- The paper introduces the Lite Any Stereo framework, achieving state-of-the-art zero-shot stereo matching with less than 1% MACs compared to traditional models.
- It employs a hybrid cost aggregation module and a three-stage training strategy that integrates supervised learning, self-distillation, and real-world knowledge distillation.
- The approach outperforms existing efficient networks on benchmarks like KITTI and Middlebury, enabling real-time deployment on resource-constrained platforms.
Efficient Zero-Shot Stereo Matching with Lite Any Stereo
Introduction
The "Lite Any Stereo" framework proposes an ultra-efficient stereo matching architecture optimized for zero-shot generalization capabilities. It addresses persistent challenges in deploying stereo vision on resource-constrained platforms by reconciling the trade-off between model efficiency and generalization, which has typically favored large accuracy-oriented networks. By introducing a hybrid cost aggregation backbone and a three-stage scalable training pipeline, Lite Any Stereo attains state-of-the-art zero-shot performance across standard benchmarks, requiring less than 1% MACs relative to existing high-accuracy models.
Standard stereo matching architectures rely on either 3D/4D cost volumes aggregated by deep CNNs or transformer-based modules, often with substantial computational overhead. While recent works leverage foundation models with monocular depth priors for enhanced zero-shot transfer, they remain unsuitable for real-time use. Efficiency-driven models employing lightweight backbones and reduced spatial resolutions achieve speed, but suffer from significant accuracy drops and limited cross-domain generalization. Lite Any Stereo distinguishes itself by preserving generalization and accuracy within the strict constraints of minimal MACs and memory footprint.
Architectural Overview
Lite Any Stereo features a four-stage pipeline: shared-weight feature extraction, stereo correlation with cost volume construction, hybrid 3D–2D cost aggregation, and convex upsampling for full-resolution disparity estimation. Backbone selection favors MobileNetV2 due to optimal channel configuration for stereo tasks, eschewing resource-intensive depth prior backbones even in their smallest variants.
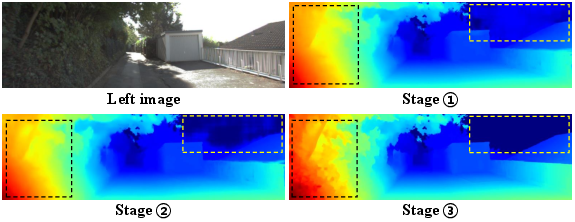
The core innovation lies in the hybrid cost aggregation module. It integrates multi-scale 3D convolutions for disparity-dimension perception (preserving geometric cues), fused with ConvNeXt-based 2D blocks for enhanced spatial context. Ablations reveal that serially stacking a minimal 3D block preceding the 2D block (with only 4.8% 3D layers under a fixed MAC budget) maximizes both accuracy and resource savings (Figure 1).
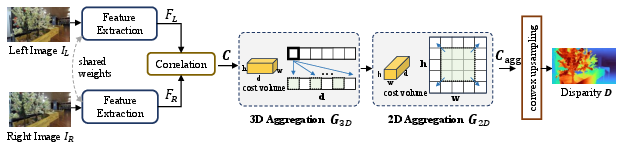
Figure 2: Overview of the proposed Lite Any Stereo, highlighting its four-stage architecture and hybrid cost aggregation strategy for efficient disparity estimation.
Three-Stage Training Strategy
Lite Any Stereo leverages a training paradigm comprising three progressive stages (Figure 3):
- Supervised Learning on Synthetic Data: Trained on 1.8M labeled stereo pairs synthesized from SceneFlow, FallingThings, FSD, CREStereo, VKITTI2, TartanAir, and Dynamic Replica for robust baseline capacity.
- Self-Distillation on Synthetic Data: Teacher and student models share initialization; the teacher receives clean inputs and the student is perturbed, enforcing domain invariance and feature robustness via a feature alignment loss.
- Knowledge Distillation on Real-World Unlabeled Data: Fine-tuning is performed using pseudo-labels produced by a frozen accurate teacher on diverse real-world stereo datasets. No self-distillation is applied at this stage, as its effect is negligible for pseudo-labeled data.
The synergy of large-scale high-quality data, progressive distillation, and robust feature alignment bridges the simulation-to-reality domain gap more effectively than data augmentation alone. Notably, fixed teacher weights in self-distillation yield optimal results over EMA or hard copy updates.
