gridfm-datakit-v1: A Python Library for Scalable and Realistic Power Flow and Optimal Power Flow Data Generation
Abstract: We introduce gridfm-datakit-v1, a Python library for generating realistic and diverse Power Flow (PF) and Optimal Power Flow (OPF) datasets for training Machine Learning (ML) solvers. Existing datasets and libraries face three main challenges: (1) lack of realistic stochastic load and topology perturbations, limiting scenario diversity; (2) PF datasets are restricted to OPF-feasible points, hindering generalization of ML solvers to cases that violate operating limits (e.g., branch overloads or voltage violations); and (3) OPF datasets use fixed generator cost functions, limiting generalization across varying costs. gridfm-datakit addresses these challenges by: (1) combining global load scaling from real-world profiles with localized noise and supporting arbitrary N-k topology perturbations to create diverse yet realistic datasets; (2) generating PF samples beyond operating limits; and (3) producing OPF data with varying generator costs. It also scales efficiently to large grids (up to 10,000 buses). Comparisons with OPFData, OPF-Learn, PGLearn, and PF$Δ$ are provided. Available on GitHub at https://github.com/gridfm/gridfm-datakit under Apache 2.0 and via pip install gridfm-datakit.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “gridfm-datakit-v1” in simple terms
Overview: What is this paper about?
This paper introduces a free, open-source Python tool called gridfm-datakit. It helps researchers and engineers create big, realistic datasets about how electricity moves through large power grids. These datasets are used to train and test ML models that try to predict or optimize how power flows across the grid.
Think of a power grid like a giant road network:
- Buses are like intersections.
- Transmission lines are like roads.
- Power flow is like traffic flow (how cars move through the network).
- Optimal power flow (OPF) is like finding the cheapest, safest way to send all cars where they need to go without breaking rules (like speed limits).
Gridfm-datakit makes “practice problems” for ML models, so they can learn to be fast and accurate when the real grid changes.
Goals: What questions are the authors trying to answer?
The paper tackles three practical problems:
- How can we generate large, realistic, and diverse training data for power grid ML models without spending huge amounts of time and money?
- How can we include both normal situations and unusual ones (like equipment failures or overloads), so ML models can handle real-life surprises?
- How can we make datasets that cover many different market conditions (like changing generator costs), not just one fixed setup?
Approach: How does gridfm-datakit work?
To keep this simple, here are the key ideas behind the tool, explained with everyday analogies:
- Realistic loads (electricity demand):
- The tool uses real-world “daily patterns” of electricity demand (like how cities use more electricity in the evening) and then adds small, random changes for each location. This is like saying “everyone in the city turns on more lights after sunset,” but each neighborhood still behaves a bit differently.
- This mix creates data that looks realistic across time and space.
- Topology changes (grid structure changes):
- In real life, lines or transformers can be turned off, fail, or be under maintenance. The tool can simulate not just one outage (called “N-1”) but many at once (“N-k”). That’s like closing multiple roads and seeing how traffic reroutes.
- It also slightly changes line properties (resistance/reactance), which is like saying some roads get a bit rougher or smoother, affecting how fast cars can go.
- Generator settings and costs:
- The tool can solve the OPF problem to get the cheapest, rule-following generator settings.
- And unlike many other tools, it changes generator costs between scenarios. That’s like gas prices moving around — it tests if your model can still make good decisions when costs change.
- Two data modes:
- OPF mode: everything follows all the rules (like voltage limits and line limits). Good for training optimization models.
- PF mode: starts with a good plan, then changes the grid and runs power flow without re-optimizing generators. This naturally creates some rule violations (like overloads) that happen in real life when the grid changes unexpectedly. Good for training models that must handle “oops” moments.
- Scale and speed:
- It works on very large grids: up to 30,000 buses for power flow and 10,000 buses for OPF.
- It’s fast enough to produce hundreds of thousands of examples in hours (instead of many weeks).
- Easy to use:
- You can run it with a simple command line or an interactive notebook.
- It also saves “baseline” results (DC-PF and DC-OPF) so you can compare ML models to standard methods easily.
- It includes tools to check that datasets are correct and to get statistics (like how many overloads happened).
Findings: What did the authors learn, and why is it important?
- More realistic and diverse data:
- Compared to other libraries, gridfm-datakit produces datasets with better variety in important features (like generator outputs and line flows), largely because it uses real demand patterns, changes line properties, varies generator costs, and simulates multiple outages.
- The balance of normal vs. violating scenarios looks more like real operations — not all samples break the rules, but enough do to train models to be robust.
- Scales to big grids:
- It can handle thousands to tens of thousands of buses and still generate lots of data quickly. This is crucial for training modern ML models that need lots of examples.
- Better generalization:
- Because it includes realistic demand, topology changes, and cost variation, ML models trained on this data are more likely to work well across different grids and market conditions.
- Reproducible and fair:
- Everyone can use the same tool to build similar datasets, making it easier to compare models fairly and repeat results — a big deal in science.
Impact: Why does this matter for the real world?
- Training stronger ML tools:
- With better data, ML models can learn to predict and optimize grid behavior faster and more reliably, which could help grid operators make better decisions under pressure.
