Group Diffusion: Enhancing Image Generation by Unlocking Cross-Sample Collaboration
Abstract: In this work, we explore an untapped signal in diffusion model inference. While all previous methods generate images independently at inference, we instead ask if samples can be generated collaboratively. We propose Group Diffusion, unlocking the attention mechanism to be shared across images, rather than limited to just the patches within an image. This enables images to be jointly denoised at inference time, learning both intra and inter-image correspondence. We observe a clear scaling effect - larger group sizes yield stronger cross-sample attention and better generation quality. Furthermore, we introduce a qualitative measure to capture this behavior and show that its strength closely correlates with FID. Built on standard diffusion transformers, our GroupDiff achieves up to 32.2% FID improvement on ImageNet-256x256. Our work reveals cross-sample inference as an effective, previously unexplored mechanism for generative modeling.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making AI-generated images look better by letting images “work together” while they’re being created. Most systems make each image separately, like students doing homework alone. This paper asks: what if we let a small group of images help each other during generation, like a study group? The authors introduce “Group Diffusion,” a way for multiple images to share information during the creation process, which improves the overall quality.
What questions did the paper ask?
- Can images be generated collaboratively instead of independently?
- If images help each other during generation, does quality improve?
- What parts of the generation process benefit most from cross-image collaboration?
- How can we measure this “cross-image helping” in a simple way, and does it relate to real quality scores?
How did they do it? (Methods and key ideas explained simply)
Think of image generation like clearing up a very blurry picture, step by step, until it becomes sharp. That process is called “diffusion.” It starts from random noise and slowly removes the noise to reveal the image.
Group Diffusion changes one important part of how the AI looks at images:
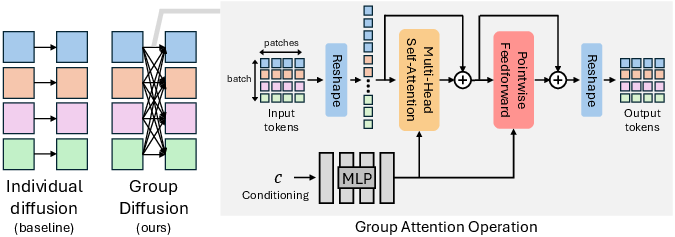
- Attention: AI models use “attention” to decide which parts of an image are most useful right now—like focusing your eyes on the most helpful piece of a puzzle. Normally, attention only looks within a single image.
- Group Diffusion unlocks attention across images: it lets each small piece (“patch”) of an image also look at similar patches in other images being generated at the same time. It’s like each student in a study group can peek at classmates’ notes to fix mistakes in their own work.
How groups are formed:
- During training, the model builds groups of related images (for example, pictures from the same class, like “balloons,” or images that look similar).
- To find related images, they use existing tools that turn images into “embeddings” (short summaries). Then they measure similarity between embeddings. Tools include CLIP and DINO, which are well-known image encoders.
How it works inside the model:
- Images are split into small patches, like cutting a photo into squares.
- The transformer model (a type of AI that uses attention) is modified so the attention looks across all patches from all images in the group, not just within one image.
- A tiny “sample embedding” is added so the model knows which patches belong to which image.
Two flavors of Group Diffusion:
- GroupDiff-f: uses group attention for both “conditional” and “unconditional” parts of the guidance.
- GroupDiff-l: uses group attention mostly for the “unconditional” part. This version is cheaper to train and often gives a great balance of quality and speed.
Key terms (in everyday language):
- Diffusion model: starts from random noise and clears it up step by step to produce an image.
- Attention: the AI’s way of focusing on the most useful parts.
- Patch: a small square of an image.
- Batch/group: several images processed together.
- Classifier-Free Guidance (CFG): a “quality knob” that pushes the AI to follow the intended label or prompt more strongly, often improving quality.
- FID (Frechet Inception Distance): a score that measures how close generated images are to real ones. Lower is better.
What did they find, and why does it matter?
