public communications.
- Tools/workflows: Policy-based auto-protection; consent and exception workflows.
- Assumptions/dependencies: Domain regulations (HIPAA/FERPA/FOIA); must verify protection does not hinder legitimate clinical/educational utility.
- Insurance and risk services
- Sector: Cyber/identity insurance
- What: Offer DeContext-backed “identity media protection” as part of identity-theft and brand-reputation coverage.
- Tools/workflows: Risk scoring, protected asset management, incident response playbooks.
- Assumptions/dependencies: Efficacy evidence for actuarial models; user adoption and correct configuration.
- Educational and research infrastructure
- Sector: Academia
- What: Curriculum, benchmarks, and interpretability tooling for attention-based defenses; standardized evaluation of cross-attention suppression across models.
- Tools/workflows: Open datasets with protected variants, leaderboards, teachable notebooks on attention dynamics.
- Assumptions/dependencies: Community adoption; evolving DiT architectures may shift best practices.
- Regulatory frameworks mandating protective defaults
- Sector: Public policy
- What: Policies requiring platforms/AI providers to offer and respect protective mechanisms for images, especially of minors and public officials.
- Tools/workflows: Audits, disclosures, conformance tests, safe defaults for high-risk categories.
- Assumptions/dependencies: Political will and international alignment; clear definitions and enforcement mechanisms.
Notes on feasibility across applications:
- Threat model fit: DeContext targets in-context DiT editors; it may be less effective against fine-tuned personalization pipelines or purification-based countermeasures without further research.
- Visibility vs. protection: Higher budgets improve protection but risk artifacts; careful default tuning and QA are required per sector.
- Black-box/transfer: The paper shows transfer to another DiT (Step1X-Edit), but robust, vendor-agnostic protection remains an open research area.
- Transform robustness: Survival through common web transforms (compression, scaling, slight crops) is essential; transformation-aware optimization may be needed in production.
Collections
Sign up for free to add this paper to one or more collections.