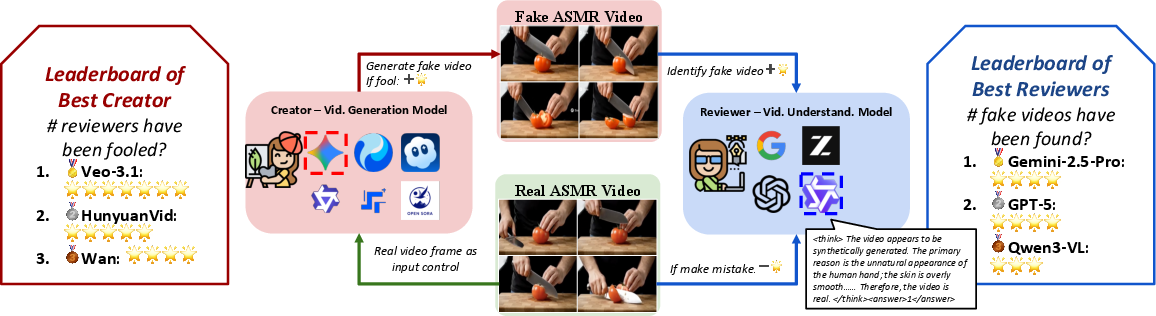
Video Reality Test: Can AI-Generated ASMR Videos fool VLMs and Humans?
Abstract: Recent advances in video generation have produced vivid content that are often indistinguishable from real videos, making AI-generated video detection an emerging societal challenge. Prior AIGC detection benchmarks mostly evaluate video without audio, target broad narrative domains, and focus on classification solely. Yet it remains unclear whether state-of-the-art video generation models can produce immersive, audio-paired videos that reliably deceive humans and VLMs. To this end, we introduce Video Reality Test, an ASMR-sourced video benchmark suite for testing perceptual realism under tight audio-visual coupling, featuring the following dimensions: \textbf{(i) Immersive ASMR video-audio sources.} Built on carefully curated real ASMR videos, the benchmark targets fine-grained action-object interactions with diversity across objects, actions, and backgrounds. \textbf{(ii) Peer-Review evaluation.} An adversarial creator-reviewer protocol where video generation models act as creators aiming to fool reviewers, while VLMs serve as reviewers seeking to identify fakeness. Our experimental findings show: The best creator Veo3.1-Fast even fools most VLMs: the strongest reviewer (Gemini 2.5-Pro) achieves only 56\% accuracy (random 50\%), far below that of human experts (81.25\%). Adding audio improves real-fake discrimination, yet superficial cues such as watermarks can still significantly mislead models. These findings delineate the current boundary of video generation realism and expose limitations of VLMs in perceptual fidelity and audio-visual consistency. Our code is available at https://github.com/video-reality-test/video-reality-test.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to test whether AI-made videos look and sound real enough to fool both computers and people. The focus is on ASMR videos, which are short, calming clips (like tapping, cutting, or squeezing things) where the sound and visuals must match perfectly to feel real. The authors ask: Can today’s AI video generators make ASMR videos that trick humans and advanced AI systems into thinking they’re real?
What questions did the researchers ask?
The researchers explored three simple questions:
- Can AI video generators make fake ASMR videos that seem real to humans and AI reviewers?
- Can AI reviewers (computer models that watch and describe videos) accurately tell real videos from AI-made ones?
- Do things like audio, watermarks, and the way questions are asked affect the results?
How did they do the study?
What is ASMR?
ASMR videos often show hands interacting with objects (like soap, paint, dolls, or slime) and include close-up sounds of the action (like slicing, tapping, peeling). They work only if the sound and video are tightly connected—if the sound doesn’t match what you see, it immediately feels fake.
Building the test
- They collected 1,400 high-quality ASMR videos from social media and carefully picked 149 real ones that were diverse and well-made (many had over 900,000 views, which suggests people find them realistic and engaging).
- They prepared each video by trimming clips, removing background distractions, and saving the first frame (image).
- They wrote short text descriptions for each video and grouped them into categories to cover different objects, actions, and settings.
- They labeled videos as “easy” (short, simple actions) or “hard” (longer, multi-step actions, with complex backgrounds and materials).
