- The paper proposes PerProb, a novel framework that indirectly evaluates LLM memorization by analyzing shifts in perplexity and average log probability.
- Experimental results show that larger models and tailored defense strategies like Knowledge Distillation and Early Stopping effectively mitigate Membership Inference Attack risks.
- The study categorizes diverse attack patterns and validates defense mechanisms, underscoring the importance of robust privacy measures in LLM deployments.
PerProb: Indirectly Evaluating Memorization in LLMs
Introduction
The paper "PerProb: Indirectly Evaluating Memorization in LLMs" (2512.14600) addresses the growing concern of privacy vulnerabilities in LLMs due to Membership Inference Attacks (MIA). As LLMs are trained on extensive datasets which may contain sensitive information, adversaries can potentially infer whether specific data was included in the model's training set, leading to significant privacy risks. The authors propose PerProb, a novel framework that evaluates LLM memorization without requiring member/non-member ground truth labels. PerProb assesses changes in perplexity (PPL) and average log probability (λ(W)) between data generated by both victim and adversary models to estimate memorization indirectly.
Methodology
PerProb Framework: PerProb leverages two key metrics: perplexity (PPL) and average log probability (λ(W)), computed on datasets generated by victim (V) and shadow models (S). These metrics capture shifts in uncertainty and confidence, revealing training-induced memory differences between member and non-member data.
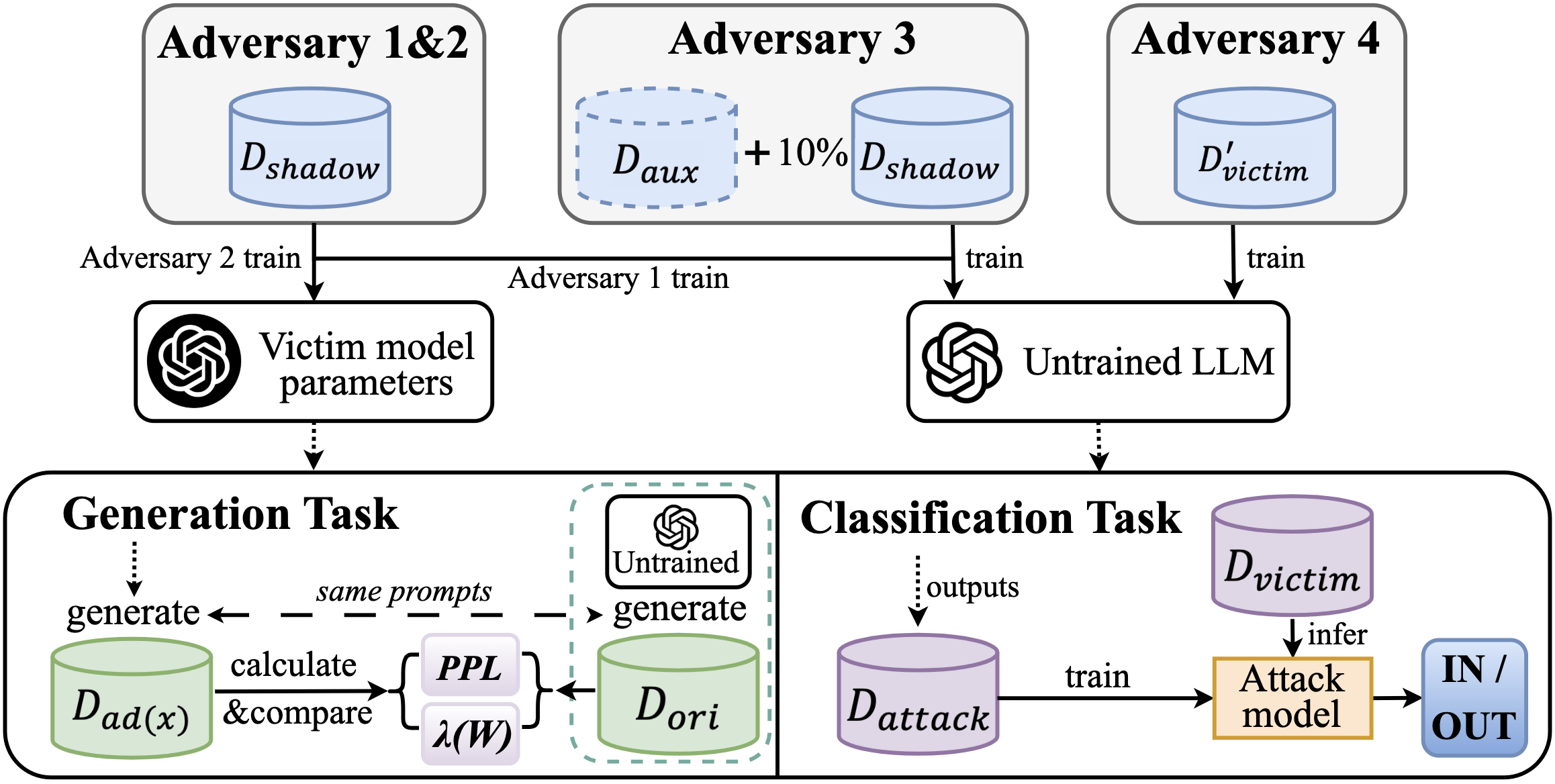
Figure 1: Structure of four attack patterns on generation and classification tasks, respectively. Adversary 1 and Adversary 2 both use the same shadow datasets for training the S.
Attack Patterns: The paper categorizes MIA into four attack patterns based on knowledge access, ranging from black-box to white-box assumptions:
- Adversary 1 (Black-box): Uses shadow datasets to train S, simulating V behavior.
- Adversary 2 (White-box): S shares parameters with V, enabling parameter-level inference.
- Adversary 3: Combines auxiliary and shadow datasets, testing distributional similarity effects.
- Adversary 4: Trains S using partial victim datasets, assessing direct data access impact.
PerProb's versatility allows it to handle both generation and classification tasks, providing comprehensive LLM memorization insights.
Experimental Evaluation
Generation Task: The paper evaluates PerProb on GPT-2 and GPT-Neo (1.3B and 2.7B), examining generated data's PPL and λ(W) under various attack patterns and defenses. Larger models like GPT-Neo exhibit stronger generalization and resistance to MIA, displaying higher PPL and more extreme λ(W) values on adversarial data. Notably, PerProb effectively identifies vulnerabilities across dimensions, such as auxiliary dataset theme consistency.

Figure 2: The features of generated data on four attack patterns in GPT-2.
Classification Task: For classification tasks, the robustness of LLMs to MIA is tested using attack models like Random Forest and MLP on datasets like IMDB and Agnews. Results show significant F1-scores above random chance, confirming the susceptibility of LLMs to MIA.
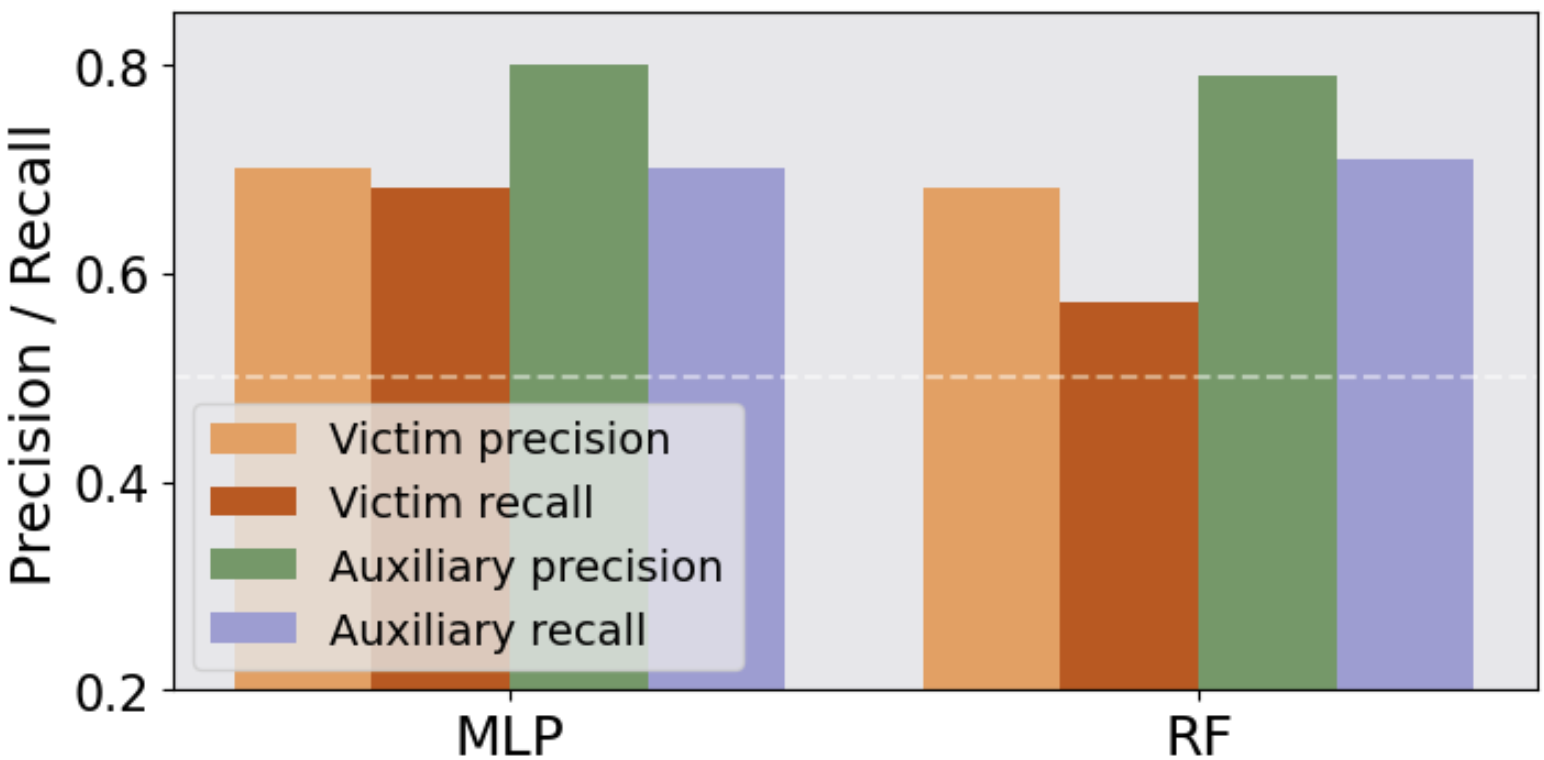
