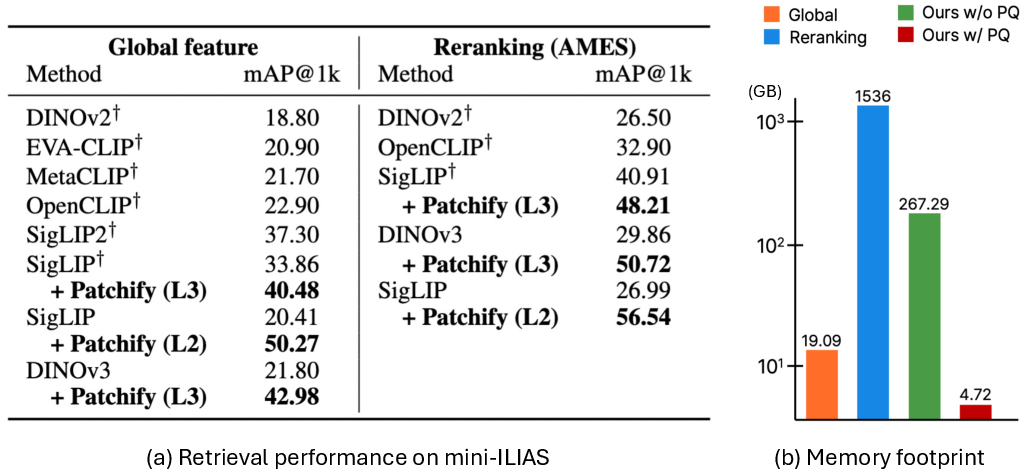
- The paper introduces Patchify, a framework that combines global efficiency with spatially precise patch descriptors for effective instance-level matching.
- The method partitions images into multi-scale patches encoded by frozen visual backbones, enabling efficient retrieval and robust localization.
- Empirical results demonstrate that Patchify outperforms traditional global methods in both retrieval accuracy and computational efficiency.
Patch-wise Retrieval: Practical Techniques for Instance-level Matching
Introduction
Instance-level image retrieval is a key problem in computer vision, requiring precise identification and localization of the same object across diverse images that may present pronounced variation in pose, scale, context, or occlusion. Traditional retrieval pipelines leverage either global features—yielding compact but spatially insensitive descriptors—or dense local features, which increase robustness but often at prohibitive computational and storage costs. The paper "Patch-wise Retrieval: A Bag of Practical Techniques for Instance-level Matching" (2512.12610) introduces Patchify, a structured patch-wise retrieval framework that combines the scalability and simplicity of global methods with the spatial precision of local representations, all without fine-tuning or heavy annotation requirements. The authors further introduce LocScore, a localization-aware evaluation metric, and present comprehensive studies on region selection and large-scale indexing.

Figure 1: Patch-wise retrieval framework overview, contrasting the spatial interpretability and performance of Patchify against global methods.
Patchify Retrieval Pipeline
Patchify partitions each database image into a multi-scale grid of non-overlapping patches. Each patch is independently encoded using a frozen visual encoder (e.g., CLIP, DINOv2), resulting in a set of local descriptors per image. Retrieval proceeds by encoding the query as a global feature and computing similarities between this global descriptor and every patch of each database image. The final ranking relies on the maximum similarity observed among patches for each candidate image.
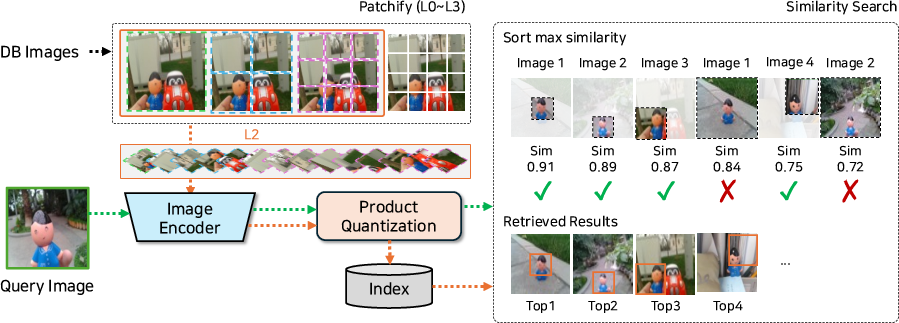
Figure 2: The Patchify pipeline with L2 configuration, showing multi-scale patch extraction, independent encoding, and patch-wise ranking mechanism.
This pipeline provides several advantages:
- Spatial grounding: Patch-level similarity enables explicit attribution of a match to a concrete image region.
- Efficiency: The method uses only a small fixed number of patches per image (dozens, not hundreds as in dense local approaches).
- Plug-and-play: Patchify is compatible with a wide range of frozen high-capacity backbones and requires no fine-tuning.
- Scalability: Patch descriptors are efficiently compressed using Product Quantization (IVFPQ).
Localization-Aware Evaluation: LocScore
Accurate instance retrieval must not only retrieve the correct images but also localize the relevant object within those images. To measure spatial fidelity, the authors introduce LocScore—a metric that weights mean average precision (mAP) by the intersection over union (IoU) between the predicted (retrieved) patch and the annotated ground-truth region. A thresholded variant, LocScore(δ), requires IoU to exceed specified values (e.g., 0.3, 0.4, 0.5) for a positive match. This continuous and thresholded analysis offers both fine-grained and discrete insight into the spatial quality of retrieval.