The “creator vs. reviewer” game
Think of this like a two-player game:
- Creators: AI video generation models (VGMs) try to make fake ASMR videos that look and sound real.
- Reviewers: AI video–LLMs (VLMs) and humans try to decide whether a video is real or AI-generated.
They measured:
- How often reviewers correctly spot real vs. fake (accuracy).
- How often creators successfully fool reviewers (lower detection rates mean better trickery).
They also tested:
- Visual-only vs. visual+audio input.
- Videos with watermarks vs. without.
- Whether asking for reasoning (explanations) before the answer helps.
- Whether choosing the real video from a pair is easier than judging a single video.
What did they find?
Here are the main results:
- Humans are better than AI reviewers at spotting fakes.
- Humans scored about 89% accuracy.
- The best AI reviewer (Gemini 3 Pro Preview) scored about 76%.
- The best AI video generator (Veo 3.1-Fast) made very convincing videos.
- In some tests, the strongest AI reviewer (Gemini 2.5 Pro) was only about 56% accurate—barely better than guessing.
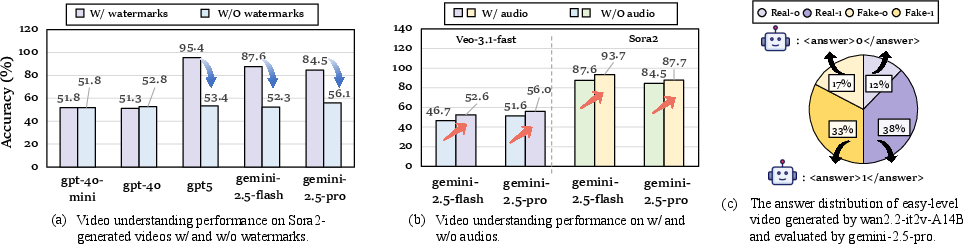
- Audio helps reviewers catch fakes.
- Adding sound raised accuracy by around 5 points overall.
- Many AI-generated audios didn’t match the visuals well (for example, adding human speech to ASMR clips when it shouldn’t be there), which made fakes easier to detect.
- Watermarks can mislead AI reviewers.
- Some AI reviewers learned to “cheat” by spotting a model’s watermark (for example, Sora2’s watermark) and immediately calling it fake.
- When the watermark was removed, accuracy dropped sharply (often from around 95% to about 52%), showing that high scores sometimes came from spotting watermarks, not truly understanding the video.
- AI reviewers tend to think videos are real.
- Across many tests, AI reviewers labeled a majority of videos as real—even when many were fake. This “real bias” means they hesitate to call something fake unless it’s obvious.
Why does this matter?
This study shows that:
- AI can already make very realistic, immersive videos (especially ASMR with close-up actions and sounds).
- Even top AI reviewers struggle to tell real from fake, especially when there are no obvious clues like watermarks.
- Audio checks are crucial—sound that matches the visual action makes or breaks realism.
- Relying on superficial hints (like watermarks) is risky because it doesn’t measure true understanding of the video.
In simple terms: As AI video tools get better, it becomes harder to know what’s real online. This benchmark helps researchers and companies build better detectors that truly understand how visuals and sounds relate. It also encourages making AI systems that don’t rely on shortcuts (like watermarks) and can handle tricky, realistic content. Ultimately, this can help fight misinformation and keep online media trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved by the paper and can guide future research:
- Domain scope limitation: The benchmark is restricted to ASMR content; it is unclear how findings transfer to broader video domains (e.g., conversational, multi-person, dynamic camera motion, narrative scenes, sports, news, long-form videos).
- Scale of real data: Only 149 real videos are retained from 1,400 candidates; the small size may limit statistical power, per-category coverage, and robustness of conclusions.
- Selection bias in real videos: Filtering by YouTube view count (>900k) may bias toward highly-produced, stylized content; impacts on generalization to typical or low-production ASMR remain untested.
- Subjective difficulty labels: “Easy” vs. “hard” splits are heuristically defined; there is no validated, quantitative difficulty metric (e.g., based on measured motion complexity, object diversity, acoustic variability).
- Annotation provenance and bias: Descriptions/storyboards are auto-generated by Gemini-2.5-Pro and clustered via Qwen3-embedding-4B; potential annotation errors or model-induced biases are neither audited nor corrected.