Main results:
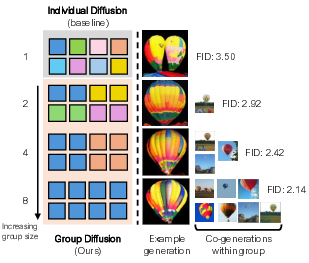
- Images generated with Group Diffusion look better than those made independently. The improvements are consistent across different models.
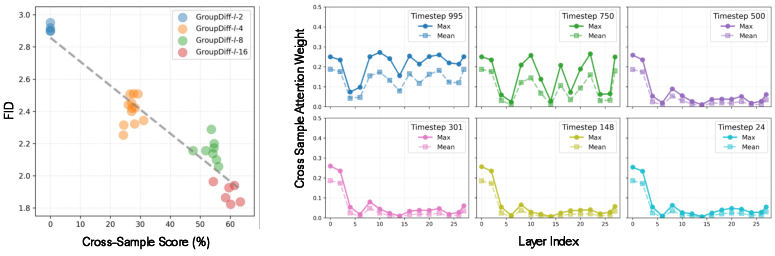
- Bigger groups help more: the more images you generate together, the stronger the cross-image attention becomes, and the quality improves.
- A new way to measure cross-image collaboration: they define a simple “cross-sample attention score” that shows how much one image focuses on the most helpful other image in its group. This score strongly matches real quality improvements (it correlates closely with FID—about 0.95 correlation).
- Early steps matter most: the model uses cross-image help strongly at the beginning, when the image’s overall structure is forming. Later steps benefit less.
- Early layers matter most: the shallow layers in the network (the first ones) make the biggest difference when using cross-image attention.
Numbers (to give a sense of scale):
- On the ImageNet 256×256 benchmark, Group Diffusion improved FID by up to about 32%.
- With popular diffusion transformer models (DiT and SiT), FID dropped from around 2.27 to 1.55 (DiT) and from around 2.06 to 1.40 (SiT) after adding Group Diffusion—big gains.
Why it matters:
- This shows a new, simple way to boost image quality: let images help each other during generation.
- It connects two ideas—generation and representation learning—because sharing attention across images teaches the model stronger, more general features.
Implications and potential impact
- Better image generators: Apps that create multiple images at once (like photo editors or design tools) could produce higher-quality results by letting those images collaborate during creation.
- Faster future models: Since early steps and early layers benefit most, future systems might use group attention only where it matters most to save time and resources.
- More flexible generation: The study shows that if you change one image’s condition (like switching its class), it can significantly change others—especially if they were highly “attended to.” This hints at powerful group editing or coordinated style control in the future.
- A new research direction: Instead of treating each generated sample as isolated, we can design models that use “cross-sample teamwork,” leading to smarter, more reliable generative systems.
In short: Group Diffusion is like turning image generation from solo work into a team effort. By letting images share helpful hints with each other, the AI produces clearer, more realistic pictures—and opens up fresh ways to build smarter generative tools.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper opens a promising direction but leaves several concrete issues unresolved. Future work could address the following:
- Lack of theoretical understanding: no formal analysis explains why and when cross-sample attention improves generation or how it affects optimization dynamics and sample diversity; develop theory or controlled synthetic experiments to isolate mechanisms.
- Generalization beyond ImageNet 256×256: results are limited to class-conditional ImageNet at 256×256; evaluate on text-to-image (e.g., COCO, LAION), unconditional datasets (e.g., LSUN), higher resolutions (512–1024), and domain shifts (art, medical).
- Architecture generality: GroupDiff is only tested with DiT/SiT; assess applicability to UNet-based diffusion (e.g., ADM, SD), hybrid transformers, and video diffusion backbones.
- Inference grouping strategy: training uses retrieval-based groups, but inference uses same-condition batches without retrieval; study retrieval or clustering at inference, group ordering sensitivity, and dynamic grouping policies.
