- The paper introduces GAS, a novel method that integrates adversarial distillation to improve discretization of diffusion ODEs for efficient and high-fidelity sampling.
- It employs a flexible solver parameterization with trainable schedule, coefficients, and evaluation offsets, enhancing convergence speed and stability.
- Empirical results reveal that GAS outperforms baselines like S4S and LD3 with lower FID scores, especially in low-NFE regimes.
GAS: Improving Discretization of Diffusion ODEs via Generalized Adversarial Solver
Introduction
The paper introduces the Generalized Adversarial Solver (GAS), a novel approach for discretizing diffusion ODEs to accelerate sampling in diffusion models while maintaining high generation fidelity. The method addresses the limitations of existing solver optimization and distillation techniques, which often require complex training procedures and struggle to preserve fine-grained details, especially in low-NFE (number of function evaluations) regimes. GAS combines a new solver parameterization with adversarial training, yielding significant improvements in both sample quality and training efficiency across a range of datasets and model architectures.

Figure 1: GAS produces images nearly indistinguishable from the teacher, outperforming UniPC at equal NFE.
Background and Motivation
Diffusion models have become the standard for high-quality generative modeling in vision tasks, but their sampling process is computationally intensive due to the need for many ODE steps. Prior work has explored both inference-time acceleration (e.g., specialized solvers, caching, quantization) and training-based distillation (e.g., LD3, S4S, Consistency Models). However, these methods either require extensive hyperparameter tuning or fail to fully exploit the parameter space of the solver, resulting in suboptimal sample quality and inefficient training.
The GAS framework is motivated by the observation that existing solver parameterizations are overly restrictive and that adversarial objectives can mitigate the regression loss limitations in distillation, especially for preserving perceptual details.
Generalized Solver Parameterization
GAS introduces a flexible solver parameterization that generalizes linear multistep methods. Each sampling step computes a weighted sum over all previous states and velocity directions, with the weights themselves being trainable corrections to theoretically derived coefficients (e.g., from DPM-Solver++(3M)). This design increases the expressivity of the solver and facilitates efficient gradient-based optimization.
