- The paper introduces a systematic acceleration strategy combining knowledge distillation, blockwise neural architecture search, and structured pruning to achieve robust zero-shot stereo matching.
- It integrates hybrid monocular-stereo priors and leverages a large-scale pseudo-labeled in-the-wild dataset to enhance out-of-domain generalization.
- Empirical results demonstrate real-time performance (21–49ms on an NVIDIA 3090 GPU) with minimal accuracy loss across diverse stereo benchmarks.
Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching
Introduction
Fast-FoundationStereo (2512.11130) addresses a fundamental challenge in stereo matching: achieving both strong zero-shot generalization, as delivered by recent vision foundation models (VFMs), and real-time inference—critical for robotics, autonomous vehicles, and AR applications. Traditional foundation stereo models are accurate and robust but computationally intensive, while fast models compromise on generalization and require extensive per-domain fine-tuning. Fast-FoundationStereo proposes a systematic acceleration strategy combining distillation, neural architecture search, and structured pruning, supplemented by a large-scale pseudo-labeled in-the-wild stereo dataset, to bridge this gap.
Framework Overview
The architecture builds on FoundationStereo, which decomposes the stereo pipeline into three stages: feature extraction, cost filtering, and disparity refinement. Each stage is independently optimized for speed and generalization via a divide-and-conquer approach. The overall pipeline is depicted in Figure 1.
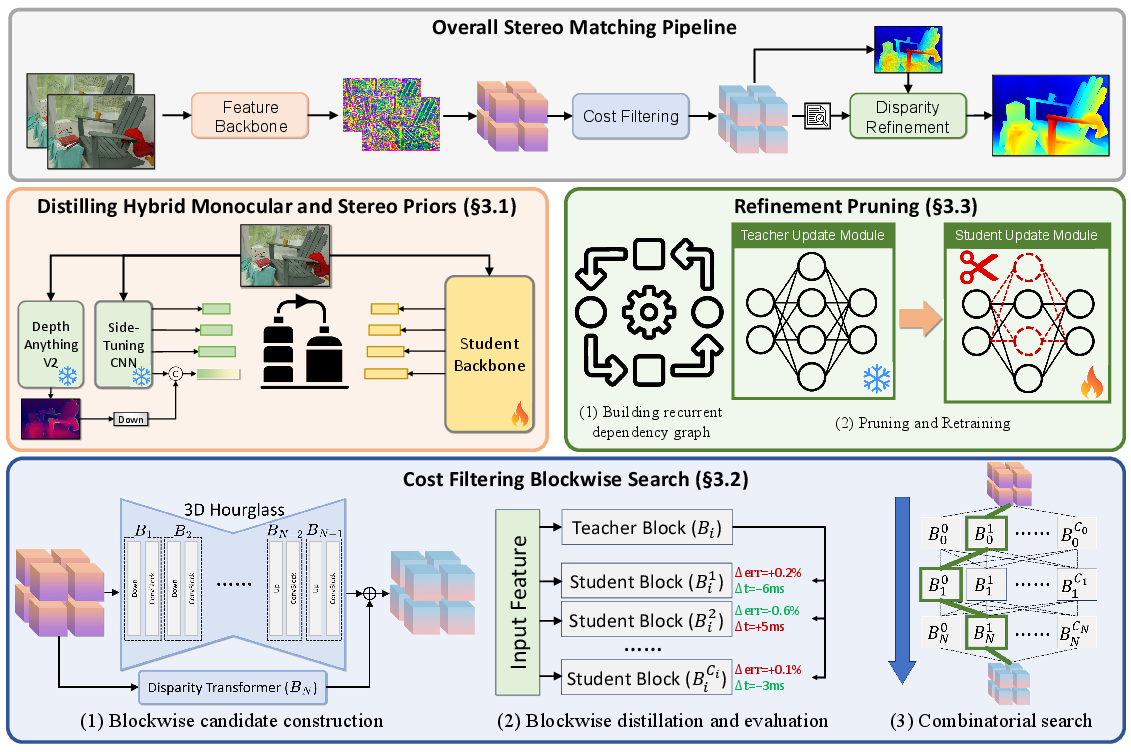
Figure 1: Overview of the Fast-FoundationStereo framework, showing staged acceleration strategies for each major component.