- Handling surprises:
- By including realistic violations, the datasets prepare ML models for unexpected events — like outages or sudden demand spikes — improving resilience.
- Research acceleration:
- It lowers the barrier to entry so more teams can work on grid ML without investing massive computing resources. That speeds up innovation.
- Building foundation models:
- The companion library, gridfm-graphkit, turns these datasets into graph-based formats for training powerful models (Graph Neural Networks and Graph Transformers) that can be reused and adapted to many tasks, like contingency analysis or fast power flow.
In short, gridfm-datakit helps the power systems community build better, fairer, and more practical ML solutions by giving them the realistic data they’ve been missing.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
The paper introduces gridfm-datakit and outlines initial capabilities and planned features. The following list distills concrete gaps and open questions that remain unaddressed, to guide future research and development:
- Realism validation: no quantitative calibration of generated distributions (loads, voltages, flows, violations) against real SCADA/EMS data, nor statistical goodness-of-fit tests across grids and seasons.
- Parameter calibration and sensitivity: no principled method or sensitivity analysis for setting key parameters (e.g., local load noise σ, admittance scaling σ, global scaling bounds l/u, cost scaling factors), and how they affect convergence, violation rates, and diversity.
- Violation targeting: lacks controls to specify and achieve target proportions/types of violations (e.g., voltage violations vs. thermal overloads) in PF mode; no conditional generation to steer constraint violation mix.
- Outage realism: N–k topology perturbations are random or exhaustive without weather-, maintenance-, or protection-driven correlation models; no incorporation of historical outage statistics or spatial clustering.
- Admittance perturbation validity: uniform scaling of R/X may produce non-physical branch parameters (e.g., unrealistic X/R ratios); no constraints to preserve manufacturer specs, thermal dependence, or tap-shift effects.
- Market and dispatch realism: generator cost permutations/scalings may not reflect market bids, fuel price volatility, or unit commitment; no multi-period OPF with ramping, min up/down times, or startup costs.
- Security-constrained OPF: no SCOPF or N–1-secure dispatch generation, limiting realism for operations under contingency criteria.
- DER and IBR modeling: absence of inverter-based resources, voltage control modes, reactive capability curves, HVDC, FACTS, phase-shifting transformers, and their impact on OPF/PF states and diversity.
- PF mode operational responses: fixing dispatch before topology changes omits automatic generation control (AGC), governor action, reactive support, OLTC/tap changer operations, and protection-induced reconfiguration—potentially yielding unrealistic post-contingency states.
- Diversity metrics: reliance on normalized Shannon entropy lacks complementary measures (e.g., coverage of feasible region, mutual information, redundancy, rare-event coverage); no demonstrated link between data diversity and ML performance gains.
- Downstream impact: no empirical evidence that datasets improve ML solver generalization, robustness, or transferability; missing controlled ablation studies across libraries, grids, and tasks.
- Scaling details: large reported CPU-hours at 10k-bus scale without guidance on HPC parallelization, distributed solving strategies, memory footprints, or queue management; unclear failure handling and reproducibility across environments.
- Solver dependence and numerical robustness: exclusive reliance on PowerModels.jl without cross-verification against alternative AC PF/OPF solvers (e.g., MATPOWER, PSS/E); no analysis of solver parameter choices or conditioning issues.
- Non-convergence characterization: convergence rates reported but no breakdown by perturbation type, grid size, or parameter settings; missing strategies for robust recovery on ill-conditioned cases.
- Load profile mapping: global aggregated profiles applied uniformly with local noise; absent bus-level load profiles, spatial correlation models, sectoral heterogeneity, and network-constrained allocation methods.
- Reactive power and bus-type handling: unspecified PV–PQ switching policy during PF, slack bus treatment consistency, generator capability curve enforcement statistics, and frequency of reactive limit hits.
- Thermal ratings and weather: static limits used; no dynamic line rating (DLR), temperature-dependent impedance, wind cooling, or transformer thermal models—despite references motivating their importance.
- Topology sampling biases: feasibility checks avoid islanding but do not control for graph-theoretic properties (e.g., cutsets, bridges, articulation points); unclear coverage of structurally critical configurations.
- Pg diversity challenge: although cost permutations increase diversity, Pg diversity remains low; no method proposed to enhance Pg variability without sacrificing realism (e.g., multi-scenario bidding or UC constraints).
- Dataset design guidance: no prescriptions for composing datasets (mix of OPF/PF samples, N–k levels, cost scenarios) tailored to specific ML tasks (PF regression, contingency screening, LMP prediction).
- Benchmarking standardization: DC-PF/DC-OPF results are stored but not evaluated for accuracy vs AC; no standardized train/validation/test splits across grids/topologies or public leaderboards.
- Temporal structure: samples are independent; no multi-step time series with ramping, commitment states, or temporal consistency for training sequence models and foundation models on dynamics.
- Dual variables and economics: duals/LMPs not yet saved, hindering primal-dual learning, market analysis, and constraint shadow-price studies.
- Distribution grid applicability: focus on transmission; missing support for radial distribution networks with regulators, voltage-dependent loads, DER, and protection schemes.
