- The paper introduces a reinforcement learning framework that dynamically hedges options using engineered features to capture market context.
- It integrates practical considerations like transaction costs, slippage, and position limits, yielding a controlled positive Sharpe ratio in stress scenarios.
- Experimental results demonstrate that blending the RL overlay with long SPY improves the mean-variance profile by reducing volatility and drawdowns.
Deep Hedging with Reinforcement Learning for Option Risk Management: Framework, Results, and Implications
Introduction
The paper "Deep Hedging with Reinforcement Learning: A Practical Framework for Option Risk Management" (2512.12420) presents an extensible RL-based framework for dynamic hedging of equity index option exposures. The approach targets realistic production settings, incorporating transaction costs, position limits, and slippage, and eschews reliance on handcrafted delta heuristics or model-based Greeks. Instead, the policy extracts interpretable signals from engineered features describing the option surface and macroeconomic activity, such as implied volatility, skew, rates, and realized volatility.
The construction is motivated by empirical fragility observed in SPX/SPY overlay desk practices: the joint dynamics of VIX, term structure, and rates over the 2005–2023 window exhibit pronounced nonstationarity and regime shifts, rendering rule-based overlays error-prone in stressed or rapidly evolving conditions.
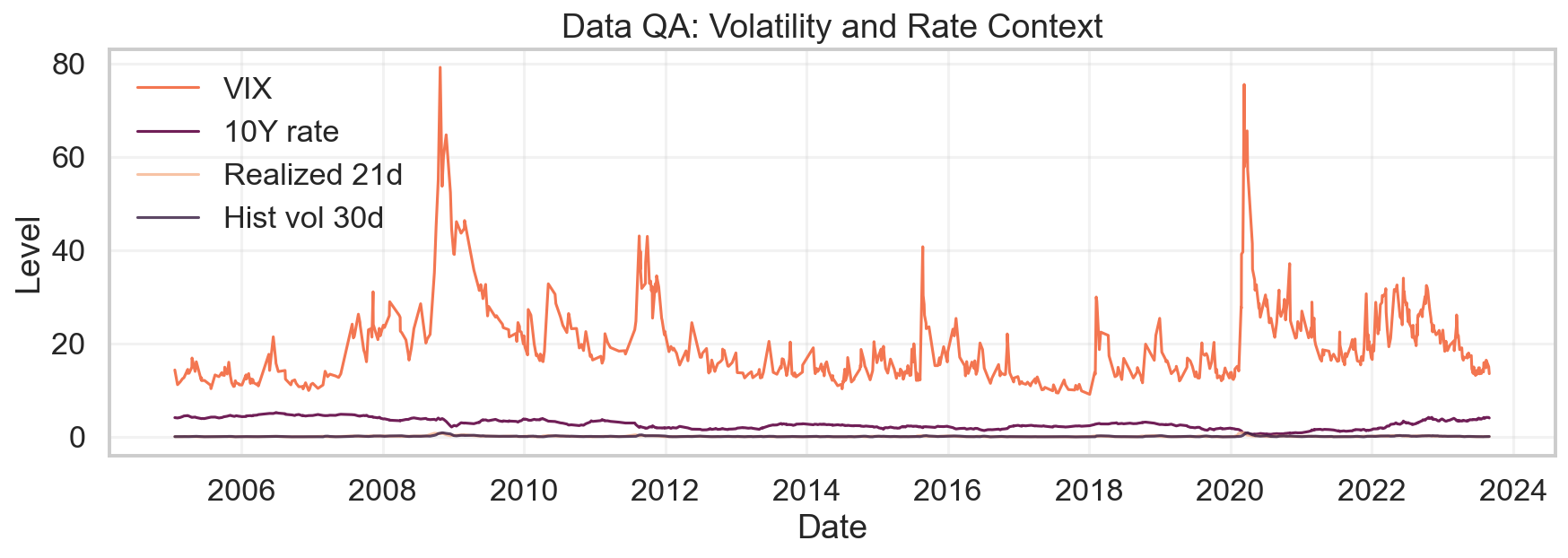
Figure 1: Long-horizon view of VIX, 10Y rates, realized 21d volatility, and 30d historical volatility.
