- The paper introduces a novel, windowed deep learning architecture (WeldNet) that reduces high-dimensional, nonlinear dynamics by partitioning temporal domains.
- It details using autoencoders, latent propagators, and transcoder networks to improve training stability and mitigate error accumulation over long-term rollouts.
- Empirical results across canonical PDEs, including Burgers' and shallow water equations, demonstrate WeldNet's superior performance over traditional linear and monolithic reduction methods.
Data-Driven Model Reduction Using WeldNet: Windowed Encoders for Learning Dynamics
Introduction
The paper "Data-Driven Model Reduction using WeldNet: Windowed Encoders for Learning Dynamics" (2512.11090) addresses high-dimensional, time-dependent data reduction in nonlinear dynamical systems arising from evolutionary and physical processes. Traditional projection-based linear model reduction strategies are well-understood but become inadequate for strongly nonlinear, non-stationary, or advection-dominated systems due to slow decay of the Kolmogorov n-width. WeldNet introduces a fundamentally nonlinear, windowed model-reduction architecture based on deep autoencoders, frame decomposition of the time domain, and cross-window latent space transcoders. This structured approach substantially improves training stability, long-term prediction, and expressivity over global, monolithic latent-space models.
WeldNet Framework and Architecture
WeldNet operates by partitioning the temporal axis into multiple (possibly overlapping) windows. Within each window, a nonlinear autoencoder provides local latent representations, while a propagator neural network models the time-evolution dynamics of these codes. Adjacent windows are connected by transcoder networks, trained on window overlaps, to seamlessly transfer latent states between temporally localized latent coordinate systems.
This hierarchical decoupling is depicted in the overall schematic of the inference pipeline:
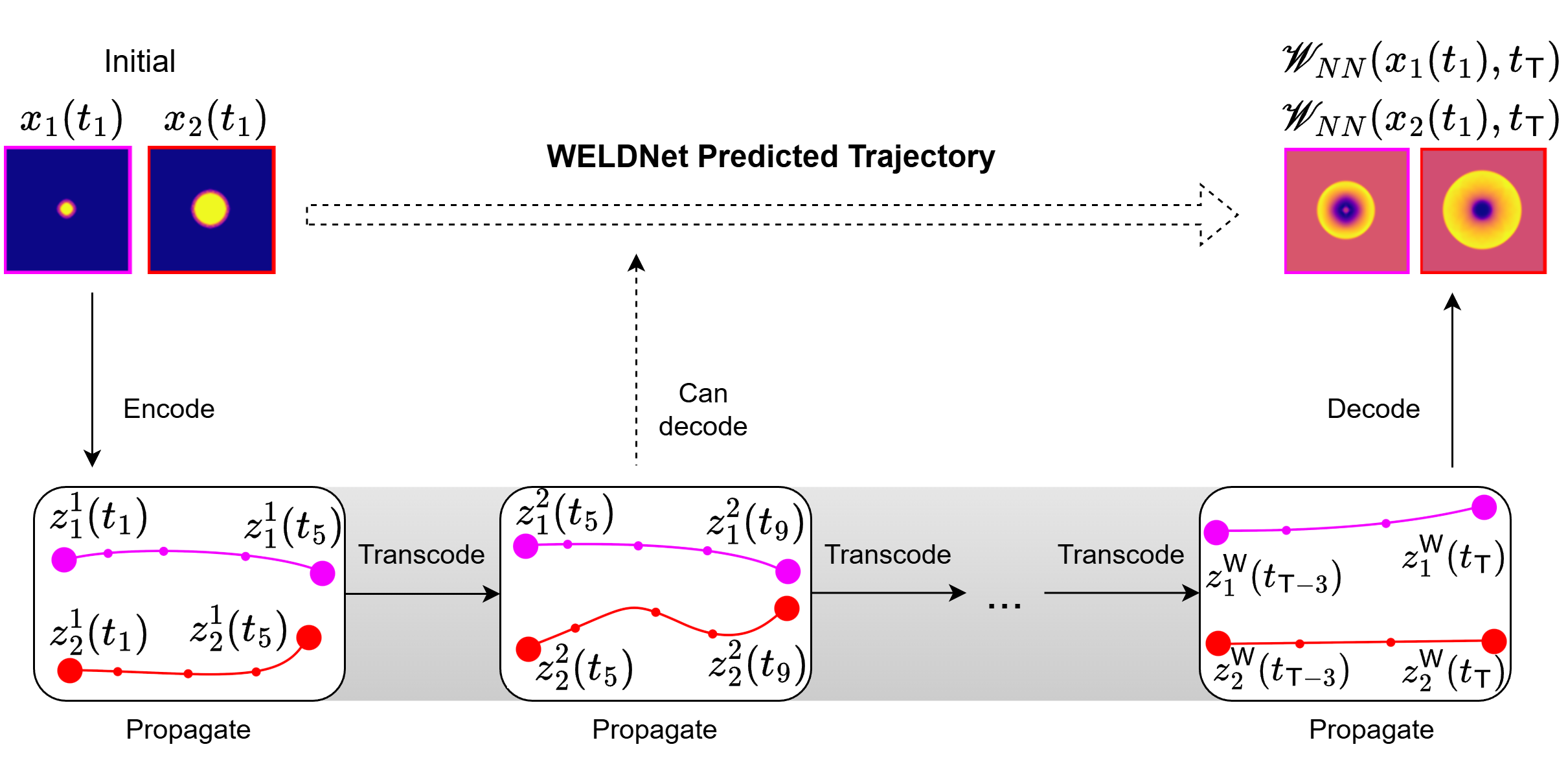
Figure 1: WeldNet: Initial conditions are encoded, propagated within windows, transcoded between windows, and decoded to reconstruct system states at any desired time.