- Element coverage clarity: support for shunts, PSTs, OLTCs, switched caps/reactors not specified; their absence limits realism of voltage control and reactive power management.
- Data validation scope: CLI verifies internal consistency but not physical plausibility of modified parameters (e.g., admittances after scaling), tap positions, or generator capability curve adherence.
- Interoperability and formats: unclear support for standard data models and ML-friendly formats (e.g., CIM, HDF5, Parquet), schema versioning, and metadata needed for long-term curation.
- Real-grid generalization: datasets use PGLib and synthetic profiles; no evidence of transferability to operational utility networks or privacy-preserving calibration methods.
- Release of large datasets: promised open-sourcing to HuggingFace not yet realized; no documented size, schema, and quality checks for public large-scale datasets.
- graphkit utilization: gridfm-graphkit described but lacks end-to-end demonstrations, pretrained models, standardized training recipes, or zero-shot/fine-tuning results on unseen topologies.
- Ethical and security dimensions: cyber-physical threats, protection misoperation, and adversarial scenarios referenced in citations but not modeled within data generation pipeline.
Practical Applications
Immediate Applications
The following applications can be deployed today using the library’s released features (PF/OPF data generation at scale, hybrid load perturbations, N−k topology/admittance perturbations, PF mode with operating-limit violations, OPF mode with diverse cost functions, CLI/interactive interfaces, dataset validation/stats, and integration with gridfm-graphkit).
- High-throughput scenario generation for contingency analysis triage (Energy; TSO/ISO; utility operations)
- What it enables: Generate large, diverse AC PF datasets with realistic N−k topology and admittance perturbations to train fast ML surrogates that pre-screen and rank contingencies before expensive AC-OPF/AC-PF runs.
- Tools/workflows:
gridfm-datakit(scenario factory) → ML surrogate viagridfm-graphkit→ EMS pre-screening pipeline with periodic retraining. - Assumptions/dependencies: Steady-state focus (no dynamics); representativeness of base grid model and limits; solver convergence for large grids; operational acceptance of ML pre-screeners.
- Rapid OPF/PF surrogate modeling for planning and markets (Energy, Software/AI)
- What it enables: Train graph neural surrogates to approximate AC-OPF objectives/constraints across cost permutations and N−k states; accelerate studies like congestion assessment, remedial action screening, and day-ahead sensitivity probes.
- Tools/workflows: Cost-permuted OPF datasets → GNN/transformer surrogates (PyTorch Geometric via
gridfm-graphkit) → “what-if” analysis tooling in planning desks. - Assumptions/dependencies: Diversity of cost and topology scenarios matches user’s markets/planning needs; calibration against select ground-truth AC runs.
- Screening tools for interconnection studies and hosting capacity (Energy; transmission planning; renewables integration)
- What it enables: Use synthetic OPF datasets covering wide load/topology/cost ranges to train capacity/violation predictors that quickly flag feasible/critical POIs for detailed study, helping triage interconnection queues.
- Tools/workflows: Region-specific profiles (e.g., ERCOT aggregated load) → large OPF PF/OPF datasets → featurized hosting-capacity ML → study prioritization dashboard.
- Assumptions/dependencies: Mapping from aggregated load profiles to bus-level scaling is reasonable; base case reflects network protections/limits; regulatory process still requires detailed studies.
- Operator training and “near-miss” library creation (Energy; control rooms; vendor simulators)
- What it enables: Create balanced sets of in-limit and out-of-limit steady-state conditions (violations emerge naturally via PF mode) for simulator drills, SOP validation, and alarm rationalization.
- Tools/workflows:
gridfm-datakitPF mode → curated scenario packs → LMS/simulator ingestion; use built-in validation/stats for quality gates. - Assumptions/dependencies: Scenarios are steady-state; do not substitute for transient/relay studies; alignment with actual protection settings needed.
- Benchmarking and reproducible ML research in PF/OPF (Academia; open benchmarking; software)
- What it enables: Standardized, scalable datasets for head-to-head comparison of PF/OPF ML methods; inclusion of DC-PF/DC-OPF baselines and automatic validation promotes fair comparisons and ablations.
- Tools/workflows: Dataset generation scripts + stats/validation +
gridfm-graphkittraining recipes; dataset publication with configs for reproducibility. - Assumptions/dependencies: Community adoption and consistent reporting (e.g., diversity metrics, convergence rates); correct interpretation of synthetic vs real data limits.
- Anomaly/violation detection model training (Energy; grid analytics; cyber-physical monitoring)
- What it enables: Train detectors for voltage/thermal/reactive violations using diverse PF mode samples that include realistic violation patterns (without artificial constraint removal).
- Tools/workflows: PF mode datasets → detector model (e.g., graph-based classifier) → addition to alarm filtering and triage pipelines.
- Assumptions/dependencies: Labels/thresholds reflect utility practices; synthetic violations complement but do not replace historical incident logs.
- Stress testing of LMPs and congestion under cost diversity (Energy/Finance; market analytics; risk)
- What it enables: Use OPF datasets with permuted/scaled generation costs to stress test LMP volatility and congestion patterns; support hedging policy evaluation and uplift risk analysis.