- Audio dimension under-explored: Audio is only partially evaluated (limited model support); there is no standardized, model-agnostic metric for audio-visual synchronization and realism (e.g., onset/offset lag, cross-modal coherence scores, AV misalignment distribution).
- Lack of audio ground truth: The benchmark does not provide aligned ground-truth audio annotations (e.g., timestamps of actions/sounds), impeding precise evaluation of sync errors and causal correspondence.
- Frame-based VLM input: Reviewers observe 8 sampled frames (visual-only or with audio); the effect of full-frame/full-rate temporal coverage on detection performance is not systematically studied or reported.
- Missing ablations on temporal sampling: No detailed analysis of frame count, sampling strategy (uniform vs. motion-aware), or clip duration on detection accuracy and failure modes.
- Watermark confound: Sora2 watermark heavily biases detection; beyond Sora2, the dataset is not comprehensively sanitized for other provenance traces (logos, artifacts, codec/fps signatures), nor is there a standardized watermark-control protocol.
- Audio watermarking and provenance: The paper does not examine audio watermarks or synthetic-audio provenance cues, which could similarly bias detection or create shortcuts.
- Compression and distribution robustness: No evaluation of detection under realistic platform transforms (re-encoding, compression, scaling, cropping, frame-rate conversion, mixed codecs) that may suppress or introduce artifacts.
- Resolution and codec control: It is unclear whether real and generated videos are normalized for resolution, bitrate, and codec; potential shortcut cues from these factors are not analyzed.
- Human study design: The human evaluation uses 100 videos (30 real) with limited details on rater expertise, screening, inter-rater reliability, demographics, hardware/audio setup, or confidence calibration; psychophysical analyses (e.g., time-to-decision) are absent.
- Calibration and bias in VLMs: The strong tendency to predict “real” is documented but not resolved; there is no calibration analysis (e.g., ROC/AUC, ECE/Brier scores) or methods to debias reviewers against base-rate or agreement bias.
- Metric limitations: Reviewer evaluation is based on accuracy; there is no error-type taxonomy (e.g., specific artifact classes), confidence measures, or cost-sensitive metrics to separate different failure severities.
- Limited generalization tests: Cross-domain, cross-dataset, and cross-lingual generalization (e.g., non-YouTube sources, non-English content, varied cultural ASMR practices) are not examined.
- Reproducibility concerns: Closed-source VGMs (manual website use) and evolving model versions introduce non-determinism and version drift; there is no protocol to ensure reproducible generations or stable leaderboard comparisons over time.
- Creator–reviewer coupling risk: Rankings may depend on the specific set of reviewers and their idiosyncrasies; robustness of creator rankings to changes in reviewer pool and vice versa is not established.
- Pairwise vs. single-video evaluation: The paper notes preference tasks are easier but evaluates them narrowly; broader validation across models, content types, and pair construction (matched/unmatched content, same/different seeds) is missing.
- Fairness across generation settings: Start-frame + text vs. text-only vs. text→image→video settings are compared sparsely; the fairness of conditioning (e.g., start-frame quality) across VGMs is not tightly controlled or audited.
- Taxonomy of audio-visual errors: Although qualitative failures (e.g., speech in ASMR) are noted, there is no structured taxonomy or quantitative incidence rates of error types (e.g., temporal desync, timbre mismatch, spatialization errors).
- Data contamination risk: No assessment of whether reviewers (VLMs) have been trained on the same or similar YouTube content; potential contamination could inflate “real” detection or shortcut reasoning.
- Ethical and legal aspects: The paper does not detail licensing/consent for scraping and redistribution of social-media ASMR content or safeguards to prevent misuse of released fakes.
- Hard-negative construction: There is no explicit creation of adversarial hard negatives (e.g., counterfactual edits, near-duplicate re-encodes) to stress-test detection beyond current generators.
- Open-source audio generation gap: Many open-source VGMs lack native audio; the benchmark’s audio dimension currently privileges select models and limits comparability.
- Statistical significance: Reported gains (e.g., +5 points with audio) lack confidence intervals and significance testing; stability across random seeds and sampling variations is unknown.
