- The paper presents libyt's innovative in situ interface that seamlessly connects simulations with Python, yt, and Jupyter to overcome I/O bottlenecks.
- It details a multi-layered, MPI-aware architecture that maps simulation data directly to NumPy arrays, minimizing memory duplication and overhead.
- Demonstrated on astrophysical and mesoscale simulations, libyt achieves a 20–45% performance boost over traditional post-processing while enabling interactive analysis.
In Situ Analysis for Exascale Simulations: Architecture and Applications of libyt
Motivation and Context
As simulation scales have increased towards exascale, traditional post-processing has become inefficient due to I/O bottlenecks and untenable storage requirements. This is acute in domains such as astrophysics, where the need for high spatiotemporal resolution frequently collides with the limits of file-based workflows. The "libyt: an In Situ Interface Connecting Simulations with yt, Python, and Jupyter Workflows" (2512.11142) provides an open-source C library, libyt, offering a robust interface for in situ analysis: simulation outputs are analyzed and visualized directly in memory through seamless integration with yt, Python, and the Jupyter ecosystem. The library is designed for HPC/MPI environments and supports advanced workflows such as interactive Jupyter Notebook-based analysis and back-communication for custom field generation.
System Architecture and Design
libyt implements a multi-layered architecture designed to support minimal workflow changes for simulation scientists accustomed to Python/yt post-processing. Its principal components include the libyt Python Module (the C–Python bridge), yt_libyt (a custom yt frontend for memory-resident data access), the libyt Jupyter kernel, and a Jupyter integration layer (jupyter_libyt). Each simulation MPI process launches its own embedded Python interpreter and module instance to enable parallel data manipulation and analysis.
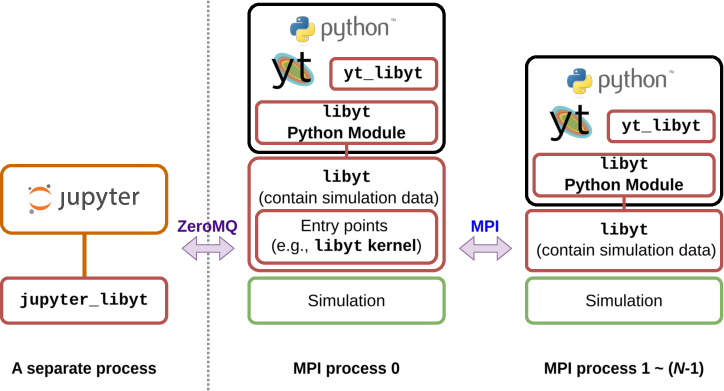
Figure 1: The libyt system architecture, showing interconnections between the simulation, the C bridge, MPI processes, the yt frontend, and the Jupyter ecosystem.
The API provides standard entry points for both automated and interactive in situ workflows. During analysis, the simulation halts and control is transferred to embedded Python, which has direct access to simulation data and can leverage the full yt ecosystem or arbitrary Python libraries.
Interface Mechanics and Data Mapping
libyt's data binding strategy minimizes memory duplication: field and particle data are registered as pointers with explicit metadata (dimensions, datatypes, ghost layers, centering), and exposed as NumPy arrays (read-only by default) within Python. When derived fields or non-contiguous particle structures are requested by Python code, user-supplied C callbacks supply only the necessary data, on-demand, into newly allocated arrays, optimizing both memory footprint and computational efficiency.
Parallel access is managed with collective MPI operations and Remote Memory Access (RMA) epochs to enable arbitrary decompositions across distributed memory, regardless of the original simulation's partitioning. All I/O is orchestrated to ensure consistency and deadlock avoidance across the MPI task space.
A yt frontend (yt_libyt) is provided that exposes the in-memory AMR data structures exactly as expected by standard yt scripts, facilitating reuse: converting a post-processing script to an in situ analysis typically requires only modification of two lines of code, specifically the import and dataset loader instantiation.