- Tools/workflows: Cost-perturbed OPF scenarios → LMP/injection/flow analysis → scenario P&L stress dashboards.
- Assumptions/dependencies: Market model simplifications (no unit commitment, outages scheduling, bids/constraints beyond cost curves); regulatory acceptance for decision support varies.
- Teaching and curriculum development in power systems + ML (Academia; education)
- What it enables: Labs on PF/OPF, security-constrained scenarios, data diversity, physics-informed ML losses; assignments scale from IEEE 24/118 to 2k–10k bus cases.
- Tools/workflows: Jupyter-based interactive interface; CLI configs for assignments;
gridfm-graphkitfor hands-on GNN labs. - Assumptions/dependencies: Access to compute (modest for PF; larger for OPF at scale); licensing is Apache 2.0, suitable for courses.
- Dataset QA, governance, and MLOps in utilities (Energy; software/AI tooling)
- What it enables: Use built-in validation and stats to establish dataset quality gates, model cards, and retraining triggers in ML lifecycle for PF/OPF surrogates.
- Tools/workflows:
gridfm_datakit validate|statsin CI/CD; drift monitoring with re-generation using updated profiles/topologies. - Assumptions/dependencies: Organizational MLOps maturity; clear data governance and model validation policies.
- Digital twin enrichment for steady-state studies (Energy; grid digital twins)
- What it enables: Populate digital twins with high-coverage steady-state scenarios for calibration, parameter sensitivity, and “what-if” playback without exposing confidential live data.
- Tools/workflows: Synthetic scenario packs aligned to twin’s model; comparison hooks for AC/DC residuals included in dataset.
- Assumptions/dependencies: Twin fidelity to protection/controls; steady-state focus; secure handling of any real system parameters used to condition generation.
Long-Term Applications
These applications need further research, integration, standardization, or scale-up (e.g., real-time deployment, richer physics, broader data access, or policy acceptance).
- Real-time contingency analysis with ML surrogates in EMS (Energy; control rooms)
- Vision: Embed trained foundation models as first-line evaluators for N−k>1 screening, with human-in-the-loop escalation to AC solvers.
- Potential product: “Contingency copilot” co-processor integrated with state estimator and security assessment.
- Dependencies: Proven safety/robustness under distribution shift; certification and regulatory approval; online calibration with streaming telemetry.
- Foundation model for power grids with zero-shot generalization (Energy, Software/AI)
- Vision: Pre-train on diverse grids and scenarios (via
gridfm-datakit+gridfm-graphkit) to enable zero/few-shot adaptation to new regions/topologies and evolving operating regimes. - Potential product: Cross-utility “GridFM” service with transfer to unseen topologies, supporting outage management and resilience analytics.
- Dependencies: Access to broad, diverse training corpora; privacy-preserving training; strong OOD detection and uncertainty quantification.
- Vision: Pre-train on diverse grids and scenarios (via
- Co-design of planning and markets with primal–dual learning and LMP prediction (Energy/Finance; market design)
- Vision: Use datasets extended with dual variables (planned feature) to train primal–dual ML that predicts LMPs, congestion rents, and shadow prices; support market rule stress testing and resource adequacy evaluations.
- Potential product: LMP forecaster with constraint-aware explanations and policy sandbox.
- Dependencies: Availability of duals; mapping training OPF to market-clearing specifics; acceptance of ML-based advisory in regulatory contexts.
- Automated interconnection queue triage and hosting capacity portals (Energy; policy/operations)
- Vision: Applicant- and operator-facing portals that use ML surrogates trained on large synthetic OPF studies to give instant feasibility tiers, likely upgrades, and indicative timelines.
- Potential product: Cloud-based “interconnection assistant” with explainable drivers (thermal limits, voltage stability proxies).
- Dependencies: Continual validation against formal studies; transparency requirements; integration with queue management systems.
- Grid-aware cybersecurity and anomaly simulation at scale (Energy; cybersecurity)
- Vision: Couple steady-state violation generators with cyber event simulators to produce richer, labeled datasets for intrusion/anomaly detection and operator decision support.
- Potential product: Cyber-physical red-teaming sandbox with realistic power system consequence modeling.
- Dependencies: Joint datasets with SCADA/DER comm stacks; scenario realism for both cyber and physical sides; data-sharing agreements.
- Distribution-level expansion and DER-rich scenarios (Energy; distribution utilities; EV/DER planning)
- Vision: Extend workflows to distribution grids (bus-level load profiles, switching, inverter controls) for EV charging siting, PV hosting, and resilience reconfiguration.
- Potential product: City-scale DER hosting explorer with probabilistic load/IBR models.
- Dependencies: Library features for bus-level profiles and distribution topology specifics; modeling inverter controls and protection; data access to feeders.
- Reliability and asset health risk analytics from steady-state envelopes (Energy; asset management)
- Vision: Translate distributions of thermal loadings/voltages into component stress indicators to inform transformer/conductor life models and maintenance prioritization.
- Potential product: “Steady-state risk map” feeding asset-health dashboards and spares logistics.
- Dependencies: Thermal/aging models (e.g., DLR, insulation degradation) and their calibration; integration of weather and dynamic duty cycles.