Each WeldNet model consists of four key components as formalized in the system block diagram:
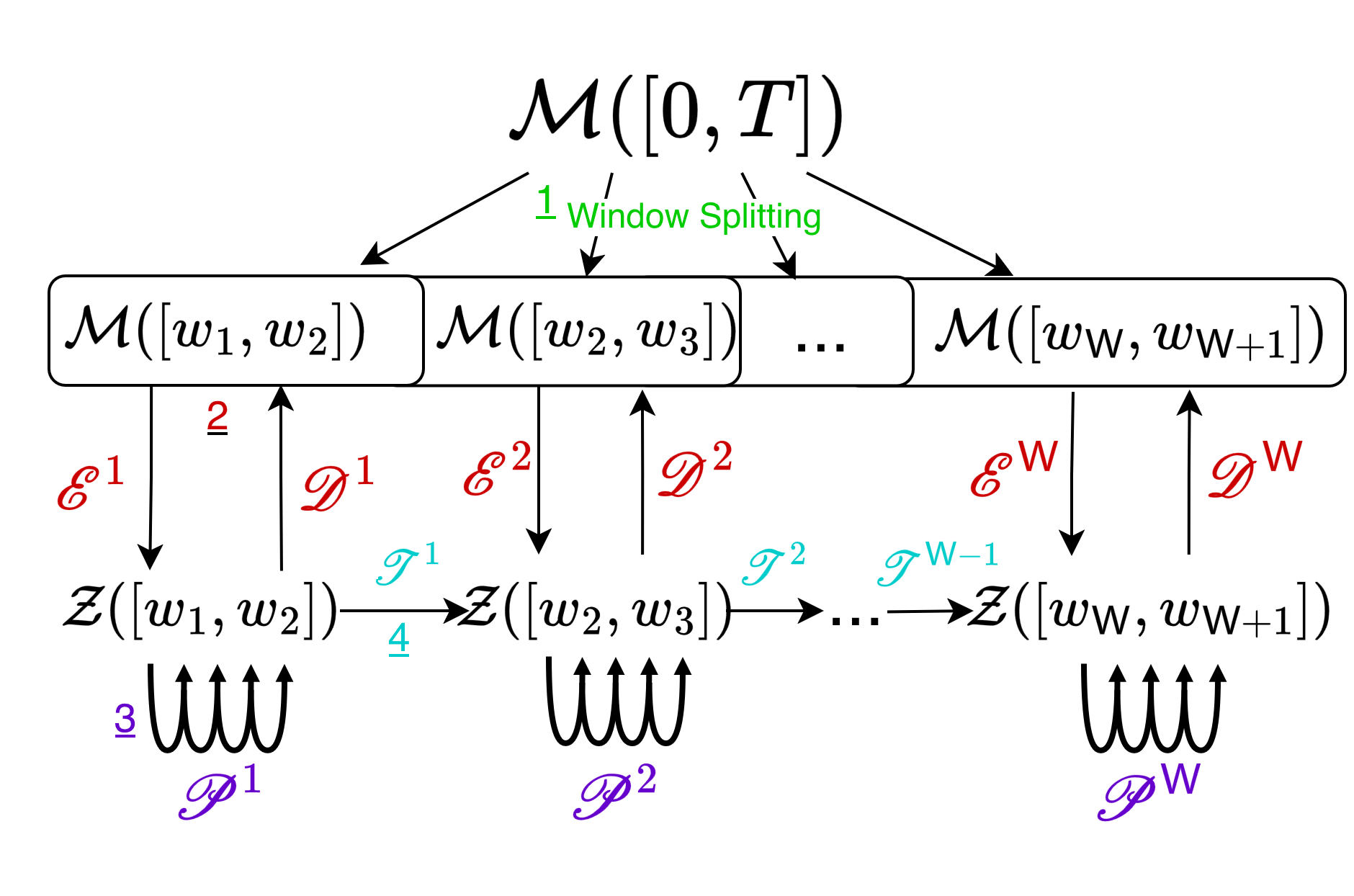
Figure 2: The WeldNet architecture comprises window splitting, nonlinear autoencoders, latent propagators, and transcoder networks.
The training pipeline is staged. First, windows are defined over the trajectory data. Dimension reduction (via autoencoders) and one-step latent-space propagators are co-trained per window. The loss is the MSE between the ground-truth trajectory and its reconstruction (autoencoder), as well as between predicted and ground truth latent state evolution (propagator):
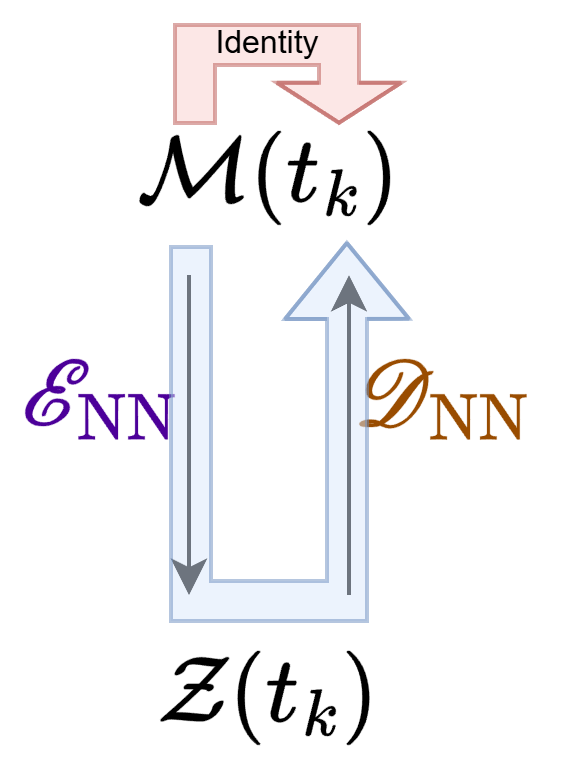
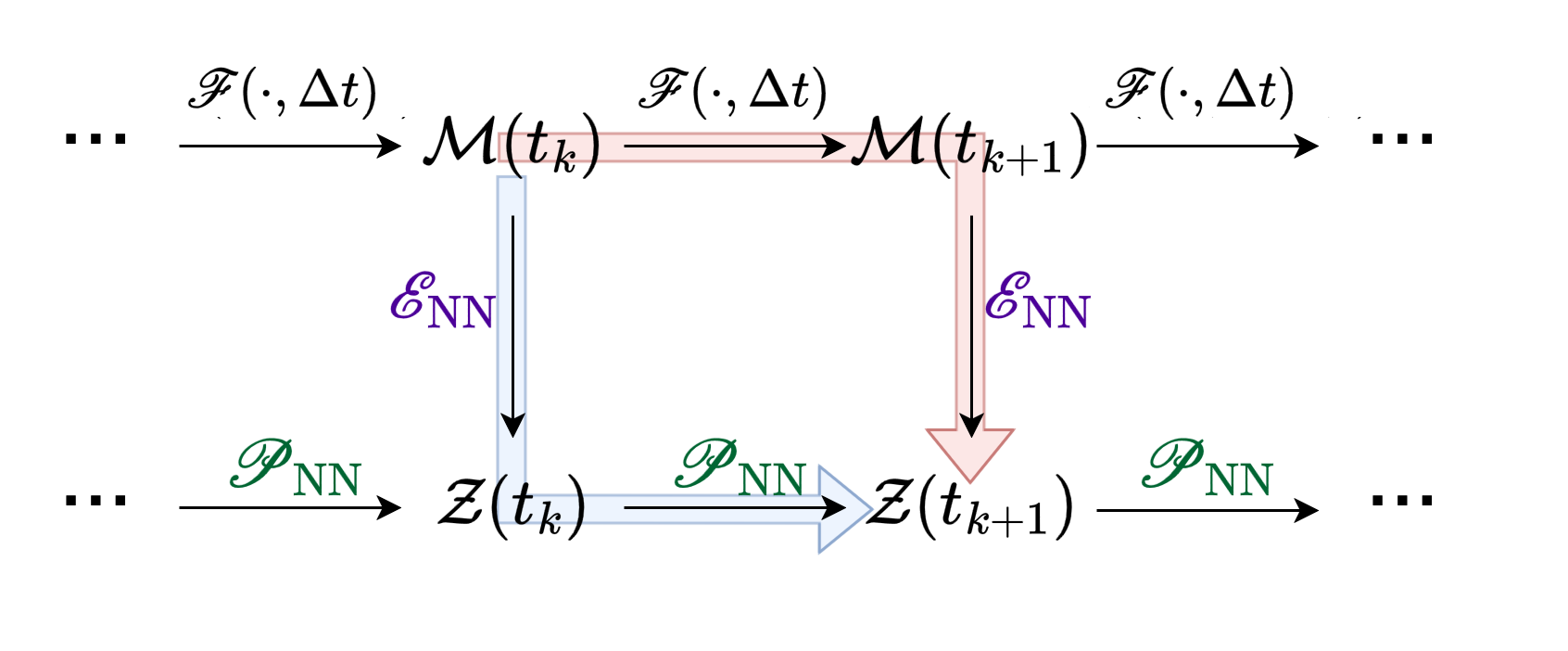
Figure 3: The training loss over each window comprises autoencoder reconstruction and latent propagator error terms.