Methodology
Data Pipeline and Feature Set
Data engineering centers on a daily panel combining SPX/SPY return series with ATM and 25-delta implied volatilities (30d, 91d tenors), VIX, 10Y rates, realized/historical volatilities, and term-structure and skew features. Rigorous quality filtering and guarded forward-filling minimize look-ahead bias and contamination from illiquid OTM strikes. Forward returns for policy evaluation are strictly close-to-close with alignment to action timestamp.
Hedging Environment
The environment (HedgingEnv) is deterministic and modular, with each step providing a rolling observation matrix (window × engineered features). Continuous hedge levels at are linked to option exposure units, with transaction costs proportional to position changes, optional slippage (linear/quadratic impact per the Almgren–Chriss paradigm), and position limits enforced. No direct Greeks are injected; rather, the agent observes high-level market context.
RL Agent Design
A compact two-layer MLP (256 units, tanh activations) serves as both policy and value function approximator. Stochasticity arises from a squashed Gaussian output, yielding continuous, bounded actions. The reward function scales per-step PnL to basis points for numerical stability. Training employs GAE-regularized policy gradients with mild entropy encouragement (coefficient 0.01), γ=0.99, and gradient clipping, followed by model selection on Sharpe-optimal validation checkpoints.
Experimental Results
Across the long walk-forward split (2005–2023), the RL overlay (GAE agent) consistently delivers a positive post-cost test Sharpe, outperforming no-hedge, VIX-band, and volatility-targeting overlays. Deterministic test window Sharpe is $0.50$ for the standalone overlay under 10bps transaction costs and 8bps slippage, with controlled turnover (<1 notional turnover per day on average) and drawdown (standalone overlay-equity drawdown within −3%). The Sharpe for the GAE overlay is the only one statistically distinguishable from zero under Newey–West SE and bootstrap analysis, although its confidence interval overlaps with long SPY.
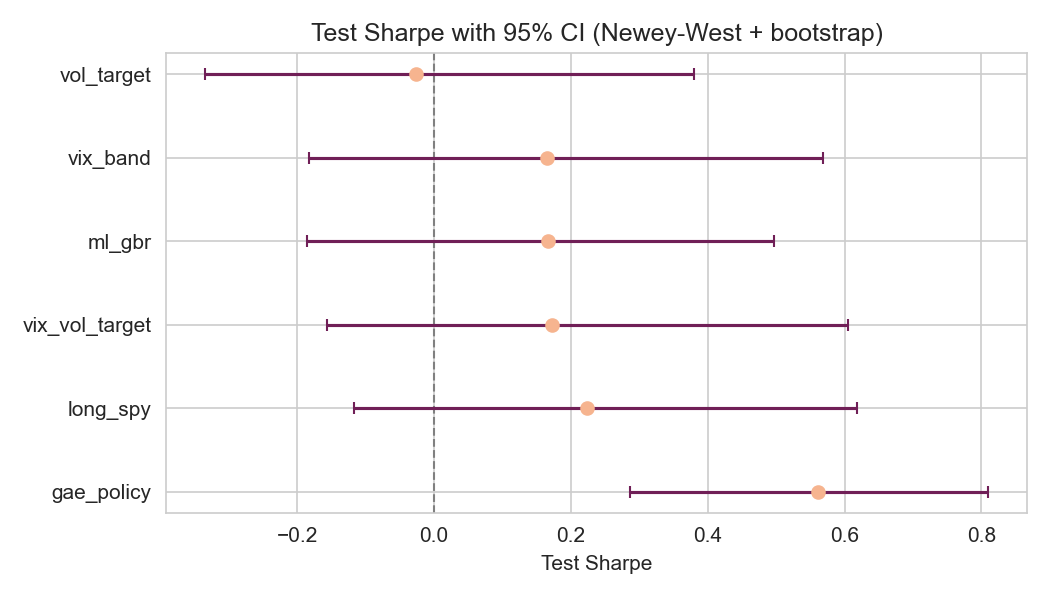
Figure 2: Test Sharpe with 95% confidence intervals from Newey–West SEs and block bootstrap (test split).