- Policy benchmarking and AI assurance for grid analytics (Policy; standards)
- Vision: Use standardized synthetic scenario suites for certifying PF/OPF ML tools (coverage/robustness/diversity metrics), informing procurement standards and AI assurance frameworks.
- Potential product: Public benchmark suites (Hugging Face) with conformance tests and documented diversity/feasibility metrics.
- Dependencies: Multi-stakeholder governance; consensus on metrics and acceptance criteria; alignment with NERC/ENTSO-E guidance.
- End-to-end digital twin with multi-physics and multi-timescale coupling (Energy; research/industry)
- Vision: Couple steady-state scenario engines with transient stability, protection, and market simulators to close loops across seconds–hours–days.
- Potential product: Integrated planning-to-operations twin for extreme-event preparedness and blackstart exercises.
- Dependencies: Model coupling standards/APIs; validated dynamic models; significant compute and data integration.
- Market participant decision-support and risk products (Finance/Energy trading)
- Vision: Use cost-diverse, topology-perturbed OPF corpora to train models for congestion risk, basis spreads, and hedging analytics that remain robust to outages and load shocks.
- Potential product: ML-augmented risk suite with stress scenarios for transmission contingencies.
- Dependencies: Alignment with market rules (UC, reserves, outage scheduling); explainability and governance; live data feeds for calibration.
Cross-cutting assumptions and dependencies (common to many applications)
- Realism of base network models (PGLib/MATPOWER) and parameterization; access to utility-grade models improves fidelity.
- Synthetic steady-state focus: dynamics, protection operations, and unit commitment are out of scope unless coupled with external tools.
- Mapping aggregated load profiles to bus-level loads introduces uncertainty; forthcoming bus-level support will reduce this gap.
- Solver scalability and convergence (PowerModels.jl back end) for very large OPF batches; adequate compute budget is required.
- Organizational readiness for ML deployment (MLOps, monitoring, governance, cybersecurity) and regulatory acceptance of ML-assisted decisions.
