- The paper presents a novel approach to training long-context models using supervised fine-tuning, significantly boosting performance on extensive text tasks.
- It introduces a robust evaluation protocol that goes beyond traditional perplexity, incorporating downstream tasks like retrieval-augmented generation and summarization.
- The ProLong-8B model demonstrates state-of-the-art performance while efficiently balancing data mixtures to handle contexts up to 512K tokens.
Effective Training of Long-Context LLMs
The paper "How to Train Long-Context LLMs (Effectively)" (arXiv (2410.02660)) presents strategies for enhancing LLMs' abilities to handle long contexts efficiently. It proposes a comprehensive evaluation protocol and investigates various design choices, focusing on continued and supervised fine-tuning (SFT) to maximize long-context performance. The findings culminate in the introduction of the ProLong-8B model, demonstrating state-of-the-art results among models of similar size.
Evaluation Protocol Development
The authors highlight the importance of deploying a robust evaluation framework that moves beyond conventional perplexity and simple needle-in-a-haystack (NIAH) tests. They recommend a broad set of downstream tasks—encompassing retrieval-augmented generation (RAG), long-document summarization, and many-shot in-context learning (ICL)—conducted post-SFT to better discern long-context capabilities. Notable is the emphasis on evaluating models after SFT, which reveals performance gains that are not apparent beforehand.

Figure 1: Improvements on RAG and re-ranking tasks are only observed when evaluating models after a supervised fine-tuning (SFT) phase on instruction data.
Data Mixture and Sequence Length
The paper explores the impact of varying the data mixture used during training, particularly the ratio of long to short data. Books and code repositories emerge as prime long-context data sources, with optimal performance achieved through a balanced mix. Surprisingly, training with sequences longer than the evaluation length further enhances long-context performance, challenging assumptions about necessary training lengths.
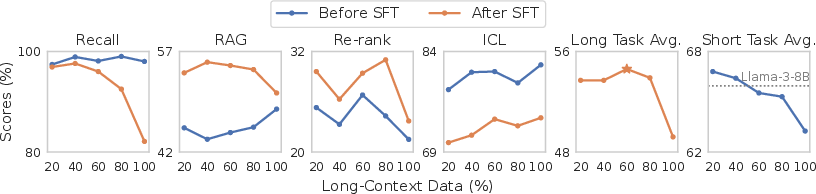
Figure 2: Impact of short/long data ratio. All models are trained on books/repos long data and our ShortMix for 5B tokens. More long data initially improves long-context performance, but then becomes impairing. More long data also consistently degrades the short-context performance.
Supervised Fine-Tuning Insights
SFT is evaluated using both short and synthetically generated long-context instruction datasets. Contrary to prior studies, the paper finds that leveraging standard, short-context instruction datasets yields sufficient performance on long-context tasks, sidelining the need for synthetic data in this setting. This emphasizes the sufficiency of existing short-context instruction datasets in enhancing model performance after continued training.
The ProLong Model
The culmination of this research is the ProLong-8B model, which achieves top-tier performance across a range of long-context benchmarks while employing only 5% of the data volume used by comparable models like Llama-3.1. ProLong can effectively manage up to 512K tokens, making it one of the longest-context models publicly available.
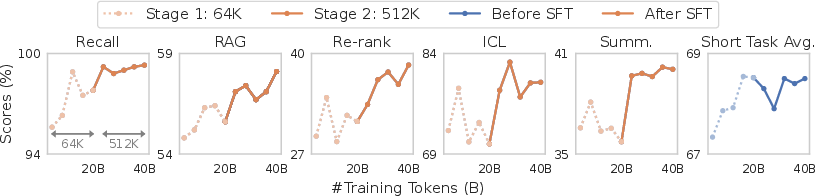
Figure 3: Performance (avg. of 32K and 64K) of our ProLong model throughout training.
Conclusion
This study offers critical insights into training LLMs for extended contexts, challenging existing methods, and proposing more efficient training strategies. Its findings significantly impact both theoretical understanding and practical applications, optimizing computational resources while retaining performance. The ProLong-8B sets a new benchmark for future research in long-context LLMs, with implications for tasks requiring extensive text comprehension.
The results presented will inevitably guide future model developments and finely tuned training methodologies, culminating in more robust and contextually aware LLMs.

