- The paper introduces Deep-LSE, a transfer learning method that robustly recovers risk-neutral densities in illiquid markets by leveraging proxy information.
- It employs a deep neural architecture with Log-Sum-Exp layers to ensure economic consistency, convexity, and no-arbitrage conditions.
- Empirical simulations and SPX market validations demonstrate superior performance over traditional spline and kernel interpolation techniques.
Transfer Learning Approaches for RND Estimation in Illiquid Option Markets
Introduction
The paper "Transfer Learning (Il)liquidity" (2512.11731) introduces a new methodology for estimating risk-neutral densities (RND) from illiquid European option markets, where traditional techniques are hampered by the scarcity and irregularity of observed option quotes. It presents a deep learning framework, the Deep Log-Sum-Exp Neural Network (Deep-LSE), which leverages transfer learning from liquid proxy markets to illiquid target markets. The authors establish rigorous theoretical guarantees for the Deep-LSE—specifically, universal approximation and convexity—while empirically validating its superior performance over classical interpolation techniques in both simulated and real financial environments.
Context and Motivation
RND estimation is fundamental in financial economics for derivatives pricing, hedging, and risk management. Most extant literature assumes relatively liquid markets, enabling parametric or nonparametric inference with fairly dense cross-sections of option prices. However, in practical settings—particularly in less liquid markets or for certain strikes and tenors—available quotes are sparse, irregular, and subject to significant market noise. This situation renders conventional interpolation (e.g., splines, kernel, entropy) and parametric expansion methods unstable, ill-posed, or inconsistent. The need for RND recovery in these contexts is acute, motivating methodologies that can regularize the inference by integrating information from structurally related liquid markets while ensuring economic consistency such as convexity and no-arbitrage requirements.
Methodology
The proposed approach interleaves deep learning with transfer learning:
- Phase I (Proxy Training): The Deep-LSE neural network is first trained on a liquid proxy market with dense and reliable option quotes. This phase imbues the network with a strong prior concerning the generic shape and smoothness of the implied volatility (IV) surface.
- Phase II (Transfer/Fine-Tuning): The pretrained model is fine-tuned using only the few available, possibly noisy, quotes from the illiquid market. Crucially, the transfer learning paradigm acts as a regularizer, ensuring that the sparse-data fit does not degenerate or violate shape constraints internalized during pretraining.
The neural architecture itself is distinguished by:
- The use of multiple Log-Sum-Exp (LSE) layers, which can flexibly and efficiently approximate convex functions due to the LSE operation's limit to max-affine functions as temperature tends to zero.
- Guarantees of input convexity, which propagates through the deep cascade by construction owing to non-negative skip connections and monotonic activation compositions.
Upon interpolation of the IV surface via Deep-LSE, the RND is numerically extracted by taking finite differences on the option pricing function with respect to strike, as per the Breeden-Litzenberger result.
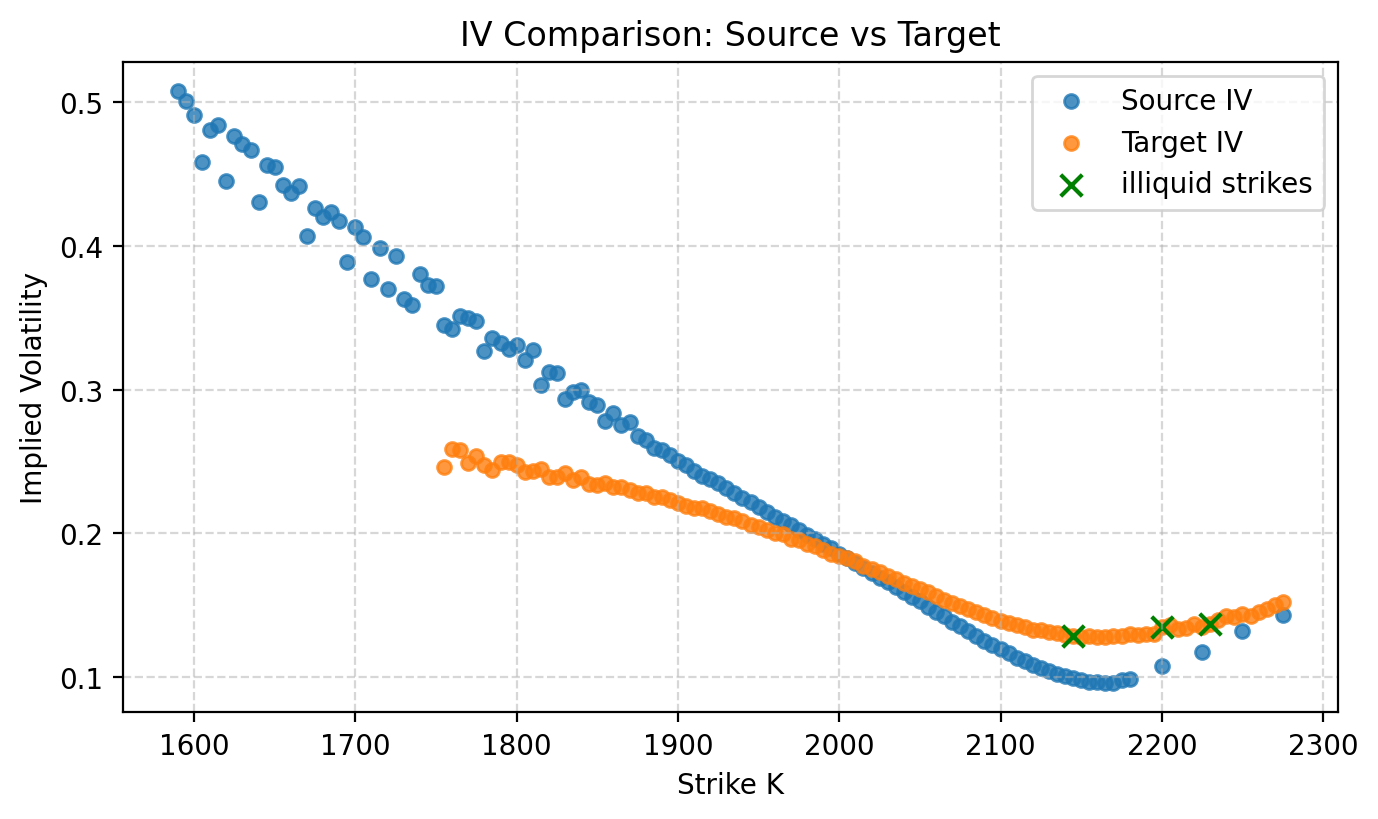
Figure 1: Setup of implied volatility curves using Bates model. In blue, the illiquid target implied volatility. In orange, the liquid proxy we use to train the model.