- Group composition sensitivity: no systematic analysis of how group heterogeneity, similarity threshold , and encoder choice affect outcomes; tune/learn , compare hard vs soft assignment, and quantify robustness to noisy group members.
- Diversity vs quality trade-offs: while FID improves, intra-group diversity metrics (e.g., pairwise LPIPS, coverage) are not reported; measure whether larger group sizes reduce diversity or increase sample similarity.
- Compute and memory profiling: training/inference overheads are reported as rough multiples; provide wall-clock, GPU memory, throughput, and energy measurements across group sizes, samplers, and resolutions; optimize attention implementation (e.g., block-sparse, cross-device).
- Sampler and NFE robustness: results largely use iDDPM/SDE with NFE=250; evaluate consistency across samplers (DDIM, Heun), low-NFE regimes, and scheduler choices; quantify how GroupDiff shifts optimal CFG scales.
- Early-steps scheduling: early timesteps/layers dominate gains, but no principled schedule is given; design and validate learned or rule-based schedules for when to enable group attention to minimize cost.
- Layer-wise control: early layers are “essential” and late layers less so; explore attention gating per layer, temperature scaling, or masks to regulate cross-sample influence and reduce compute.
- Cross-sample attention control: the proposed cross-sample score is an analysis tool only; investigate training-time regularizers, constraints, or curricula to target desired attention patterns (e.g., neighbor-focused vs distributed).
- Metric validity: the strong correlation (r≈0.95) between the cross-sample score and FID is shown under limited conditions; validate across seeds, datasets, layers, and samplers; perform partial correlation controlling for group size confounds.
- Conflict resolution in multi-condition groups: brief qualitative tests modify one class per group, but no systematic framework exists for mixed prompts/classes; design mechanisms (e.g., masks, per-sample keys/values, routing) to prevent interference.
- Privacy and content leakage: cross-sample attention may induce copying or leakage across user inputs; measure copy rates and patch-level attribution; add safeguards (e.g., anti-copy regularizers, content filters).
- Retrieval overhead: building and maintaining retrieval indices (CLIP/DINO) at scale is unaddressed; quantify indexing cost, latency, and memory, and compare on-the-fly vs offline retrieval and approximate nearest neighbor options.
- Sample identity encoding: the learnable “sample embedding” is under-specified; ablate its dimension, initialization, sharing strategy, and alternatives (e.g., per-image positional offsets, learnable tokens) and their effects.
- Weight-sharing hypothesis: claims that UC group training improves the conditional model via shared weights are not directly validated; test with decoupled C/UC weights or partial sharing to confirm causality.
- Robustness to adversarial or unrelated group members: random groups degrade FID; study worst-case and adversarial compositions, and develop detection or filtering strategies to reject harmful members.
- Distillation pathway: the paper suggests teacher–student distillation to reduce cost but provides no experiments; implement and compare distillation recipes (feature, attention, or score-matching distillation).
- Fairness across samples: high-attention images may dominate others; measure per-sample quality variance, introduce fairness regularizers to balance attention and prevent overshadowing weaker samples.
- Scaling group size: gains rise with group size, but saturation/instability trends and practical upper bounds are unclear; explore very large groups, hierarchical grouping, and memory-efficient approximations.
- Representation learning benefits: linear-probe gains are reported sparsely; systematically evaluate pretrained features on downstream tasks (segmentation, retrieval, detection) to substantiate representation claims.
- Extension to multi-view/video: cross-sample interactions suggest potential for multi-view and temporal consistency, but no experiments are provided; design cross-frame/group attention for video generation with consistency metrics.
- Interaction with different latent spaces: only SD’s VAE is used; test pixel-space diffusion, alternative VAEs (beta-VAE, HQ-VAE), and tokenizer designs to understand dependencies on latent geometry.
- Reproducibility of cross-sample metrics: detail the exact layers, heads, normalization, and aggregation choices used to compute attention statistics; provide code and protocols for consistent measurement.
Practical Applications
Immediate Applications
Below are actionable, deployable-now use cases that directly leverage the paper’s findings and methods.
