Bidirectional Normalizing Flow: From Data to Noise and Back
Abstract: Normalizing Flows (NFs) have been established as a principled framework for generative modeling. Standard NFs consist of a forward process and a reverse process: the forward process maps data to noise, while the reverse process generates samples by inverting it. Typical NF forward transformations are constrained by explicit invertibility, ensuring that the reverse process can serve as their exact analytic inverse. Recent developments in TARFlow and its variants have revitalized NF methods by combining Transformers and autoregressive flows, but have also exposed causal decoding as a major bottleneck. In this work, we introduce Bidirectional Normalizing Flow ($\textbf{BiFlow}$), a framework that removes the need for an exact analytic inverse. BiFlow learns a reverse model that approximates the underlying noise-to-data inverse mapping, enabling more flexible loss functions and architectures. Experiments on ImageNet demonstrate that BiFlow, compared to its causal decoding counterpart, improves generation quality while accelerating sampling by up to two orders of magnitude. BiFlow yields state-of-the-art results among NF-based methods and competitive performance among single-evaluation ("1-NFE") methods. Following recent encouraging progress on NFs, we hope our work will draw further attention to this classical paradigm.


















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a way to make computers create realistic images quickly and well. It builds on a family of models called “Normalizing Flows” (NFs), which turn real data (like pictures) into random-looking noise and then back again. The authors introduce a new idea called Bidirectional Normalizing Flow (BiFlow). Unlike traditional NFs that require a perfect, hand-crafted way to reverse the process, BiFlow learns the reverse step with a flexible model. This makes image generation both faster and more accurate.
Goals and Questions
The paper asks three simple questions:
- Can we remove the strict rule that the reverse step must be the exact, built-in inverse of the forward step in normalizing flows?
- If we learn the reverse step with a separate model, can we make image generation much faster?
- Can this learned reverse step also improve image quality compared to the traditional exact inverse?
How They Did It (Methods)
Normalizing Flows in simple terms
Imagine you have a device that takes a clear picture and turns it into “pure noise,” like scrambling it into random dots. The device also has a way to turn noise back into a picture. In traditional NFs:
- The “forward” direction transforms pictures into noise.
- The “reverse” direction must be the exact mathematical inverse of the forward transformation, so you can go back perfectly.