Propagators are further finetuned to mitigate error accumulation over multi-step rollouts within each window, formulated as a loss over compositional sequences:
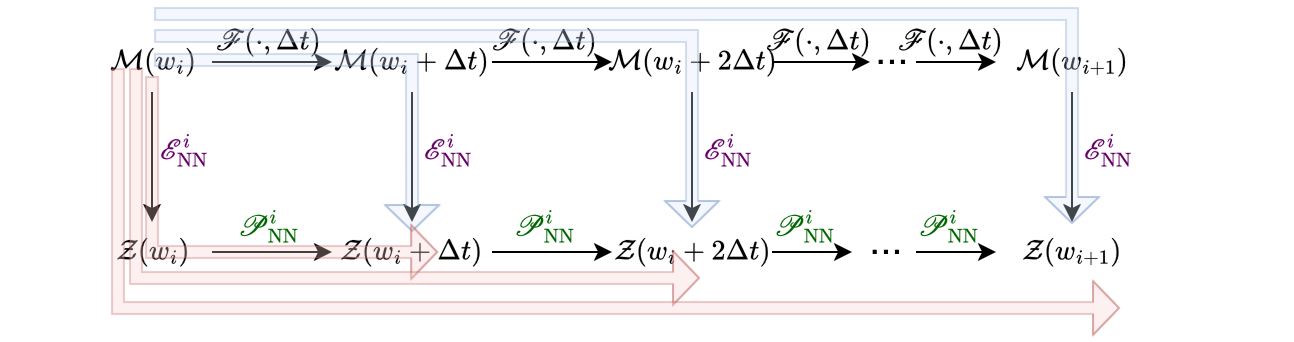
Figure 4: Propagator finetuning loss is the averaged MSE across multiple future steps in the latent space, addressing accumulation error over long time horizons.
Finally, transcoders are trained on window overlaps to ensure accurate latent state transfer across temporal partitions:
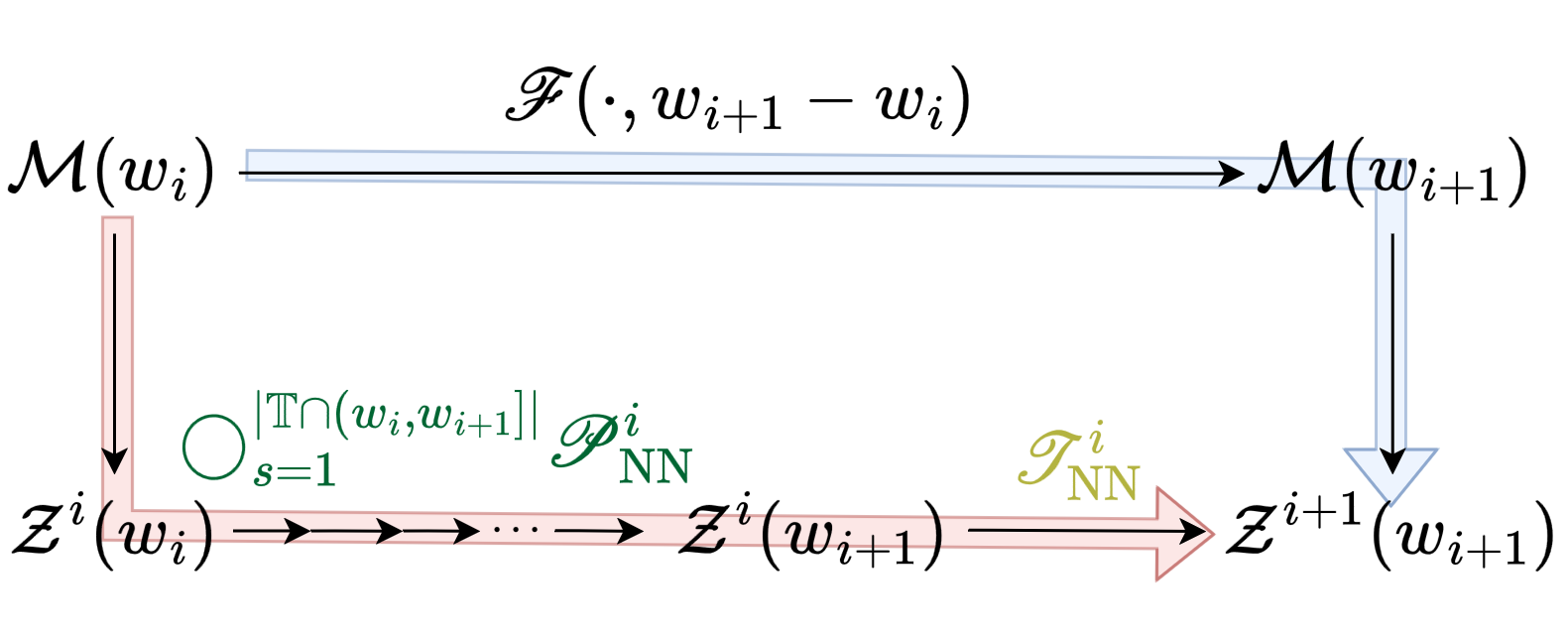
Figure 5: Transcoder loss is defined as the MSE between transformed latent codes at the end of window i and the codes at the start of window i+1.
Theoretical Representation Guarantees
The authors establish a mathematical foundation for WeldNet extending classical results for universal approximation and manifold hypothesis to the windowed, sequential, deep learning setting. Under the assumption that the solution manifold is piecewise regular and embedded, and the dynamical evolution is locally Lipschitz and (optionally) governed by latent ODEs, the WeldNet architecture (with sufficient network capacity and window resolution) can approximate the time-evolution operator to any desired accuracy.
The size of the required neural networks scales with the intrinsic dimension d of the underlying manifold, not the observed dimension D, demonstrating superior efficiency over methods whose costs are dictated by ambient space complexity. This holds both for the idealized setting with known latent dynamics and the general case, although windowing is critical to bounding error propagation over extended prediction horizons.
