- The paper introduces a hierarchical Random Forest model that achieves median recall and precision above 86% in identifying VLM spectral blend binaries.
- It constructs a rigorous synthetic dataset from empirical NIR spectra and demonstrates superior performance over classical index-based methods.
- The approach scales to large surveys, offering rapid component classification while highlighting challenges with similar component binaries and flux imbalances.
Machine Learning Identification and Characterization of Very Low Mass Spectral Blend Binaries
Introduction: Scientific Context and Challenges
The identification and characterization of unresolved very low mass (VLM; M≲0.1M⊙) binaries—specifically systems comprising late-M, L, and T dwarfs—provides critical constraints on star and brown dwarf formation, substellar mass function, and atmosphere physics. Traditional imaging and radial velocity surveys suffer from substantial selection incompleteness for close-separation binaries, motivating spectroscopic blend techniques. In the near-infrared, blends of L and T dwarfs display distinct molecular absorption (e.g., CH4, H2O) yielding composite spectra divergent from single objects.
Historically, binary identification in this regime has utilized manually constructed spectral indices and template fitting (Burgasser et al. 2010; Bardalez Gagliuffi et al. 2014)—approaches which display limited recall, significant contamination, and suboptimal performance for near-equal or low-flux-ratio binaries. The proliferation of high-cadence, high-volume survey data necessitates automated, robust classification pipelines capable of leveraging the full spectral information content.
Methods: Random Forest Model Development and Training Data
To address these limitations, the study implements hierarchical Random Forest (RF) classifiers and regressors, trained on synthetically generated spectral data. The training set construction is methodologically rigorous: starting from a curated library of 1006 empirical IRTF/SpeX NIR spectra (M6–T9), the dataset is augmented to balance S/N and spectral type density. Three distinct S/N regimes are established, controlling for spectral fidelity (Figure 1).
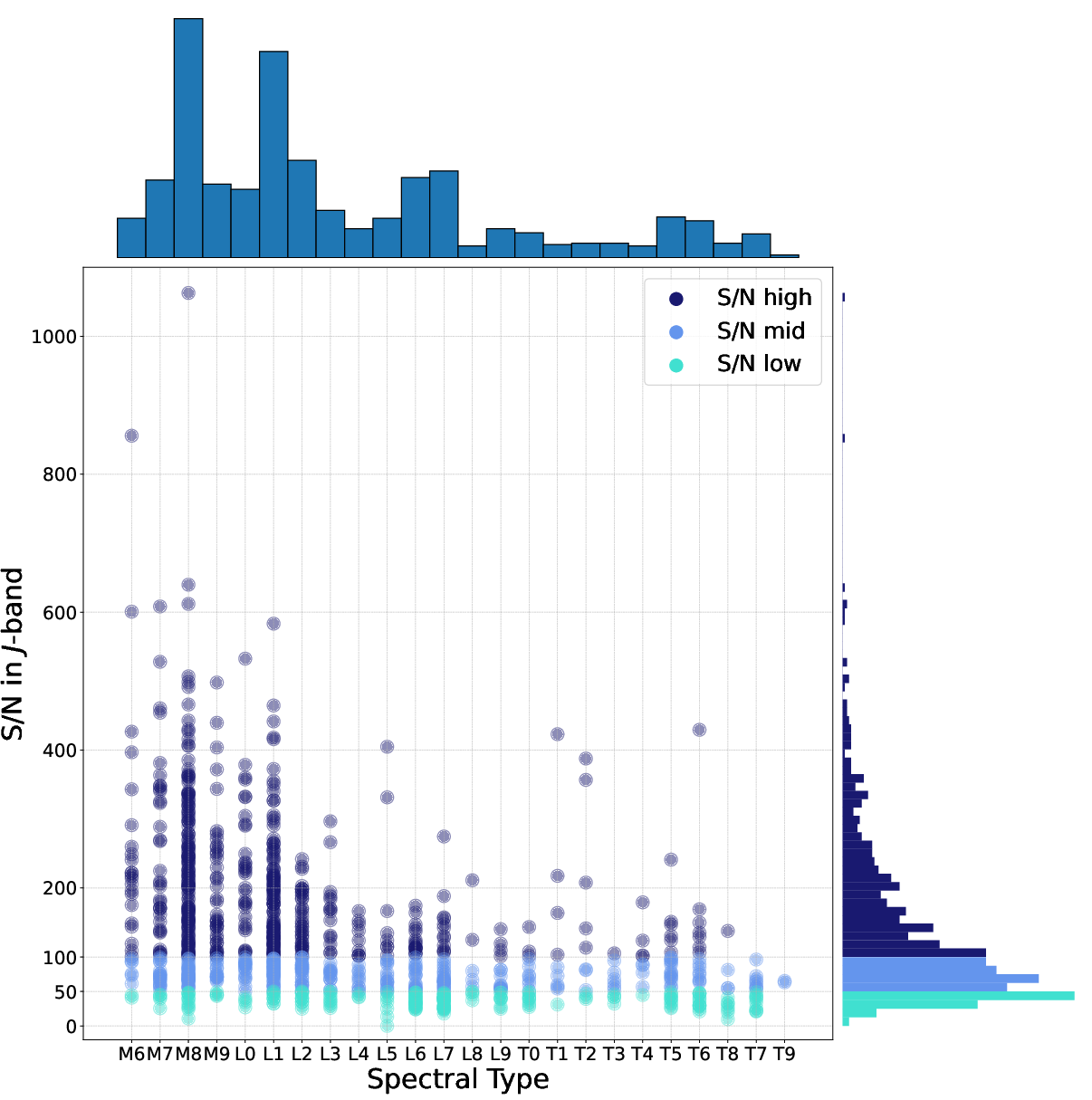
Figure 1: Distribution of J-band S/N vs. spectral type for the empirical sample. Color encodes S/N category assignment.
Synthetic binary templates are created by empirically pairing single spectra, scaling with the MJ/SpT relation, and renormalizing to suppress selection artifacts. The overall set comprises O(104) blended and single templates per S/N bin, with Monte Carlo flux perturbations to simulate observational variance.