This exactness forces the model to use special, sometimes awkward, designs. It often slows down generation because the reverse step has to go piece-by-piece (like translating a sentence word-by-word in order) instead of all at once.
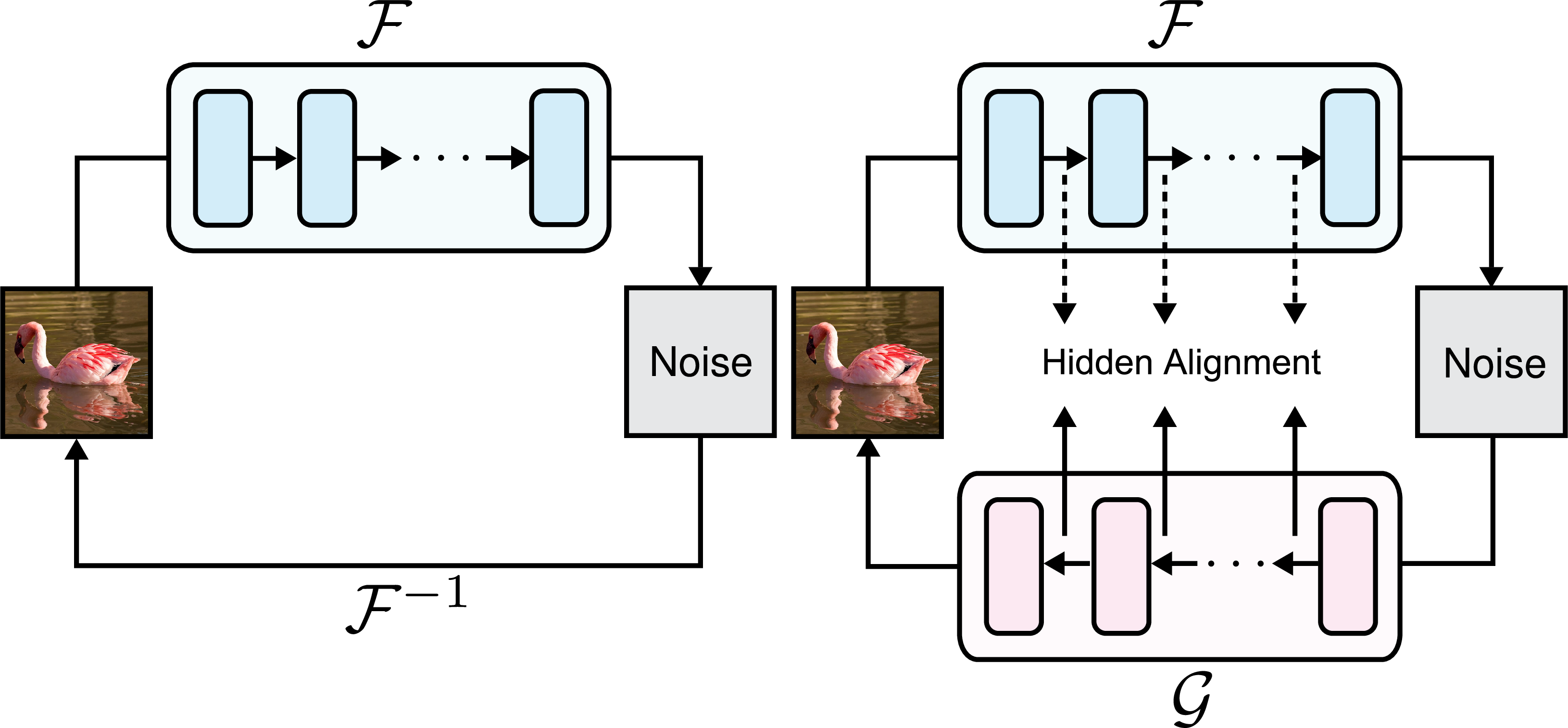
What’s new: BiFlow
BiFlow keeps the forward direction like a standard NF (it still learns how to turn images into noise), but it replaces the strict reverse rule with a learned model. Think of it as training a smart “decoder” that figures out how to turn noise back into a clear image, without being tied to the exact steps of the forward process. This learned decoder can use powerful tools (like Transformers with full attention) and run in a single shot, rather than slowly step-by-step.
Key idea: decouple the two directions.
- Forward model: any normalizing flow that is stable and easy to train.
- Reverse model: a separate, flexible network trained to approximate “noise-to-image” in one go.
How the reverse model is trained (hidden alignment)
Training a reverse model is tricky if you only tell it, “Noise should become a good picture.” The authors found a better way:
- As the forward model turns an image into noise, it passes through several intermediate “hidden states” (like checkpoints on a route).
- The reverse model also produces hidden states while going from noise back to the image.
- Instead of forcing these reverse hidden states to match the image space exactly at every checkpoint (which limits flexibility), the paper uses learnable projection heads to align the reverse model’s hidden states with the forward model’s hidden states. This is called “hidden alignment.”
Analogy: If forward is a trip from home to a destination with checkpoints along the way, hidden alignment teaches the reverse model to follow those checkpoints back home—but it’s allowed to use a different map format, as long as it lines up after a small translation.
Faster and simpler sampling: learned denoising and guidance
- Learned denoising: Some older NF methods add noise during training and then need an extra, expensive “denoising” step at the end. BiFlow merges denoising into the reverse model itself, so the model outputs a clean image in one pass.
- Guidance (CFG): Classifier-free guidance is a common trick to steer the model toward the requested class (like “golden retriever”) for better fidelity. Doing CFG naively doubles the compute. BiFlow trains with guidance scales included, so at test time it still runs in one pass while letting you control the guidance strength.
Where the model runs
The experiments are done in a compressed “latent” space using a VAE (Variational Autoencoder). The VAE acts like a translator that turns images into smaller codes and back. BiFlow operates on these codes, which makes training and generation more efficient.
