- The paper introduces a dual-threshold ternary assignment mechanism to filter out unconfident samples, reducing noise in SCOOD tasks.
- The methodology employs a concept contrastive loss that boosts ID/OOD discrimination, leading to improved performance on benchmarks like CIFAR-10 and CIFAR-100.
- Empirical results show that PSA achieves lower false positive rates and higher AUROC, demonstrating computational efficiency and robust detection compared to clustering-based methods.
Predictive Sample Assignment for Semantically Coherent Out-of-Distribution Detection
Introduction and Problem Setting
Semantically Coherent Out-of-Distribution (SCOOD) Detection reframes standard OOD detection by assuming access to labeled in-distribution (ID) data and mixed unlabeled data (containing both ID and OOD samples) during training, reflecting more realistic deployment scenarios where outlier exposure data is noisy and semantically entangled with the source distribution. Existing methods in SCOOD predominantly rely on clustering-based In-Distribution Filtering (IDF), which splits unlabeled data into presumed ID and OOD subsets. Those strategies, however, inject substantial noise into training streams, degrading ID/OOD representational separation and hurting detection efficacy.
This work proposes a concise framework, Predictive Sample Assignment (PSA), exploiting dual-threshold ternary assignment based on predictive energy scores to minimize noise and promote semantic discrimination. PSA excludes unconfident samples from learning, enhances representational distance using a concept contrastive loss, and adopts a staged retraining protocol for full exploitation of selected samples.
Methodology
Limitations of Clustering-Based In-Distribution Filtering
Clustering-based IDF algorithms, which assign unlabeled data to auxiliary ID or OOD pools, suffer from imprecise sample splitting especially during early training phases because of poor feature separability. This leads to persistent noise accumulation in the ID pool and corresponding performance degradation, both for representation learning and subsequent filtering rounds.
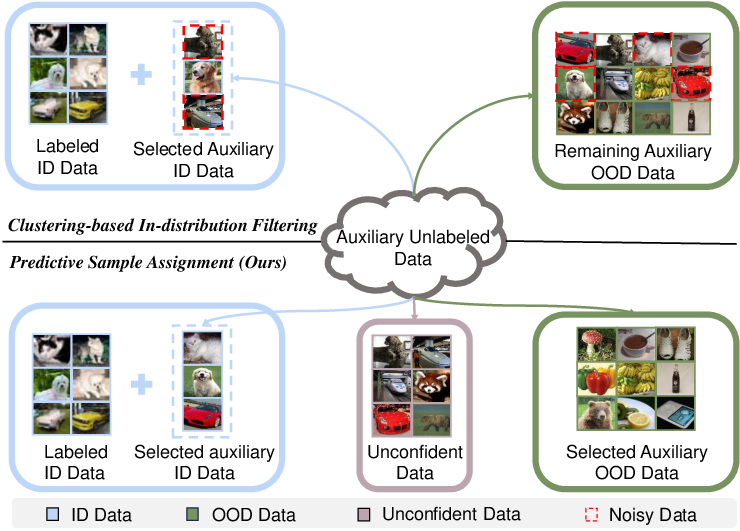
Figure 1: PSA eliminates training on unconfident samples by allocating them to a discard set, resulting in improved semantic discrimination and SCOOD efficacy.
Predictive Sample Assignment (PSA) Framework
PSA circumvents the binary clustering-based assignment limitations by leveraging energy scores (derived from model logits) for robust sample labeling. Using quantile thresholds computed on labeled set energies after a warm-up period, PSA performs a dual-threshold ternary assignment:
- If si>δid: assign sample as ID
- If si<δood: assign as OOD
- Otherwise: discard as unconfident
This mechanism is architecture-agnostic and avoids reliance on clustering, enabling effective filtering even with poor early-stage representations.
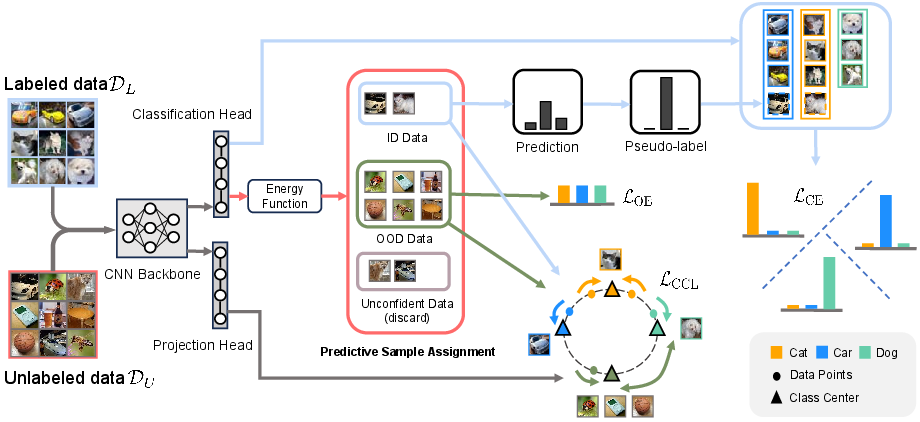
Figure 2: PSA model architecture, showing backbone, classification head, and projection head, along with energy score-based ternary sample assignment and associated losses.