- Batch image generation with higher quality and coherence
- Sector: software, advertising/marketing, e-commerce
- Application: Replace independent per-sample inference with GroupDiff-l in batch prompt workflows to boost average quality (lower FID), ensure stylistic consistency, and reduce manual curation.
- Tools/workflow: A batch generator that forms groups via CLIP/DINO retrieval (e.g., group size 4–8), adds per-image sample embeddings, and applies group attention especially in early timesteps/shallow layers to control compute.
- Assumptions/dependencies: Access to attention-enabled DiT/SiT backbones; CLIP/DINO indexes over internal reference libraries; GPU capacity for group sizes; CFG integration.
- Auto-quality control for generative pipelines using attention-based metrics
- Sector: software, content platforms
- Application: Use the cross-sample attention score (neighbor-focused vs. distributed) as a proxy to rank, filter, and select outputs without computing FID online.
- Tools/workflow: Expose attention weights; compute mean/max cross-attention; track score vs. output acceptance thresholds.
- Assumptions/dependencies: Model must expose attention maps; calibration per domain; privacy/security review if attention stats are logged.
- Consistent multi-variant content for product catalogs and campaigns
- Sector: e-commerce, advertising/marketing
- Application: Generate multiple product shots or ad variants in a single batch to maintain background, lighting, and composition coherence via cross-sample attention.
- Tools/workflow: Prompt-level grouping with product category retrieval; early-step group attention; configurable group size.
- Assumptions/dependencies: Availability of per-category reference images; internal copyright-cleared assets.
- Style harmonization across a set of images
- Sector: creative tools, media production
- Application: Align color grading, texture, and stylistic features across multiple outputs by grouping semantically similar references (via q(x)) and enabling cross-sample attention.
- Tools/workflow: “Style bank” retrieval (CLIP/DINO) to form groups; Adobe/Photoshop or Figma plugins that jointly denoise batch candidates.
- Assumptions/dependencies: Reference library curation; retrieval thresholds (e.g., τ≈0.7).
- Faster, cost-aware deployment via early-timestep group attention
- Sector: software infrastructure, cloud
- Application: Apply group attention only during the early denoising steps and shallow layers (as ablated), then switch to single-sample inference to reduce compute while preserving quality.
- Tools/workflow: Scheduler that toggles group attention 0–20% or 0–40% of timesteps; layer-specific attention masks.
- Assumptions/dependencies: Empirical tuning per model and domain; memory profiling; potential small quality trade-offs.
- Dataset augmentation with class-consistent variability
- Sector: academia, ML engineering
- Application: Create synthetic, semantically coherent image sets for training classifiers or segmentation models; cross-sample attention strengthens shared features.
- Tools/workflow: Class-conditional grouping; balanced retrieval; label-preserving augmentation pipelines.
- Assumptions/dependencies: Guardrails against bias and overfitting; domain shift assessment.
- Generation failure diagnosis and prompt refinement
- Sector: software, UX research
- Application: Inspect cross-sample attention maps to diagnose poor generations; adjust retrieval, group size, or CFG scale to steer attention to relevant neighbors.
- Tools/workflow: Attention visualization panel; real-time retrieval threshold tuning; batch re-run with targeted neighbors.
- Assumptions/dependencies: Interpretability access; operator training; logs retention compliant with privacy policies.
- Multi-image narrative and storyboard creation
- Sector: media/entertainment, education
- Application: Produce a set of frames for storyboards or lesson illustrations with consistent characters and environments by batching prompts under shared conditions.
- Tools/workflow: Prompt templates; character reference grouping; early-timestep attention emphasis.
- Assumptions/dependencies: Retrieval of consistent character/environment references; content policy adherence.
- Content moderation steering via reference anchors
- Sector: policy, platform trust & safety
- Application: Include compliance-approved references in the group to subtly steer outputs toward allowed semantics; reduce drift toward disallowed content.
- Tools/workflow: Pre-curated “safe anchor” groups; monitoring of cross-attention toward anchors.