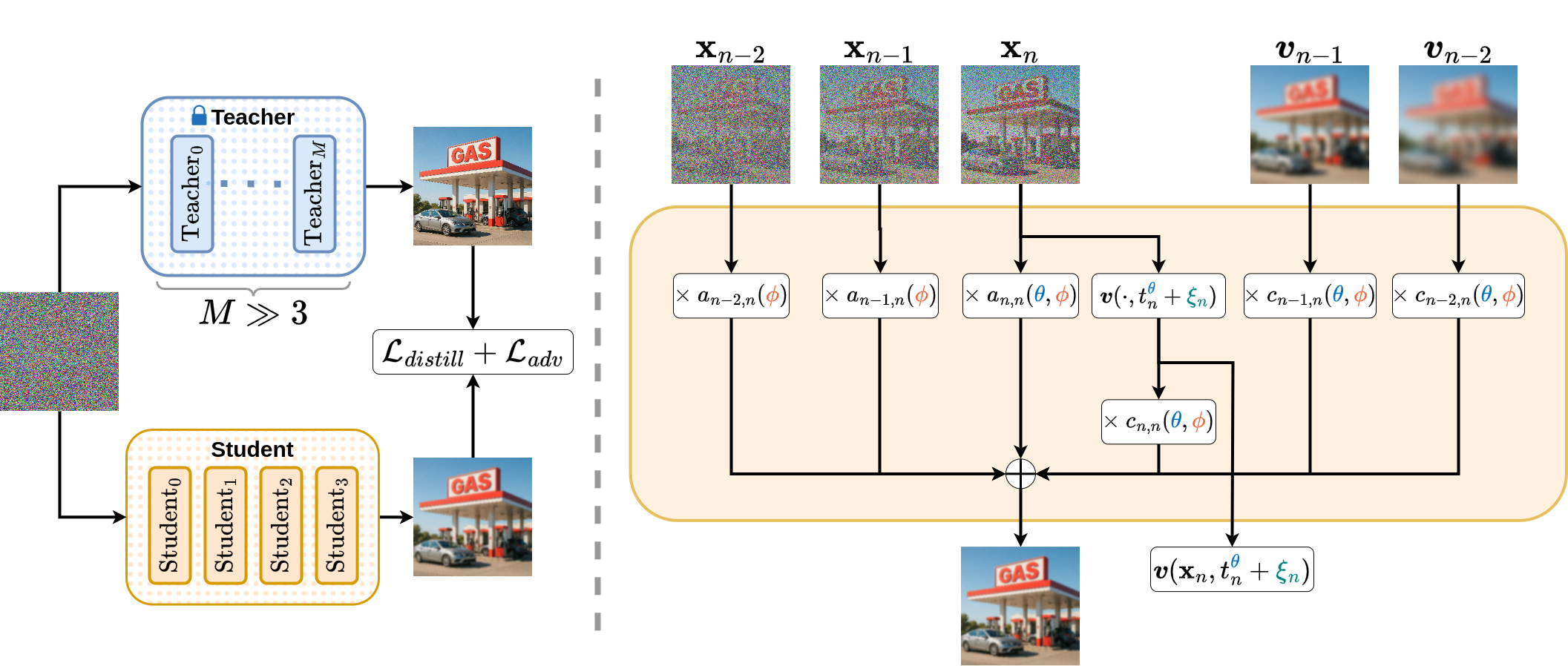
Figure 2: GAS computes each step as a weighted sum over all previous points and velocities, with weights learned via distillation and adversarial loss.
The parameterization consists of three sets of trainable parameters:
- Schedule parameters (θ): Define the timestep schedule via a stick-breaking transformation.
- Solver coefficients (ϕ): Additive corrections to base solver coefficients for both points and velocities.
- Model evaluation offsets (ξ): Decoupled corrections to the timesteps at which the diffusion model is evaluated.
This approach allows GAS to leverage theoretical guidance for initialization and stability, while enabling the optimizer to discover corrections that improve sample quality and convergence speed.
Adversarial Distillation
GAS augments the standard distillation loss (LPIPS in pixel space, L1 in latent space) with a relativistic adversarial loss using an R3GAN discriminator. The adversarial objective is crucial for reducing perceptual artifacts and mode collapse, particularly in low-NFE settings where regression losses alone are insufficient to match the teacher's distribution.
The combined objective is:
θ,ϕ,ξminψmaxLdistill(θ,ϕ,ξ)+Ladv(θ,ϕ,ξ,ψ)
where Ladv is the relativistic GAN loss with gradient penalties.

Figure 3: Adversarial loss reduces artifacts and improves perceptual quality in low-NFE regimes.
Empirical Results
GAS demonstrates consistent improvements over both solver-based and distillation-based baselines across pixel-space (CIFAR10, FFHQ, AFHQv2) and latent-space (LSUN-Bedroom, ImageNet, MS-COCO) datasets. Notably, GAS achieves lower FID scores than S4S, LD3, and UniPC in all tested scenarios, with the largest gains observed at low NFE.
- On FFHQ with NFE=4, GAS achieves FID=7.86 vs. S4S Alt's FID=10.63.
- On AFHQv2 with NFE=4, GAS achieves FID=4.48.
- On ImageNet-256 (latent), GAS achieves FID=5.38 at NFE=4.
Training efficiency is also improved: GAS converges in 2–9 hours depending on dataset and NFE, with minimal memory overhead compared to LD3 and S4S. The method is robust to dataset size, requiring as few as 1400–5000 samples for competitive performance.
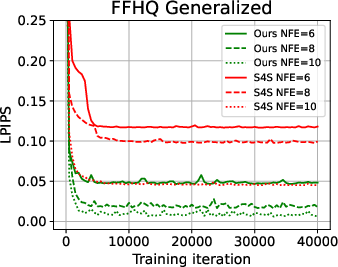
Figure 4: GAS parameterization yields more stable and efficient training than S4S, as measured by LPIPS loss.