Methodology
Distillation of Hybrid Monocular and Stereo Priors
Feature extraction in FoundationStereo leverages both monocular priors from DepthAnything V2 and stereo-specific features via side-tuning CNNs. Fast-FoundationStereo applies knowledge distillation to compress this hybrid backbone into a single efficient student network. This approach preserves cross-domain robustness and high-frequency edge detail needed for challenging scenes (Figure 2), while providing significant reductions in computational cost and memory footprint.

Figure 2: Distillation of hybrid monocular and stereo priors into a unified backbone preserves high-frequency edge structure and improves robustness in challenging cases.
Multiple student backbones are trained to offer a range of accuracy-latency tradeoffs, outperforming direct pruning or manual redesigns.
Cost Filtering Blockwise Neural Architecture Search
Cost filtering uses a 3D hourglass architecture with axial-planar convolutions and a Disparity Transformer for global context. Rather than direct distillation or naive pruning—which yields marginal improvements at significant performance loss—Fast-FoundationStereo divides the cost filtering network into blocks and uses blockwise training. Neural architecture search (NAS) is performed independently for each block, constrained by runtime budgets, and the best block combinations are selected by integer linear programming.
This blockwise strategy reduces the NAS search space exponentially from O(nN) to O(n) and decouples local optimization from combinatorial explosion, enabling efficient hardware-aware exploration (Figure 3).
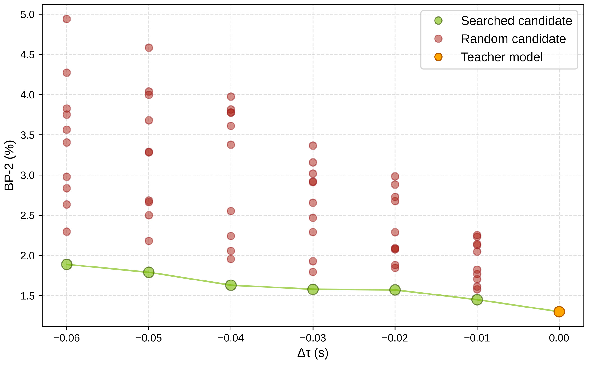
Figure 3: Effects of blockwise architecture search for cost filtering under varying latency budgets, supporting the construction of models at diverse accuracy-speed tradeoffs.
Structured Pruning of Refinement Modules
Disparity refinement is implemented with recurrent ConvGRU modules, introducing redundancy across iterations and channels. Fast-FoundationStereo constructs a dependency graph (Figure 4), prunes redundant connections or channels based on global importance ranking, and retrains the pruned modules to restore performance. This structured approach leverages inter-layer dependencies unique to the refinement networks and translates directly to improved inference speed.
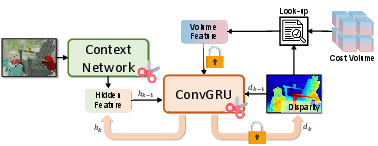
Figure 4: Dependency graph for the recurrent refinement module, illustrating structured pruning points and protected channel dependencies.
Empirical results (Figure 5) demonstrate that aggressive pruning is feasible without a substantial loss in prediction accuracy after retraining, highlighting significant over-parameterization in standard ConvGRU-based refinement.
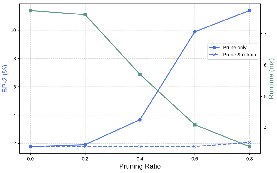
Figure 5: Influence of pruning ratio on both accuracy and speed, showing recoverability via retraining.
Internet-Scale Pseudo-Labeling for Robustness
High-quality real-world ground-truth for stereo is scarce. To address this, Fast-FoundationStereo curates 1.4 million in-the-wild stereo pairs using a pseudo-labeling pipeline (Figure 6) that cross-verifies teacher disparity outputs against monocular predictions via a normal consistency check, discarding unreliable samples and masking sky regions with semantic segmenters. These pseudo-labeled pairs supplement synthetic data during student training, enhancing out-of-domain robustness.