Regime Attribution
Volatility-regime disaggregation reveals the overlay's strongest outperformance relative to benchmarks occurs during high-VIX states; moderate positive contribution is observed even in low-volatility regimes, while rule-based overlays tend to suffer in calm periods without compensating tail performance.
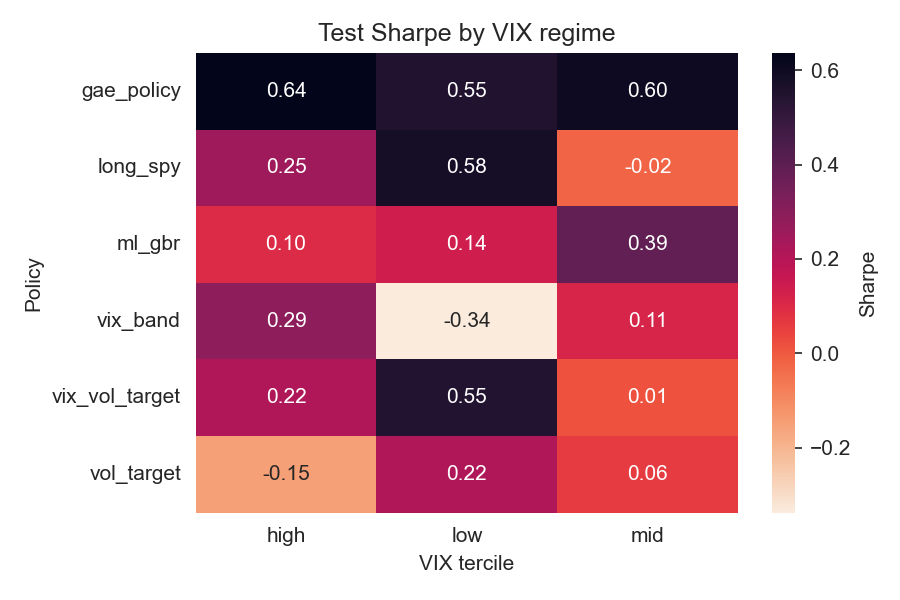
Figure 3: Test Sharpe by VIX tercile for each policy on the test split.
Portfolio Blending
When capital is blended 50% into the RL overlay and 50% into long SPY, the resulting position tracks a much more favorable mean-variance frontier. Annualized volatility is nearly halved relative to pure SPY, while most of the total CAGR is retained. Efficient frontier sweeps show concavity: incremental GAE allocation increases risk-adjusted return until capital is mostly deployed in the overlay. Rolling risk differential diagnostics confirm systematic realized risk suppression by the overlay, with negative volatility and drawdown differentials prevailing across the test window—including during crisis periods such as Q1 2020 and 2022.
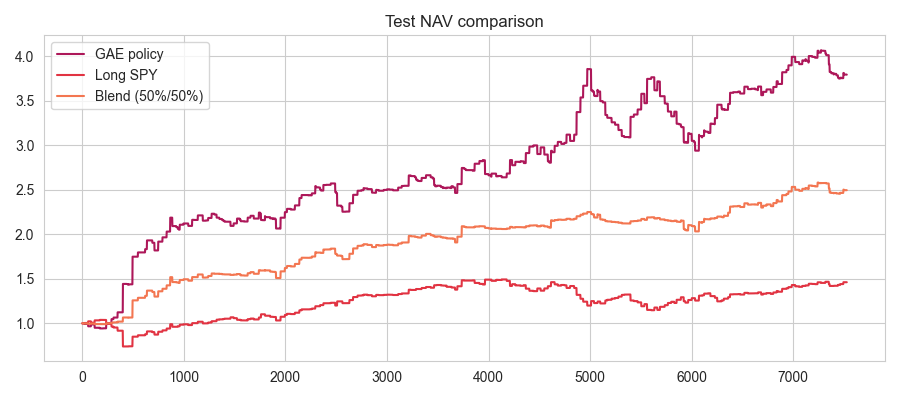
Figure 4: Test NAV overlay for a blended strategy that allocates 50% to GAE and 50% to long SPY.