Empirical Results
Latent Space Visualization and Windowing Efficacy
The necessity for windowed latent spaces is illustrated on a canonical transport problem. Monolithic (one-window) autoencoders fail to produce well-parameterized, regular latent embeddings over long temporal sequences; the latent space exhibits folding, pinching, and poor organization:
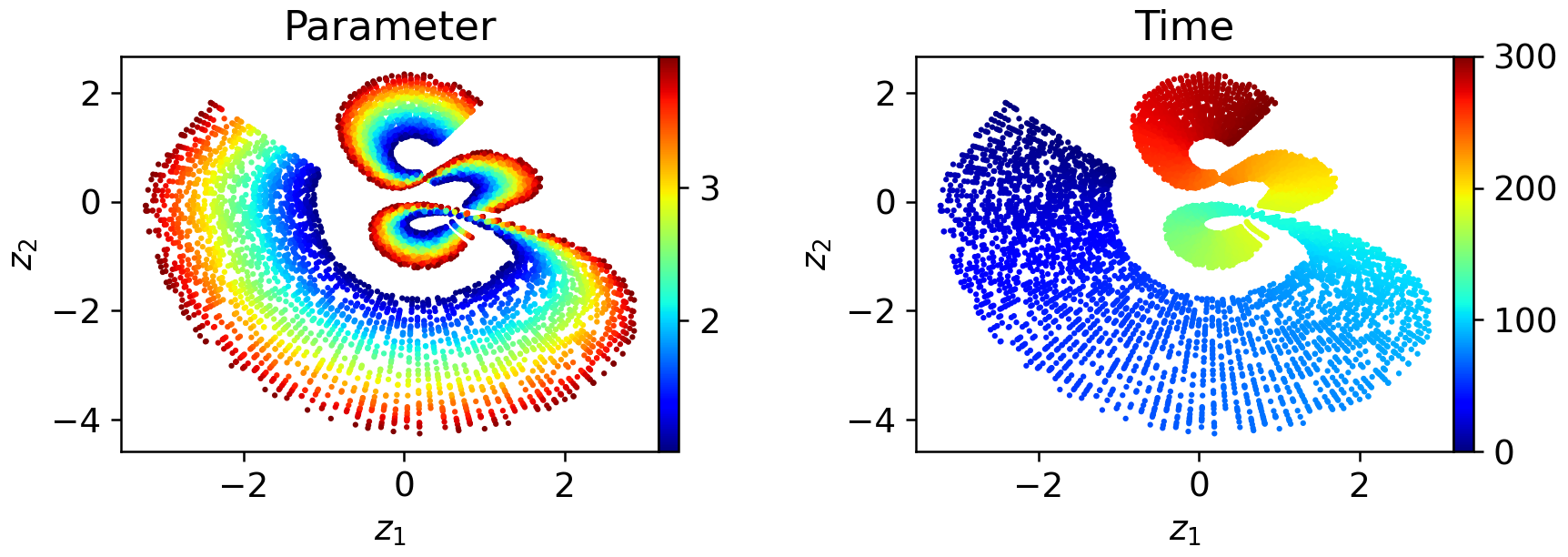
Figure 6: In a one-window model, latent codes exhibit severe geometric distortion as a function of both time and initial condition parameters.
Decomposing the trajectory into two or more windows yields latent representations that are substantially more regularized and locally aligned with intrinsic parameters:
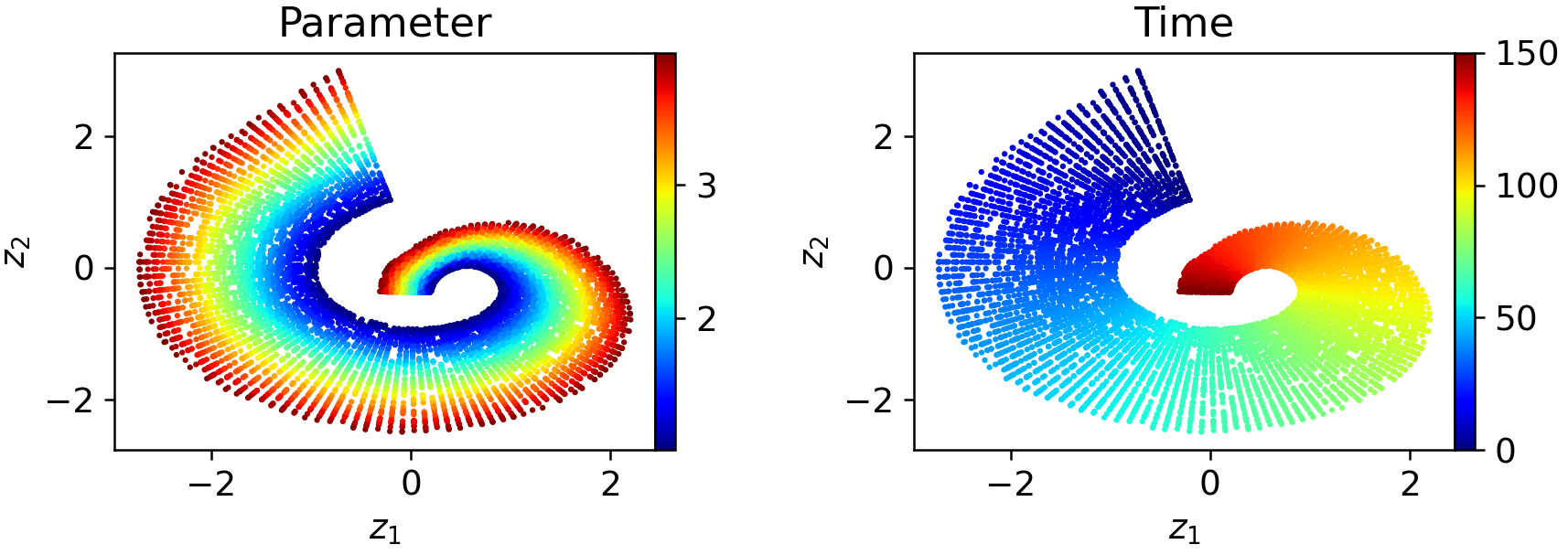
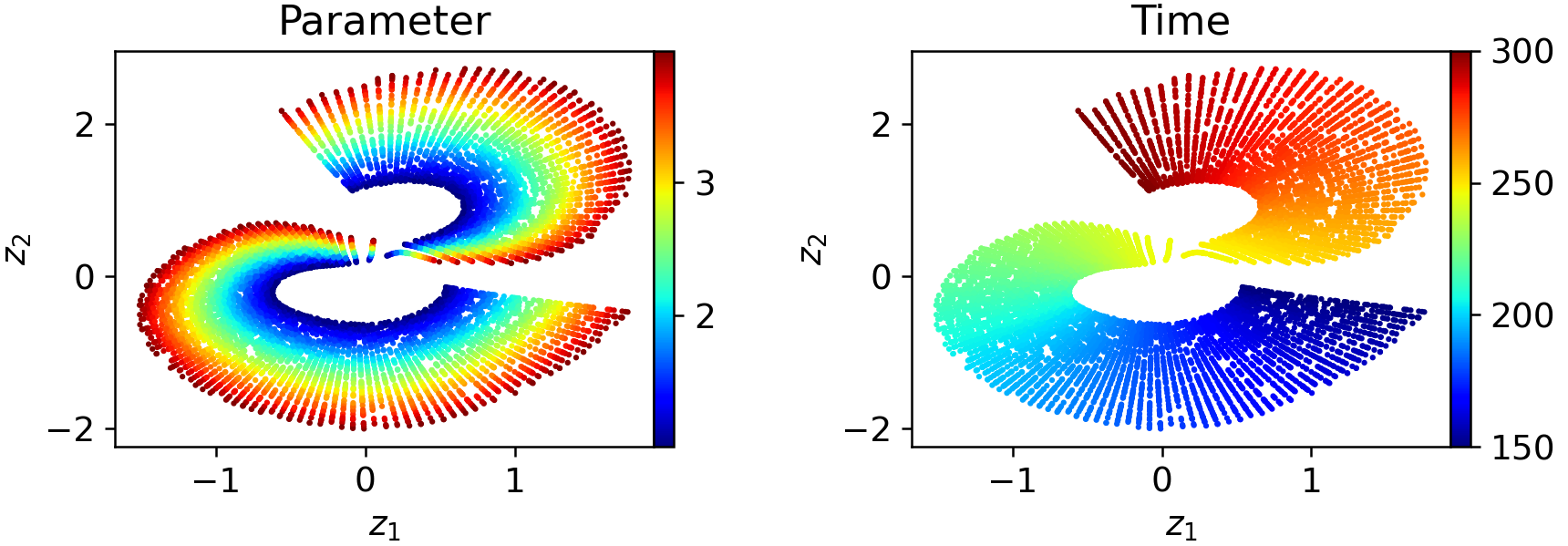
Figure 7: Two-window WeldNet models yield smoother and more uniformly parameterized local latent spaces.