RF architectures are optimized via cross-validated tuning of the ensemble size, tree depth, and leaf splitting thresholds. Input features include normalized flux values (λ=0.9–2.4\,μm), optionally concatenated with difference spectra (relative to best-fit single templates) and variable telluric masking.
Benchmarking Classical Index-Based Approaches
The study benchmarks the classical index-based methods of B10 and B14 using this synthetic sample. The recall for B10 and B14 is strongly dependent on binary component combination and S/N, with aggregate recall failing to exceed 66% even in the most favorable combinations. Performance outside the initial target ranges collapses sharply, particularly for equal-type binaries, late-M pairs, and extreme flux ratios.
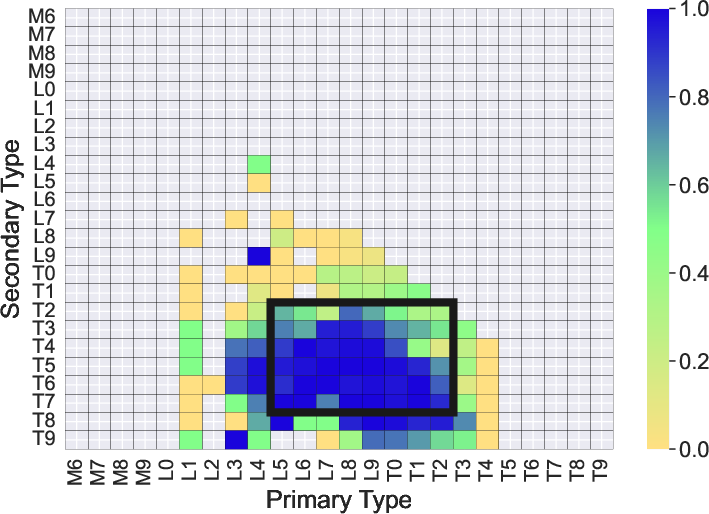
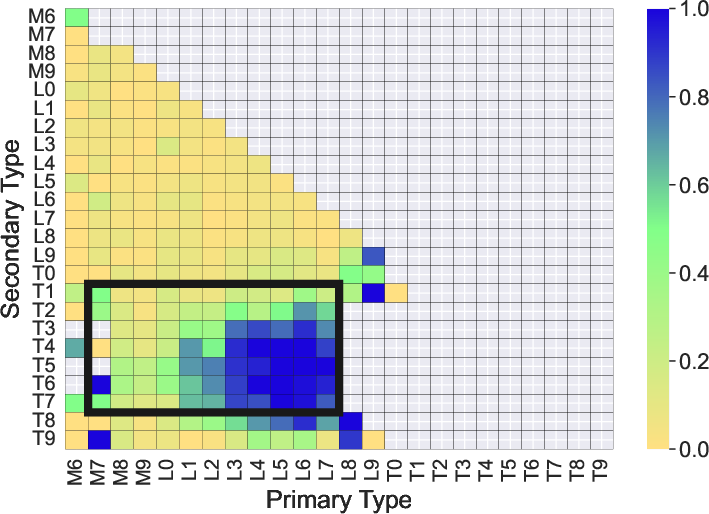
Figure 2: Recall performance mapped as a function of binary component types for the B10 (left) and B14 (right) index-based methods.
The RF binary identification models (BId N) show high performance and stability across S/N regimes and model variants. The baseline BId1 model achieves median recall and precision ≳ 86%, with F1-scores ≳ 0.88. The ROC curves show AUC≥0.95 (Figure 3), indicating negligible loss from true/false positive trade-offs. Specialized training on the B14 and B10 ranges yields best recall ≳0.9 only for those spectral regions, underperforming the fully-general model elsewhere.