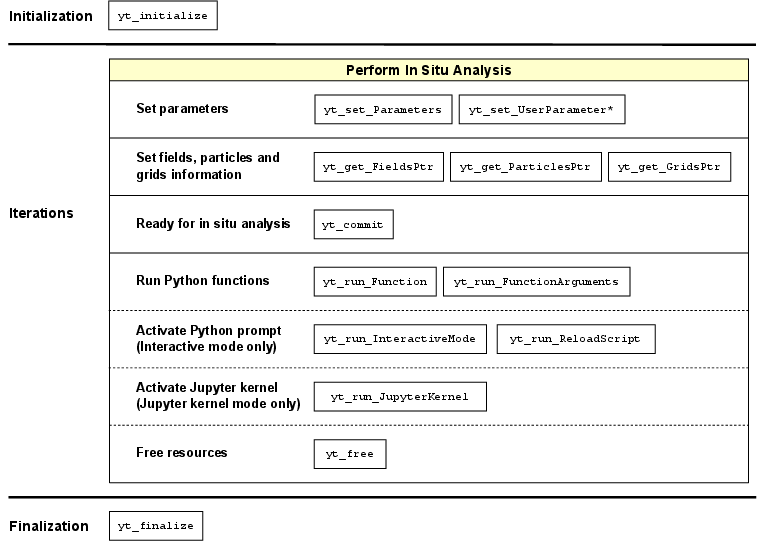
Figure 2: Workflow for libyt-based in situ analysis, detailing API method calls and stage transitions within each simulation cycle.
Jupyter Integration and Human-in-the-Loop Capabilities
Jupyter Notebook access is realized by launching a custom libyt kernel from the simulation root MPI process and providing a Jupyter extension that connects to this kernel via ZeroMQ. This supports interactive, synchronous analysis under MPI, enabling exploratory workflows such as visualization, real-time feature extraction, and dynamic experiment steering.
Notably, direct access to the simulation's runtime data from a fully functional Jupyter interface, including support for auto-completion and magic commands for libyt-specific inspection and error management, offers significant debugging and development advantages.
Application Demonstrations
Astrophysical Simulations
libyt is deployed in both the GAMER and Enzo simulation frameworks to demonstrate its operational efficacy in large-scale, real-world simulations. Core-collapse supernovae, isolated dwarf galaxies, and fuzzy dark matter (FDM) scenarios are analyzed in situ with high-frequency (e.g., 0.2 ms) plane extractions, projection plots, and phase diagrams, with minimal overhead and orders-of-magnitude reduction in storage requirements compared to traditional snapshot dumping.
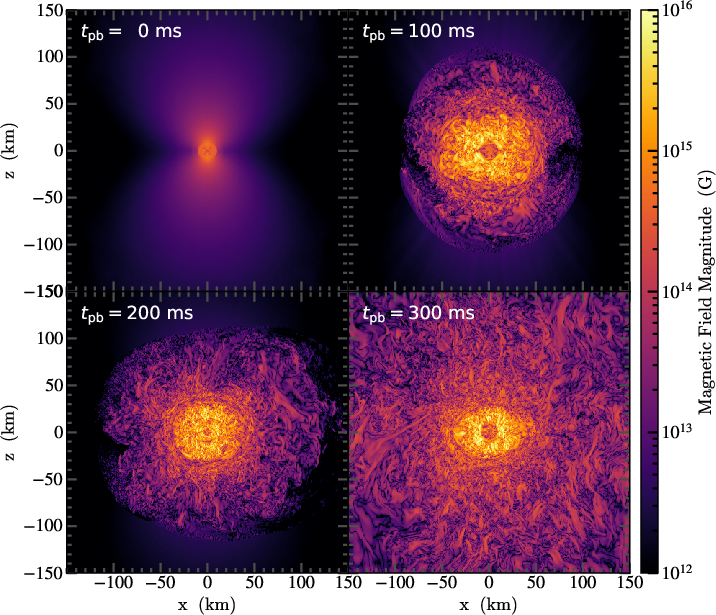
Figure 3: Evolution of the magnetic field following core bounce in a 3D supernova simulation; in situ plane extraction at 0.2 ms cadence via libyt enables resolution of fast-growing MRI/SASI instabilities.