- Chain-of-thought (CoT) effects: CoT helps some reviewers and hurts others, but there is no systematic protocol to control for hallucinations, step-by-step verification, or constrained reasoning to improve reliability.
- Artifact localization and explanation: Reviewers are not evaluated on localizing artifacts or providing verifiable rationales; moving beyond binary labels to diagnostic explanations remains open.
- Long-horizon realism: The benchmark includes clips up to ~20s but reviewers see sparse frames; how realism and detection scale with longer, more complex multi-step activities remains unexplored.
- Continual benchmark governance: As new creators and reviewers emerge, how to maintain longitudinal comparability (versioning, frozen splits, “evergreen” vs. “live” tracks) is not specified.
- Reviewer training protocols: It is unknown whether training/fine-tuning reviewers on curated, watermark-free, audio-visual-aligned data would reduce shortcut reliance and real-bias; such interventions are not tested.
- Causal cues vs. surface cues: The benchmark surfaces shortcut use (e.g., watermarks) but does not propose or evaluate methods to enforce causal, content-grounded detection (e.g., interventions, counterfactual queries, audio–visual causal tests).
- Automated quality control: The preprocessing pipeline (e.g., background removal, scene segmentation) may introduce artifacts; its impact on downstream detection and realism perception is not audited.
Practical Applications
Practical Applications Derived from “Video Reality Test: Can AI-Generated ASMR Videos fool VLMs and Humans?”
Below are actionable applications that leverage the paper’s benchmark, methods (audio–visual coupling, peer-review creator–reviewer protocol), and empirical findings (audio improves detection, watermark shortcuts, “real” bias, preference vs. single-judgment difficulty). They are grouped by deployment horizon and annotated with sectors, potential tools/workflows, and key assumptions/dependencies.
Immediate Applications
- Content moderation and trust & safety benchmarking
- Sectors: social media, streaming platforms, advertising networks, news/media platforms
- What: Use Video Reality Test to stress-test moderation/VLM pipelines on “real vs. AI-generated” under audio–visual coupling; add “watermark-robust” checks to avoid shortcutting; incorporate a “preference” task (pairwise real–fake) for triage where single-clip judgment is unreliable.
- Tools/workflows:
- Audio–Visual Reality Score API that ingests video+audio and returns a realism score and alignment diagnostics.
- Watermark-Independent Audit: automatic watermark removal and re-evaluation to expose shortcut reliance.
- Reviewer-in-the-Loop dashboards showing creator fooling rates and reviewer false-real bias.
- Assumptions/dependencies: Access to video audio tracks; licensing to evaluate third-party model outputs; compute budget for multi-frame/audio inference.
- Red-teaming and QA for generative video vendors
- Sectors: software, creative tools, VFX/post-production, AIGC startups
- What: Integrate the peer-review protocol as a pre-release regression suite to quantify fooling rates, audio–visual alignment errors, and watermark leakage before shipping new model versions.
- Tools/workflows:
- “Creator–Reviewer Arena” CI pipeline: each new VGM build generates clips from provided start-frames+prompts; internal reviewers (VLMs) score realism; fail gates on spikes in watermark reliance or alignment errors.
- Audio Alignment Linting: rule-based and learned checks for human speech leakage in ASMR-like sequences.
- Assumptions/dependencies: Access to internal generation configurations; ability to synthesize with and without watermarks; standardized prompts and start frames.
- Media forensics calibration and training
- Sectors: cybersecurity, digital forensics labs, broadcast compliance
- What: Use the benchmark as a calibrated “hard case” suite (fine-grained hand–object interactions with tight sound sync) to train and evaluate detectors beyond face-deepfakes.
- Tools/workflows:
- Curriculum construction (easy→hard splits) to stage training and analyst exercises.
- Chain-of-custody reporting templates that explicitly include audio–visual alignment features as evidence.
- Assumptions/dependencies: Legal admissibility standards; stable benchmark hosting and provenance for reference clips.
- Policy-grade procurement tests for AI reviewers
- Sectors: public sector, regulators, elections and information integrity, platform governance
- What: Require vendors of VLM-based detection services to pass watermark-independent tests and audio-enabled reality tests; document bias toward “real” classifications.
- Tools/workflows:
- Certification checklists: audio-on vs. audio-off deltas; watermark removal deltas; pairwise-preference vs. single-judgment performance.