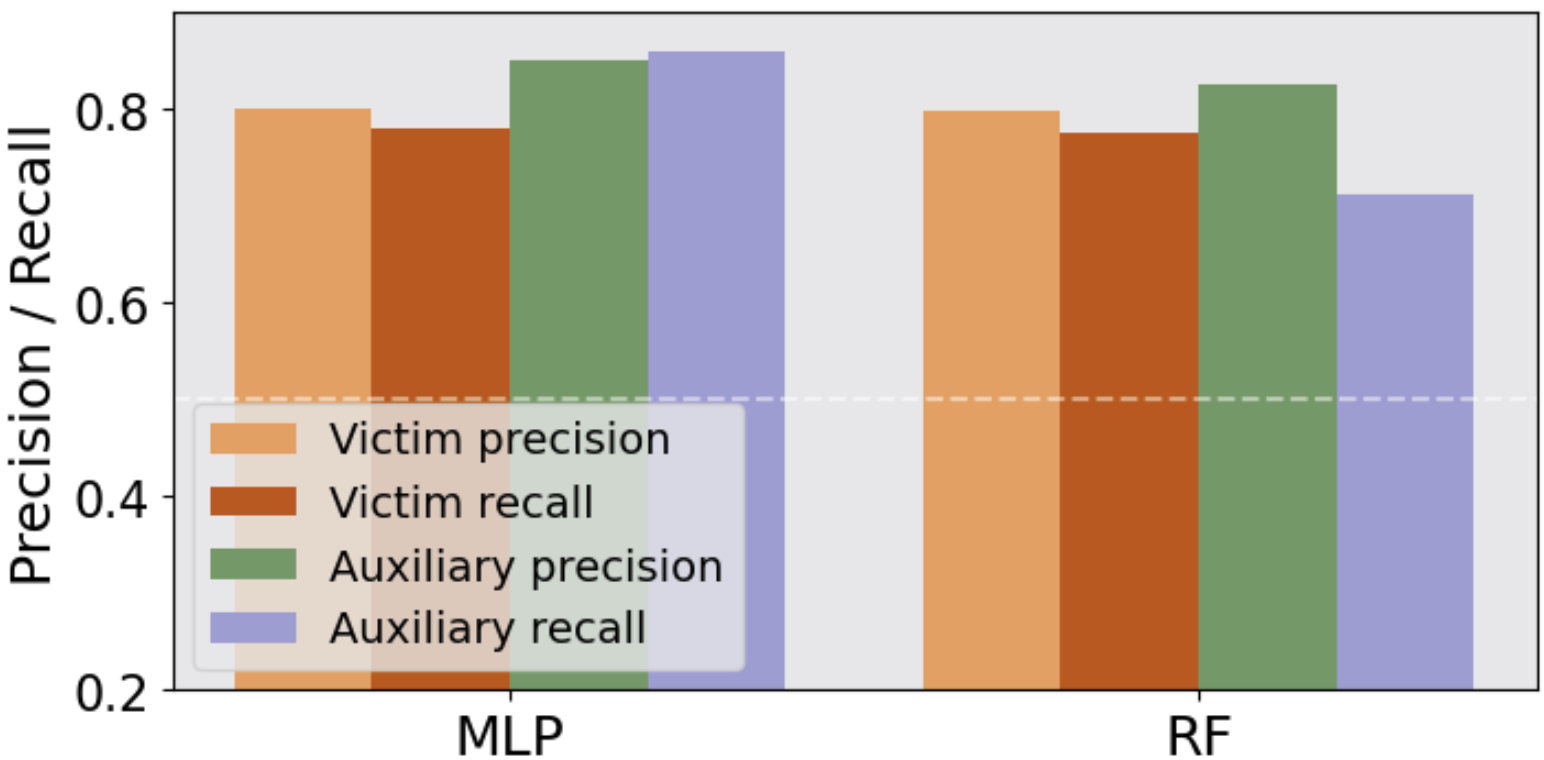
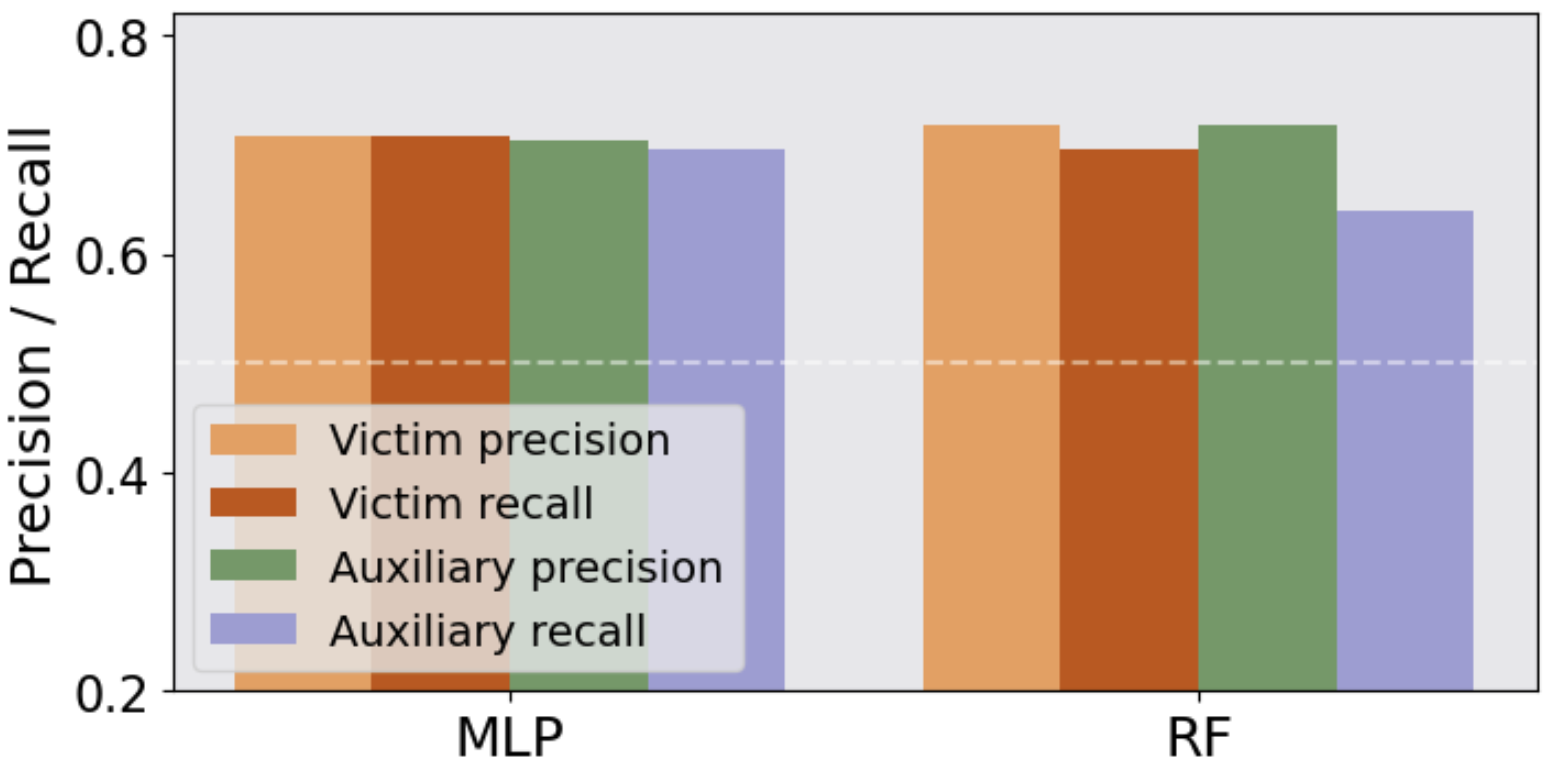
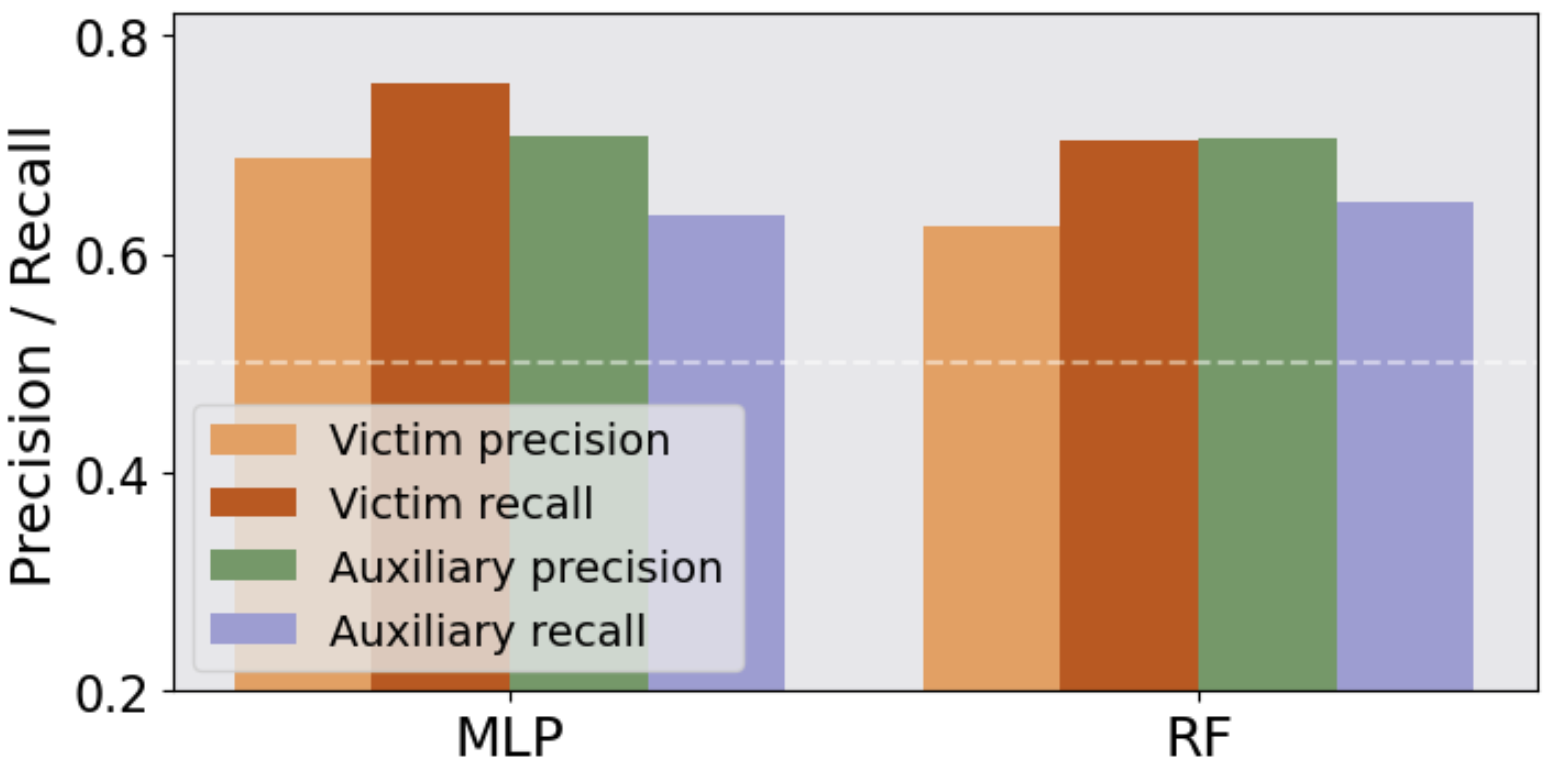
Figure 3: The MIA precision and recall on the victim and auxiliary datasets.
Defense Mechanisms
The study assesses the efficacy of defense strategies like Knowledge Distillation (KD), Early Stopping (ES), and Differential Privacy (DP). KD and ES effectively elevate PPL and reduce λ(W), mitigating MIA threats. KD transfers generalized knowledge while reducing overfitting, and ES halts training early, preserving model generalization. DP, particularly the improved version, effectively obscures posteriors, reducing MIA accuracy even in challenging scenarios with partial victim data access.