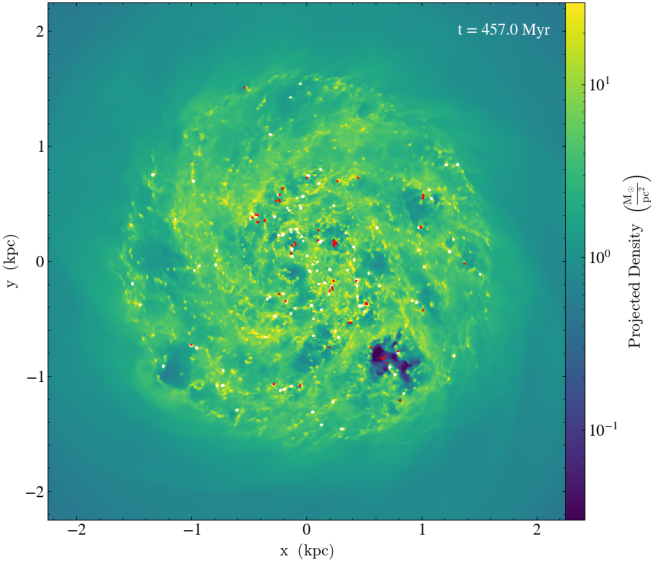
Figure 4: Projected gas density from an isolated dwarf galaxy simulation, with annotations for recent supernovae and star particles, computed during simulation runtime using in situ workflows.
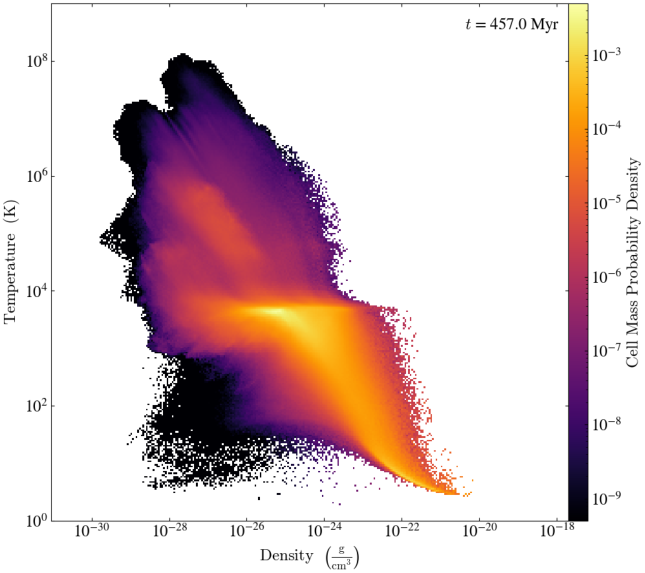
Figure 5: Gas phase distribution over time in a dwarf galaxy, constructed at ~1 Myr cadence during simulation, illustrating turbulent ISM evolution at temporal resolutions impractical for direct snapshot storage.
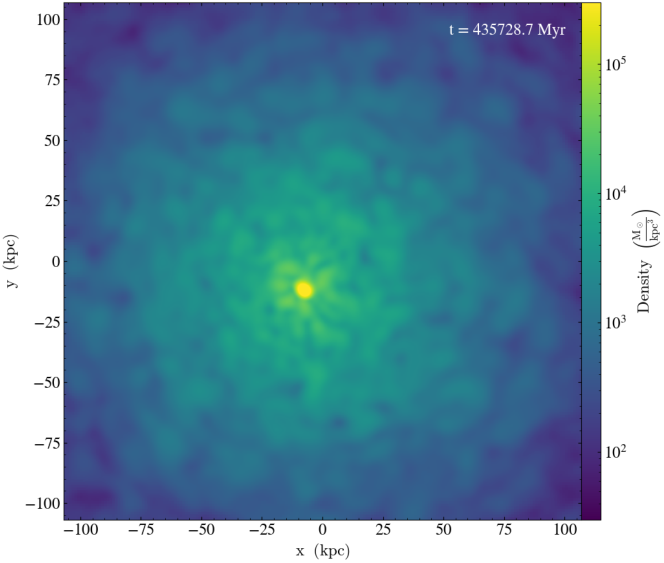
Figure 6: High-cadence tracking of soliton condensation in a fuzzy dark matter halo; animation constructed from in situ projections without costly full-volume snapshot I/O.
Mesoscale and Standard Test Problems
libyt also provides a performant interface for analyzing traditional test problems (1D Sod shock tube, 2D Kelvin-Helmholtz instability) and high-resolution galaxy simulations (AGORA benchmark) entirely in situ, with tightly coupled yt-based analysis and direct pipeline consistency with pre-existing post-processing scripts.