Contrastive Representation Learning
To further reinforce ID/OOD separation, PSA incorporates Concept Contrastive Loss (CCL). All selected OOD samples are treated as a single semantic concept, while ID samples retain their ground-truth semantic labels. This contrastive framework ensures that intra-class embeddings are compact, and ID/OOD inter-class embeddings remain maximally distant.
Retraining Protocol
Given that large quantities of reliable samples are only identified at later training epochs, the model undergoes an additional retraining phase using all final selected ID/OOD samples, bolstered by the labeled training data. This procedure is critical to fully utilize the benefits of reliable assignment.
Empirical Evaluation
SCOOD Benchmarks and Metrics
Experiments are conducted on CIFAR-10 and CIFAR-100 benchmarks with Tiny-ImageNet as unlabeled auxiliary data. Testing involves diverse OOD datasets re-split for semantic coherence. Metrics include FPR95, AUROC, AUPR-In/Out, CCR@FPRn, and accuracy.
PSA consistently outperforms prior SOTA methods including cluster-filtering approaches (UDG, ET-OOD), post-hoc detectors (ODIN, Energy-based), and outlier exposure baselines (OE, MCD). Notably, PSA achieves superior performance across FPR95 and AUROC, indicating a robust tradeoff between false positive rate and overall discrimination.
Ablation Analysis
Ablations reveal:
- Ternary assignment (via discard set) substantially reduces noise compared to binary IDF
- Retraining is essential for maximizing the utility of reliably assigned samples
- CCL is more effective than supervised or self-supervised contrastive alternatives in separating ID/OOD
- PSA’s sample selection purity for both ID and OOD subsets is markedly higher, directly resulting in improved detection metrics
- Joint training via CosineAnnealingWarmRestarts yields nearly identical results to staged retraining
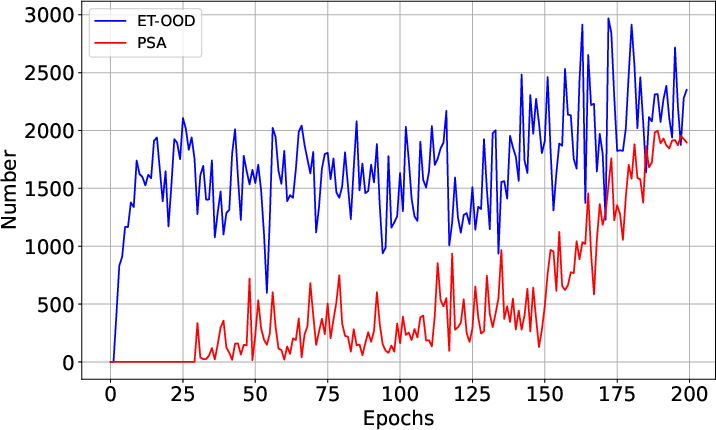
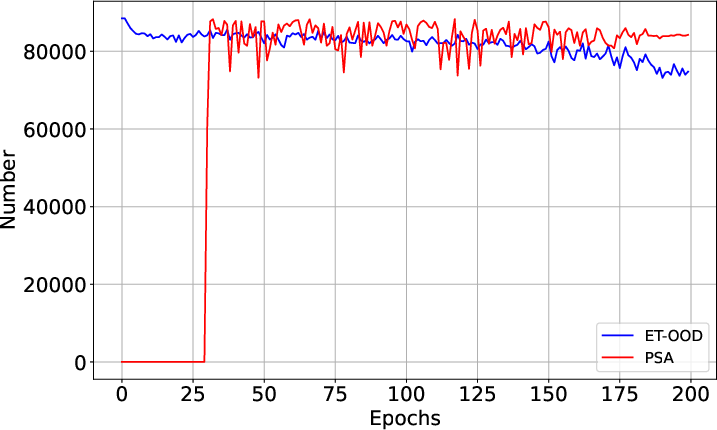
Figure 3: PSA achieves higher purity in both ID and OOD sample assignment compared to ET-OOD, despite selecting slightly fewer clean ID samples initially.
Representation Characteristics
t-SNE visualizations indicate that PSA produces well-separated clusters for ID classes (colored) and OOD samples (dark gray), outperforming both pure cross-entropy and ET-OOD reducers that suffer persistent entanglement.