Theoretical Properties
The Deep-LSE is shown to be a universal approximator of convex functions (Theorems 2, 3), with formal bounds connecting its representation to finite max-affine surrogates. Analytical control is provided on the error between the neural output and the closest max-affine function, with explicit dependence on architecture hyperparameters (depth, temperature, skip coefficient magnitudes). The convexity-by-design property is critical for meaningful IV surface extrapolation under severe data impoverishment and precludes the accidental generation of concavities—thereby upholding no-arbitrage.
Furthermore, a sieve estimation framework is adapted for neural function classes, and consistency is established provided suitable growth rates on model complexity relative to sample size. The paper also presents an information-theoretic stopping criterion for the fine-tuning phase, balancing empirical risk minimization against parameter divergence from the proxy prior, operationalized via a PAC-Bayes bound on parameters' KL divergence.
Simulation Results
The authors conduct extensive simulation studies using several industry-standard stochastic volatility jump-diffusion models, e.g., Bates, Kou-Heston, Andersen-Benzi-Lund, and the Three-Factor Double Exponential process.
Strong results are obtained for Deep-LSE in the severely illiquid regime (as few as three available quotes), with clear superiority over spline-based interpolation—even in difficult regions such as the right tail of the RND, where sparse or noisy data can cause classical methods to become unstable or economically inconsistent.
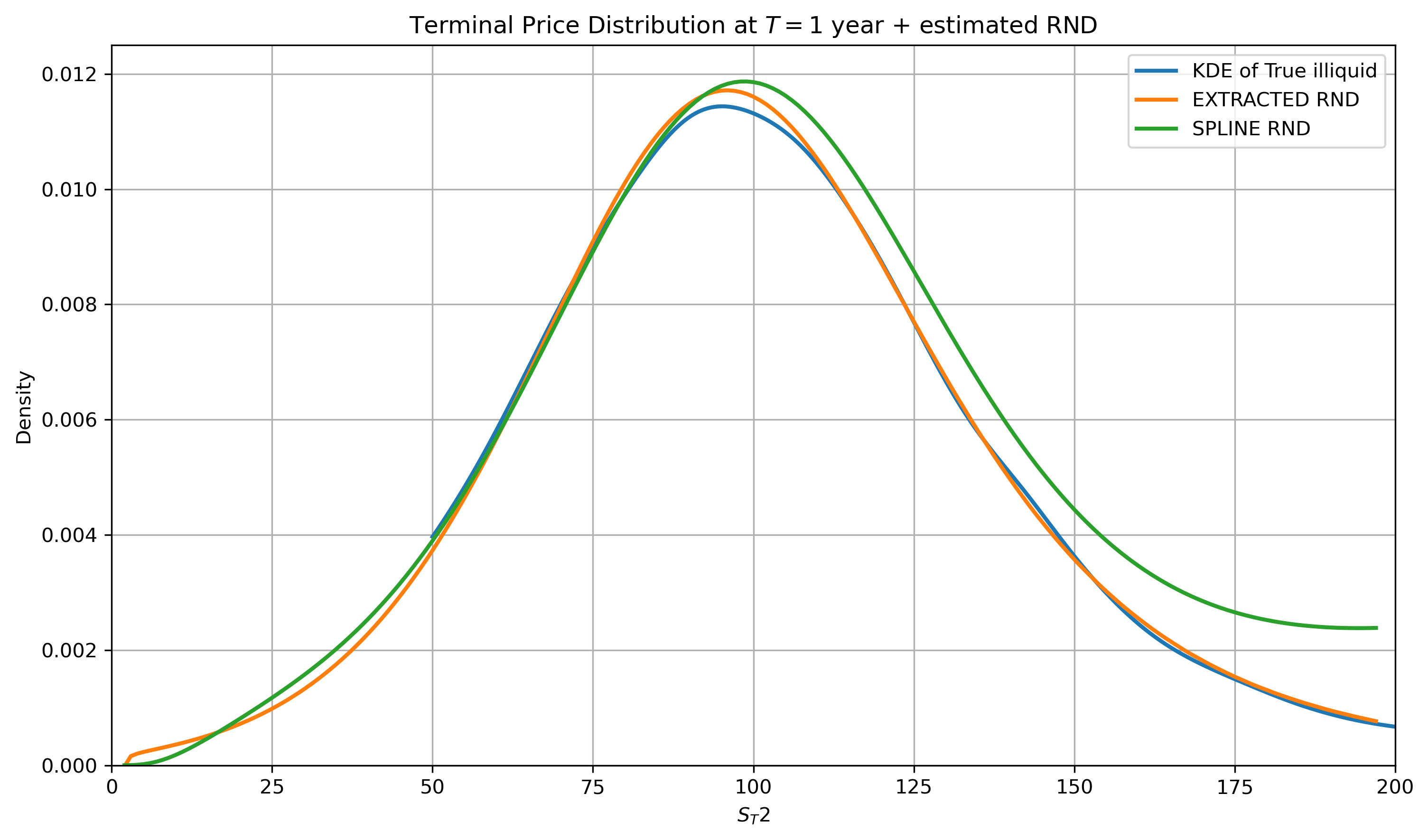
Figure 2: Illiquid RND recovery of Deep-LSE (orange curve) and quadratic splines (green curve) in comparison with the target ground truth simulated RND (blue curve).