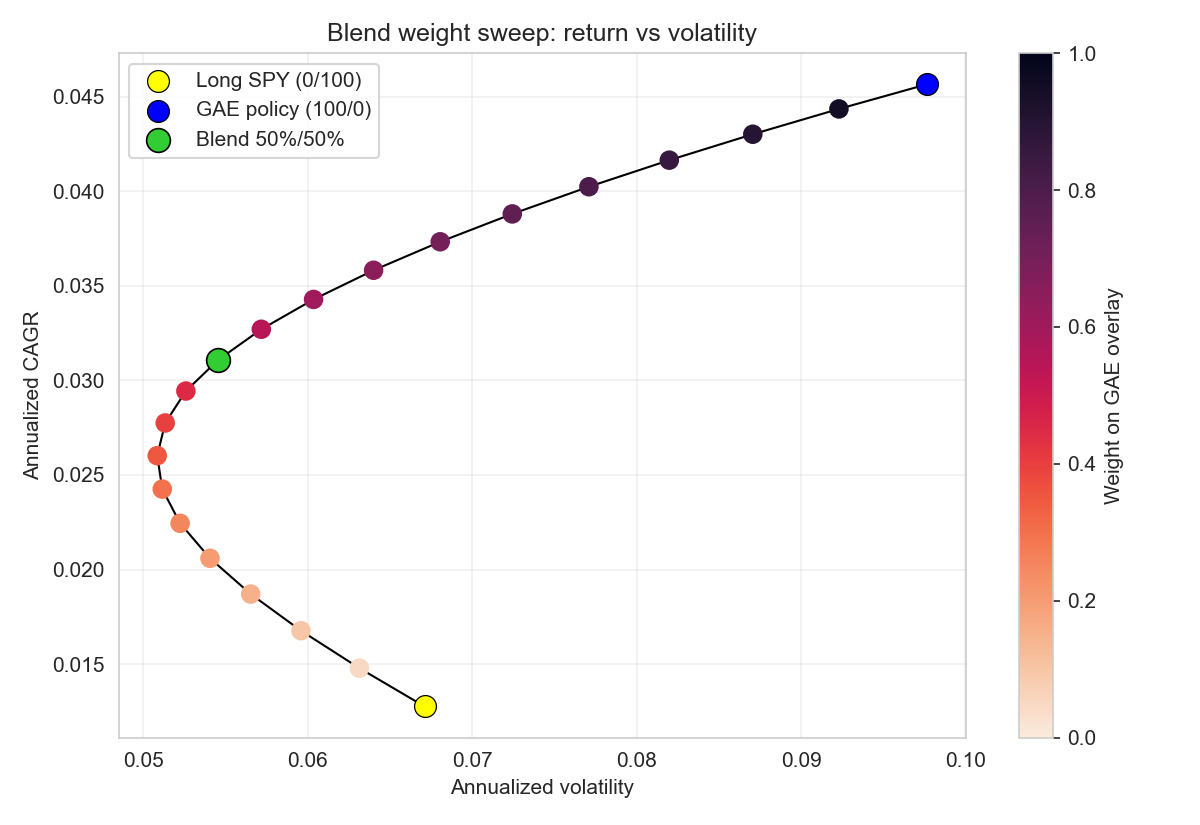
Figure 5: Blend weight sweep showing the efficient frontier as capital shifts between the overlay and SPY (color indicates GAE weight).