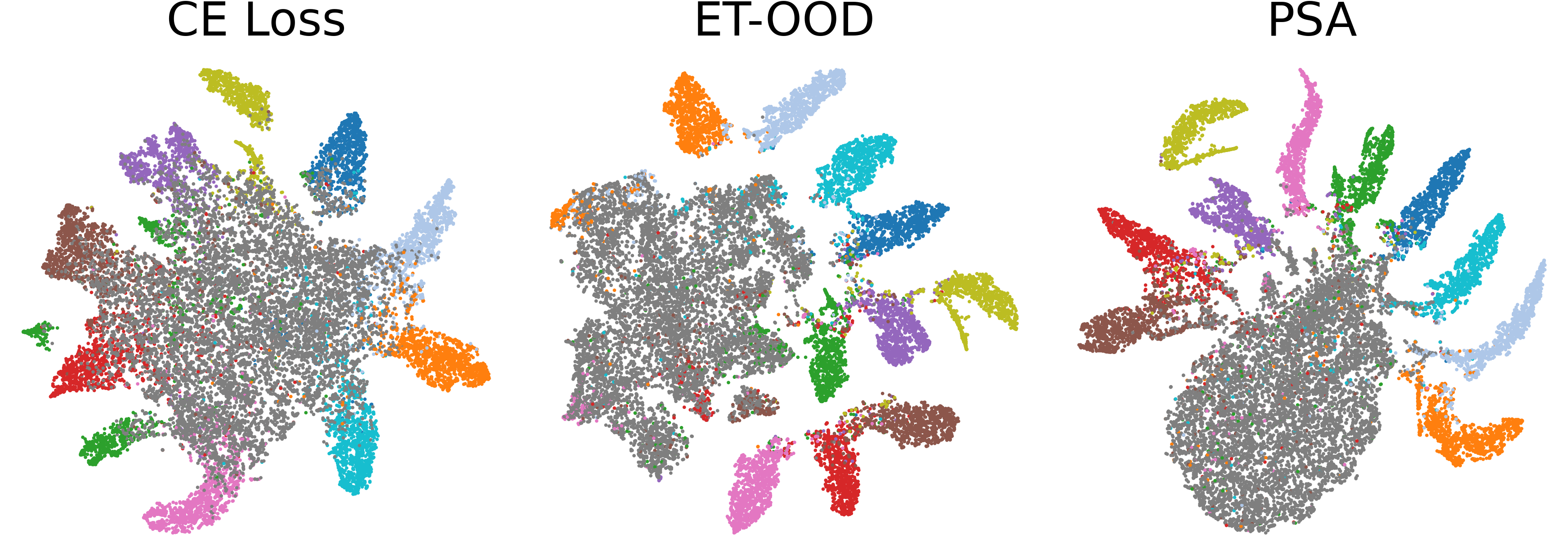
Figure 4: t-SNE embeddings show prominent separation between ID and OOD samples on CIFAR-10 under PSA training.
Hyperparameter Stability
Extensive sweeps demonstrate that PSA achieves stable performance for qid in the 0.8--0.9 range and qood between 0.1--0.3, with robustness to loss weighting and warm-up durations.
Computational Analysis
Despite the extra retraining phase, PSA’s energy-based assignment is computationally efficient relative to clustering-based alternatives. Experimentally, training times are lower than ET-OOD.
Implications and Future Directions
PSA’s ternary assignment paradigm and semantic concept contrastive learning elevate the reliability of SCOOD detection, improving practical robustness in open-world scenarios where labeled and unlabeled distributions are intertwined. The discard of unconfident samples and staged retraining enable the network to focus representation capacity on genuinely separable ID/OOD semantics. This approach motivates future directions in deploying energy-based assignment for other semi-supervised anomaly detection tasks, extending contrastive representational learning to finer sub-OOD semantic decomposition, and integrating PSA into more scalable architectures (e.g., transformers or diffusion models).
Beyond SCOOD, explicit unconfident sample management will likely be valuable in open-set learning, open-world action recognition, and high-stakes domains (autonomous driving, security monitoring) where anomaly class boundaries are inherently fluid.
Conclusion
Predictive Sample Assignment introduces an effective PSA framework for SCOOD by combining dual-threshold ternary labeling, contrastive semantic separation, and retraining. Extensive benchmarking demonstrates state-of-the-art results and strong assignment purity, confirming the advantage of energy-based sample filtering over clustering-based approaches. The analysis substantiates PSA's utility, robustness, and computational efficiency, with practical relevance for realistic open-world deployment and theoretical implications for discriminative representation learning in OOD settings.