The staged training (proxy → target) is visualized, confirming that the Deep-LSE efficiently internalizes and transfers structure, while fine-tuning under data impoverishment.
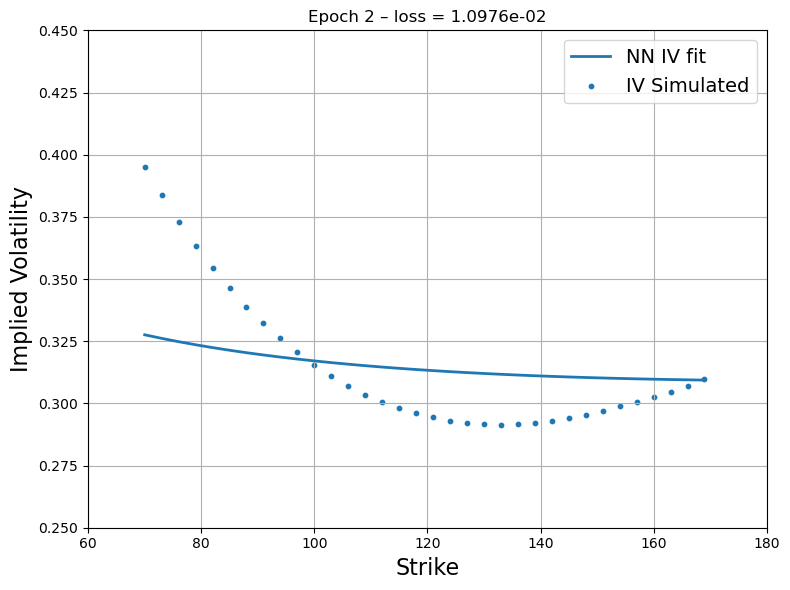
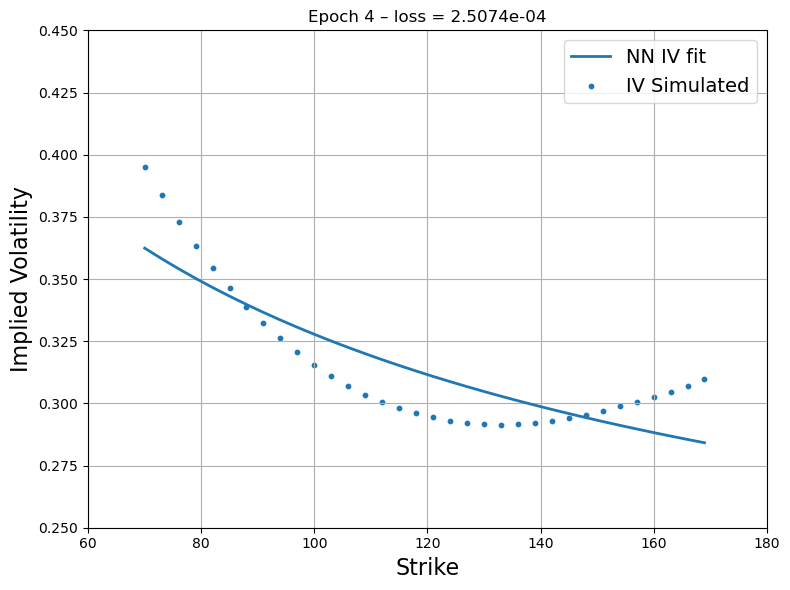
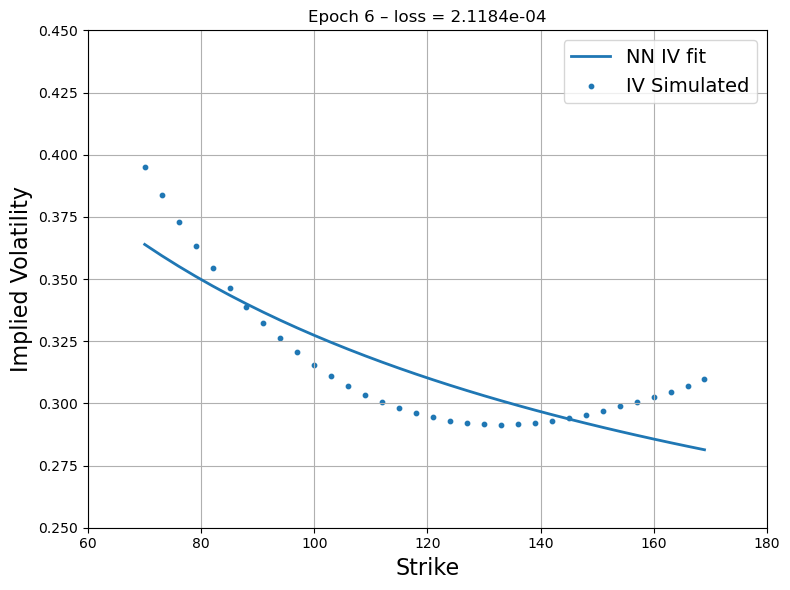
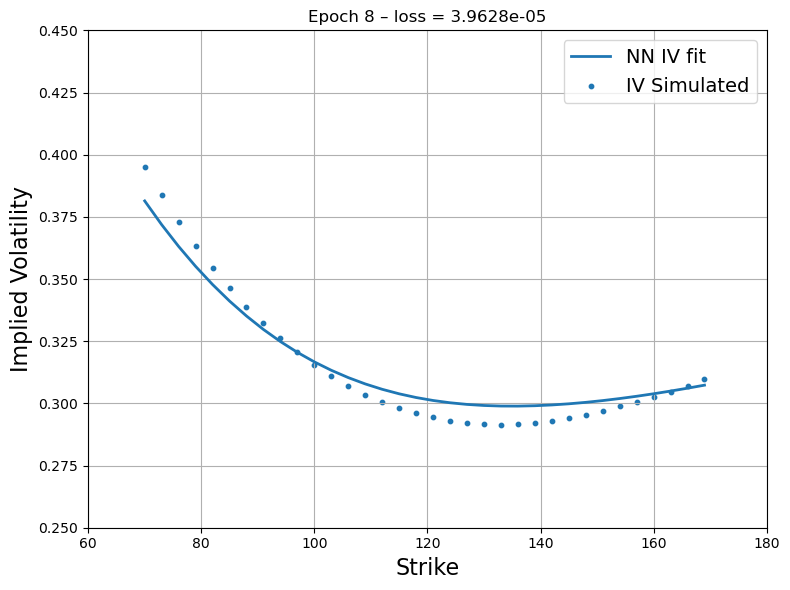
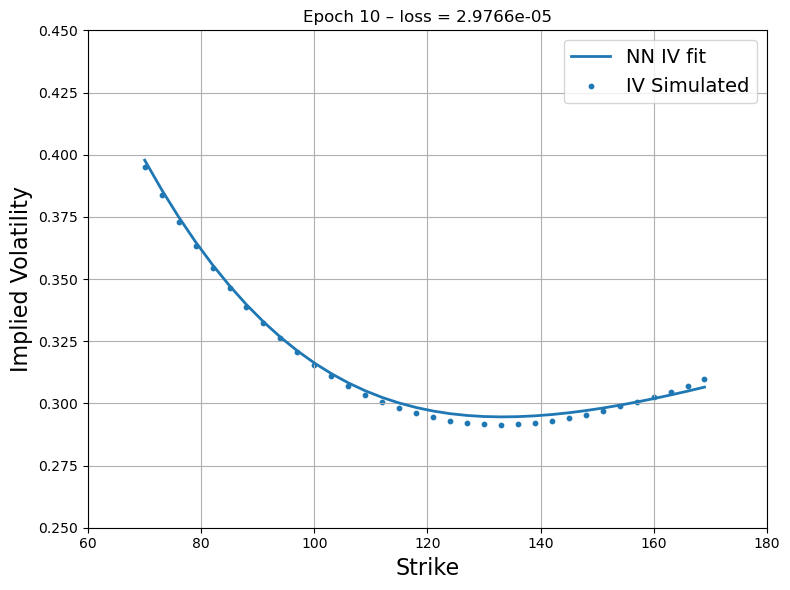
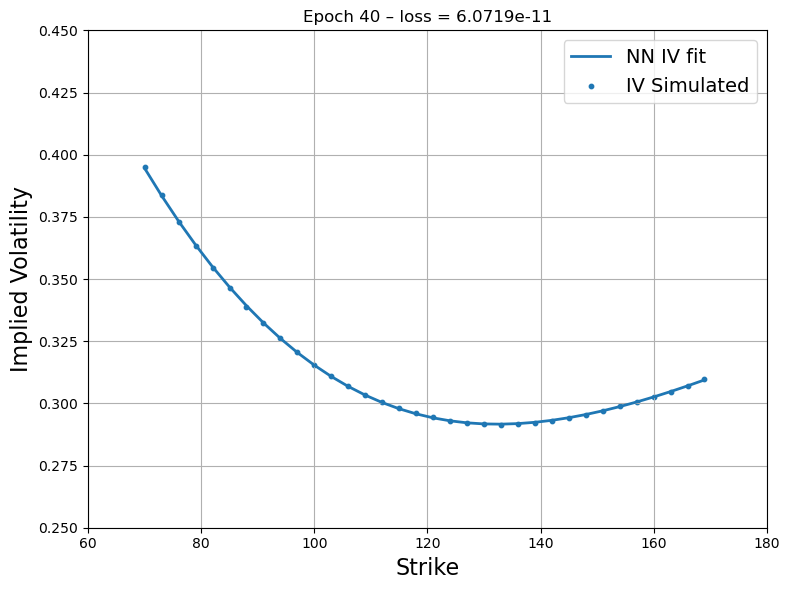
Figure 3: First step recovery - Source Deep-LSE Fit. The blue dots represent the implied volatility curve of option quotes of the liquid proxy asset while the blue solid line represents the fit of the interpolating function of the Deep-LSE model.
