- The paper presents a novel Collaborative Diffusion framework that dynamically integrates pre-trained uni-modal diffusion models for enhanced multi-modal face generation and editing.
- It achieves superior performance with improved FID scores and high user-preference ratings (69.40% for generation, 84.37% for editing) compared to state-of-the-art methods.
- The dynamic diffuser enables nuanced control by adjusting modality contributions spatially and temporally, preserving identity while adhering to text and segmentation conditions.
Collaborative Diffusion for Multi-Modal Face Generation and Editing
Introduction
The paper "Collaborative Diffusion for Multi-Modal Face Generation and Editing" presents a novel framework combining pre-trained uni-modal diffusion models for multi-modal image synthesis tasks. The central challenge addressed is the integration of different modalities—such as text descriptions and segmentation masks—into the generative process, thereby expanding the creative flexibility available to users. This integration is achieved without the need for re-training the pre-trained models, which are traditionally developed for single-modality inputs.
Methodology
The proposed framework, named Collaborative Diffusion, leverages a mechanism termed the dynamic diffuser. This component dynamically predicts spatial-temporal influence functions, which dictate each modality's contribution throughout the iterative denoising steps that characterize diffusion models. Rather than statically aggregating the influence of each modality, the dynamic diffuser adjusts these contributions based on the specific spatial location and diffusion timestep, enhancing or suppressing them as needed.
This approach is built upon existing conditional diffusion models (2304.10530). Each model is conditioned on a specific modality and has been independently trained. During inference, these models synergize through the computed influence functions orchestrated by the dynamic diffuser.
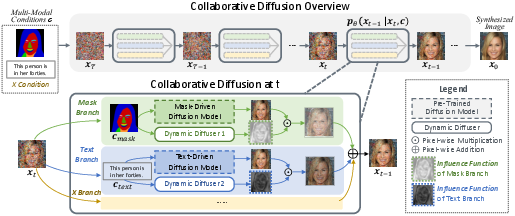
Figure 1: Overview of Collaborative Diffusion. We use pre-trained uni-modal diffusion models to perform multi-modal guided face generation and editing.
Results
Collaborative Diffusion showcases superior performance in both face generation and editing tasks when compared to state-of-the-art methods like TediGAN and Composable Diffusion. Quantitative metrics such as FID (Frechet Inception Distance) show that the proposed method synthesizes images with better quality and higher condition consistency. Particularly, the influence of text-driven models becomes more pronounced during later stages of diffusion when fine details are refined.

Figure 2: Qualitative Comparison of Face Generation. In the second example, TediGAN and Composable fail to follow mask, while ours generates results highly consistent to both conditions.
In face editing, the framework effectively preserves the identity of input images while making meaningful edits based on the given multi-modal conditions. Participants of a user study preferred the results from this framework over others in terms of realism and adherence to specified conditions (69.40% for generation, 84.37% for editing).
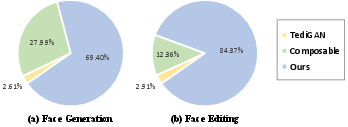
Figure 3: User Study. Among the three methods, the majority of users vote for our results as the best for both generation (69.40\%) and editing (84.37\%), in terms of image quality, condition consistency, and identity preservation.
Technical Contributions
Key contributions include the dynamic diffuser's adaptability and its ability to generalize across different modalities without re-training uni-modal models. The spatial-temporal nature of the influence functions enables nuanced control over the generative process, ensuring consistency in the synthesized outputs relative to the specified conditions.
The framework also demonstrates flexibility in extending single-modal face editing methods to a multi-modal setting. By utilizing the same dynamic diffuser mechanism, various uni-modal editing techniques can be seamlessly integrated, providing robust multi-modal editing capabilities.

Figure 4: Qualitative Comparison of Face Editing. While TediGAN's hair shape is inconsistent with mask, and Composable fails to generate beard according to text, our framework produces results highly consistent with both conditions while maintaining identity.
Conclusion
The research advances the scope of diffusion models by introducing a collaborative mechanism that unlocks multi-modal possibilities in face generation and editing. The work underlines the importance of spatial-temporal adaptivity in model coordination and suggests potential future developments in multi-modal AI applications across other domains such as 3D modeling and motion synthesis. Potential improvements could focus on expanding the dataset diversity to ensure the robustness of generated imagery across different demographics.
Through innovative methodology and comprehensive evaluations, this study positions Collaborative Diffusion as an effective tool for advanced generative tasks, bridging the gap between individual modality frameworks and holistic multi-modal applications.