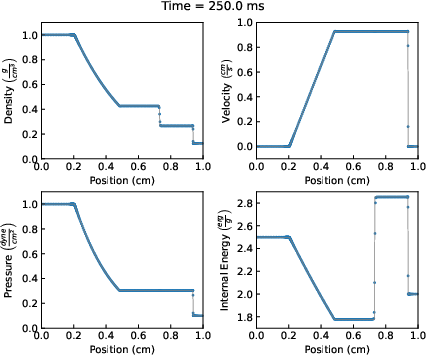
Figure 7: Sod shock tube results visualized at each timestep; simulation, analysis, and figure generation unified via libyt-driven in situ LinePlots.
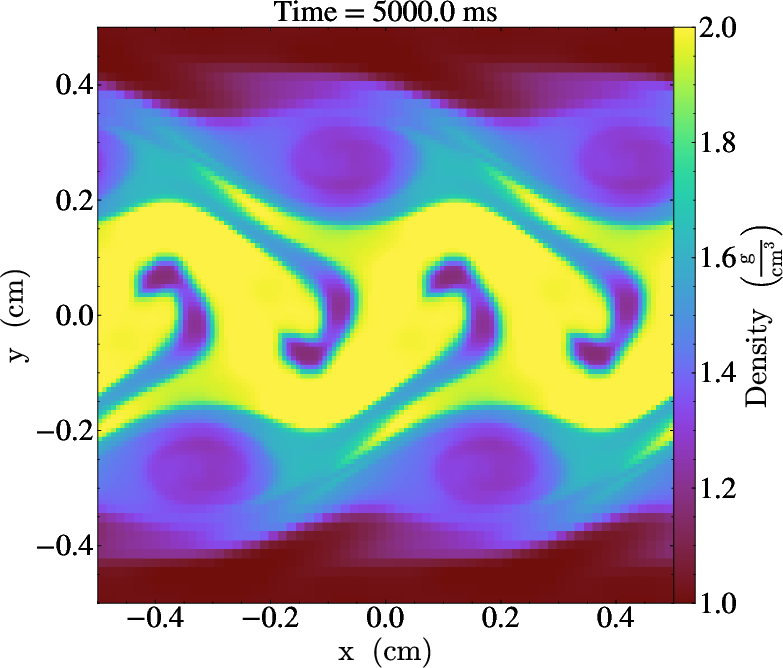
Figure 8: Kelvin-Helmholtz vortex evolution, rapidly visualized at each step without post-run file manipulation.
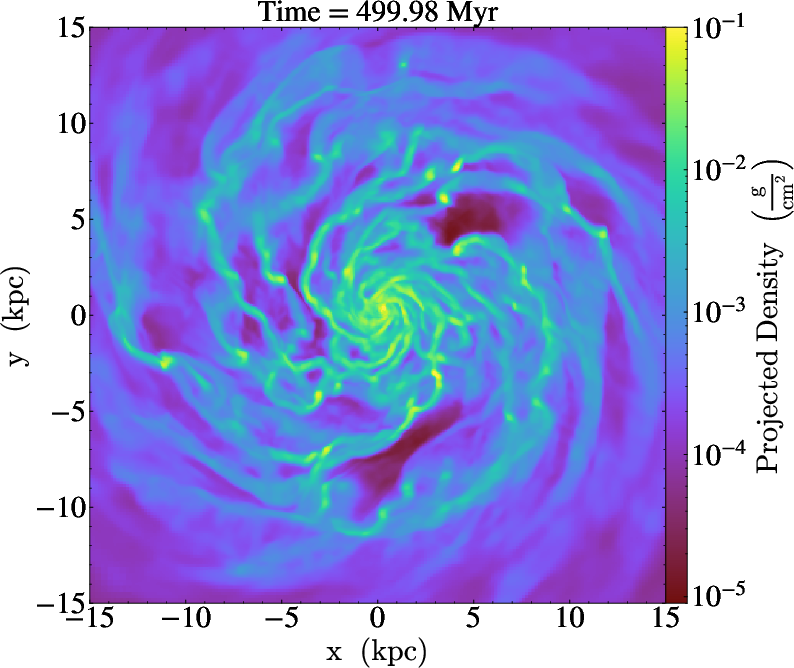
