- The paper introduces SFG, a generative framework that recasts CTR prediction as feature generation, addressing embedding collapse and redundancy.
- It employs an encoder-decoder architecture leveraging supervised signals to enhance AUC and reduce logloss across benchmark datasets.
- Empirical evaluations demonstrate significant GMV and CTR lifts in production, highlighting the method’s practical deployment benefits.
A Generative Paradigm for CTR Prediction: From Feature Interaction to Feature Generation
Motivation and Limitations of Discriminative Paradigms
Click-Through Rate (CTR) prediction underpins large-scale recommender systems, driving user engagement and advertising revenue. Traditionally, CTR models utilize discriminative architectures, focusing on explicit or implicit feature interactions—typically via raw ID embeddings and multi-layer perceptrons (MLPs) or factorization approaches. This discriminative paradigm, while widely adopted, introduces structural limitations:
- Embedding Dimensional Collapse: Discriminative feature interaction, especially with low-cardinality fields, leads to low-rank embedding spaces ("interaction collapse"), restricting the information capacity of the learned representations.
- Information Redundancy: Excessive feature interactions result in highly redundant embeddings, violating redundancy reduction principles that are crucial for unsupervised and supervised representation learning.
- Ignorance of P(X): Discriminative models optimize P(Y∣X) but do not explicitly model P(X), limiting their ability to capture the complex co-occurrence structure inherent in multi-field categorical data.
The Supervised Feature Generation Framework
The paper proposes Supervised Feature Generation (SFG), a generative modeling framework for CTR prediction. SFG reformulates feature interaction as feature generation, leveraging supervised signals rather than traditional self-supervision. The architecture consists of two principal modules:
- Encoder: For each feature, a field-wise, one-layer non-linear MLP transforms the concatenation of all feature embeddings into a hidden representation.
- Decoder: Feature-specific linear projections map each hidden representation back to the original feature space, allowing the decoder to regenerate every feature's embedding from the encoded global context.
Rather than modeling ordered sequences as in next-token prediction, SFG employs an All-Predict-All paradigm, reflecting the unordered, multi-field structure of CTR data.
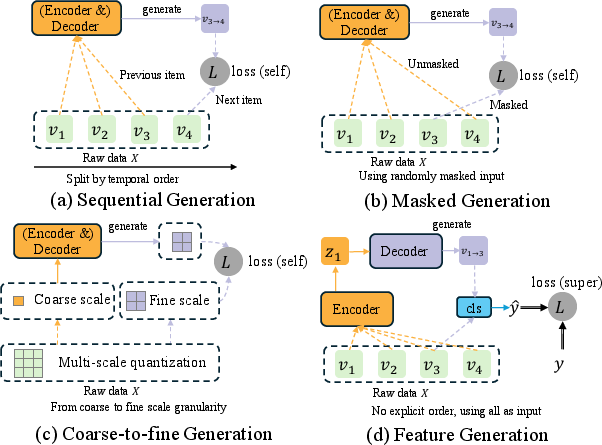
Figure 1: Various generative paradigms; SFG adopts the "all predict all" approach for categorical multi-field CTR data, using supervised generative loss.
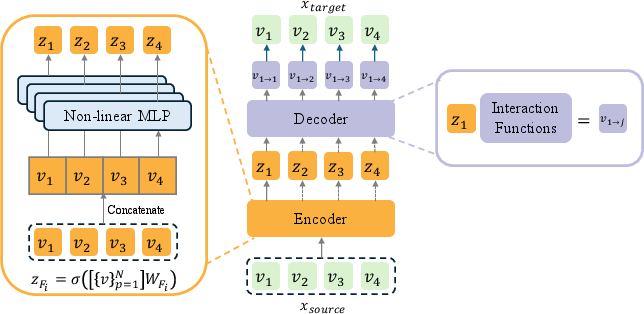
Figure 2: The SFG architecture, where the encoder aggregates all features and the decoder predicts all features, creating a fully connected generative process.