- Assumptions/dependencies: Policy bodies adopt standardized test artifacts and allow third-party audit reports.
- Brand safety and creative QA
- Sectors: advertising, entertainment, branded content, influencer networks
- What: Preflight checks for unintended watermarks, misaligned foley/sound design, or artifacts that could harm brand trust.
- Tools/workflows:
- Foley Alignment Checker: flags speech or out-of-context sounds in “silent”/ASMR-styled spots.
- Watermark Scrub & Re-check: ensures “no watermark” versions maintain realism without triggering detector shortcuts.
- Assumptions/dependencies: Access to final mixed audio stems; support for last-mile QC integration.
- Education and workforce training
- Sectors: academia, professional training, journalism schools
- What: Lab modules that expose students to multimodal deception detection, watermark bias, and preference vs. judgment paradigms.
- Tools/workflows:
- Classroom “arena” exercises where students act as reviewers and analyze failure modes vs. VLMs.
- Assumptions/dependencies: Educational licenses for benchmark access; compute or hosted notebook environments.
- Research baselines and ablation frameworks
- Sectors: academia, industrial research
- What: Use the creator–reviewer setup to study shortcut learning, agreement bias (“real”-leaning), and the contribution of audio to detection; build new metrics for audio–visual consistency.
- Tools/workflows:
- Public leaderboards for both creators and reviewers; automated ablations (frames counts, audio toggles, watermark toggles, thinking prompts).
- Assumptions/dependencies: Continued dataset updates to remain adversarially relevant.
- Fraud/scam video triage
- Sectors: finance, e-commerce platforms, customer support
- What: Add audio-augmented checks to flag scam content where visuals look plausible but audio cues (timing, timbre, background speech) are off.
- Tools/workflows:
- Lightweight pre-screeners performing audio–visual sync scoring before human review.
- Assumptions/dependencies: Access to original audio; privacy and consent constraints.
Long-Term Applications
- Standards and certification for AI-generated media authenticity
- Sectors: policy/regulation, media industry bodies (e.g., SMPTE), platform governance
- What: Formalize audio–visual reality tests (including watermark-neutral protocols) into certification standards akin to “safety case” submissions for detectors and generators.
- Tools/workflows:
- ISO-like conformance suites with periodic re-baselining and “no-shortcut” requirements.
- Assumptions/dependencies: Multistakeholder buy-in; legal frameworks recognizing standardized tests.
- Integrated provenance plus detection ecosystems
- Sectors: tech platforms, camera/OS vendors, standards bodies
- What: Combine content credentials (cryptographic signatures) with watermark-independent detection benchmarks for robust provenance and post-hoc verification.
- Tools/workflows:
- Dual-pipeline validators: verify signed provenance when available; otherwise run audio–visual reality checks with shortcut audits.
- Assumptions/dependencies: Adoption of open provenance standards; cooperation from device and platform vendors.
- Real-time, on-device reality assessment
- Sectors: mobile/edge devices, smart TVs, browsers, AR/VR headsets
- What: Optimize audio–visual detection models for streaming or playback to warn users about potential AI content during consumption.
- Tools/workflows:
- Edge-optimized reviewer models with frame subsampling and low-latency audio alignment heads.
- Assumptions/dependencies: Hardware acceleration; battery and privacy constraints; model compression.
- Adversarial co-training of generators and reviewers
- Sectors: AI model development (video generation and VLMs)
- What: Adopt the peer-review framework as a training signal: RL or adversarial loops where creators minimize detection while reviewers learn robust, watermark-independent cues (physics, contact realism, acoustic consistency).
- Tools/workflows:
- Closed-loop “arena training” with curriculum-scheduled easy→hard ASMR and beyond-ASMR expansions.
- Assumptions/dependencies: Stability of adversarial training; scalable evaluation harnesses; safety controls to avoid misuse.
- Domain-general multimodal fidelity metrics
- Sectors: healthcare (procedure videos), education (lab demonstrations), robotics/industry (operator training), autonomous systems
- What: Generalize the ASMR-derived audio–visual fidelity measures to mission-critical domains where temporal alignment and fine motor realism are essential.