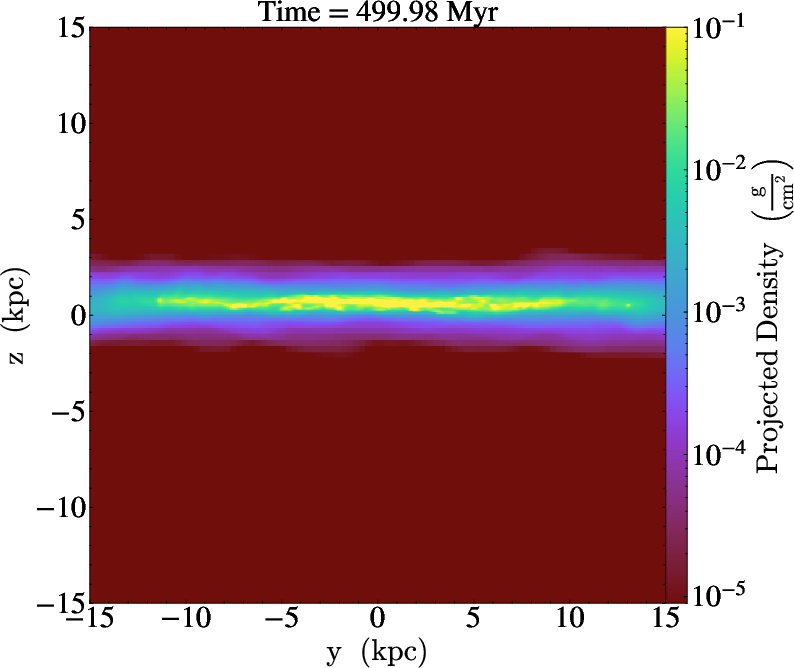
Figure 9: AGORA galaxy simulation; projections produced in situ by libyt at high spatiotemporal resolution without exceeding storage constraints.
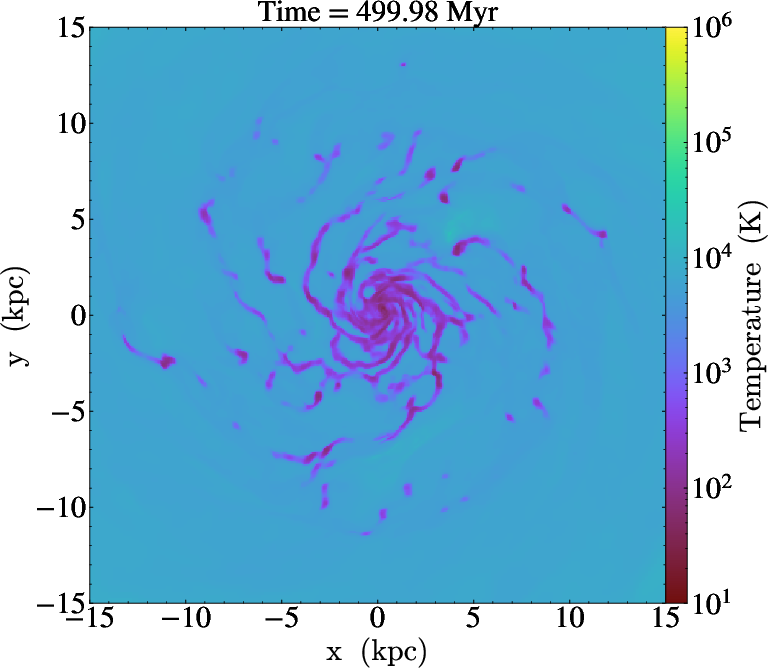
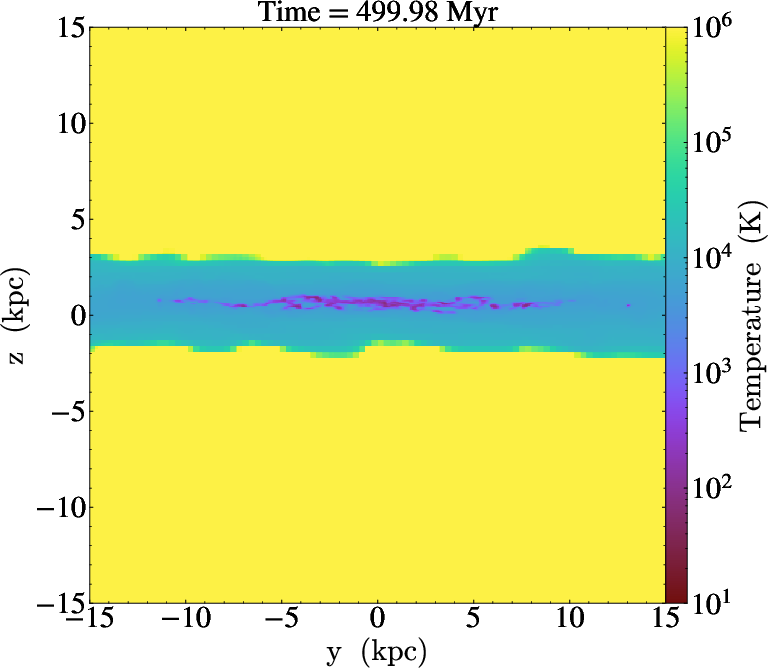
Figure 10: Temperature projections (density-squared weighted) from AGORA galaxy simulation, generated at each simulation timestep.