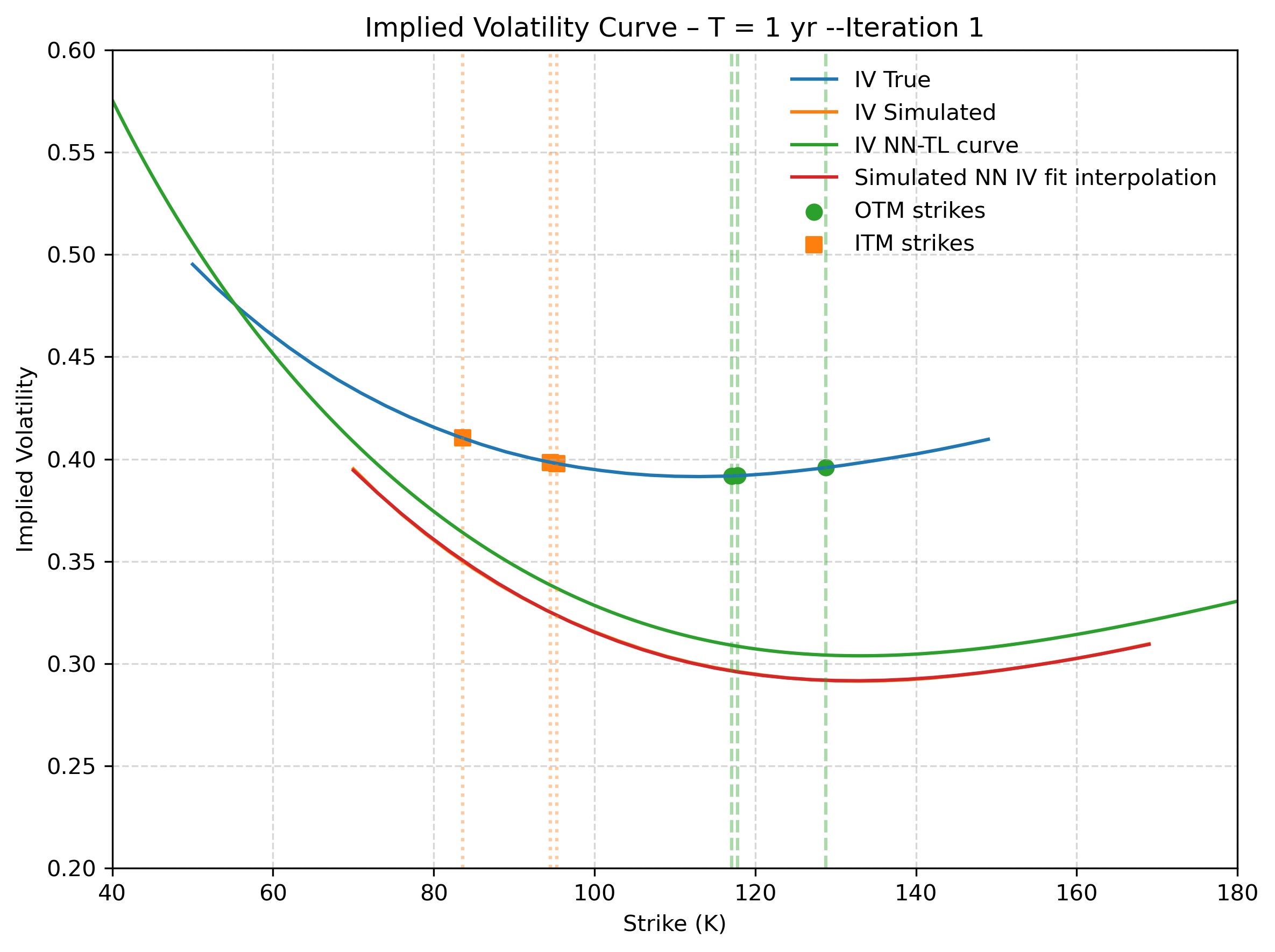
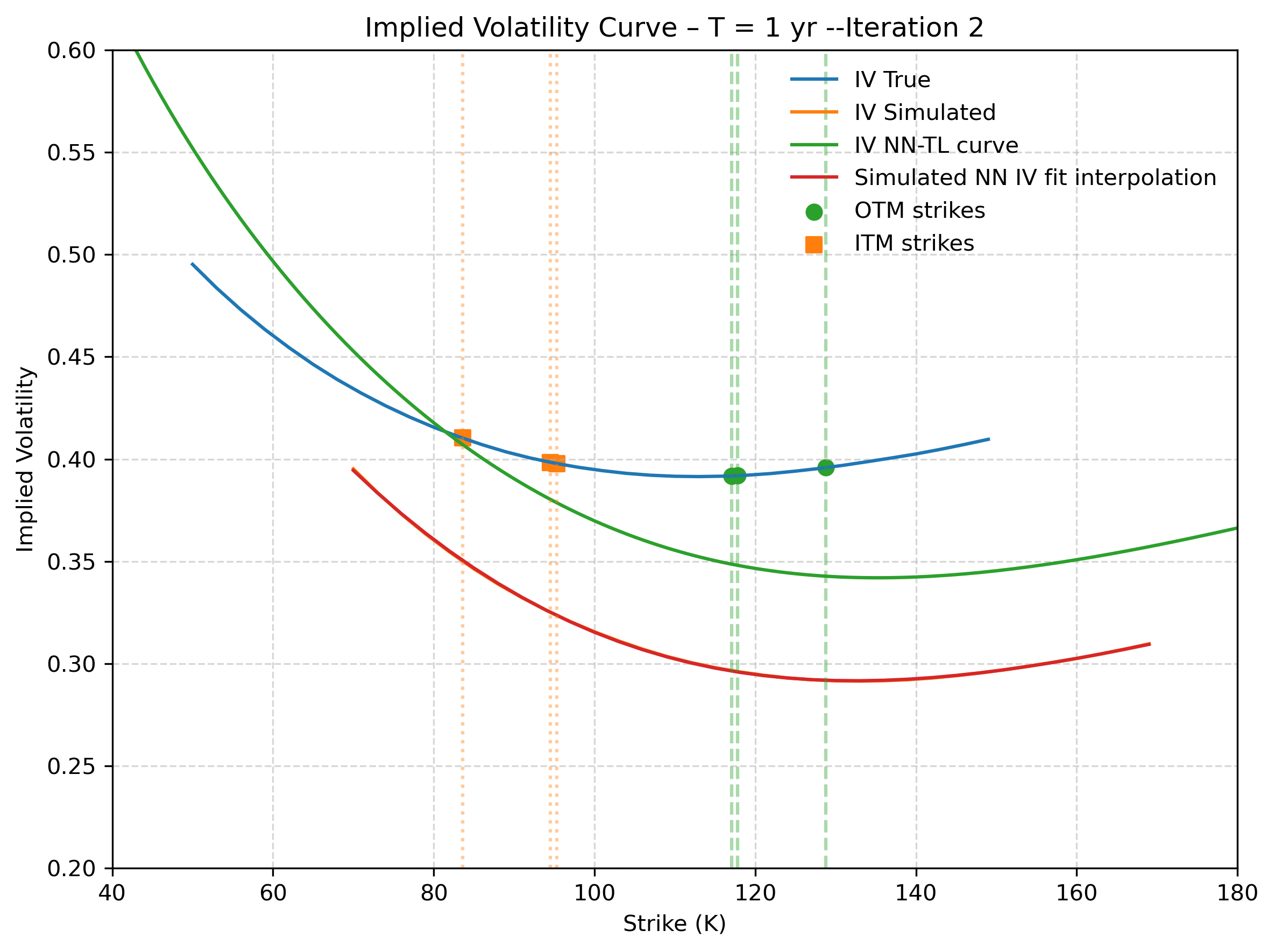
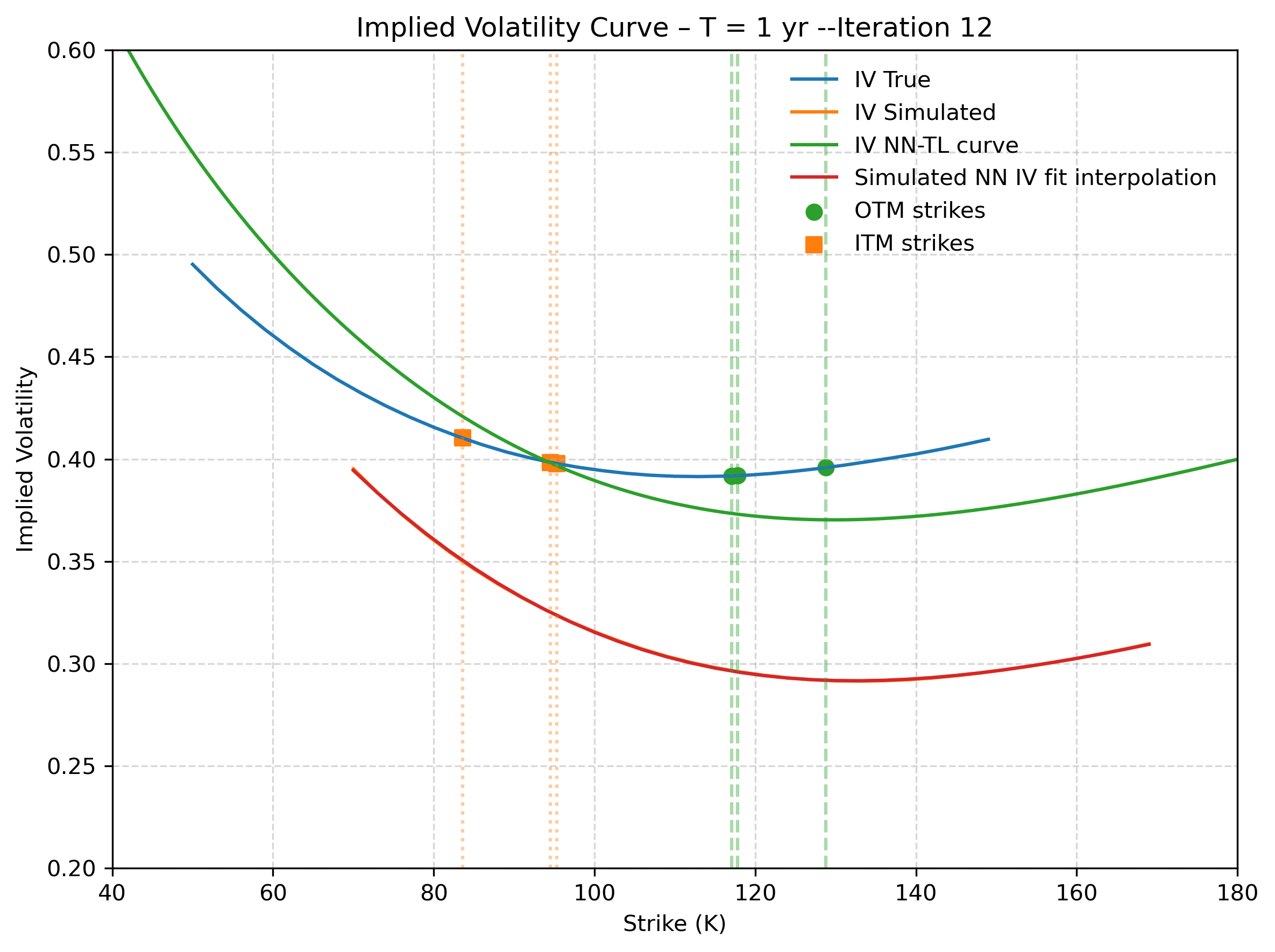
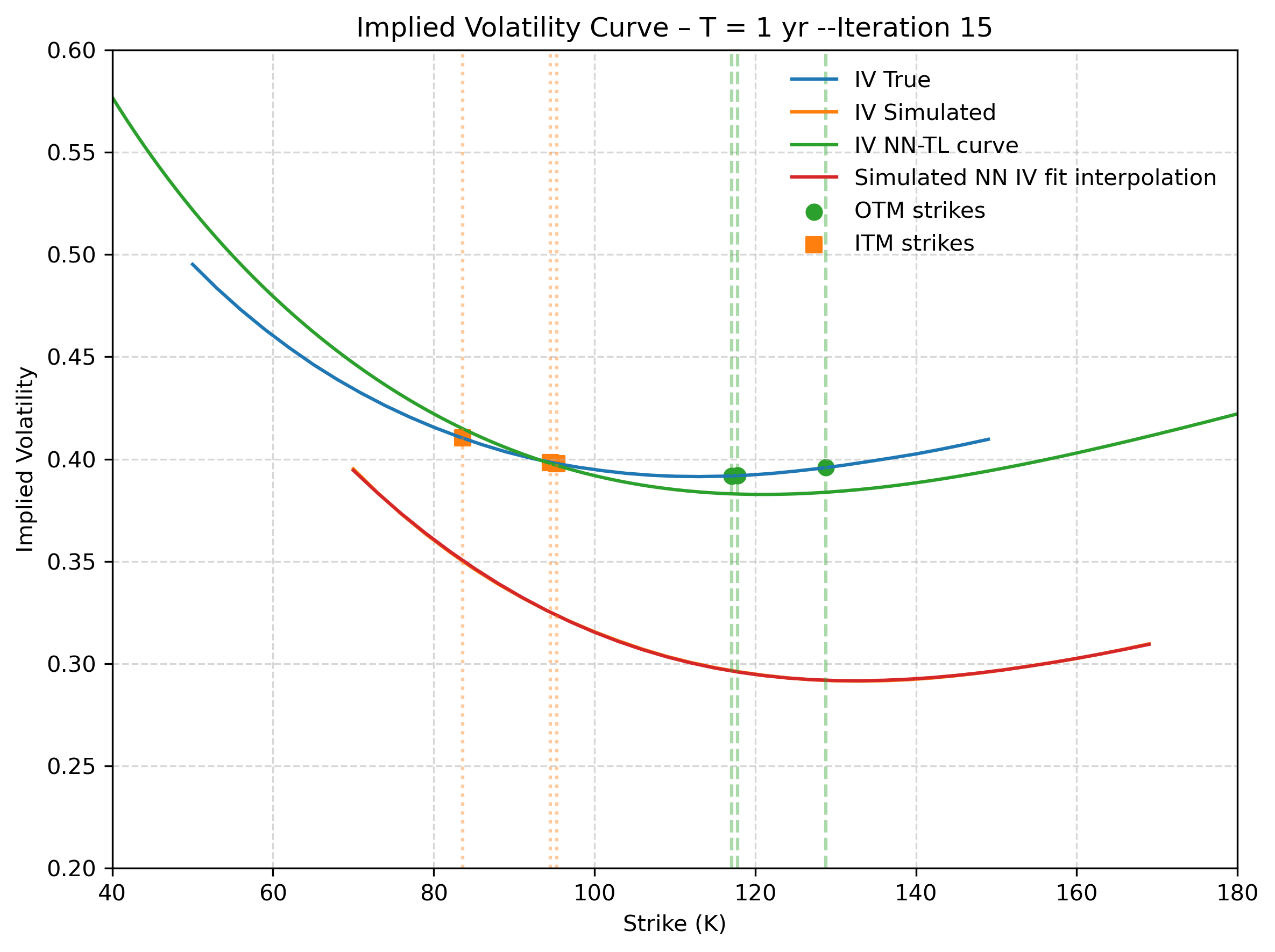
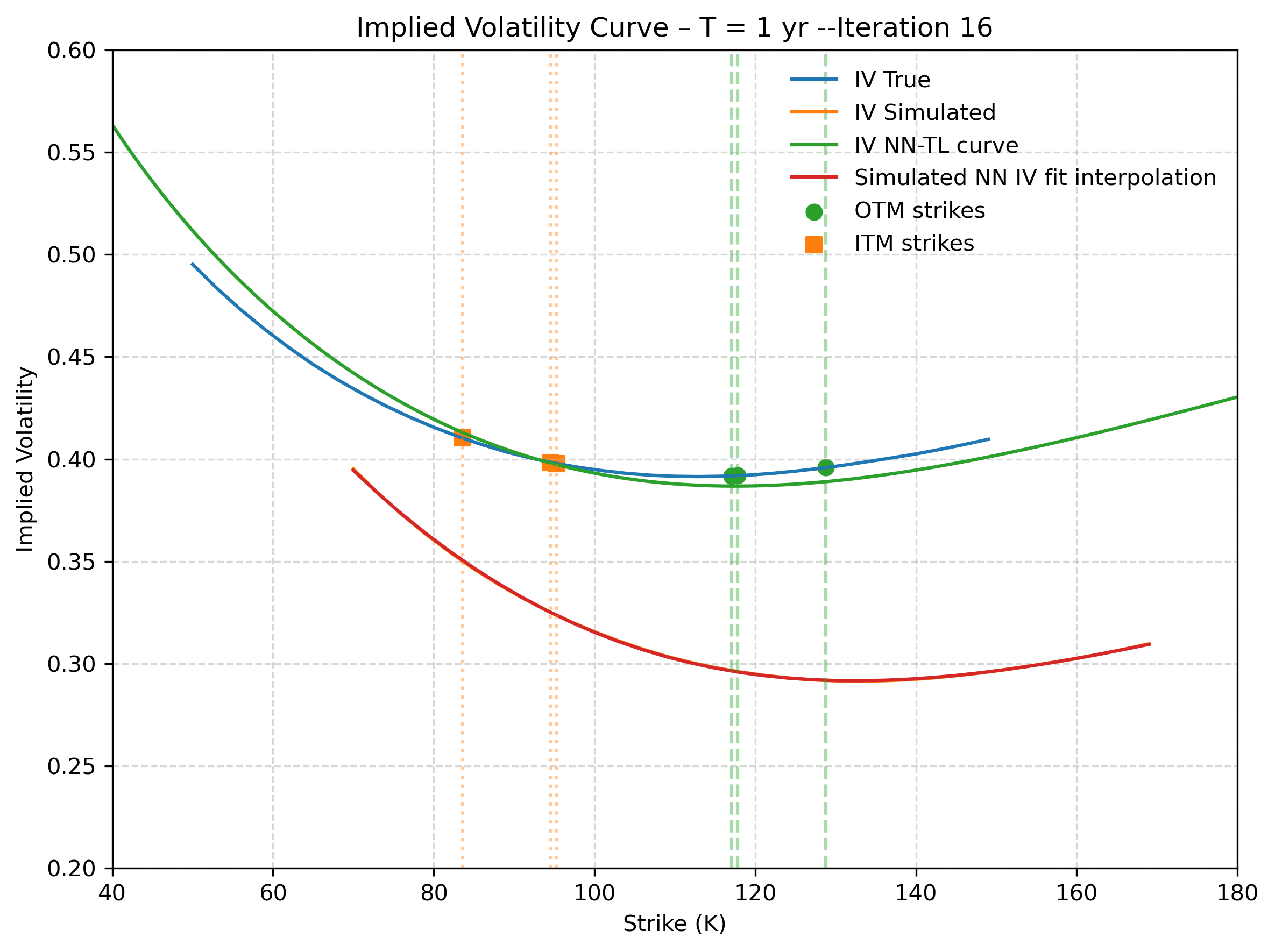
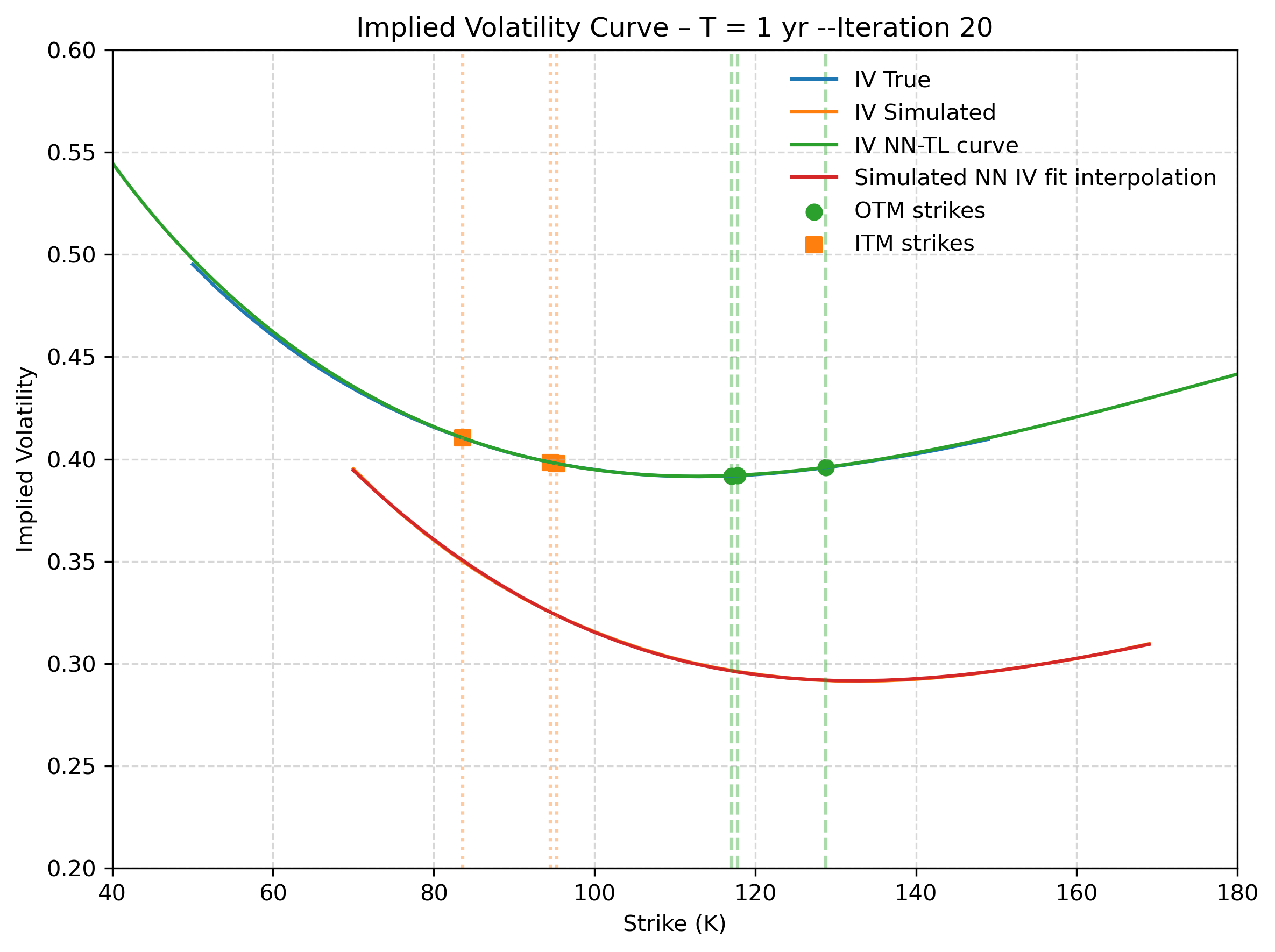
Figure 4: Second step recovery - Target Deep-LSE Fit. The model only sees the illiquid (orange) quotes. The blue solid line is the true implied volatility function that the Deep-LSE recovers (green solid line). The solid orange and red curves represent the true and estimated IV curve of the first step.