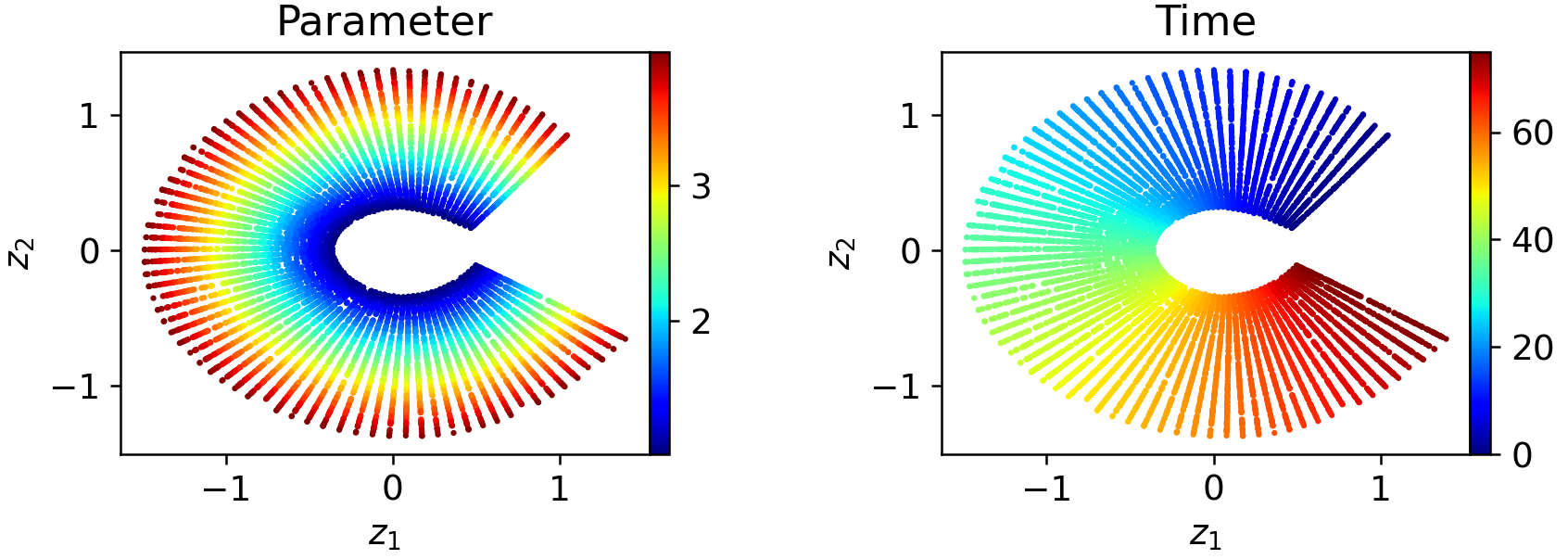
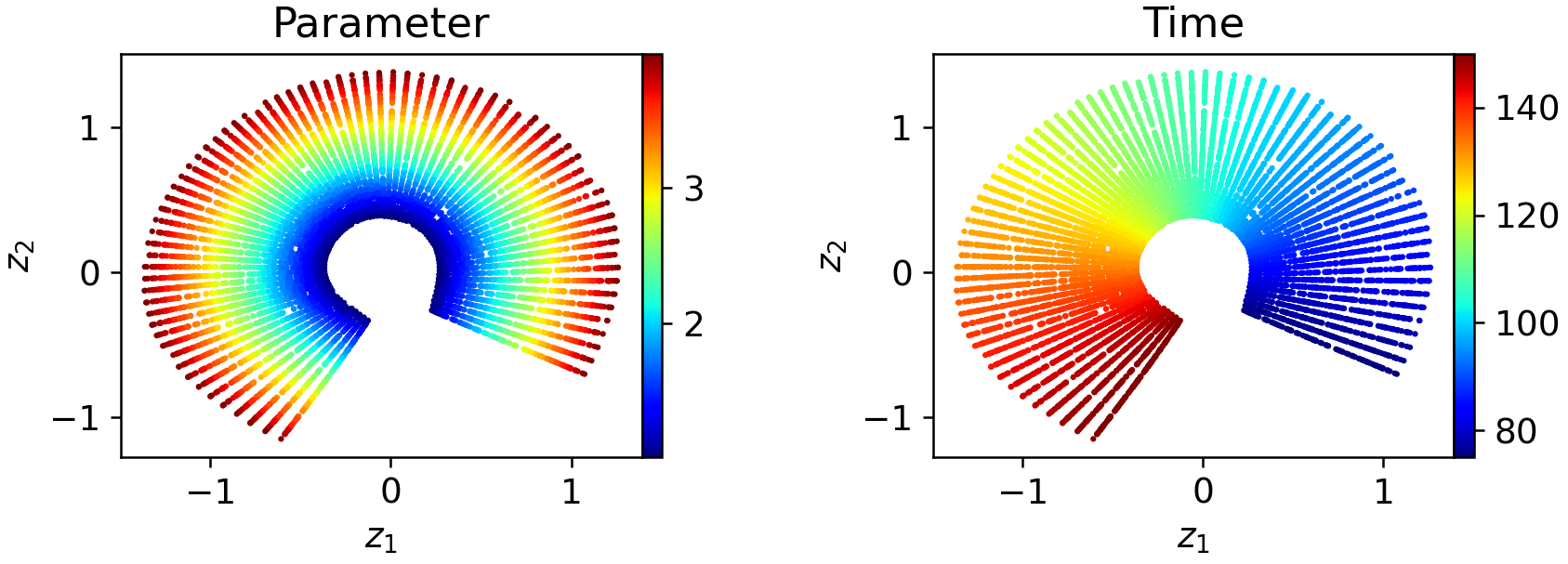
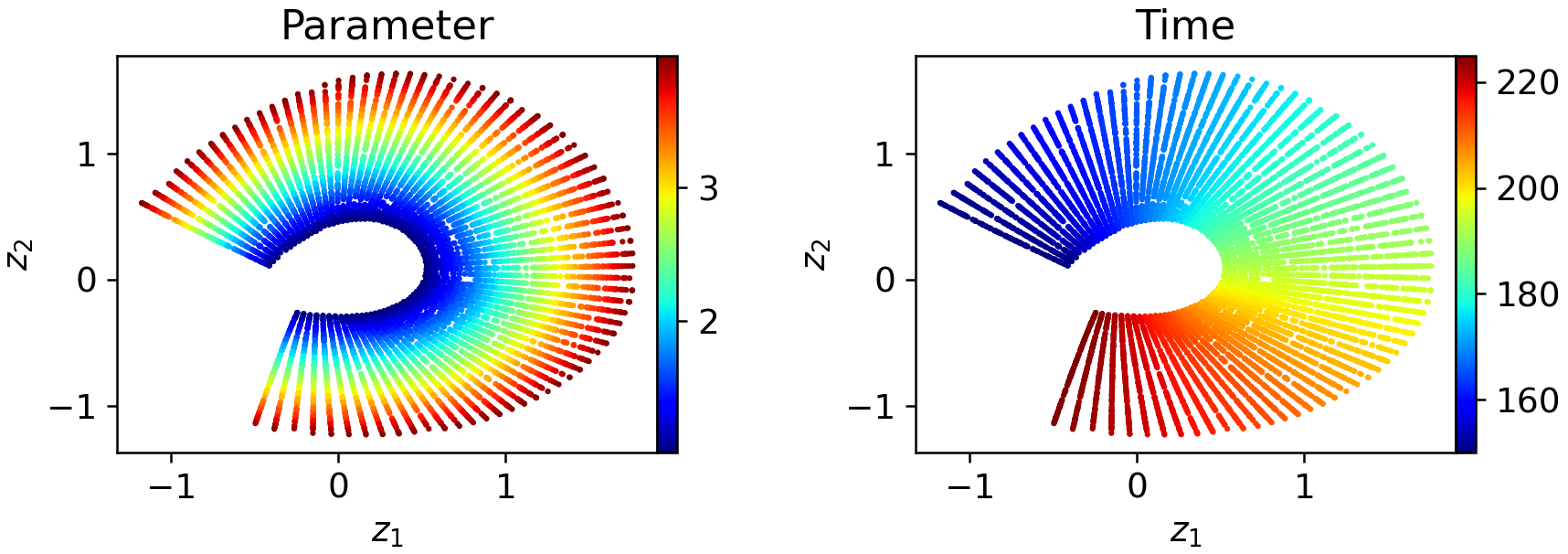
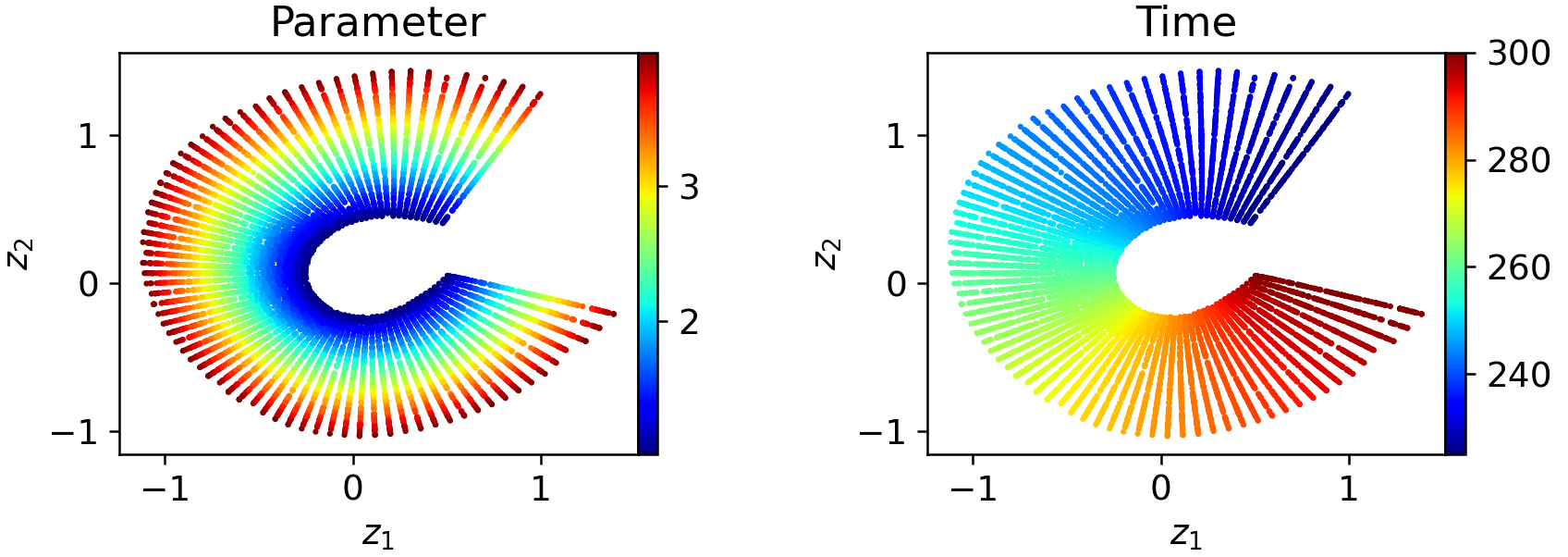
Figure 8: Four-window decompositions further regularize the local latent embeddings, simplifying downstream propagation.
Crucially, windowed models control the growth of operator (prediction) error, preventing the severe error accumulation seen in global models as rollouts progress over time:
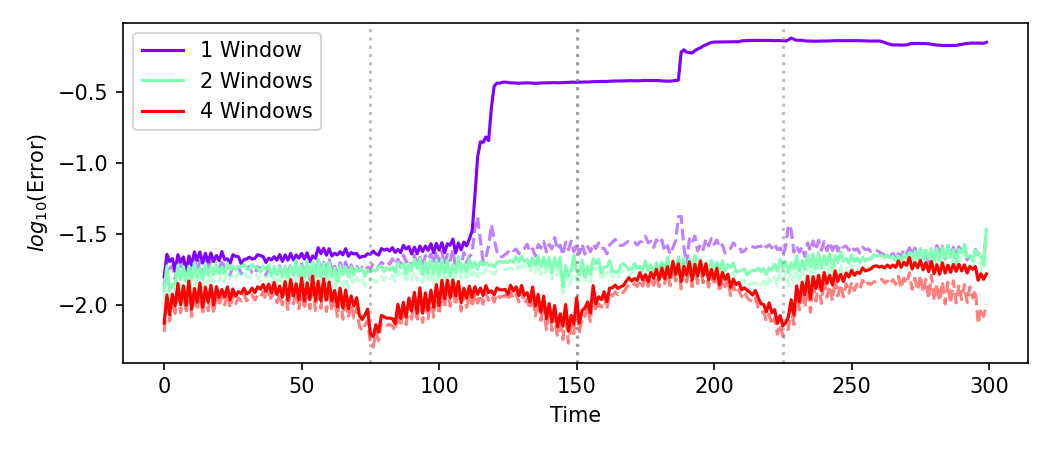
Figure 9: Projection (latent space reconstruction) and operator (multi-step prediction) errors for WeldNet: windowed models (solid) constrain rollout error while global models (dashed) exhibit compounding inaccuracy.