- Tools/workflows:
- Fidelity indices that weight contact mechanics, material acoustics, and temporal causality; sector-specific thresholds for acceptance.
- Assumptions/dependencies: Domain datasets with consented audio; expert-defined realism criteria.
- Insurance, legal, and compliance-grade forensics
- Sectors: insurance underwriting, legal tech, forensic consulting
- What: Use standardized, benchmark-validated detectors as part of evidentiary pipelines and risk scoring for claims involving video evidence.
- Tools/workflows:
- Forensic reports that include watermark-neutral tests, bias profiling, and audio–visual alignment analyses admissible in court.
- Assumptions/dependencies: Judicial acceptance of benchmark-derived validation; independent lab accreditation.
- Consumer-facing authenticity controls
- Sectors: browsers, communication apps, social platforms
- What: Provide “Suspected AI” indicators and user education, especially when audio–visual misalignment is detected or watermark reliance would otherwise mislead detectors.
- Tools/workflows:
- UI affordances that show why a clip is flagged (e.g., “audio timing inconsistent with actions”; “watermark-independent assessment”).
- Assumptions/dependencies: UX acceptance; risk of false positives/negatives; accessibility of audio streams.
- Training next-gen realism-aware VLMs
- Sectors: foundation models, multimodal AI
- What: Pretraining and fine-tuning objectives that explicitly reward consistency across audio and visual modalities, penalize shortcut use, and reduce “real”-leaning bias.
- Tools/workflows:
- Contrastive preference training (pairwise real–fake); debiasing routines; counterfactual augmentation (watermark-in/out).
- Assumptions/dependencies: Large-scale, licensed multimodal data; compute for multimodal optimization.
Notes on feasibility and dependencies across applications:
- Replicability and licensing: Access to and redistribution rights for the curated ASMR data; ongoing maintenance of the dynamic benchmark as VGMs evolve.
- Generalization: While ASMR is a stringent testing ground (fine-grained interactions, tight audio sync), some applications assume transferability to broader content types; domain-specific validation will be needed.
- Model/API constraints: Some VLMs currently cannot ingest image+text+audio concurrently; audio-aware capabilities or workarounds are necessary.
- Arms race dynamics: Creator–reviewer co-evolution demands continuous updates; static detectors will degrade as generators improve.
- Compute and latency: Audio–visual analysis is costlier than visual-only; practical deployments must balance accuracy and real-time requirements.
Glossary
- AIGC (AI-generated content): Content produced by generative AI models, often requiring specialized methods for detection. "Prior AIGC detection benchmarks mostly evaluate video without audio, target broad narrative domains, and focus on classification solely."
- ASMR (Autonomous Sensory Meridian Response): A genre of media designed to evoke sensory tingles using tightly coordinated audio and visual cues. "These cues dominate Autonomous Sensory Meridian Response (ASMR) style videos that convincingly mimic human activities (\eg, cutting or tapping), which are carefully produced for engagement and highly sensitive to perceptual authenticity, thus even minor visual or auditory artifacts break the sensory effect, helping explain why such content readily deceives viewers on social media."
- audio–visual coupling: The tight synchronization and interdependence between audio and visual streams in multimedia. "testing perceptual realism under tight audioâvisual coupling"
- Bhattacharyya distance: A statistical measure of similarity between two probability distributions, used here for detecting scene transitions. "using frame color histograms and Bhattacharyya distance to detect scene transitions (threshold $0.5$)"
- chain-of-thought: A prompting strategy where models generate intermediate reasoning steps before final answers. "reasoning style: prompting VLMs to provide chain-of-thought before answering vs. giving a direct answer;"
- cross-modal denoising: A diffusion approach where noise is removed jointly across modalities to produce synchronized outputs. "MM-Diffusion~\citep{ruan2023mm} first established cross-modal denoising for synchronized audioâvisual generation,"
- creator–reviewer protocol: An adversarial evaluation setup where generators try to fool reviewers who must detect fakes. "An adversarial creatorâreviewer protocol where video generation models act as creators aiming to fool reviewers, while VLMs serve as reviewers seeking to identify fakeness."
- DiT backbones: Diffusion Transformer architectures used as shared backbones for joint modeling in generation tasks. "AV-DiT~\citep{wang2024av}, which achieves efficient joint modeling via shared DiT backbones."