- Data privacy and security constraints when conditioning generation on utility-specific data; need for privacy-preserving or federated workflows.
Glossary
- AC Optimal Power Flow (ACOPF): A nonlinear optimization that finds cost-optimal generator settings subject to AC network physics and operating limits; "Most PF libraries only generate points that are feasible for the AC Optimal Power Flow (ACOPF) problem, excluding operating states that violate its inequality constraints (e.g., voltage magnitude or branch limits)."
- AC power flow: The nonlinear equations governing voltages, angles, and power flows in AC networks; "After fixing these setpoints, topology perturbations are applied, and an AC power flow is solved to obtain the new system state."
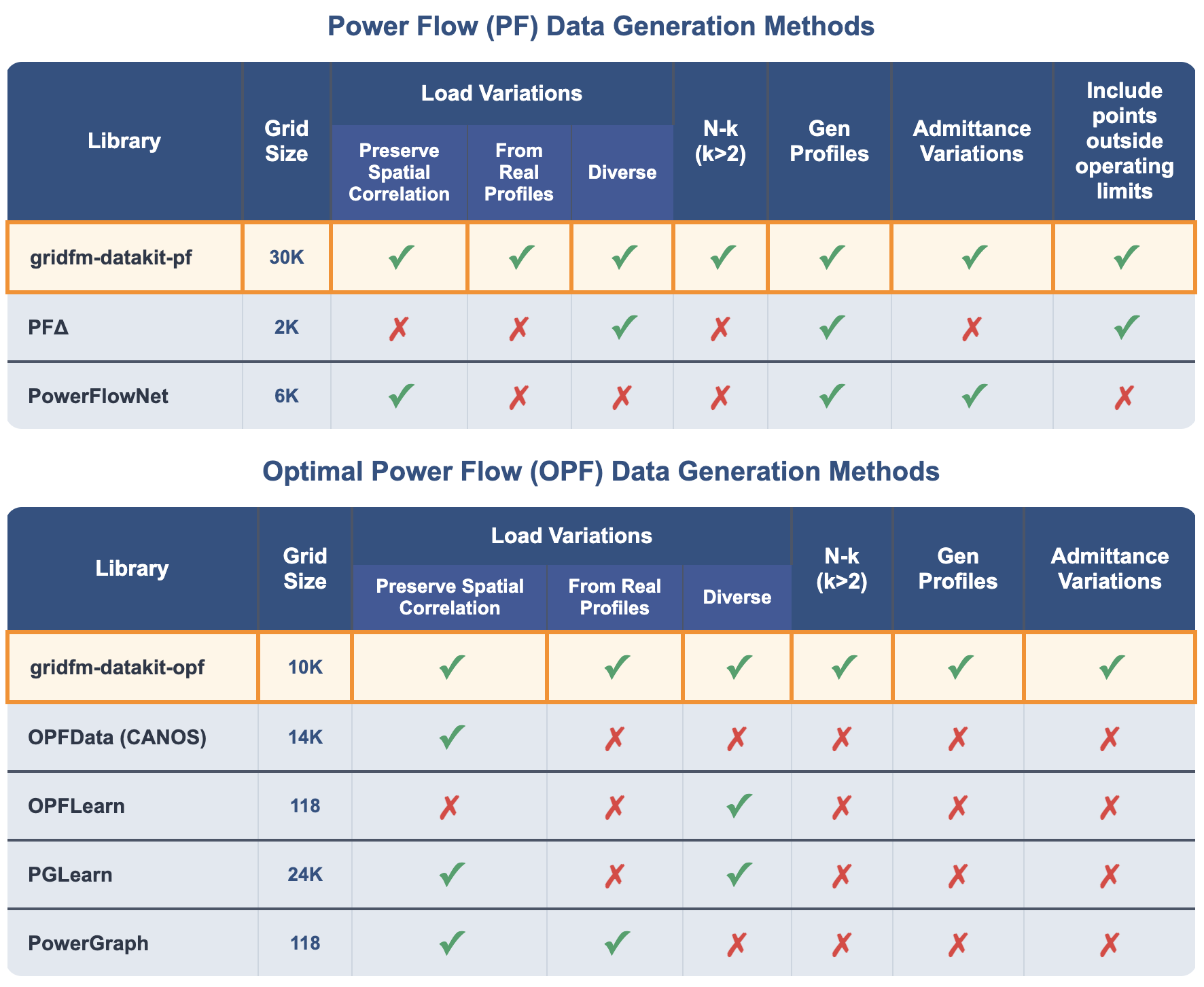
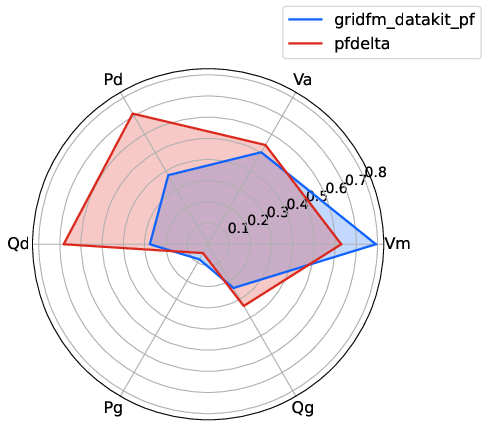
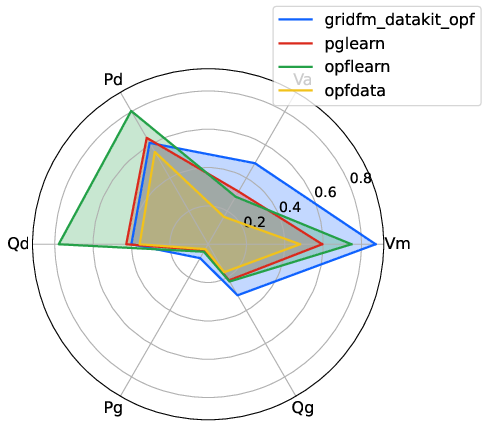
- Admittance: The inverse of impedance (combining conductance and susceptance) describing how easily current flows; "State-of-the-art methods for generating diverse and realistic load, topology, generator dispatch, and admittance scenarios are scattered across more than ten Python and Julia libraries, and even the latest ones don't include all of them, as shown in Figure~\ref{fig:summary}."
- Admittance perturbations: Random modifications to branch resistance/reactance that alter network admittance; "We introduce admittance perturbations by randomly scaling the resistance and reactance of branches using scaling factors sampled from a uniform distribution in the range , where is a user-defined parameter."
- Aggregated load profiles: Time series of total system demand used as global scaling references; "PowerGraph~\cite{varbella2024powergraph} leverages real aggregated load profiles to derive time-dependent global scaling factors, but omits local noise, resulting in limited spatial diversity."
- Branch angle difference violations: Cases where the phase angle difference across a branch exceeds allowed bounds; "Because generator dispatch is not re-optimized after the topology change, some samples violate operating limits defined by the OPF inequality constraints, such as branch overloads, voltage limit violations, branch angle difference violations, reactive power bound violations, and active power bound violations at the slack bus."
