- The paper introduces Motion Score Distillation (MSD) to decouple motion from appearance, ensuring faithful 3D animations derived from static assets and text prompts.
- It employs a dual-distribution framework with LoRA-tuned static priors and DDIM-based noise estimation to enhance motion fidelity and reduce artifacts.
- Experimental results demonstrate significant improvements over state-of-the-art methods in metrics like CLIP scores, FID, and FVD, validating the approach.
Animus3D: Text-driven 3D Animation via Motion Score Distillation
Introduction and Problem Setting
Animus3D presents a novel framework for text-driven 3D animation, reformulating the canonical score distillation sampling (SDS) paradigm to directly address deficiencies in prior direct video-diffusion distillation. Existing methods rooted in vanilla SDS, though capable of transferring some generative 2D video priors into 3D domain, tend to produce static or visually degraded motion due to the lack of explicit source distribution modeling and uncontrolled entanglement between appearance and motion. Animus3D introduces Motion Score Distillation (MSD) to overcome these fundamental issues and achieve animation sequences displaying substantial motion and visual integrity from static 3D assets and motion-descriptive text prompts.
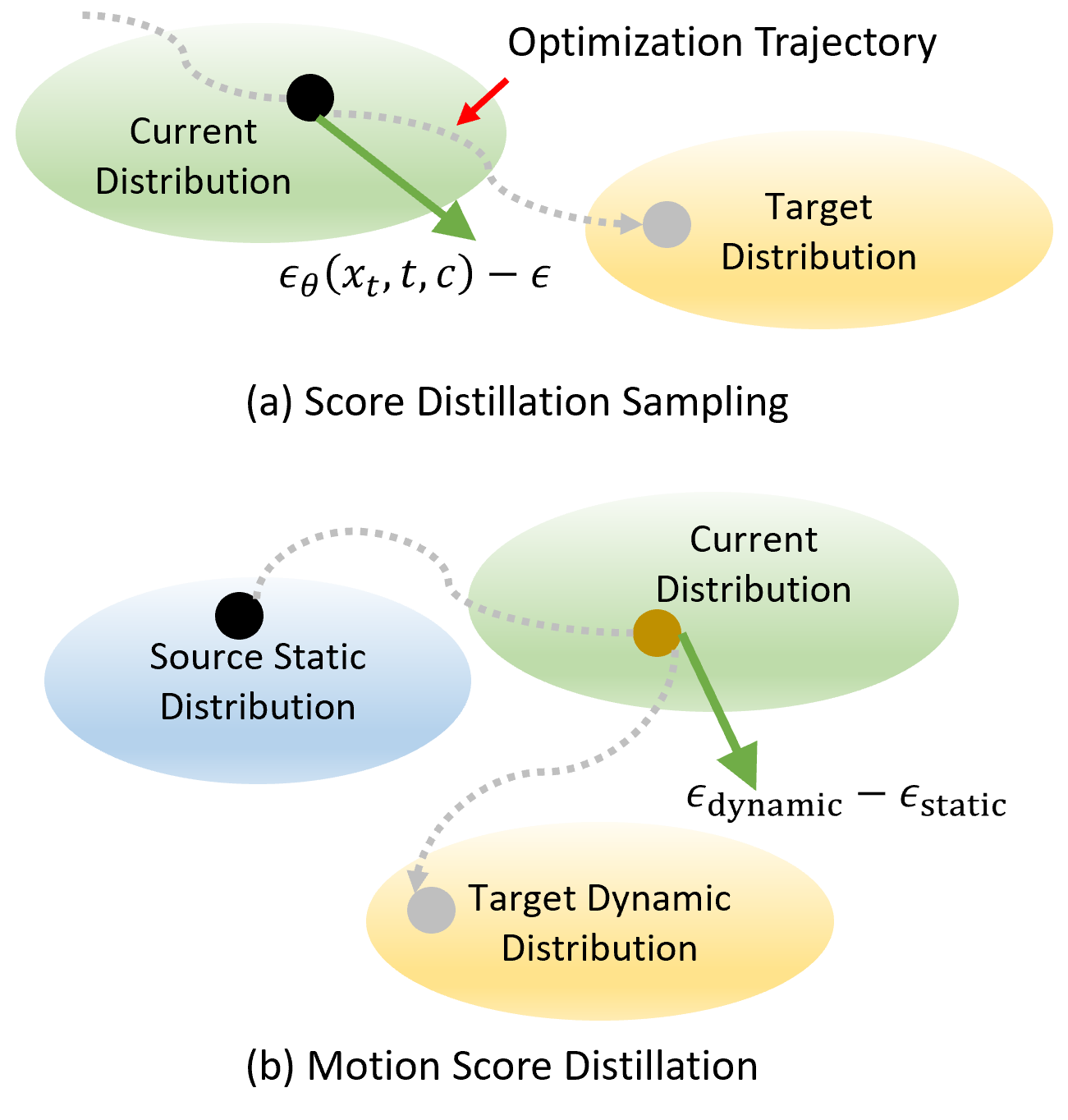
Figure 1: Comparison between the classical SDS and the proposed MSD formulation, illustrating how MSD provides a principled separation of appearance and motion supervision.
Methodology
The core contribution is the reconceptualization of SDS: instead of distilling gradients from a noise-centered stochastic domain into the 3D representation, Animus3D establishes a dual-distribution framework. The approach defines two domains—static and dynamic—where the static domain is modeled via a Low-Rank Adaptation (LoRA)-tuned video diffusion model trained to synthetically generate static video sequences faithful to the original asset, and the dynamic domain corresponds to the target articulated motion per user prompt.
The gradient for motion field optimization is then given as the difference between the noise predictions for dynamic and static renderings of the scene, sampled and rendered via 3D Gaussian Splatting (3D-GS) and subsequent deformation fields. The static-noise predictor is fine-tuned to be strictly appearance-preserving, detaching motion supervision from potentially destructive appearance-related gradients present in vanilla SDS.
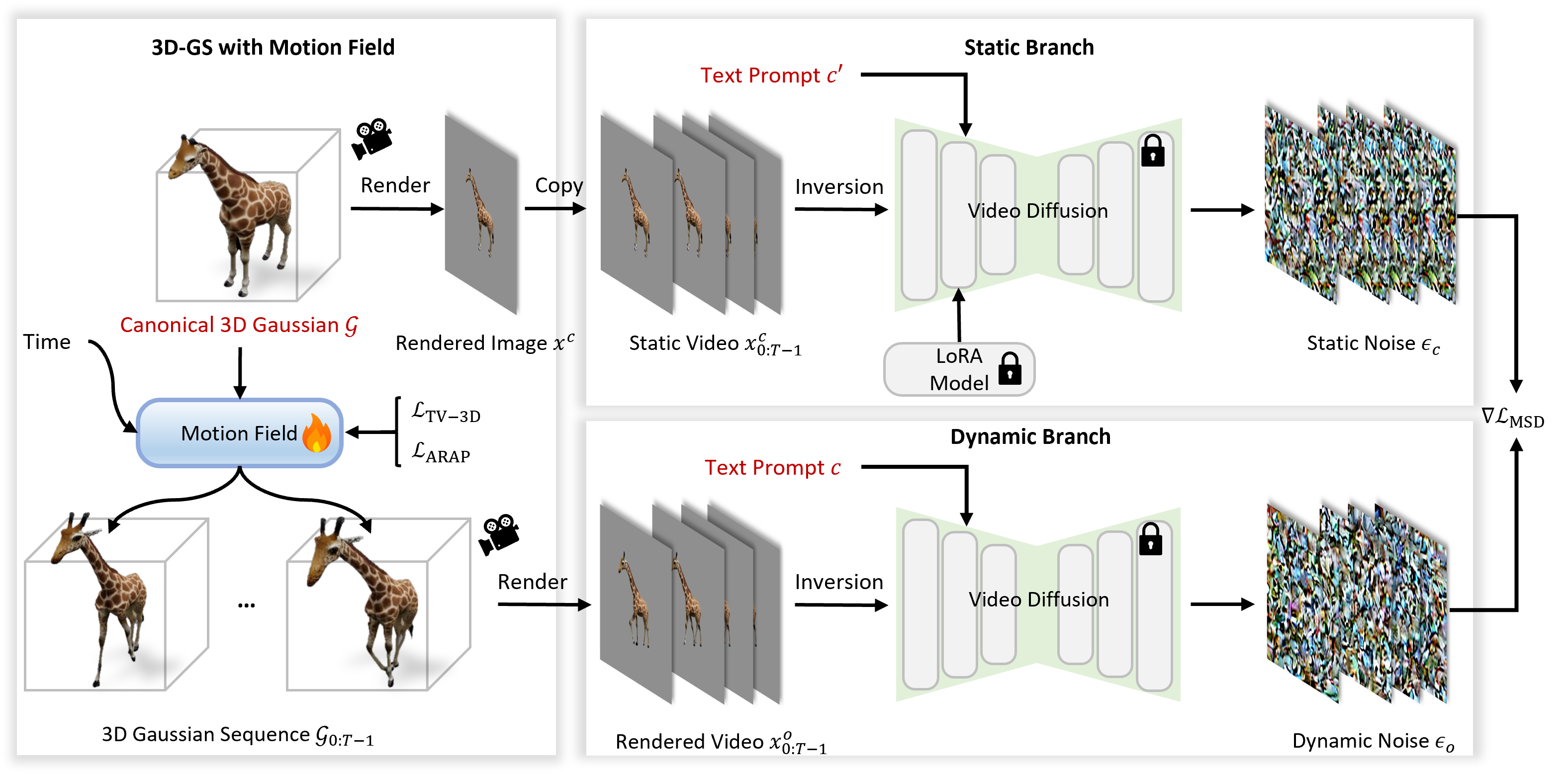
Figure 2: Architecture overview—3D Gaussians are deformed via a learnable motion field, rendered to video, and supervised through dual distributional guidance and LoRA-tuned static diffusion priors.
Faithful Noise Estimation
To disentangle motion from appearance and suppress spatial or temporal artifacts, the framework replaces the unconstrained stochastic noise schedule with faithful, inversion-based noise estimation using DDIM inversion. This approach ensures image reconstructions post-denoising remain semantically consistent with the underlying 3D shape, reducing visual drift and background hallucination observed in standard SDS settings.

