- The paper introduces an extended TSM that leverages multi-task learning and ensemble strategies to improve action boundary detection, achieving top mAP scores in the BinEgo-360 challenge.
- The methodology employs interval-based classification and confidence-weighted ensemble voting to merge predictions across diverse video modalities efficiently.
- The experimental results demonstrate significant performance gains over traditional models, highlighting potential applications in robotics, VR/AR, and surveillance.
Multi-task Learning with Extended Temporal Shift Module for Temporal Action Localization
Introduction and Problem Setting
Temporal action localization (TAL) within multi-modal, multi-perspective video constitutes a major challenge due to the heterogeneity of input sources and the need for fine-grained temporal and semantic precision. The paper "Multi-task Learning with Extended Temporal Shift Module for Temporal Action Localization" (2512.11189) presents a solution optimized for the BinEgo-360 Challenge, which introduces a unique dataset comprising panoramic (360°), third-person, egocentric monocular, and binocular videos, as well as complementary sensory inputs, annotated for both action and scene categories. The crux of the task is identification of action boundaries and semantic labels in long, untrimmed, context-rich video streams with rigorous evaluation by mean Average Precision (mAP) at multiple Intersection-over-Union (IoU) thresholds.
Related Work Context
Conventional video understanding approaches, such as two-stream CNNs, 3D convolutional architectures (C3D, I3D), and efficient temporal models (SlowFast, TSM), have shown progress for action recognition and scene classification. Recent transformer architectures (ViViT, TimeSformer) outperform static models in capturing long-range dependencies. For TAL, the progression is from anchor-based models (SSN, TAL-Net) to anchor-free paradigms (BMN, BCG), where end-to-end boundary regression and proposal mechanisms dominate. Multi-modal datasets (THUMOS, ActivityNet, EPIC-Kitchens, HACS) mostly focus on single or limited modalities, underlining the novelty of BinEgo-360’s multi-view, multi-modal setting.
Methodological Framework
The solution utilizes a multi-task learning approach wherein a unified backbone network jointly addresses scene classification and temporal action localization. The Temporal Shift Module (TSM) serves as backbone, chosen for its efficient temporal feature modeling via channel-wise shift operations and demonstrated robustness. Joint optimization encourages shared representation of contextual scene features and temporal action boundaries, facilitating cross-task inductive transfer and improved sample efficiency.
Extending TSM for TAL
To convert classification-centric TSM to a TAL-compatible model, the authors introduce a background label and train the model on Nclass+1 categories, with segmentation of videos into non-overlapping intervals of fixed size t. For inference, the trained model classifies each interval; post-processing merges consecutive intervals with the same predicted action label, adjusting segment confidence to maximize temporal coherence.

Figure 1: Illustration of extending TSM for temporal localization.
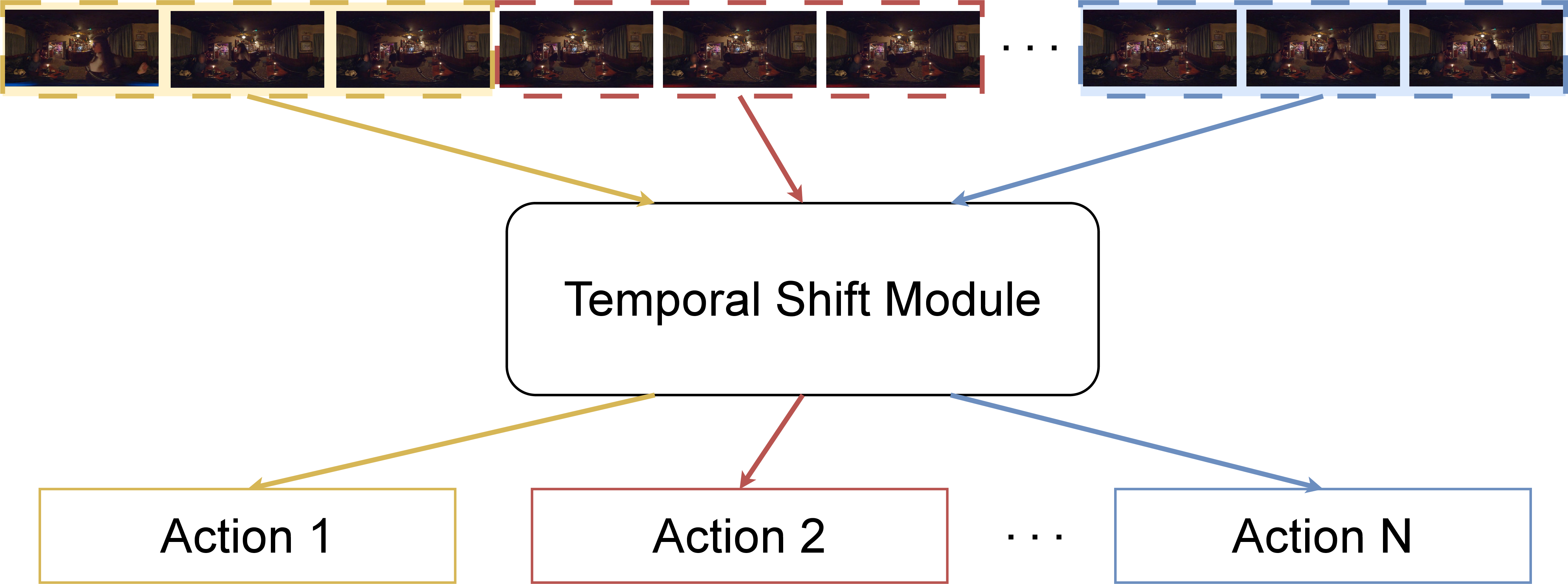
Figure 2: Visualization of the modified TSM architecture and downstream processing for interval-based classification and merging operations.