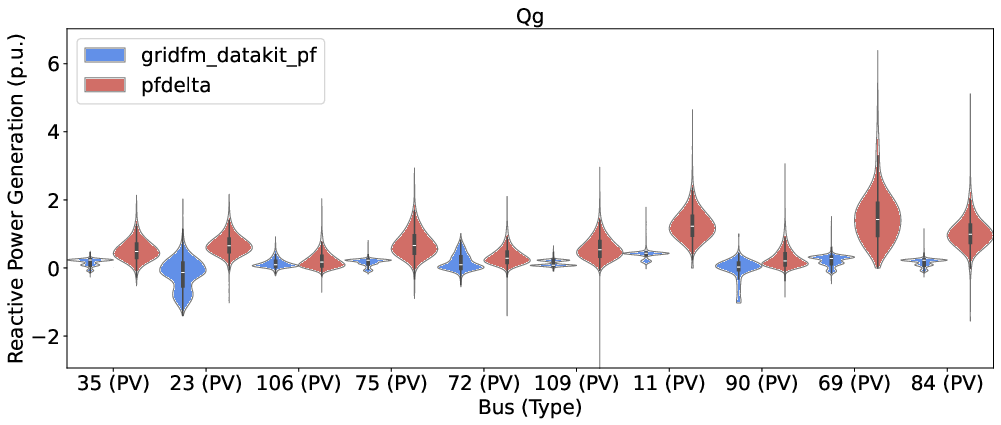
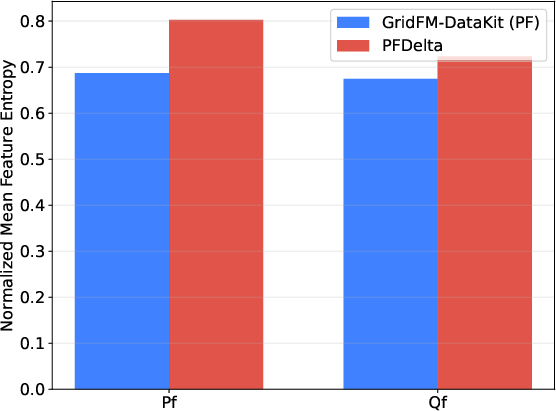
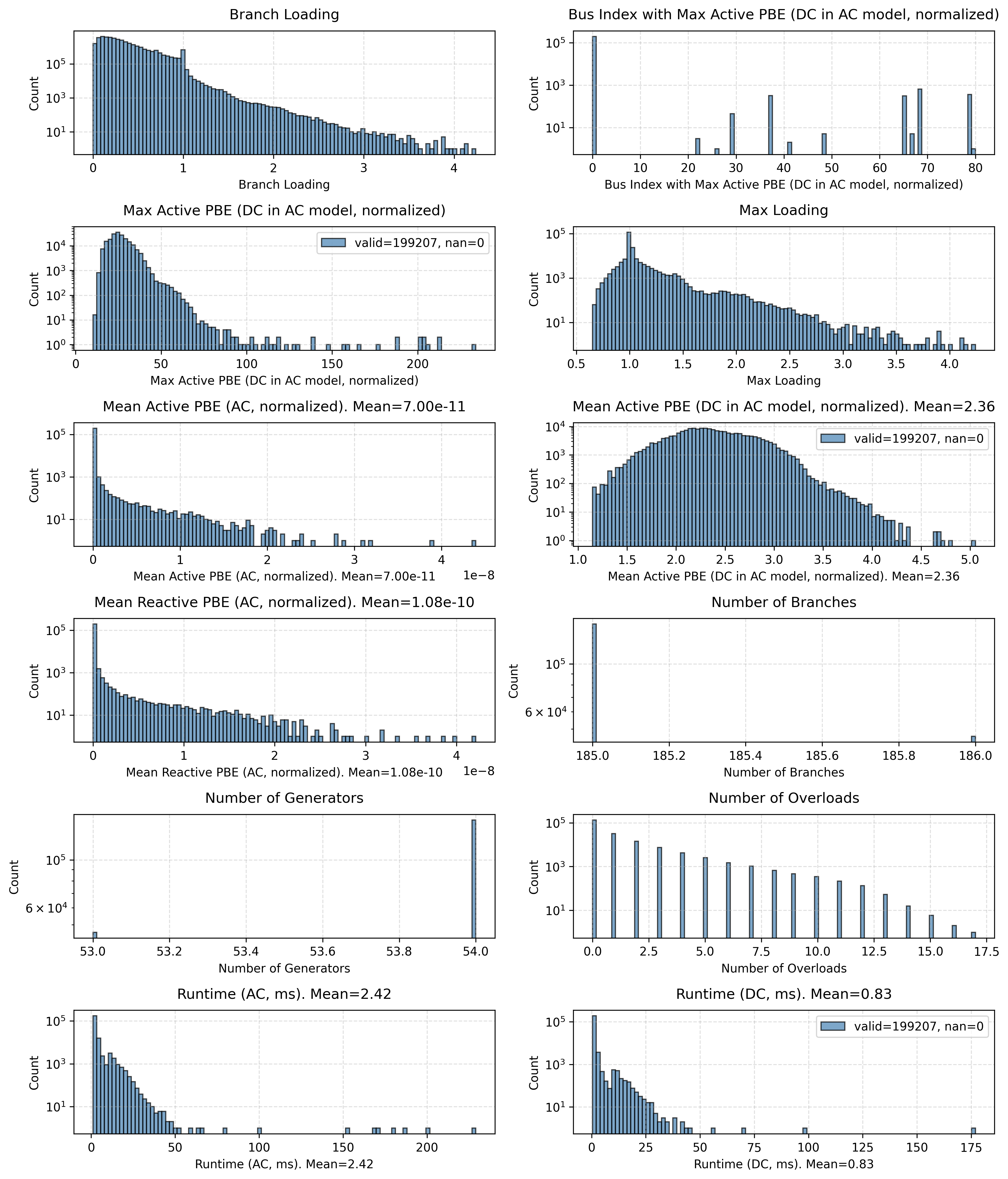
- Branch loading: The ratio of branch flow to its thermal rating indicating utilization; "We show in Figure~\ref{fig:barplot} the mean normalized entropy for branch flow features and in Figure~\ref{fig:loading_hist} the distribution of branch loadings for both datasets."