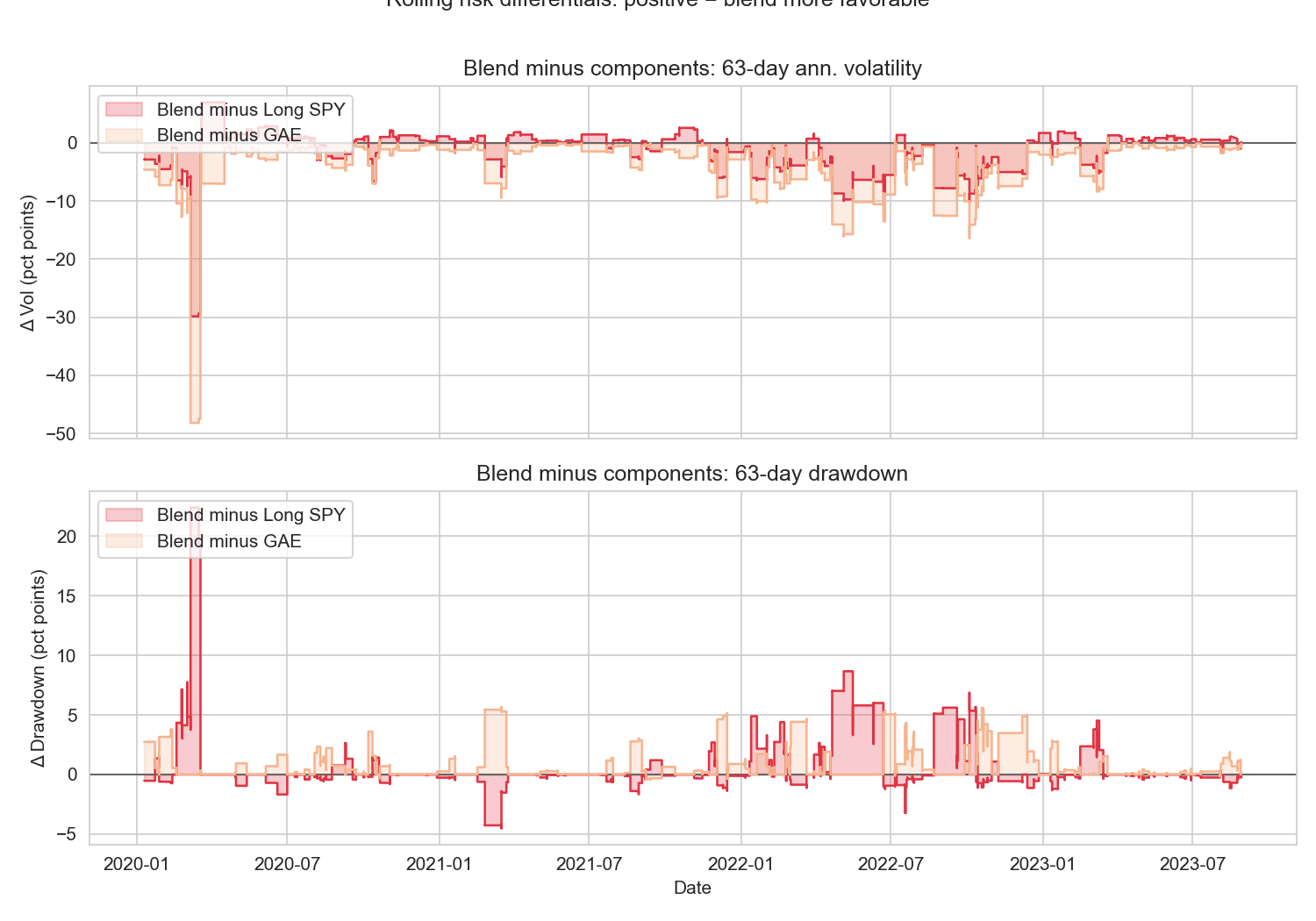
Figure 6: Rolling risk differentials showing 63-day volatility and drawdown of the blend minus each component (negative values are better).