- Assumptions/dependencies: Anchors must be strong enough to attract cross-sample attention; careful evaluation to avoid over-constraint or style lock-in.
- Research instrumentation for representation learning
- Sector: academia
- Application: Study inter-image correspondence and layer/timestep attention dynamics; evaluate correlations between cross-sample attention and downstream performance.
- Tools/workflow: Logging pipelines; datasets with controlled semantic similarity; reproducible ablation setups.
- Assumptions/dependencies: Access to training loop; DiT/SiT integration; compute resources.
- Consumer batch generation for consistent photo sets
- Sector: daily life, creator economy
- Application: Users generate sets of images (e.g., social posts, mood boards) with coherent style by batching prompts; a mobile/cloud app with group-aware inference.
- Tools/workflow: Cloud-based GroupDiff-l; simple sliders for group size and CFG; retrieval from user’s reference album.
- Assumptions/dependencies: Cloud inference (mobile devices often too constrained); user consent for reference indexing.
Long-Term Applications
The following use cases require further research, scaling, or development to reach production maturity.
- Cross-conditioned, any-to-any group generation
- Sector: multimodal software, media production
- Application: Joint generation with mixed conditions (text, layout, sketches, class labels) within the group to orchestrate complex scenes; leverage the observed sensitivity to high-attention neighbors.
- Dependencies/assumptions: New architectures for multi-condition group attention; robust control interfaces; expanded retrieval modalities.
- Multi-view/3D-consistent image sets and video
- Sector: robotics, AR/VR, film production
- Application: Extend group attention to ensure geometric and temporal consistency across views/frames; pair with multi-view adapters or video diffusion.
- Dependencies/assumptions: 3D-aware latent spaces; camera parameter conditioning; evaluation for geometric fidelity.
- Teacher–student distillation for single-image speedups
- Sector: software infrastructure, cloud
- Application: Use a high-quality GroupDiff model as a teacher to distill lighter students that approximate group benefits in single-image inference.
- Dependencies/assumptions: Distillation objectives capturing inter-image correspondences; validation of diversity retention.
- Retrieval-augmented personalization at scale
- Sector: advertising/marketing, design SaaS
- Application: Maintain per-user or per-brand style banks; dynamic retrieval forms groups that infuse brand identity across campaign assets.
- Dependencies/assumptions: Scalable retrieval indices; governance for brand-specific data; privacy and consent.
- Synthetic data pipelines with improved generalization
- Sector: robotics, autonomous driving, healthcare
- Application: Generate class- or domain-consistent sets to pretrain perception models with stronger representations; reduce real-data requirements.
- Dependencies/assumptions: Domain gap analysis; regulatory reviews (especially in healthcare); rigorous validation.
- Attention-driven auto-curation and feedback loops
- Sector: content platforms, AIGC marketplaces
- Application: Use cross-sample attention scores as signals for automatic re-grouping, prompt adjustments, and iterative refinement at platform scale.
- Dependencies/assumptions: Large-scale orchestration; attention telemetry; bias monitoring to prevent homogenization.
- Collaborative multi-agent generative systems
- Sector: distributed AI, federated learning
- Application: Multiple models or clients contribute samples to a shared group and collaboratively denoise; potential for privacy-preserving creativity.
- Dependencies/assumptions: Secure aggregation of attention signals; communication overhead; fairness and contribution governance.
- Energy-aware scheduling and cost optimization
- Sector: cloud, energy
- Application: Operational policies to apply group attention selectively (early steps/layers, adaptive group size) based on real-time energy/cost budgets.
- Dependencies/assumptions: Accurate compute profiling; policy frameworks; SLAs balancing quality vs. latency.
- Compliance-by-design retrieval governance
- Sector: policy, legal/compliance
- Application: Standards and tooling for building retrieval corpora (copyright-cleared, de-biased, privacy-safe) that form groups without legal risk.
