- The paper proposes a novel neural framework that learns constrained descent directions to achieve strict feasibility and near-optimality.
- It integrates learnable feature transformations and adaptive step sizes within modular descent modules, validated on convex/nonconvex QPs, portfolio, and AC-OPF problems.
- Experimental results demonstrate significant speedups and scalability, outperforming classical solvers with robust convergence guarantees.
Descent-Net: Learning Deep Descent Directions for Constrained Optimization
Introduction
Descent-Net proposes a neural architecture for constrained optimization, addressing fundamental scalability and feasibility challenges in traditional solvers and learning-to-optimize (L2O) methods. Unlike previous L2O frameworks—which typically struggle with hard constraint satisfaction and scalability to large problem instances—Descent-Net explicitly learns constrained descent directions, providing near-optimal feasible solutions through iterative neural updates. The architecture is validated on convex and nonconvex quadratic programs, portfolio optimization, and AC optimal power flow (AC-OPF), demonstrating superior feasibility and efficiency on large-scale problem instances. This essay details the theoretical foundation, algorithmic structure, experimental evaluations, and implications for constrained optimization research.
At the heart of Descent-Net is the reformulation of the classical feasible directions method (MFD) for constrained optimization. The descent direction at each feasible iterate y is constrained to satisfy orthogonality to active equality constraints and non-violation of active inequalities by solving a direction-finding subproblem—a linear program based on Zoutendijk and Topkis–Veinott formulations. Descent-Net generalizes these with an exact penalty reformulation, ensuring feasibility and providing uniform lower bounds on the allowable step size.
The penalized subproblem is defined as: dmin∇fx(y)⊤d+j=1∑l cjmax(⟨d,∇gx,j(y)⟩,−Mgx,j(y)),s.t.d∈D,
where cj weights are adaptively computed depending on proximity to constraint boundaries, and D enforces both norm and equality constraint orthogonality. Rigorous proofs (see Lemma~1 and accompanying discussion) guarantee that global minimizers of this penalized problem correspond exactly to those of the uniformly feasible directions subproblem under suitable choices of cj.
Descent-Net Neural Architecture
Descent-Net operationalizes the descent direction learning and update in a modular neural framework. Each Descent Module unrolls a projected subgradient optimization over K layers, with learnable feature transformation operators Tk and layerwise learnable step sizes γk. The output descent direction d of each module is applied through a controlled step along the feasible set, using a policy that maintains all constraints by adapting the step size via αmax and a learned scaling factor.
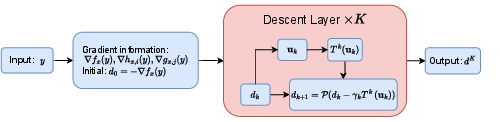
Figure 1: Overall structure of the Descent Module.
The global Descent-Net architecture chains S Descent Modules, each initialized with the preceding feasible iterate, with continual refinement toward improved objective and strict constraint satisfaction. The architecture is designed to exploit parallel GPU computation, making it suitable for deployment on very high-dimensional problems.
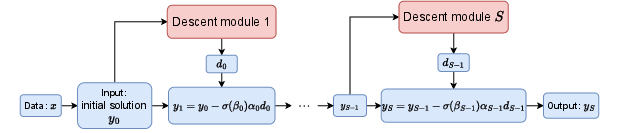
Figure 2: Architecture of the entire network.
A key theoretical result (Theorems~1 and~2) establishes that for linear constraints and sufficiently expressive modules, Descent-Net iterates asymptotically approach KKT points, with convergence rates dependent on the number of layers and modules. No batch-specific retraining is required for differing input dimensions or problem sizes; the module parameters are independent of instance dimension, providing strong generalizability.
Experimental Evaluation
Convex and Nonconvex Quadratic Programs
Descent-Net achieves strict feasibility and consistently low objective error across convex QP instances with dimensionality up to n=5000, outperforming established solvers (OSQP, qpth, HPR-QP, CuClarabel) in computational time for similar solution accuracy. In nonconvex problems, Descent-Net maintains feasibility with relative objective errors on the order of 10−4, achieving approximately 19× speedup over IPOPT.
Crucially, scalability tests demonstrate that Descent-Net's batch parallelization provides substantial runtime reductions compared to sequential solvers, and solution quality does not degrade significantly as problem dimension increases.
Portfolio Optimization
Portfolio optimization—critical in financial engineering—is used to illustrate practical efficacy and scalability. Descent-Net solves problems involving up to 4000 asset variables with strict feasibility and objective errors on the order of 10−6, whereas conventional solvers exhibit runtime scaling that is orders of magnitude higher for increasing n.
AC Optimal Power Flow (AC-OPF)
For AC-OPF instances with nonlinear equality and inequality constraints, Descent-Net is adapted to maintain feasibility through equation completion techniques. In both 30-bus and 118-bus power network cases, Descent-Net produces solutions with low relative objective errors (10−4) and is approximately 4× faster than standard solvers including PYPOWER. Neural baseline competitors (DC3, H-Proj, CBWF) fail to match Descent-Net’s accuracy and efficiency, particularly on larger, nonconvex instances.
Ablation and Sensitivity Studies
A series of controlled experiments reveal that:
- Increasing the layer counts boosts accuracy only marginally, suggesting rapid convergence.
- Learnable step size scaling is critical for balancing sufficient decrease and constraint preservation; fixed steps or unsupervised maximum feasible steps degrade solution quality.
- Descent-Net’s learnable subgradient transformations provide significantly enhanced solution refinement compared to projected subgradient descent, which stagnates even with many more iterations.
- The architecture’s theoretical guarantees are empirically matched, confirming the practical tightness of the analytic convergence bounds.
Implications and Prospect
Descent-Net’s approach advances constrained optimization in several directions:
- Rigorous Feasibility Enforcement: Unlike previous L2O systems, Descent-Net guarantees strict feasibility at every update, necessary for high-stakes engineering and scientific domains.
- Parallel Scalability: Neural iteration chaining and batch inference allow for rapid solution of thousands of high-dimensional instances, scaling far beyond the capability of classical solvers.
- Modular Generality: Separation of projection and descent mechanisms enables ready adaptation to different constraint structures (linear, nonconvex, nonlinear equality), with only minor architectural tuning required.
- Hybrid Optimization: Descent-Net solutions can be used for warm-starting classical optimization algorithms, potentially reducing time-to-convergence for certificate-level accuracy.
Future developments should explore extending Descent-Net to implicit constraint structures and hybrid primal-dual updates, enhancing its expressiveness for large-scale nonlinear programs. Generalization properties to combinatorial and integer constraints, as well as integration with differentiable optimization layers for model-based RL and operations research, present compelling avenues for theoretical and applied research.
Conclusion
Descent-Net epitomizes a principled, highly efficient neural approach for constrained optimization, resolving both feasibility and scalability limits of previous learning-to-optimize frameworks. Its iterative, modular architecture is theoretically solid, empirically robust, and practically versatile across convex, nonconvex, and complex constraint scenarios. Overall, Descent-Net lays a foundation for future research at the confluence of optimization theory, deep learning, and real-world system design.