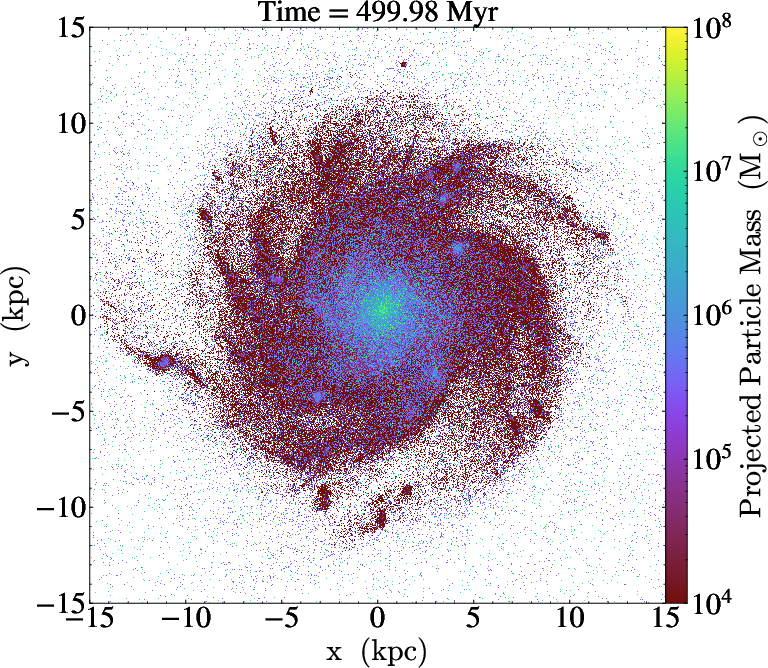
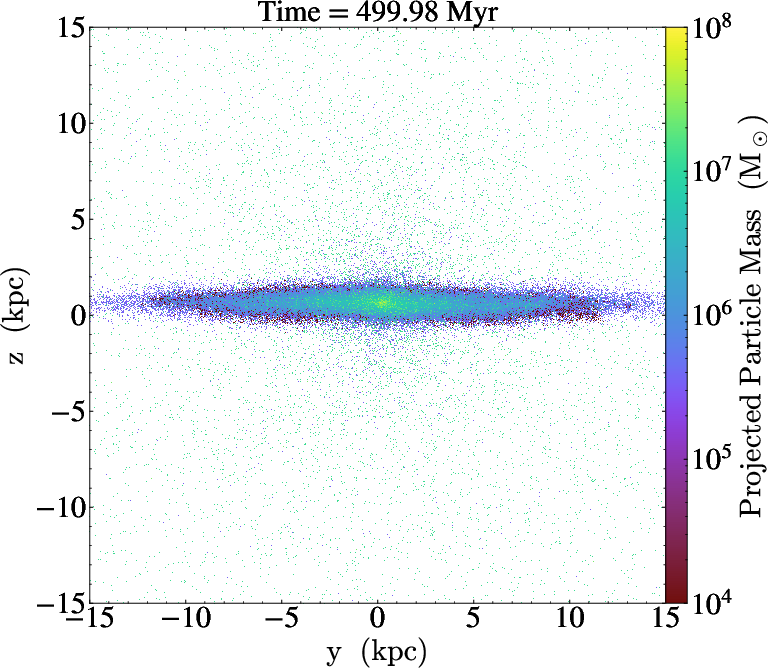
Figure 11: Particle mass annotations in AGORA galaxy output, colored by clump mass, rendered live via in situ analysis with libyt.
Strong scaling is demonstrated up to at least several hundred MPI processes and 109 cells, with libyt outperforming traditional post-processing by 20–45% due to the elimination of disk I/O when generating complex diagnostics such as yt 2D profiles.