Quantitative Model Reduction Benchmarks
WeldNet was empirically validated on Burgers', transport, Korteweg–de Vries (KdV), and shallow water equations, with initial condition variation inducing parametric families of solution manifolds. The error as a function of initial parameter demonstrates both the representational power and predictive accuracy of WeldNet, particularly in comparison to high-dimensional direct forecasting, classical POD/PCA, and other latent-dynamics models:
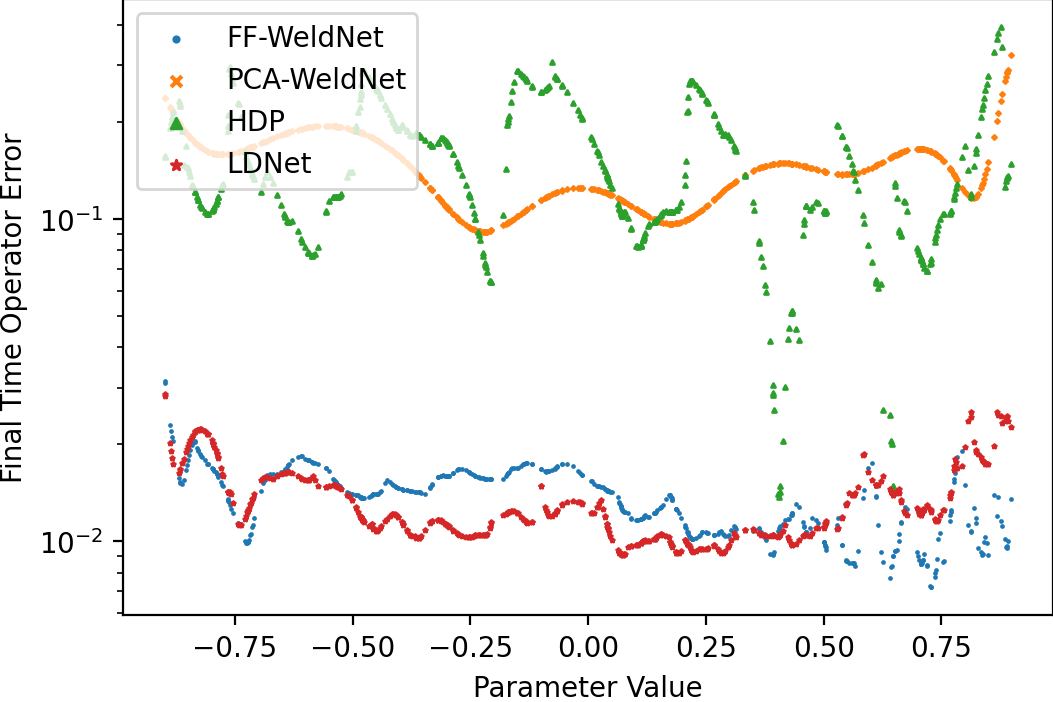
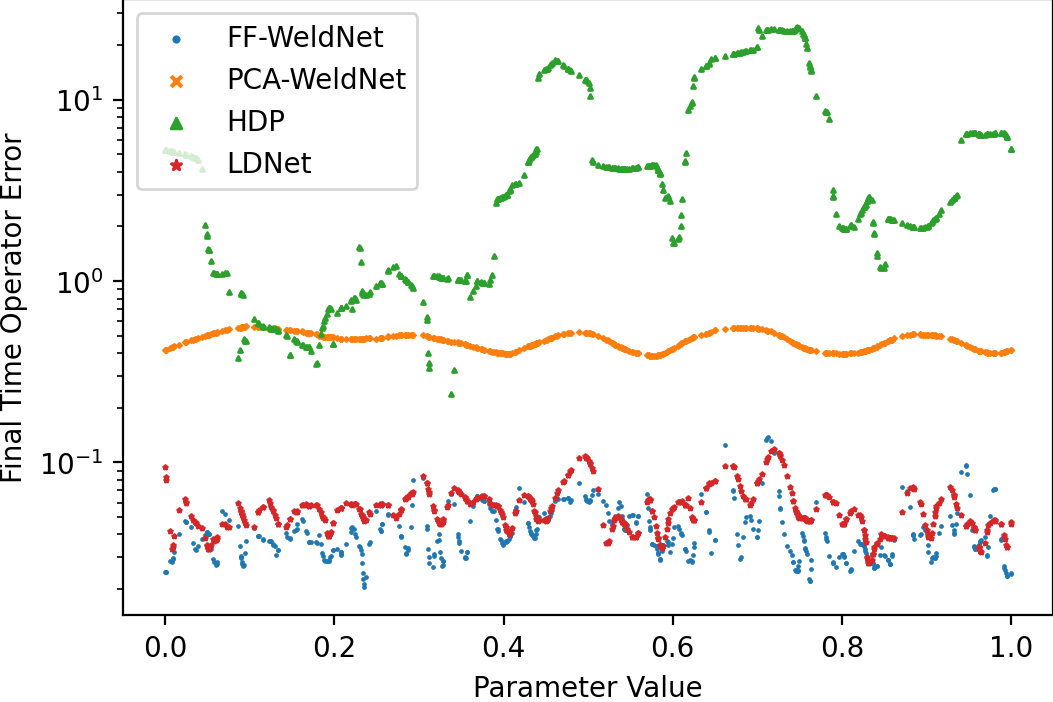
Figure 10: Final-time prediction errors versus parameter for nonlinear Burgers' equation ($\cM_\text{bscale}$): WeldNet achieves the lowest errors across the range.
Latent space and test errors (autoencoder vs. multi-step rollout) further highlight the benefit of nonlinear dimension reduction over linear approaches, and the stability improvement under windowed versus monolithic schemes:
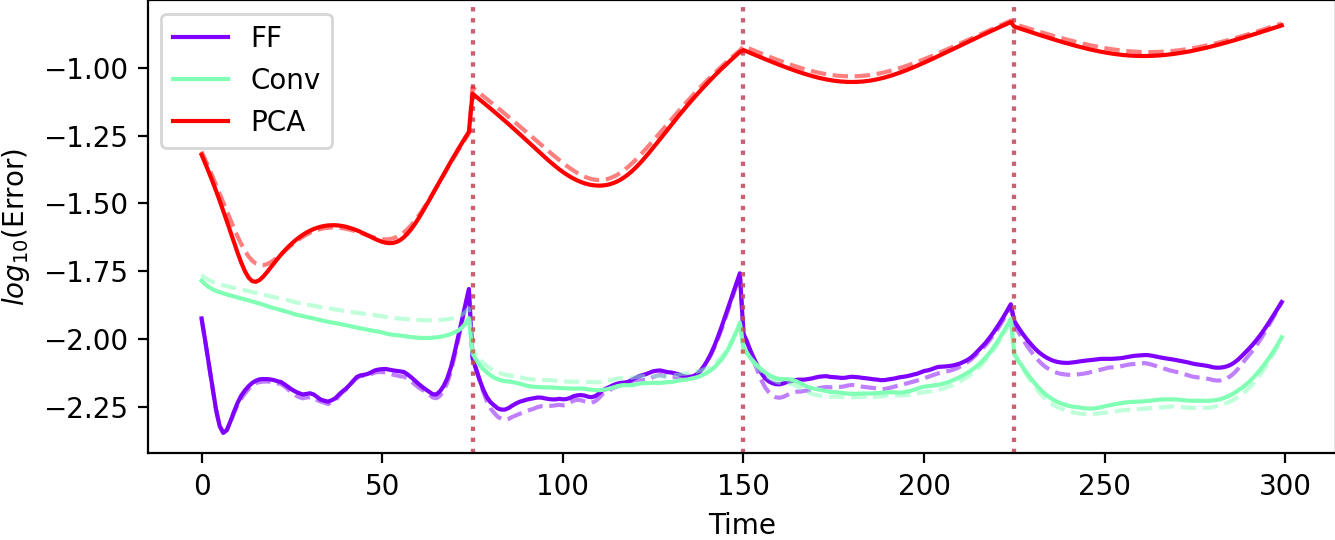
Figure 11: Autoencoder (representation) versus test (prediction) errors for $4$-window WeldNet on Burgers' equation ($\cM_\text{bscale}$): nonlinear approaches dominate linear PCA-based models.