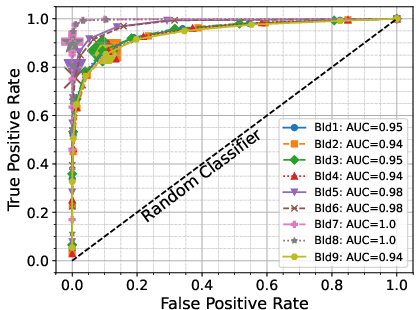
Figure 3: ROC curves for the nine BId models, highlighting true vs false positive tradeoff and signal fidelity. Large symbols: default 0.5 classification threshold.
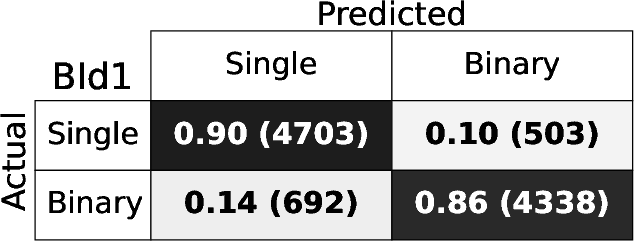
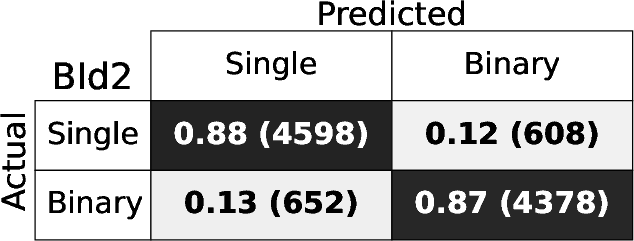
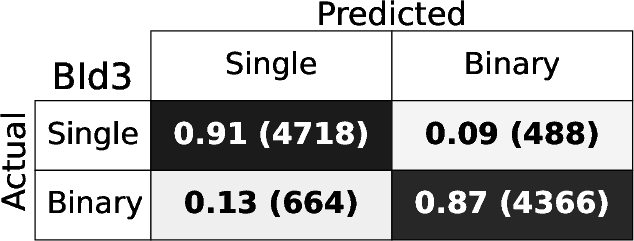
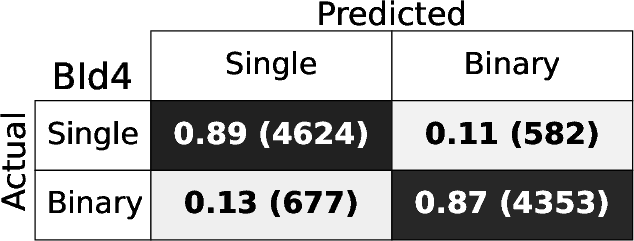
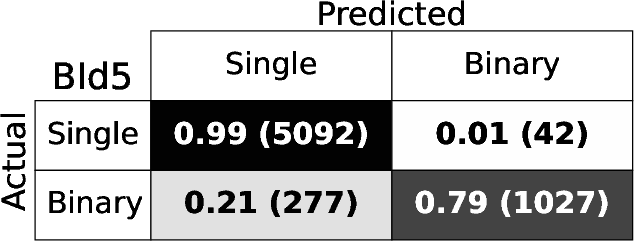
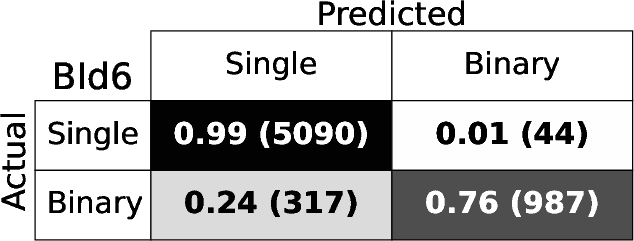
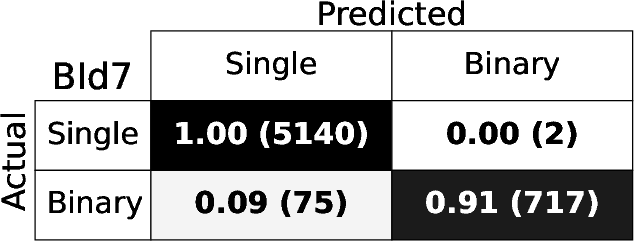
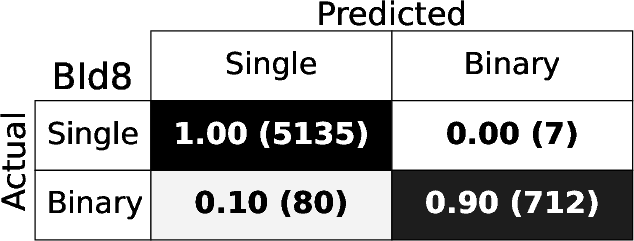

Figure 4: Confusion matrices for each BId model, demonstrating high fraction of correct identifications for both singles and binaries.
The recall heatmap for BId1 (not shown here) further reveals that low recall is restricted to binaries with minimal blended spectral peculiarities: equal-component lines (diagonal), T8–T9 secondaries, or cases with high flux differentials. Otherwise, recall approaches unity, especially for L+T and mid-L+T5–T6 systems.
Feature importance (FI) analysis for BId1 shows consistent prioritization of molecular features (K I, CH4, CO bands) and the T dwarf–dominated J-band flux peak as the dominant branches for high S/N, with a shift to broader continuum structure at low S/N.