Empirical Analysis
Empirical validation is performed on SPX options. Historical data is used to train the proxy, and subsequent (sparser) data to represent the illiquid target. The Deep-LSE model consistently recovers plausible, arbitrage-free RNDs across a range of strike domains (ITM/OTM) using at most three observed quotes for the illiquid period.
Benchmark comparisons are provided against kernel regression, maximum-entropy, mixture parametric, and quadratic spline estimators. Across both in-the-money and out-of-the-money illiquidity scenarios, Deep-LSE delivers the lowest mean absolute error in option pricing relative to ground truth, with the regularization provided by the transfer learning phase being particularly crucial under extreme illiquidity.
Implications and Future Directions
This research addresses a critical methodological gap in the recovery of economically meaningful RNDs from illiquid option markets. The approach provides a natural framework for incorporating economic structure (convexity, no-arbitrage) and prior information (via proxies) into deep nonparametric modeling, with formal theoretical guarantees on expressiveness and generalization behavior. In practice, this facilitates downstream risk management and pricing tasks in markets where liquidity constraints routinely arise.
Potential extensions include:
- Adaptive proxy selection based on market similarity and other econometric metrics.
- Dynamic updating of the proxy model for nonstationary environments.
- Integration with robust learning approaches to further mitigate the impact of market microstructure noise.
The theoretical apparatus (universal approximation, input convexity, sieve consistency) offers a blueprint for further architectures tailor-built for convex regression problems in finance and related domains.
Conclusion
"Transfer Learning (Il)liquidity" (2512.11731) presents a comprehensive deep learning and transfer framework for RND estimation in the presence of extreme illiquidity. By leveraging both theoretical convex analysis and large-scale empirical evidence, the approach demonstrates clear advantages over classical interpolation methods—enabling robust, arbitrage-consistent nonparametric inference in otherwise ill-posed environments. The work establishes deep transfer architectures as a viable and superior solution for RND recovery where data limitations are the fundamental roadblock.