- diffusion-based generators: Generative models using diffusion processes to synthesize high-fidelity, temporally coherent videos. "As diffusion-based generators produce videos with unprecedented realism and temporal coherence,"
- dual diffusion: A synchronization technique leveraging two diffusion processes to improve alignment (e.g., between audio and video). "Synchronization-focused methods such as SyncFlow~\citep{liu2024syncflow} and KeyVID~\citep{wang2025keyvid} further enhance temporal alignment through dual diffusion and keyframe-aware mechanisms."
- fooling rate: A metric quantifying how often generated videos escape detection as fakes by reviewers. "Generators are scored by fooling rate; reviewers by real and fake accuracy."
- frequency-domain inconsistencies: Detection cues derived from anomalies in the frequency spectrum of generated media. "Subsequent studies leveraged frequency-domain inconsistencies~\cite{wang2020cnn,luo2021generalizing}, temporal dynamics~\cite{zi2020wilddeepfake,ni2022core}, and audioâvisual cues~\cite{khalid2108fakeavceleb} to enhance generalization."
- high-order temporal statistics: Complex temporal features (beyond simple motion cues) used to analyze video dynamics for detection. "recent works~\cite{vahdati2024beyond,zheng2025d3,ma2024detecting} have begun exploring motion-level inconsistencies and high-order temporal statistics,"
- keyframe-aware mechanisms: Generation or synchronization methods that explicitly model and leverage keyframes for better temporal alignment. "further enhance temporal alignment through dual diffusion and keyframe-aware mechanisms."
- motion-level inconsistencies: Artifacts or mismatches in motion patterns that can reveal generated or manipulated video content. "recent works~\cite{vahdati2024beyond,zheng2025d3,ma2024detecting} have begun exploring motion-level inconsistencies and high-order temporal statistics,"
- omni-modal foundation models: Foundation models that jointly process multiple modalities (e.g., video, audio) in a unified framework. "Recent omni-modal foundation models (\cite{qwen25omni,qwen3omni}) emphasize unified videoâaudio perception and reasoning,"
- Peer-Review evaluation: A competitive benchmark design where generators and reviewers are co-evaluated in an adversarial setup. "Peer-Review evaluation. An adversarial creatorâreviewer protocol where video generation models act as creators aiming to fool reviewers, while VLMs serve as reviewers seeking to identify fakeness."
- provenance and traceability: Methods for verifying the origin and lifecycle of digital media to ensure authenticity. "while complementary efforts such as SynthID~\cite{deepmind_synthid_blog_2024} address provenance and traceability."
- self-supervision: Learning from inherent structure or synchrony in data without explicit labels. "Early works leveraged natural audio and visual synchrony for self-supervisionâtransferring visual knowledge to audio~\cite{soundnet}, learning audioâvisual correspondence~\cite{lll,spokenmoments}, and advancing sound source separation and event localization~\cite{soundofpixel,ave}."
- silhouette score: A clustering quality metric measuring cohesion and separation of clusters. "Clustering the videos by Qwen3-embedding-4B with maximum silhouette score,"
- sound source separation: The task of isolating individual sound sources from a mixed audio signal. "advancing sound source separation and event localization~\cite{soundofpixel,ave}."
- temporal coherence: Smooth, consistent evolution of content across time in generated videos. "As diffusion-based generators produce videos with unprecedented realism and temporal coherence,"
- temporal consistency: The property of maintaining continuity and stability of visual content across frames. "producing visually coherent and temporally consistent videos that are increasingly indistinguishable from real-world videos."
- video generation models (VGMs): Models that synthesize videos from inputs like text or images. "We evaluate mainstream video generation models (VGMs), including the latest open-source ... and closed-source models (Sora2, Veo3.1-fast)."
- video understanding models (VLMs): Multimodal models that analyze and reason about video content, often with language inputs/outputs. "We evaluate a range of popular video understanding models (VLMs), encompassing both latest open-source ... and proprietary models ..."
- watermark: Embedded visual marks used to indicate origin or ownership that can unintentionally serve as shortcuts for detection. "Adding audio improves realâfake discrimination, yet superficial cues such as watermarks can still significantly mislead models."
Collections
Sign up for free to add this paper to one or more collections.