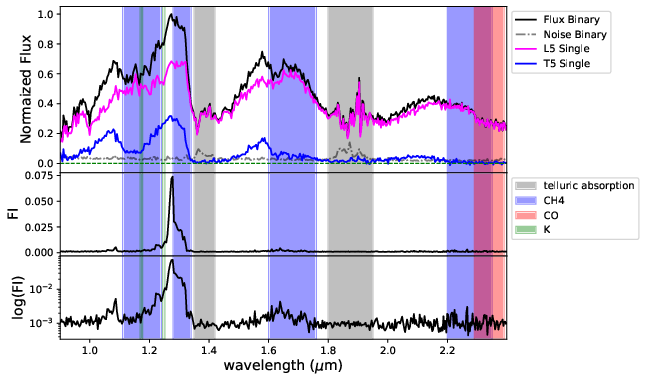
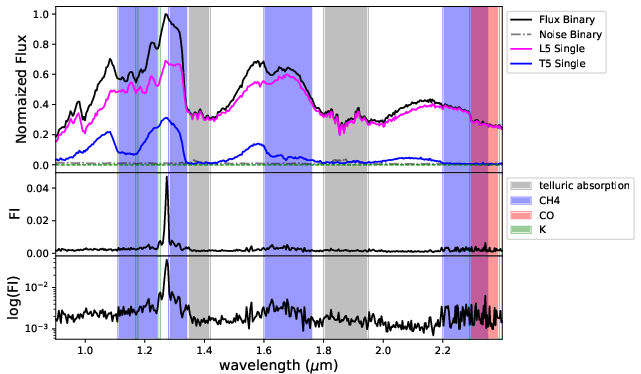
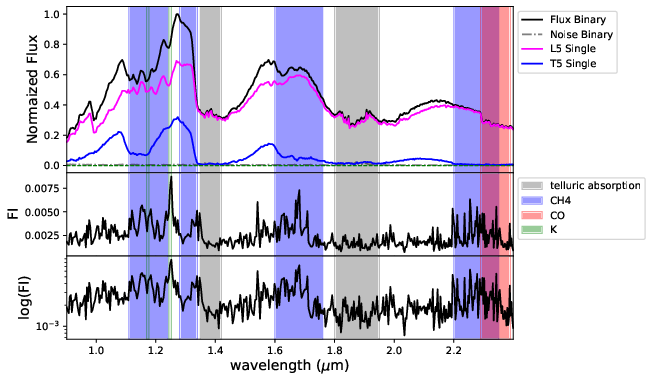
Figure 5: FI profiles for BId1 across S/N bins. Peaks are prominent at K I, CH4, and CO spectral regions.
Component Classification: Regression and Feature Sensitivity
Component subtype regression with RFs yields primary system errors <0.1 subtypes and scatter ≲0.5 for high S/N data, with secondary errors ∼1 subtype. Enhanced performance for secondary classification is achieved only in the compositional ranges corresponding to index-based method sensitivity. Regression outperforms classification models for non-uniform spectral pairings, but degrades for binaries that are close in type or low S/N.
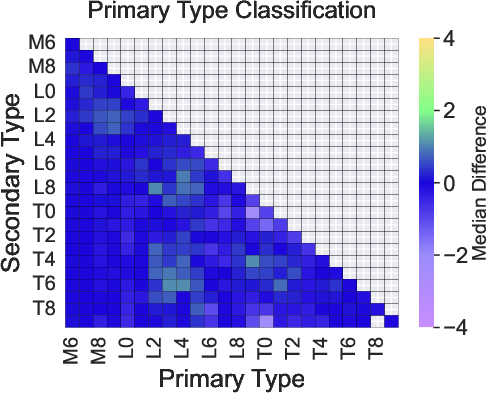
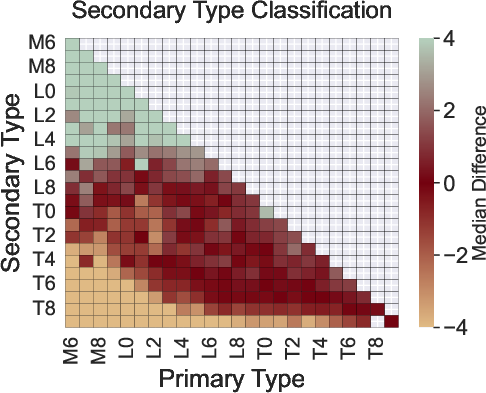