Figure 3: Comparison between AP and LocScore, highlighting scenarios where perfect ranking does not imply high localization quality.
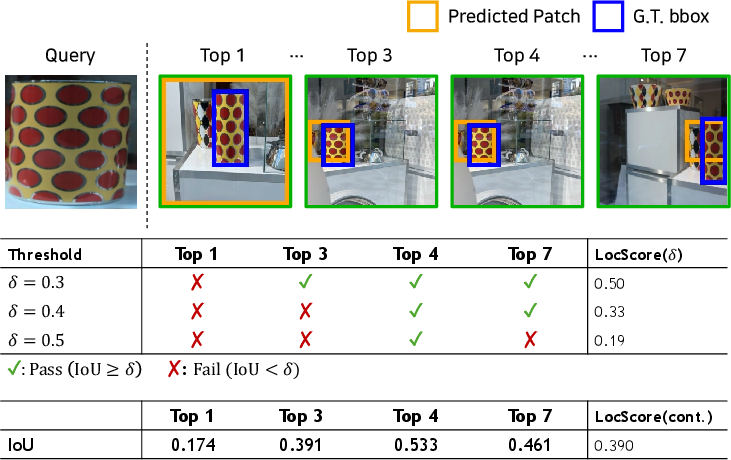
Figure 4: Visualization of LocScore variants as the IoU threshold δ varies, demonstrating continuous and thresholded evaluation sensitivity.
Empirical Results and Ablation Analyses
Experiments across benchmarks such as INSTRE and ILIAS, and using diverse encoders (Transformers and CNNs), robustly demonstrate that patch-wise features significantly outperform standard global features in both mAP and LocScore. In challenging scenarios—small, occluded, or off-center instances—the spatial granularity of patch-based descriptors is particularly advantageous.

Figure 5: Qualitative comparison showing global retrieval failures on non-centered/small instances versus Patchify's consistent localization and retrieval.
Patchify's performance and scalability are further dissected with respect to:
Compression and Large-Scale Retrieval
Patchify's memory footprint is minimized using Product Quantization (IVFPQ). Critically, performance is sensitive to the training features used for PQ: centroids computed from ground-truth box-aligned patches yield the best results, underscoring the need for semantically informative features during compression.

Figure 7: Visualizations of patches used to train PQ indices at different Patchify levels, showing the semantic alignment of ground-truth-based training.

Figure 8: Qualitative retrieval comparisons with different PQ training features at L3—training on ground-truth instances yields superior discrimination.
Despite aggressive compression, Patchify maintains a decisive advantage over global baselines and achieves parity with reranking methods at a fraction (1/5 to 1/6) of the storage and computational cost.
Theoretical and Practical Implications
Patchify demonstrates that a modest number of systematically sampled local descriptors, combined with powerful pretrained encoders, are sufficient for high-fidelity, interpretable, and scalable instance-level retrieval. The research provides several important insights and implications:
- Unified retrieval-localization framework: Integrating patch-wise descriptors and LocScore creates a retrieval system with built-in explainability and diagnostic transparency.
- Efficient memory-computation trade-off: Patchify reconciles the spatial granularity of local methods with the storage and inference speed of global pipelines.
- Guidance for future system design: Findings motivate further work on region selection schemes, on-the-fly region proposal/segmentation integration, and unsupervised or weakly-supervised adaptation of compression schemes.
- Potential for extension: The principles underlying Patchify and LocScore have direct relevance to open-set recognition, visual grounding, and multimodal embedding spaces, especially as foundation models grow in scale.
Conclusion
The Patchify framework advances instance-level retrieval by providing a systematic, practical approach for patch-wise image matching with high interpretability and scalability. The strong empirical superiority of local features and the nuanced analysis enabled by LocScore challenge the dominance of global-only pipelines. The demonstrated efficiency gains, combined with diagnostic clarity, position Patchify as a foundational paradigm for large-scale, spatially-aware retrieval and localization tasks in computer vision (2512.12610).