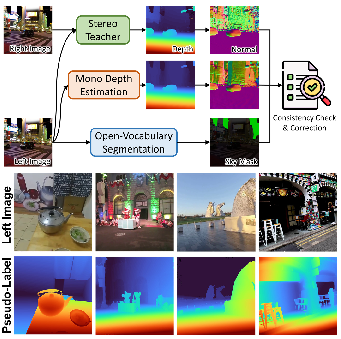
Figure 6: Automatic pseudo-labeling and consistency check pipeline for harvesting diverse, high-realism stereo pairs from internet videos.
Experimental Analysis
Zero-Shot Generalization and Efficiency
Fast-FoundationStereo delivers strong zero-shot generalization with real-time (21–49ms on NVIDIA 3090 GPU) inference, significantly outperforming prior real-time baselines and closely matching foundation models that are over an order of magnitude slower (Figure 7).
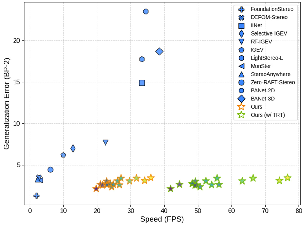
Figure 7: Zero-shot accuracy-speed trade-off: Fast-FoundationStereo achieves real-time inference with minimal degradation in accuracy compared to foundation stereo baselines.
Qualitative analysis (Figure 8) across Middlebury, ETH3D, Booster (for non-Lambertian surfaces), and KITTI-2015 datasets confirms robust generalization without in-domain fine-tuning, a historically difficult barrier for real-time models.

Figure 8: Qualitative results in diverse real-world conditions, demonstrating high fidelity for real-time inference without any training on the target datasets.
A detailed runtime breakdown (Figure 9) demonstrates speed gains stemming from every stage—feature extraction, cost filtering, and refinement—confirming the holistic impact of the divide-and-conquer acceleration.
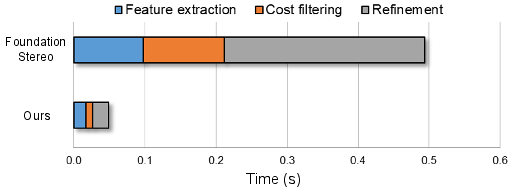
Figure 9: End-to-end runtime decomposition highlights efficiency improvements throughout the pipeline.
Ablation and Component Analysis
Blockwise NAS consistently outperforms randomly-assembled or manually-pruned networks at the same latency (Figure 3). Distillation from hybrid monocular-stereo priors outperforms simple ImageNet pretraining or alternative loss functions (as shown in the main text). Inclusion of pseudo-labeled in-the-wild data improves out-of-domain generalization for both Fast-FoundationStereo and competing baselines.
Implications and Future Directions
Fast-FoundationStereo demonstrates that foundation model performance and real-time inference are not mutually exclusive. Its modular acceleration and training strategies unlock practical foundation stereo models for robotics, AR/VR, and autonomous driving—domains where robustness and latency are concurrently critical. The blockwise NAS approach and structured pruning methodology generalize to other deployment-constrained vision systems utilizing hybrid foundation architectures.
The paper suggests that quantization remains an orthogonal direction for further latency and memory reduction, and the pseudo-labeling pipeline highlights opportunities for self-supervised and hybrid training schemes that close the synthetic-to-real gap.
Conclusion
Fast-FoundationStereo (2512.11130) systematically closes the gap between robust, open-world zero-shot performance and real-time constraints in stereo vision. Its combined use of knowledge distillation, blockwise neural architecture search, structured recurrent pruning, and large-scale pseudo-labeling establishes state-of-the-art generalization within real-time budgets, while providing flexible accuracy-speed tradeoffs. This advancement provides both a strong practical tool for embodied AI applications and a methodological template for accelerating other large vision model families.