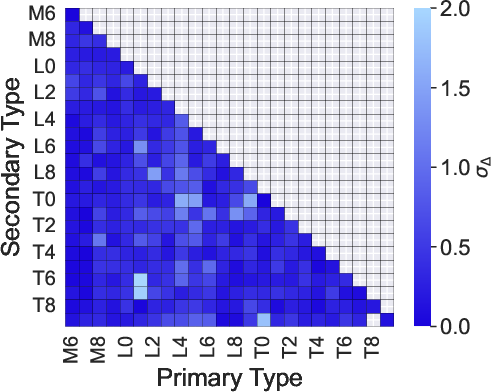
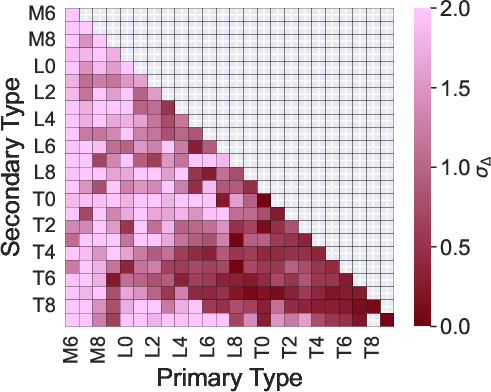
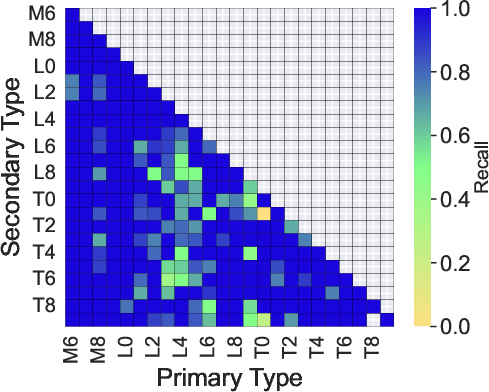
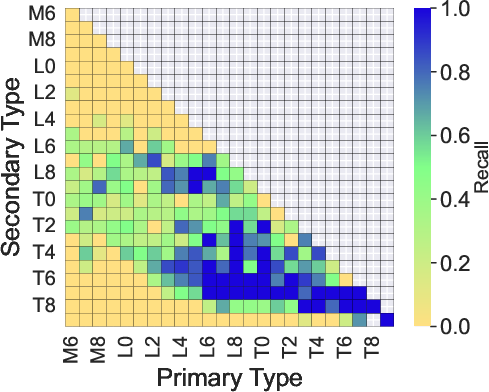
Figure 6: Median error, scatter, and recall for primary and secondary classification as a function of component spectral types (mid-S/N group, BClass1 model).
Feature importance in the classification models again emphasizes molecular absorption and flux peaks, but the FI profiles are distinctly localized for primaries and secondaries, with different wavelength sets dominating as S/N increases.
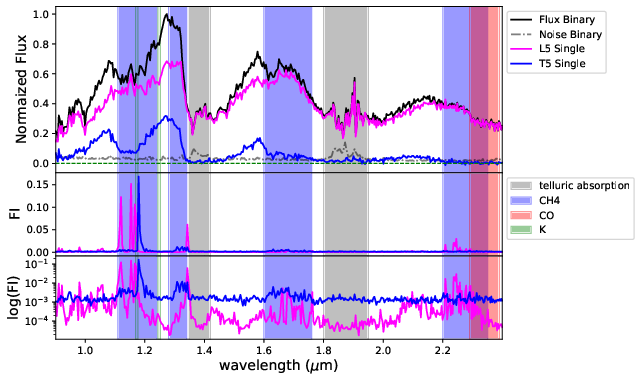
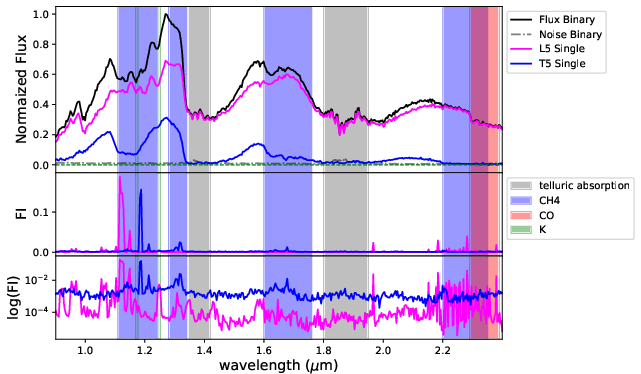
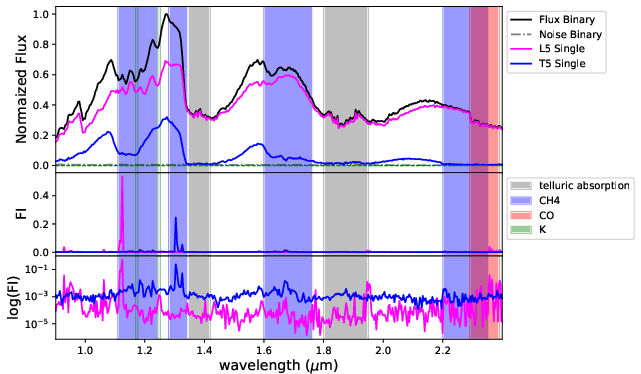
Figure 7: FI for BClass1 model: S/N dependence in primary/secondary sensitivity, peaks at $1.1$–1.24μm (K I, CH4), and 1.95μm (H2O).