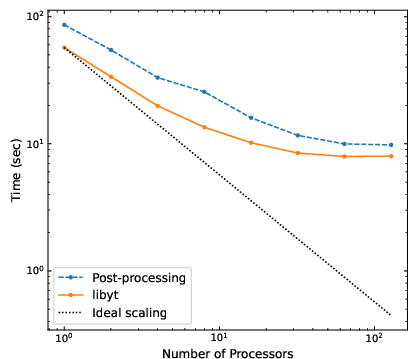
Figure 12: Strong scaling efficiency comparison of libyt in situ workflows to post-processing; libyt yields a significant time advantage by leveraging in-memory data.
Memory profiling confirms that libyt introduces minimal additional overhead (∼0.2 KB per grid metadata) beyond simulation-resident data; transient increases during derived field generation and data redistribution are controllable through chunking. However, Python's memory consumption—especially for operations such as print_stats on topologically fine AMR hierarchies—can dominate if not tightly managed.
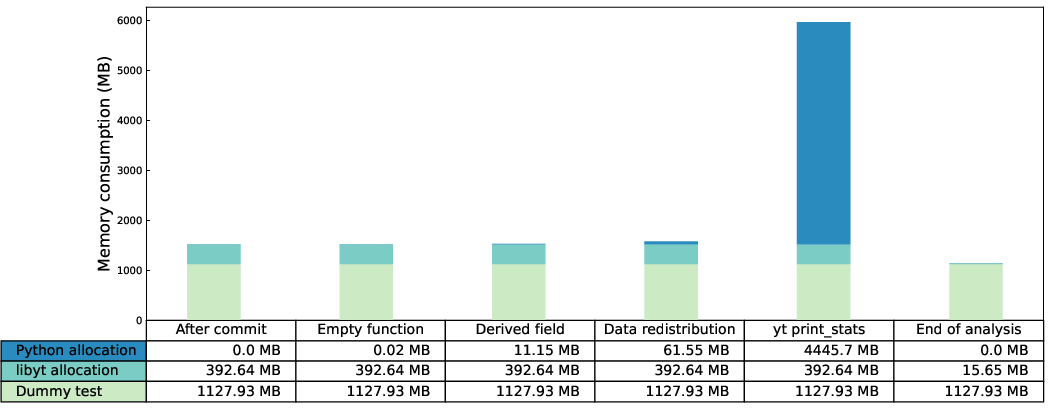
Figure 13: Per-process memory usage for each libyt analysis phase, confirming low overhead and illustrating potential peaks during yt-driven diagnostics.
Limitations
Two primary constraints are salient: (1) All I/O under libyt is collective, so every MPI process must participate in data-accessing yt operations. Asymmetric or local-only operations in parallel analysis routines may cause deadlock. (2) The Python prompt/Jupyter kernel runs in an isolated loop and does not support asynchronous interruption (e.g., KeyboardInterrupt), and certain advanced notebook frontend features are restricted to text outputs. Volume rendering with odd numbers of MPI processes is not supported due to yt parallel decomposition requirements.
High memory use by Python—especially for unbalanced workflows or very large datasets—remains an issue; mitigation requires careful job decomposition, increasing the number of ranks, or offloading analysis to separate nodes.
Implications and Future Directions
libyt demonstrates that seamless in situ analysis, with negligible code changes relative to traditional post-processing workflows, is achievable for state-of-the-art AMR and particle-based astrophysical simulations. This paradigm substantially reduces I/O and storage demands and supports interactive, human-in-the-loop exploration even at full simulation scale. The approach serves as a blueprint for exascale simulation analysis, and its Python-centric ecosystem is well-positioned to enable integration with machine learning frameworks and real-time, coupled AI-driven model updates. Bidirectional communication enables not only analysis but the potential for simulation steering and hybrid physics–AI workflows.
As future scientific needs shift towards adaptive, on-the-fly analysis, AI integration, and large-ensemble pipeline management, the libyt model provides a compelling, open-source platform for scalable and flexible simulation analysis.
Conclusion
The libyt interface (2512.11142) achieves a high degree of interoperability between legacy HPC codes and the modern Python analysis stack, implementing a robust in situ analysis solution that overcomes key exascale simulation bottlenecks. By closely matching existing post-processing APIs, supporting tight Jupyter integration, and providing efficient MPI-aware data management, libyt presents a system that will be directly beneficial for large-domain simulation researchers and offers a strong foundation for next-generation AI-driven simulation–analysis loops.