Figure 3: Comparison of denoised reconstructions using vanilla SDS and MSD, highlighting improved appearance preservation and reduced background artifacts with MSD.
Motion Field Regularization
MSD is augmented by two explicit geometric regularizers for the 4D Gaussian splatting domain:
Motion Refinement Module
Given the inherent frame length limitations of off-the-shelf video diffusion backbones, the framework attaches a secondary refinement stage using a rectified flow-based video diffusion model. This module increases the temporal granularity and continuity of generated sequences, facilitating extended and more naturally dynamic animation.
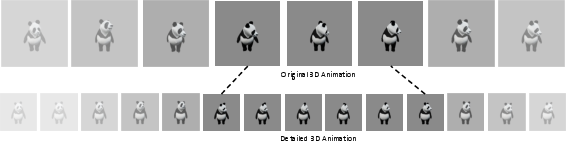
Figure 5: Motion refinement yields finer-grained, temporally extended 3D animations as compared to fixed-length base video diffusion outputs.
Experimental Results
Quantitative and Qualitative Evaluation
Animus3D significantly outperforms prior state-of-the-art (AYG, TC4D) in all critical metrics, including CLIP-Image (93.04 vs. 91.75/90.99), CLIP-Text (51.05 vs. 44.31/50.02), as well as lower FID (88.50 vs. 105.33/179.14) and FVD (204.1 vs. 647.6/340.0). These improvements directly follow from the MSD framework’s ability to synthesize substantial, high-fidelity motion while suppressing the appearance drift and geometric degeneracy prevalent in single-distribution SDS.