Integrating Supervised Loss
Distinct from many recent generative models that exploit self-supervision (e.g., masked feature/object modeling), SFG exploits the available CTR label ("clicked" or "not clicked") as a supervision signal. This design avoids label leakage and compels the hidden representations to be informative with respect to the downstream CTR objective.
Empirical Results and Analysis
Comprehensive evaluation on the Criteo and Avazu datasets demonstrates that integrating SFG with a spectrum of archetypal CTR models—from Factorization Machines (FM), FmFM, and CrossNet V2, to DeepFM, xDeepFM, IPNN, and DCN V2—consistently improves both AUC and logloss, with up to 0.428% AUC lift and 0.689% logloss reduction for explicit interaction models. For DNN-based models, average improvements reach 0.116% (AUC) and 0.181% (logloss), narrowing the inter-architectural performance gap. Despite increased expressivity, SFG introduces only modest computational overhead (approx. 3% increase in runtime and 1.45% in memory footprint).
Notably, SFG has been deployed in a production-scale advertising platform, yielding a 2.68% GMV (gross merchandise volume) lift and 2.46% CTR lift, with statistically significant improvements across key business metrics.
Embedding Collapse Mitigation
The paper rigorously analyzes the singular value spectrum of model embeddings to quantify dimensional collapse. In conventional discriminative paradigms, the spectrum exhibits a sharp cut-off, with a substantial portion of dimensions informationally degenerate, especially in high-capacity models like DCN V2. In contrast, the SFG-generated embeddings preserve a more balanced singular value distribution, increasing the number of informative dimensions by up to 25%, as shown below.
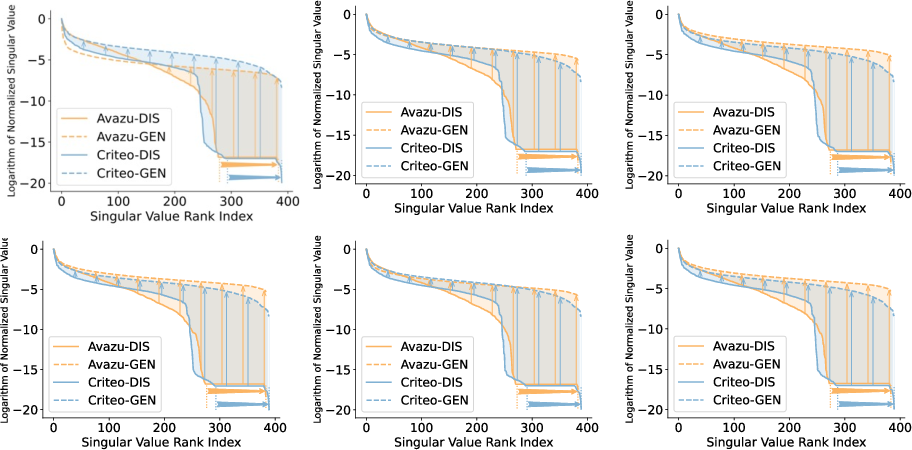
Figure 3: Normalized embedding spectrum under different random seeds; SFG ensures consistent, balanced spectrum, indicating robust mitigation of dimensional collapse.
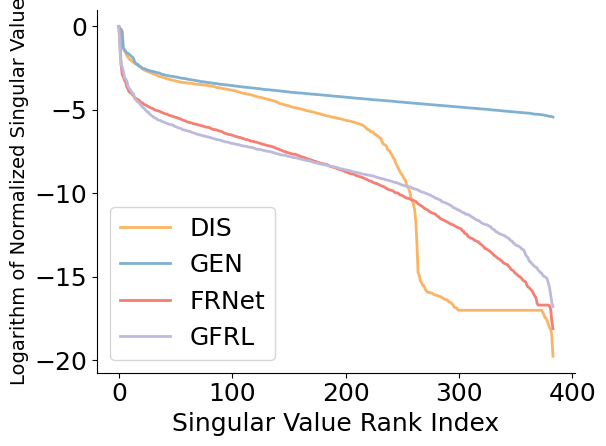
Figure 4: SFG yields more robust singular values across dimensions compared to feature enhancement baselines and discriminative DCN V2.