The approach maintains TSM’s computational advantages but may under-represent short or concurrent actions due to interval granularity constraints.
Ensemble Learning Strategy
To mitigate model instability and harness complementary strengths of different backbones/configurations, a weighted model ensemble is adopted. Individual prediction files are aligned and aggregated using a confidence-weighted voting scheme, with weights calibrated on validation performance. Overlapping segment predictions are merged via IoU-maximization and score pooling, resulting in robust, consistent TAL.
Dataset and Experimental Protocol
Experiments utilize the 360+x dataset, encompassing four video modalities and extensive annotations—28 scene categories and 38 action classes. Each video averages six minutes, yielding densely layered action sequences across modalities.




Figure 3: Sample videos from the dataset, illustrating diverse modalities including panoramic, third-person, monocular, and binocular views.
Evaluation consists of two rounds, each measured by mAP across multiple IoU thresholds. Implementation employs PyTorch; backbone options include ResNeXt-101 (32×8d, 64×4d) with panoramic video input due to incomplete ancillary modality coverage.
Numerical Results and Analysis
The proposed method achieved first place in both rounds of the BinEgo-360 Challenge, with mAP scores outperforming all other teams in both public and private leaderboard evaluations. Notably, ensemble learning contributed the highest gain in both settings; multi-task optimization and backbone selection yielded consistent incremental improvements. Ablation studies confirm that joint multitask learning and TSM extension substantially improve TAL performance compared to single-task or baseline constructions.
Implications and Future Directions
This work demonstrates that efficient temporal modeling via TSM, when extended with background segmentation, interval-based classification, and context-aware multitask training, can achieve state-of-the-art results in complex, multi-modal TAL benchmarks. Notably, results were obtained without leveraging the full suite of available modalities, implying that future research may benefit further from multi-modal fusion (audio, GPS, textual descriptions) and more adaptive interval selection strategies to capture diverse action lengths and concurrency. The dataset itself sets a precedent for realistic TAL evaluation in robotic, VR/AR, and real-world surveillance deployments.
Potential lines of inquiry include:
- Development of dynamic or adaptive interval sizing for finer temporal granularity
- Integration of transformer-based modules to further enhance long-range temporal context modeling
- Full exploitation of multi-modal sensory inputs for robust domain generalization and transfer learning
- End-to-end training with modality-specific fusion architectures
Conclusion
The presented solution formalizes an extensible approach for temporal action localization built on TSM, multi-task learning, and ensemble strategies. Comprehensive evaluation on the BinEgo-360 dataset validates its efficacy for multi-modal, multi-perspective TAL. The architecture, while already competitive, serves as a strong baseline for future innovations leveraging richer modalities and advanced temporal reasoning mechanisms.