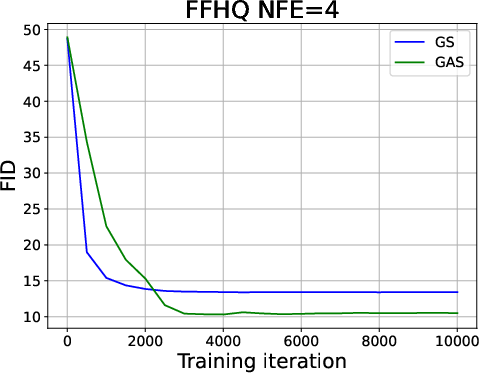
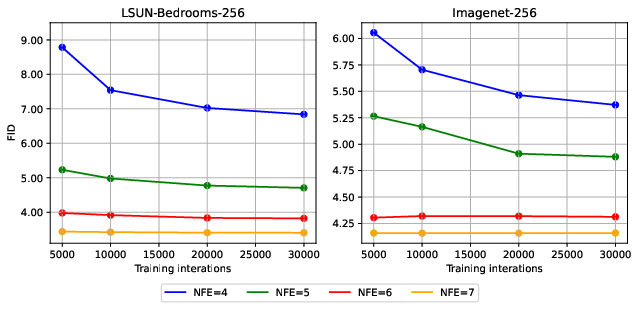
Figure 5: FID progression during training for FFHQ, showing GAS achieves lower FID with more iterations.
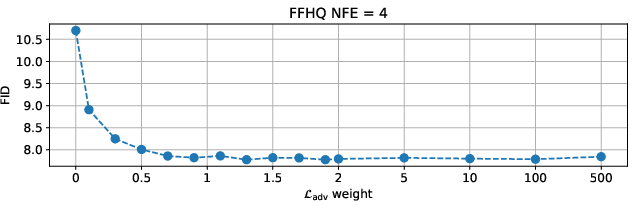
Figure 6: GAS is insensitive to adversarial loss weight, maintaining stable FID across a wide range of values.
Ablation and Analysis
Ablation studies confirm the importance of the additive theoretical guidance in the solver coefficients and the adversarial loss. GAS parameterization leads to faster convergence and more stable training than S4S, even when controlling for the number of trainable parameters. The adversarial loss is particularly effective in low-NFE regimes, where regression losses fail to correlate with perceptual quality.
Generalization experiments show that GAS solvers trained on one dataset (e.g., FFHQ) transfer effectively to related datasets (e.g., AFHQv2), outperforming baseline solvers without retraining.
Implementation Considerations
- Resource Requirements: GAS requires backpropagation through the entire solver trajectory, which may limit scalability for very large images or models.
- Training Details: The method uses Adam optimizer, EMA for parameter averaging, and gradient clipping. Discriminator is trained jointly with the solver.
- Inference Efficiency: GAS introduces negligible inference overhead compared to baseline solvers, as the additional computations are trivial relative to model evaluations.
Implications and Future Directions
GAS advances the state-of-the-art in solver optimization for diffusion models, providing a practical framework for fast, high-fidelity sampling under resource constraints. The approach is broadly applicable to both pixel and latent diffusion models, and can be integrated with existing acceleration techniques.
Theoretical implications include the demonstration that solver parameterization with additive theoretical guidance and adversarial objectives can overcome the limitations of regression-based distillation. Practically, GAS enables efficient deployment of diffusion models in scenarios where computational resources are limited, such as real-time or high-resolution generation.
Future work may focus on scaling GAS to larger models and images, developing lightweight variants for extreme resource constraints, and exploring its integration with other acceleration methods (e.g., caching, quantization).
Conclusion
GAS introduces a principled and effective approach for discretizing diffusion ODEs, combining a generalized solver parameterization with adversarial distillation. The method achieves superior sample quality and training efficiency across diverse datasets and model architectures, with robust performance in low-NFE regimes. GAS sets a new standard for solver optimization in diffusion models and opens avenues for further research in fast, high-fidelity generative modeling.