Redundancy Reduction
SFG also achieves substantial decorrelation in the learned embeddings. The Pearson correlation coefficient matrices between interacted embeddings display pronounced intra- and inter-field redundancy in discriminative models, notably reduced in SFG-based generative formulations. Consequently, the representations adhere more closely to the redundancy reduction principle, empirically linked to improved recommendation performance.
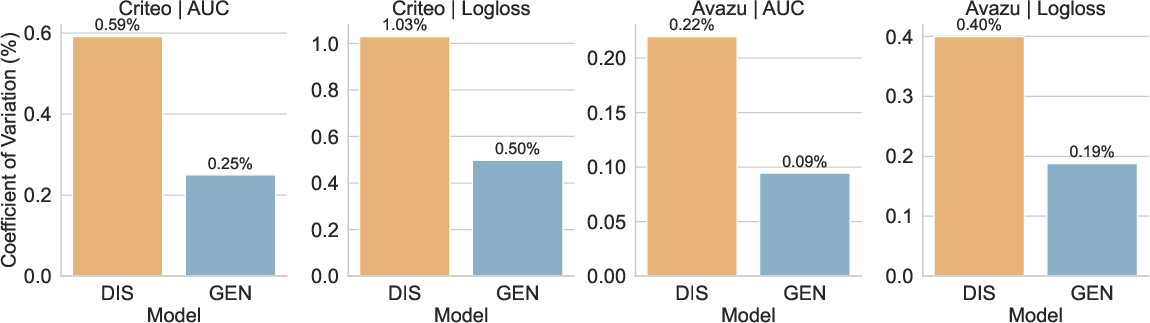
Figure 5: Coefficient of variation comparison; generative SFG reduces performance variability across model archetypes.
Ablation Studies and Architectural Design
Ablation analyses reveal that SFG achieves optimal performance when:
- All features are used as encoder input (xsource): Using only high- or low-cardinality fields degrades performance, confirming the importance of global contextualization.
- Encoder remains a one-layer, field-wise, non-linear MLP: Simplifications or added complexity diminish results, emphasizing the effectiveness of minimal design.
- Generative "predict all" targets outperform masked or partially masked alternatives: The All-Predict-All strategy is superior under supervised objectives.
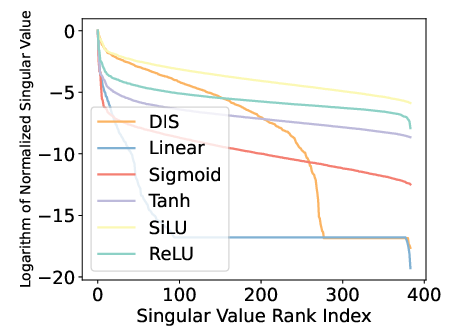
Figure 6: Ablation on source embedding selection, illustrating the degradation when not using all feature fields as input.
Theoretical and Practical Implications
SFG establishes a methodological shift from discriminative to generative modeling in industrial CTR prediction, providing a framework that is both flexible—able to subsume existing architectures—and practical for production deployment. By explicitly modeling the data distribution P(X) via supervised generation, SFG enhances embedding expressiveness and mitigates pathologies (collapse, redundancy) endemic to large-scale recommendation settings.
Theoretically, SFG offers a path to unify feature interaction and generative modeling in structured tabular domains well beyond CTR, contrasting sharply with existing generative paradigms designed for sequence or image data. Practically, its compatibility with legacy architectures and negligible resource costs facilitate its adoption in production.
Future Directions
Future work could extend SFG along several directions: integrating more expressive generative decoders (e.g., attention-based), exploring alternate supervised signals in multi-label settings, and investigating connections to self-supervised and contrastive learning. Additionally, the SFG framework could guide the design of domain-agnostic generative models for structured data, potentially informing representation learning strategies across machine learning domains.
Conclusion
Supervised Feature Generation recasts CTR modeling as a generative problem, yielding statistically significant accuracy improvements, robust and expressive embeddings, and smooth deployment into large-scale systems. By mitigating embedding collapse and redundancy while remaining computationally tractable, it offers a compelling foundation for future research and application in recommender systems and other structured prediction tasks.