Figure 6: Qualitative comparison with state-of-the-art systems, demonstrating superior motion expressiveness and fidelity of Animus3D-generated sequences.
Moreover, user preference studies reflect consistent favor towards Animus3D in terms of overall quality, appearance preservation, and motion characteristics.
Comparison with Articulated Baselines
Direct comparison to structure-constrained or heuristic-specific frameworks (e.g., AKD, TC4D) demonstrates that Animus3D’s data-driven, dual-distribution supervision framework generates more organic, less constrained motion, without the perceptual stiffness inherent to skeleton-based or physically-rigidity-enforced approaches.

Figure 7: Stiff, sparse skeletal motion from AKD contrasts with the fluid, visually coherent 3D motion of Animus3D.
Ablation Studies
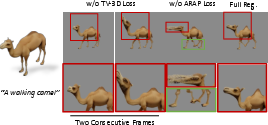
Ablative analysis reveals that: (1) MSD’s dual-distribution gradient is essential for substantial motion; (2) exclusion of faithful noise estimation causes catastrophic appearance corruption; (3) LoRA-tuned static priors are essential for stable initialization—forgoing this leads to content drift and “ghost” artifacts; (4) omission of either TV-3D or ARAP regularizers induces flicker or non-physical motion, respectively.

Figure 8: Comparison between different score distillation methods; only full MSD provides both large and realistic motion while maintaining fidelity.
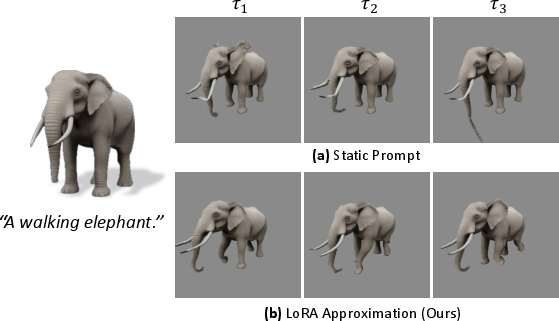
Figure 9: Role of static distribution modeling—the LoRA route is strictly required for preventing local distortion during animation.
Limitations and Future Prospects
Animus3D is currently constrained by the capacity of its deformation field (limited to mesh-deformable or Gaussian-representable structure; cannot instantiate new topology such as particle ejection or fluid emergence) and by motion sequence duration (bounded by the backbone video model’s fixed window). Synthesis time remains non-trivial (~hours), a persistent limitation of gradient-based score distillation. Potential advances include efficient amortization, explicit topology augmentation mechanisms, and exploitation of higher-fidelity video priors.

Figure 10: Failure case—fluid/particle generation (e.g., rocket exhaust) is out of scope for pure Gaussian deformation-based animation.
Conclusion
Animus3D establishes a scalable, effective methodology for text-driven 3D animation, leveraging Motion Score Distillation to explicitly separate appearance and motion supervision with faithful noise inversion and dual-distribution modeling. This produces substantial, temporally smooth, and visually consistent motions from static assets and natural language prompts. On both quantitative and qualitative metrics, Animus3D leads among score distillation animation approaches. Extensions in dynamic topology and compute efficiency define key directions for its broader adoption and practical impact within both neural graphics and generative 3D modeling.