- Contingencies (N-1): Reliability scenarios with a single component (line/transformer/generator) out; "In particular, most datasets only consider contingencies, although real grids can see ten or more branches switch status per day."
- DC Optimal Power Flow (DC-OPF): A linearized OPF using DC power flow approximations; "gridfm-datakit computes DC-PF and DC-OPF for every generated sample and stores the solutions and the per-sample runtime directly in the dataset."
- DC Power Flow (DC-PF): A linearized power flow model ignoring reactive power and voltage magnitudes; "gridfm-datakit computes DC-PF and DC-OPF for every generated sample and stores the solutions and the per-sample runtime directly in the dataset."
- Feasible load space: The set of load vectors for which the solver can find a solution satisfying constraints; "Finally, OPF-Learn~\cite{opflearn} and PF~\cite{pfdelta} sample directly from the feasible load space, producing scenarios that may be unrealistically uncorrelated across scenarios and buses, and computationally expensive to generate for large networks\footnote{\scriptsize This sampling technique prevents PF and OPF-Learn from generating data for grids larger than 2{,}000 buses and from producing large datasets for 2{,}000-bus grids.}."
- Generator cost coefficients: Parameters shaping generators’ cost curves used in OPF; "OPF libraries (e.g., OPFData~\cite{lovett2024opfdatalargescaledatasetsac}, PGLearn~\cite{pglearn}, OPFLearn~\cite{opflearn}) use fixed generator cost coefficients, limiting the diversity of generator dispatch and the ability for models trained on these datasets to generalize across different cost conditions."
- Generator dispatch: The allocation of power output across generators; "OPF libraries (e.g., OPFData~\cite{lovett2024opfdatalargescaledatasetsac}, PGLearn~\cite{pglearn}, OPFLearn~\cite{opflearn}) use fixed generator cost coefficients, limiting the diversity of generator dispatch and the ability for models trained on these datasets to generalize across different cost conditions."
- Generator setpoints: Target values of generator outputs (active/reactive power, voltage) used to run PF; "Generator setpoints are obtained by solving an ACOPF problem after topology perturbations."
- Islanding: Unintended separation of a grid into disconnected sub-networks; "by randomly sampling topologies by disabling up to components, while ensuring feasibility (i.e., no islanding)."
- MATPOWER format (.m): A standard case format (MATLAB files) for power system models; "Grids can be imported from the MATPOWER format (.m)~\cite{matpower}, and all grids from the PGLib dataset~\cite{pglib} are supported."
- N-k perturbations: Scenarios with simultaneous outages/changes of up to k elements; "While libraries are restricted to contingencies, i.e., single-line, transformer, or generator outages~\cite{pfdelta, opflearn, lovett2024opfdatalargescaledatasetsac}, datakit supports arbitrary perturbations."
- Per-unit (p.u.): A normalized unit system in power systems simplifying comparisons/scaling; "which are 0.32~p.u. and 0.23~p.u., respectively."
- PGLib dataset: A benchmark suite of realistic power system cases; "Grids can be imported from the MATPOWER format (.m)~\cite{matpower}, and all grids from the PGLib dataset~\cite{pglib} are supported."
- Power factor: The ratio of active to apparent power indicating load phase angle; "Uniform sampling yields high variability in power factors across buses and samples."
- Reactance: The imaginary component of impedance affecting AC power flow; "We introduce admittance perturbations by randomly scaling the resistance and reactance of branches using scaling factors sampled from a uniform distribution in the range , where is a user-defined parameter."
- Reactive power: AC power associated with energy storage in fields (var), affecting voltages; "Let and denote the nominal active and reactive powers of load ."
- Resistance: The real component of impedance representing energy dissipation; "We introduce admittance perturbations by randomly scaling the resistance and reactance of branches using scaling factors sampled from a uniform distribution in the range , where is a user-defined parameter."
- Shannon entropy: An information-theoretic measure of diversity/uncertainty in feature distributions; "Figure~\ref{fig:spider} shows, for each feature, the mean normalized Shannon entropy, an information-theoretic measure analogous to metric in \cite{hedgeopf2025}."
- Slack bus: The reference bus that balances power and sets the angle in PF solutions; "such as branch overloads, voltage limit violations, branch angle difference violations, reactive power bound violations, and active power bound violations at the slack bus."
- Thermal limit violations: Exceedances of equipment current/temperature ratings on lines/transformers; "Post-processing utilities compute line loadings, detect thermal limit violations, and identify critical components under perturbed conditions."
- Topology perturbations: Changes to network connectivity or status of components; "After fixing these setpoints, topology perturbations are applied, and an AC power flow is solved to obtain the new system state."
- Transmission grid: The high-voltage network transporting bulk power over long distances; "gridfm-datakit unifies and advances state-of-the-art methods for data generation that were previously scattered across existing libraries, providing the most scalable Python-based framework for generating both Power Flow and Optimal Power Flow datasets for the transmission grid."
- Voltage magnitude limits: Bounds on bus voltage levels enforced for safe operation; "Most PF libraries only generate points that are feasible for the AC Optimal Power Flow (ACOPF) problem, excluding operating states that violate its inequality constraints (e.g., voltage magnitude or branch limits)."
Collections
Sign up for free to add this paper to one or more collections.