- Dependencies/assumptions: Dataset provenance tracking; auditability; policy alignment with jurisdictional requirements.
- Education content engines with consistent pedagogy style
- Sector: education
- Application: Generate large sets of diagrams/examples that share a consistent visual language for textbooks/courses; reduce manual editing.
- Dependencies/assumptions: Curriculum-aligned retrieval; educator-in-the-loop review; accessibility considerations.
- Medical imaging augmentation with clinical coherence
- Sector: healthcare
- Application: Create synthetic cohorts with consistent pathology characteristics for training and benchmarking; group attention maintains clinical semantics.
- Dependencies/assumptions: Expert validation; strict privacy and safety protocols; bias and diagnostic performance audits.
- Integrated productization in creative suites
- Sector: creative tools
- Application: Native support for group denoising in major tools (e.g., batch generation mode in Photoshop/Firefly) with retrieval, attention visualization, and cost-aware scheduling.
- Dependencies/assumptions: Product engineering; UX for retrieval/attention controls; performance across diverse hardware.
Common Assumptions and Dependencies Across Applications
- Architectural support: Access to transformer-based diffusion models (DiT/SiT) that expose attention; ability to reshape tokens across samples and add sample embeddings.
- Retrieval quality: Availability of CLIP/DINO (or similar) embeddings and an indexed, permissioned corpus; careful selection of similarity thresholds (e.g., τ≈0.7) to avoid off-topic neighbors.
- Compute trade-offs: Group size increases compute and memory; GroupDiff-l and early-timestep/shallow-layer attention mitigate costs but require profiling.
- Generalization scope: Most results verified at ImageNet 256×256; performance at higher resolutions or domain-specific data will require validation.
- Diversity vs. coherence: Cross-sample attention can reduce diversity if groups are too homogeneous; balance retrieval breadth and CFG to preserve variation.
- Privacy and copyright: Group formation from proprietary/user content must comply with data policies; audit trails and consent mechanisms are essential.
Glossary
- AdamW optimizer: A variant of Adam that decouples weight decay from the gradient update to improve generalization. "We train the GroupDiff with AdamW optimizer, a constant learning rate of , and weight decay $0.01$ on A100 GPUs."
- Classifier-free diffusion guidance (CFG): A guidance technique that combines conditional and unconditional denoising to trade off sample quality and diversity without an external classifier. "Classifier-free diffusion guidance~\cite{ho2022cfg} enables controlling the trade-off between sample quality and diversity in diffusion models."
- CLIP: A pretrained vision-LLM that provides image-text embeddings useful for measuring semantic similarity. "In practice, we compute the by cosine similarity between image embeddings from pre-trained models like CLIP~\cite{clip} or DINO~\cite{dinov2}."
- Cross-sample attention: Attention computed across different images in a batch so patches can learn from other samples during generation. "Our GroupDiff uses cross-sample attention, enabling samples within a batch to collaborate on a generation."
- Diffusion models: Generative models that iteratively denoise noisy samples to synthesize data from learned distributions. "Diffusion models gradually reverse the process of adding noise to an image, starting from a noise vector and progressively generating less noisy samples with learned denoising function ."
- Diffusion Transformer (DiT): A transformer-based architecture tailored to diffusion models, operating over image patches with attention. "We follow best practices, adopting the Diffusion Transformer (DiT~\cite{peebles2023dit}) model architecture, which uses an attention mechanism between patches within an image."
- DINOv2: A family of self-supervised visual encoders used for robust image representation and similarity. "800K & C = 1, UC = 4 & \cellcolor{red!15} DINOv2-B & 0 & 14.40 & 2.51 & 1.9 & 18.45\% & 63.32 "
- Fréchet Inception Distance (FID): A metric comparing distributions of generated and real images using features from an Inception network. "Built on standard diffusion transformers, our GroupDiff achieves up to FID improvement on ImageNet-256256."
- Group attention: An attention operation applied across concatenated patch tokens from multiple images to enable inter-image interactions. "Group attention can be implemented simply by reshaping the tokens within a batch, before and after the attention operation."