Application to Confirmed Binary Systems and Population Simulation
Application to 43 confirmed VLM binaries with empirical combined-light spectra demonstrates a lower recall (58% for BId1), attributable to the higher frequency of equal-component systems in the empirical set—exactly the configuration with minimal RF and index sensitivity. For binaries with Δ spectral type >3, the recall increases substantially to 74%. Specialized models underperform these general models except in their respective compositional subdomains.
Population synthesis illustrates that only ∼8% of VLM field binaries—assuming state-of-the-art IMF and mass-ratio distributions—are in the spectral type combinations optimally detected via the blend-spectral method.
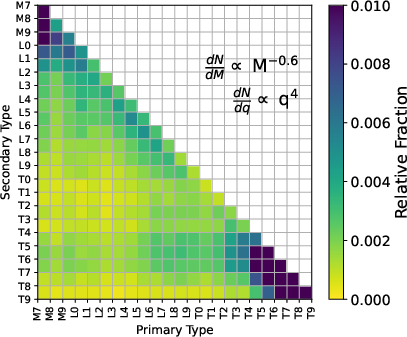
Figure 8: Component spectral type frequencies in a simulated population. Most binaries lie outside the optimal blend-detectable domain.
Practical and Theoretical Implications
The RF-based architecture enables spectral binary identification and component typing at computationally negligible per-object costs (∼2 ms/object classification) and robustly outperforms classical methods on synthetic, well-balanced datasets. However, both RF and index/spectral template approaches are fundamentally limited by astrophysical degeneracy: the overlap in spectral characteristics for systems with similar component types, or those with extreme flux ratios, typical of the majority of the VLM binary population. Furthermore, empirical contaminant classes (peculiar, subdwarf, or young brown dwarfs) can introduce additional ambiguity.
Implications for massive spectroscopic surveys (e.g., SPHEREx, Euclid, JWST, Roman) are significant: these models are sufficiently general and scalable to process anticipated data volumes, provided adequate empirical training sets and appropriate domain adaptation for varying instrumental passbands and resolutions. Incorporating non-spectral data (e.g., parallax, photometry) or expanding to more expressive ML architectures (deep neural nets, ensemble learning) is likely to further increase recovery for hard-to-detect systems.
Conclusion
This study establishes that supervised machine learning, specifically RFs, provides an efficient, high-fidelity alternative to classical index-based approaches for the identification and characterization of unresolved VLM spectral blend binaries. The main strength lies in computational scalability and absorption feature sensitivity, with robust performance for L+T and compositionally divergent systems. Performance degrades for the dominant equal-type or strongly flux-imbalanced pairs, setting an astrophysical and algorithmic limitation. Anticipated advances include hybrid architectures, broader feature space integration, and adaptation to non-NIR survey regimes. The methodology and open-source training data framework delineated here provide a reproducible template for future binary population studies and automated classification in SSA.
Reference: "Identifying and Characterizing Very Low Mass Spectral Blend Binaries with Machine Learning Methods" (2512.12098)