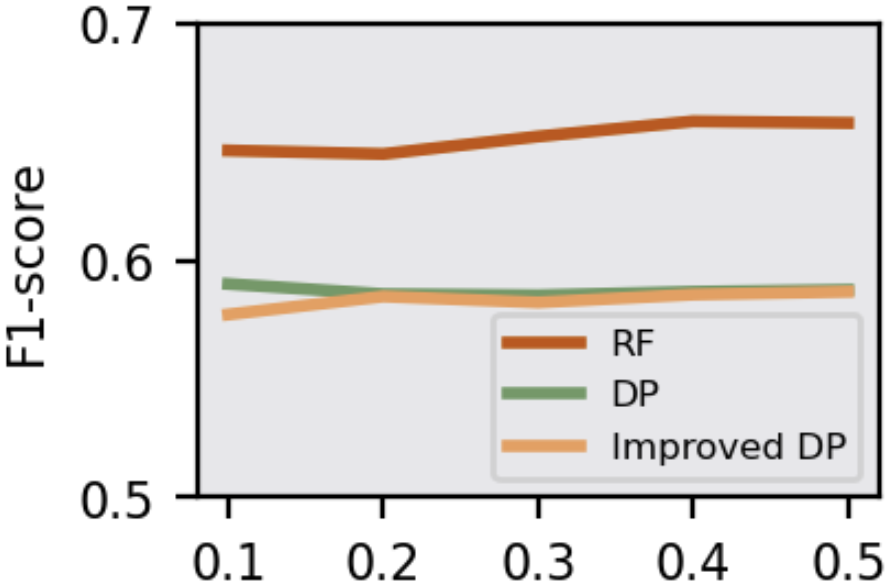
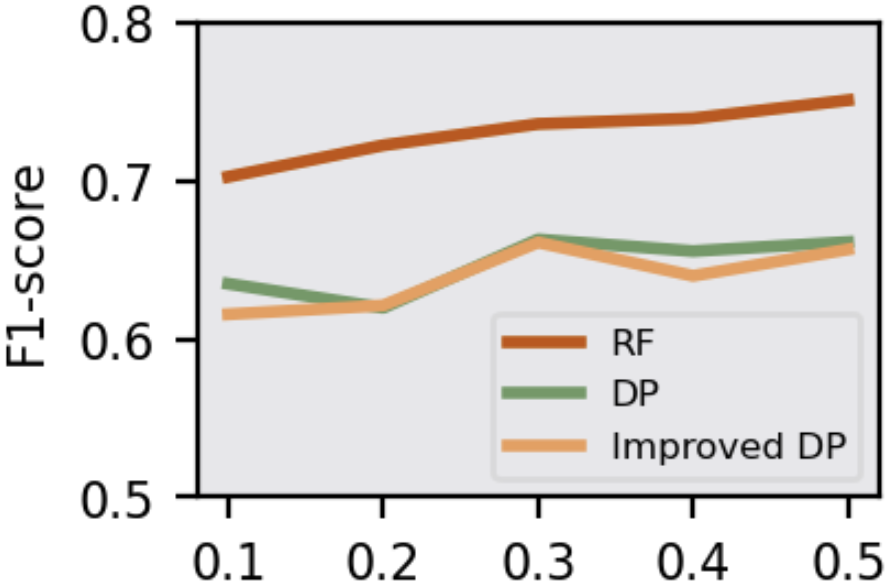
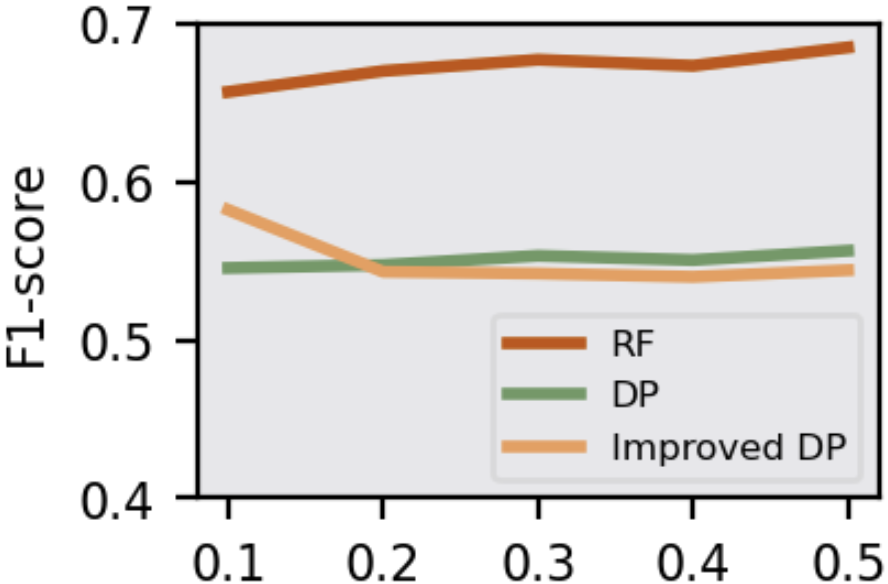
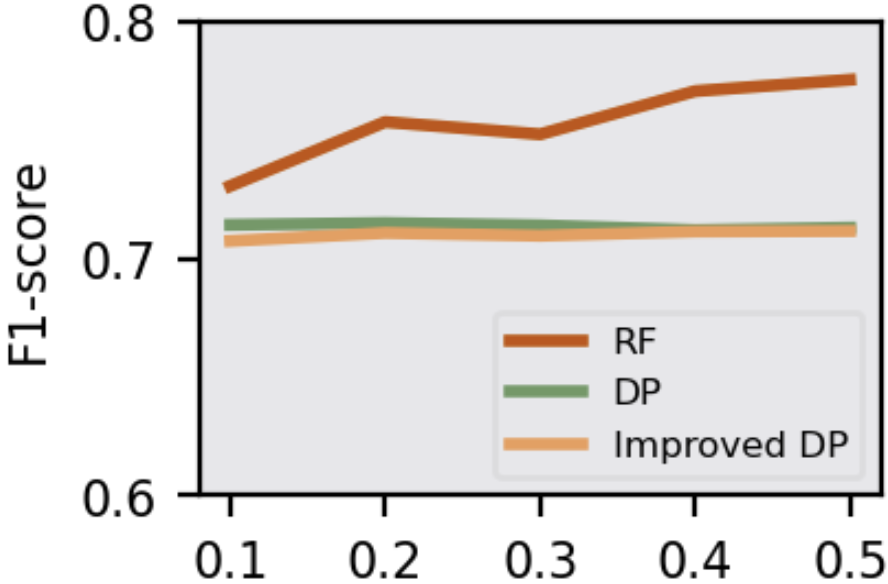
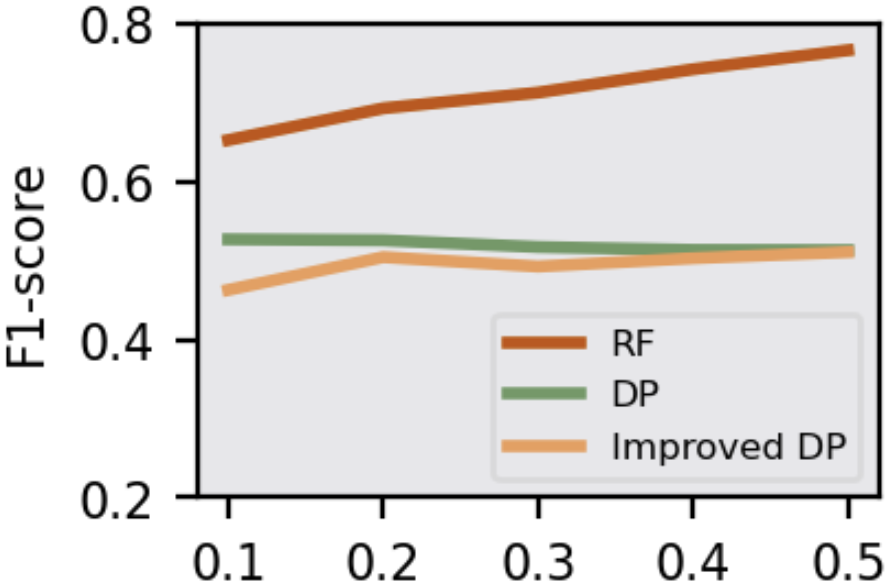
Figure 4: F1-score of attack models in Adversary 4 under DP mechanism.
Limitations and Future Work
While PerProb offers a robust framework for evaluating LLM privacy risks, it assumes consistent prompts and focuses on small-to-mid scale models due to resource constraints. Future work could extend PerProb to larger proprietary LLMs and explore advanced defenses tailored for diverse architectures. Additionally, analyzing diverse dataset characteristics and attack combinations could further enhance understanding and mitigate risks.
Conclusion
The paper "PerProb: Indirectly Evaluating Memorization in LLMs" contributes an innovative framework for assessing LLM memorization vulnerabilities through indirect metrics like PPL and λ(W). PerProb provides a unified, label-free approach applicable across diverse attack patterns and model architectures, effectively highlighting privacy risks in LLM deployments. The study underscores the importance of tailored defense strategies such as KD, ES, and DP for mitigating MIA, paving the way for more secure LLM applications.