Similar behavior is observed for transport and KdV benchmarks—WeldNet models leverage windowed nonlinear coordination to outpace all comparison methods in both prediction fidelity and error stability over time.
High-Dimensional Application: Shallow Water Equation
After PCA-based preliminary dimension reduction on 2D shallow water equations, WeldNet achieves an order-of-magnitude improvement in trajectory prediction error as compared with traditional approaches, again benefiting from the correction and resetting capabilities due to window transitions. Notably, error does not monotonically accrue over time, due to the local refinement provided by the transcoder modules.
Training Strategy and Ablation
Ablation on the WeldNet training sequence (joint autoencoder-propagator followed by accumulation-based propagator finetuning) shows that this two-stage protocol outperforms joint or fully separated schemes, especially in single- or few-window settings:
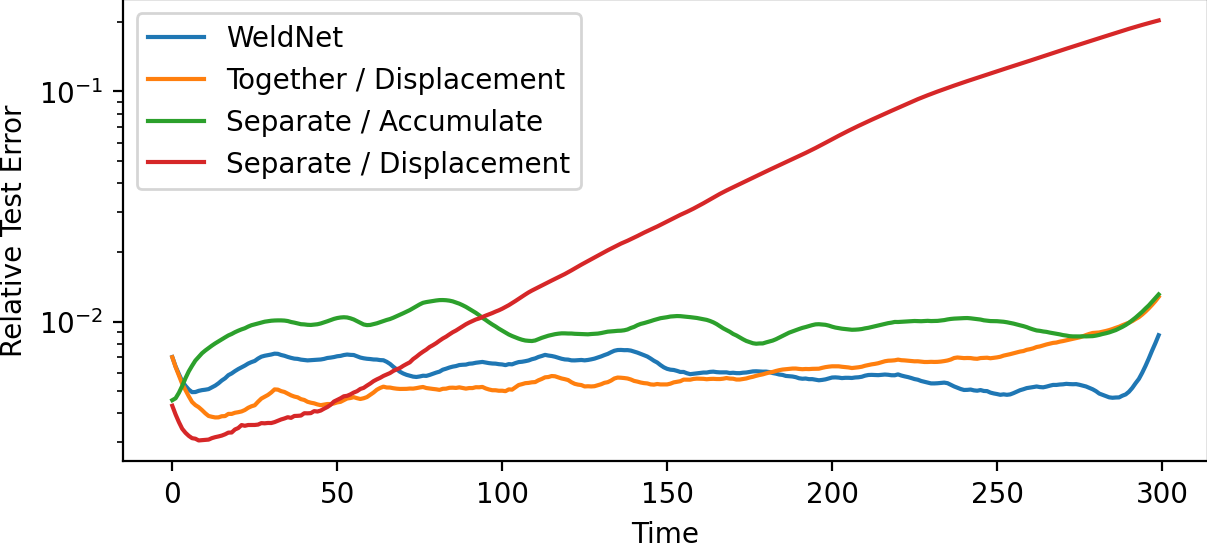
Figure 12: Test error evolution for different WeldNet training strategies (1 window): joint plus accumulation finetuning yields lower error.
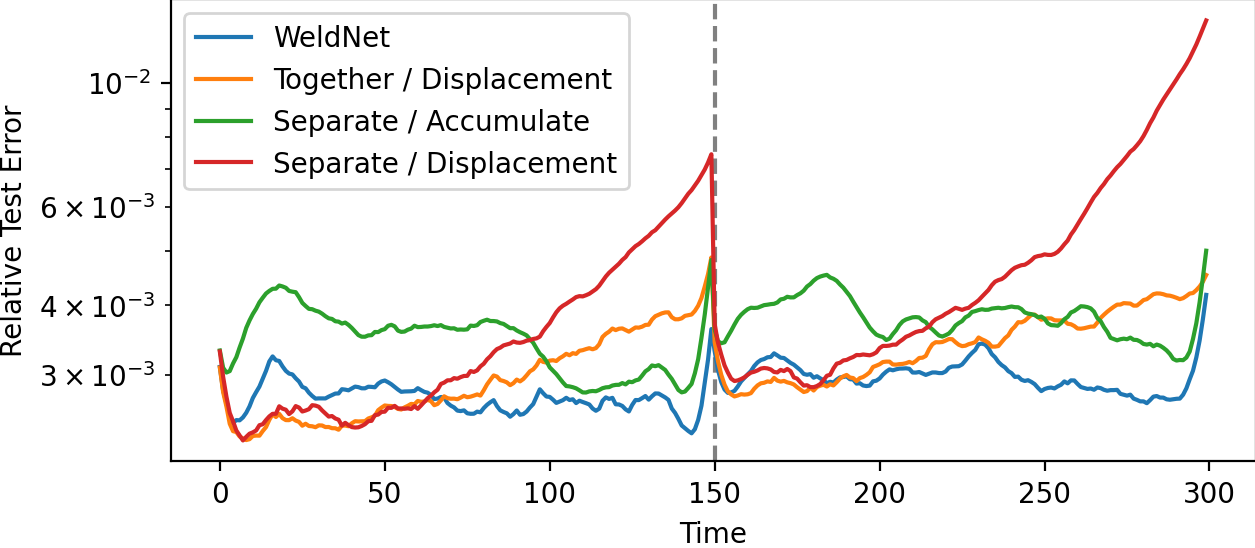
Figure 13: As window count increases to two, the importance of accumulation finetuning remains, but all windowed models significantly limit error growth.
Implications and Future Directions
WeldNet establishes a general template for nonlinear, local, windowed model reduction, providing both the architectural rigor and theoretical justification needed for reliable applications to high-dimensional, nonlinear, and nonstationary dynamical systems. The construction is compatible with parallelization at the training phase—window-specific autoencoders and propagators can be fit independently. Principled windowing mitigates critical training instabilities and allows model scaling to large horizon and high-dimensional scenarios.
The approach is in line with ongoing trends in physics-informed ML, operator learning, and data-driven scientific computing, but introduces a key architectural motif: temporal windowing and latent space patching as a solution to error accumulation in sequential prediction. Further integration with operator-theoretic models (FNO, DeepONet), uncertainty quantification, and hierarchical/multiscale systems is anticipated as logical extensions.
Conclusion
This work presents a windowed deep learning model reduction paradigm for nonlinear, high-dimensional evolutionary systems. By leveraging local latent coordinate charts, temporally localized propagators, and cross-window transcoders, WeldNet achieves consistent accuracy and robustness in the representation and prediction of nonlinear dynamical systems. Theoretical results demonstrate intrinsic-dimension-dependent efficiency, while thorough experimentation across canonical PDEs confirms practical improvements over global and linear baselines. WeldNet's design---windowed latent dynamics with deep autoencoder-based dimension reduction---offers a robust and extendable toolset for future research in scientific ML and model reduction.