Training and Robustness
Training diagnostics reveal that the episode return distribution is heavy-tailed due to financial time series properties. The robustness check across seeds and shifted splits shows modest variance; the base and shifted test Sharpe averages are $0.45$ (std $0.13$) and $0.52$ (std $0.05$) respectively. This suggests the policy generalizes out-of-sample provided walk-forward discipline.
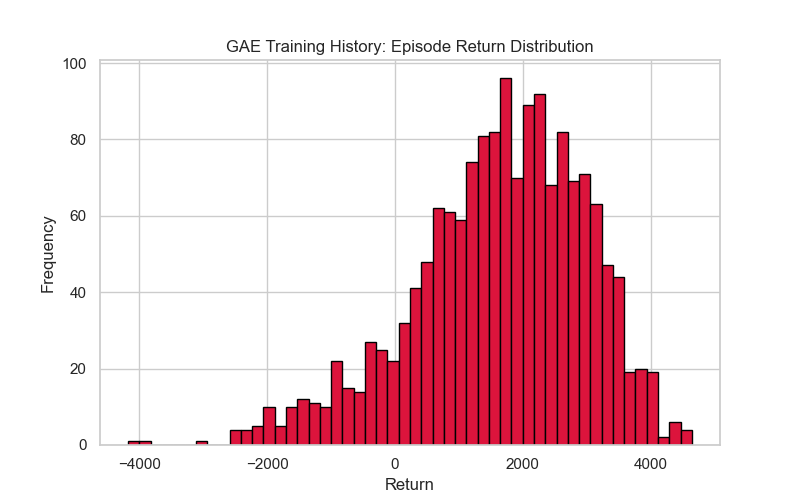
Figure 7: Episode return distribution from the training notebook (episode returns, not per-step bps).
Practical and Theoretical Implications
The proposed deep hedging RL overlay offers an interpretable, cost-aware alternative to both static Greek-based hedging and ad hoc rule-based overlays. By consuming engineered, explainable features and not relying on option pricing model assumptions (e.g., Black–Scholes), the policy remains robust to regime changes and observable drift in volatility surfaces and rates.
From a portfolio management perspective, the overlay is best utilized as a completion sleeve rather than a standalone alpha strategy: it aims to systematically improve the mean-variance profile of an existing SPX/SPY allocation, specifically by dampening portfolio drawdowns and realized volatility, with tightly managed turnover and cost drag. Risk managers benefit from the auditability of actions, which can be mapped to feature-level drivers rather than abstract neural representations.
The framework supports straightforward extension to multiple assets, alternative risk objectives (CVaR, drawdown constraints), intraday bars, and can incorporate dynamic execution cost models. The codebase and experiment design facilitate deterministic reproducibility, supporting, for instance, regulatory or governance-mandated post-trade analysis.
Outstanding limitations include the focus on daily cadence (intraday effects are outside scope), lack of exhaustive architecture/model search, and the absence of granular per-trade explainability. Statistically significant outperformance over SPY is not established; rather, robust positive Sharpe at the overlay level is emphasized. Future directions involve exploring alternative reward specifications (e.g., with explicit downside risk Aversion), further interpretability advances, and adaptation to evolving liquidity and volatility landscapes.
Conclusion
This research validates the operational viability of RL-based deep hedging overlays for option exposure management. By combining engineered observable features with a reproducible, deterministic evaluation protocol and robust environment design, the solution achieves controlled positive risk-adjusted returns under practical cost and execution limits. The framework is inherently extensible, serving as a foundation for both production overlay deployment and further academic or practitioner development in RL-based risk management. The open implementation enables independent benchmarking, extension, and effective governance integration for institutional portfolios.