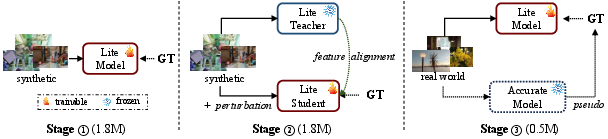
Figure 3: Overview of the three-stage training strategy: supervised training, self-distillation, and real-world knowledge distillation.
Lite Any Stereo achieves highly competitive zero-shot results, outperforming all tested efficient networks and approaching—sometimes surpassing—non-prior-based accurate models, while requiring under 1% of their compute budget. Benchmarked on KITTI 2012/2015, Middlebury, and ETH3D, the model leads in D1 and EPE metrics across million-scale settings.
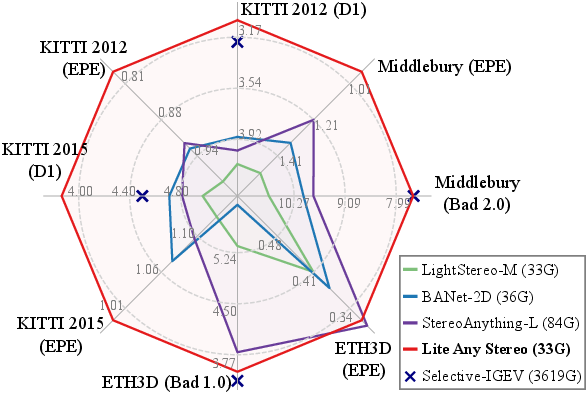
Figure 4: Zero-shot performance: Lite Any Stereo achieves SOTA by a large margin, rivaling accurate models at <1% of their MACs.
In an extensive qualitative comparison, Lite Any Stereo preserves structural details, smooth boundaries, and accurate disparities in challenging scenes where competing methods manifest blur, artifacts, or geometric loss.
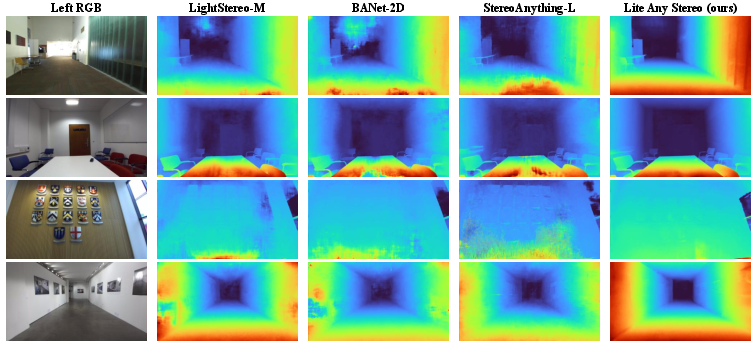
Figure 5: Qualitative comparison of zero-shot inference on wild images—Lite Any Stereo maintains geometric accuracy and structural integrity in diverse scenarios.
Lite Any Stereo generalizes across varied domains without target-specific fine-tuning. It also offers superior efficiency in runtime (17 ms inference on an A100 for 2K inputs; 2.5 GB VRAM), enabling practical deployment for embedded and mobile scenarios.
Ablations and Design Choices
Extensive ablation studies validate optimal architectural and training choices:
Practical and Theoretical Implications
Lite Any Stereo sets a precedent for zero-shot deployment of stereo matching networks in real-world applications constrained by compute, such as robotics, mixed/augmented reality, and automotive systems. Its design challenges the prevailing assumption that efficiency-oriented networks cannot attain robust generalization and high accuracy. Moreover, the universality of the training strategy extends improvements to alternate lightweight architectures.
The work underscores the importance of high-quality large-scale datasets, judicious pseudo-labeling, and feature-aligned self-distillation for sim-to-real transfer, independent of backbone complexity. Future directions include scaling real stereo data collection, developing a zoo of parameterized lightweight models, and further advancing robustness to transparency/reflective artifacts.
Conclusion
Lite Any Stereo demonstrates that ultra-lite, generalizable stereo matching is achievable by combining hybrid cost aggregation and a scalable, multi-stage training strategy. It consistently attains SOTA zero-shot performance with unprecedented efficiency, broadening the prospects for real-world stereo vision deployment. Further work should focus on expanding real-world datasets and heterogeneous model scaling for enhanced flexibility.
(2511.16555)