- I-JEPA: A self-supervised learning approach that predicts masked semantic content via joint-embedding predictive objectives. "800K & C = 1, UC = 4 & \cellcolor{red!15} I-JEPA & 0 & 13.08 & 2.44 & 1.8 & 18.50\% & 60.50 "
- iDDPM sampler: A specific sampler for diffusion models used during inference, here paired with a fixed number of function evaluations. "Sampling is performed using the SDE Euler-Maruyama sampler and the iDDPM~\cite{nichol2021iddpm} sampler with when SiT~\cite{ma2024sit} and DiT~\cite{peebles2023dit} are selected as the baseline model, respectively."
- Inception Score (IS): A metric evaluating image generation quality based on the entropy of class predictions from an Inception network. "And we report the FID~\cite{heusel2017fid}, Inception Score~\cite{salimans2016is_score}, Precision and Recall~\cite{kynkaanniemi2019improved_precision_and_recall} for measuring the generation quality."
- Mutual attention: Attention-based mechanisms that explicitly model interactions between multiple images or views. "Furthermore, there is another line of work that goes beyond single-image generation to multi-view generation~\cite{huang2025mv_adapter}, style-controlled group generation~\cite{sohn2023styledrop}, and video generation~\cite{kara2024rave}, by modeling inter-image correspondence with mutual attention."
- Number of Function Evaluations (NFE): The number of denoising steps (function evaluations) used by a diffusion sampler during inference. "Sampling is performed using the SDE Euler-Maruyama sampler and the iDDPM~\cite{nichol2021iddpm} sampler with when SiT~\cite{ma2024sit} and DiT~\cite{peebles2023dit} are selected as the baseline model, respectively."
- Precision and Recall (for generative models): Metrics that assess fidelity (precision) and diversity (recall) of generated samples compared to real data. "And we report the FID~\cite{heusel2017fid}, Inception Score~\cite{salimans2016is_score}, Precision and Recall~\cite{kynkaanniemi2019improved_precision_and_recall} for measuring the generation quality."
- Sample embedding: A learnable vector added to all patches of an image so the model can distinguish different samples in a group. "To ensure that the diffusion model can recognize different image samples, we add the same learnable sample embedding to all patches from a given image."
- SDE Euler-Maruyama sampler: A stochastic differential equation solver used to discretize and simulate the continuous-time diffusion process at inference. "Sampling is performed using the SDE Euler-Maruyama sampler and the iDDPM~\cite{nichol2021iddpm} sampler with when SiT~\cite{ma2024sit} and DiT~\cite{peebles2023dit} are selected as the baseline model, respectively."
- Semantic correspondence: A mapping between semantically related regions across images that supports alignment despite appearance changes. "Semantic correspondence maps semantically related regions across images, enabling alignment despite changes in appearance or pose."
- SigLIP: A vision-LLM that provides image-text representations optimized with a sigmoid-based contrastive loss. "800K & C = 1, UC = 4 & \cellcolor{red!15} SigLIP & 0 & 13.83 & 2.45 & 2.0 & 19.98\% & 63.32 "
- Timestep variation: A constraint controlling the variance of denoising timesteps within a group to stabilize group-wise training. "To obtain the noisy latent, we sample the timestep independently for each sample but ensure that the variance of the timestep within each group is under the threshold of timestep variation ."
- Variational Autoencoder (VAE): A probabilistic encoder-decoder model used to map images into a lower-dimensional latent space for diffusion. "For such image group, we first extract their latent with a pre-trained VAE from Stable Diffusion~\cite{stablediffusion}."
- ViT (Vision Transformer): A transformer architecture for images that treats an image as a sequence of patch tokens. "ViT~\cite{dosovitskiy2020vit} proposed to convert images to a series of smaller patches to adapt the transformer model to the vision field and find its remarkable scaling capabilities under increasing data, training compute, and data."
Collections
Sign up for free to add this paper to one or more collections.