Main Findings and Why They Matter
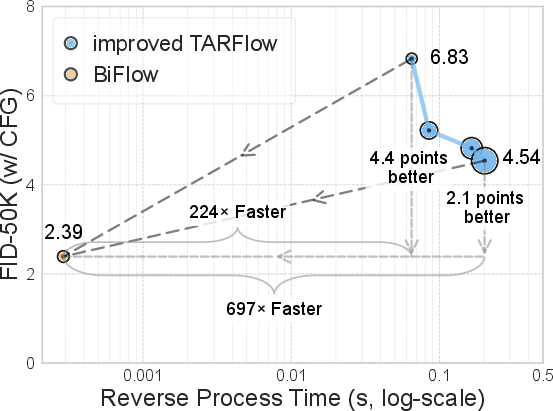
- Quality: On the ImageNet 256×256 benchmark, BiFlow achieves a very strong FID score (about 2.39). FID (Fréchet Inception Distance) measures how close generated images are to real ones; lower is better.
- Speed: BiFlow generates images in a single forward pass (called “1-NFE”). Compared to a strong NF baseline (TARFlow), BiFlow can be up to around 100 times faster in practice, depending on hardware. “Up to two orders of magnitude” means about 100× speedup.
- Flexibility: The learned reverse model can use efficient, fully parallel Transformers instead of slow, step-by-step decoding. It can also use better loss functions, like perceptual loss (which measures how images look to humans), because its outputs are directly available during training.
- Simplicity: BiFlow removes the extra denoising pass used by TARFlow, cutting compute and making the pipeline cleaner.
In short, BiFlow’s learned reverse step not only matches but can beat the exact inverse in image quality, while being much faster.
Implications and Impact
- For researchers and engineers: BiFlow shows that normalizing flows don’t need to be held back by strict invertible architectures. Learning the reverse process opens the door to modern, flexible designs and big speed gains.
- For applications: Faster and high-quality single-pass generation is valuable for real-time or resource-limited scenarios, like on mobile devices or interactive tools.
- For the field: This work bridges ideas between classic NFs and modern diffusion/flow-matching approaches, hinting at new hybrid methods that combine the strengths of both. It revives interest in normalizing flows by proving they can be competitive and practical today.
Overall, BiFlow is a smarter, faster way to go from noise to images, making normalizing flows more useful and competitive with the best image generators.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of concrete gaps that remain unresolved and could guide future research.
- Theoretical guarantees on the learned inverse: no analysis of conditions under which the learned reverse model G is (approximately) bijective, cycle-consistent (F∘G≈id and G∘F≈id), or stable; no bounds on inversion error along the trajectory or at the output.
- Likelihood-consistency between training and sampling: the forward NF F is trained by maximum likelihood, but generation uses G instead of the analytic inverse F⁻¹. It is unclear whether samples from G follow the same distribution implied by F (i.e., whether p_F(x) is consistent with the generative distribution induced by G). No evaluation of log-likelihood or bits-per-dimension on generated samples.
- Distributional coverage and diversity: evaluation focuses on FID/IS; there is no assessment of precision/recall for generative models, density/coverage trade-offs, or diversity metrics, especially under training-time CFG and perceptual losses.
- Hidden alignment design: the choice, capacity, and regularization of projection heads φ_i are not specified or studied. How sensitive is performance to the number and placement of alignment points, weighting across blocks, or alternative objectives (e.g., contrastive alignment, optimal transport, cycle-consistency losses)?
- Learned denoising validity: integrating denoising into G removes score-based refinement, but there is no formal link to score-matching or analysis across varying noise magnitudes σ. How robust is learned denoising when σ changes at test time or when noise statistics differ from training?
- Guidance calibration and generalization: training-time CFG reduces inference cost, yet the behavior under unseen guidance scales, per-block guidance schedules, or mis-specified conditions is untested. The impact on diversity (e.g., class-conditional mode collapse) is not quantified.
- Scaling laws and overfitting: scaling saturates with ConvNeXt-based perceptual loss, with suspected overfitting. There is no deeper analysis of training dynamics, regularization strategies, or data augmentation to mitigate overfitting, nor guidance on model scaling thresholds.
- Dependence on the VAE tokenizer/decoder: results are in VAE latent space (32×32×4); the tokenizer’s reconstruction quality and inductive biases are not studied. How do conclusions change with different tokenizers (e.g., RAE, VQ-VAE, VAE variants) or direct pixel-space training? VAE decoding dominates inference cost but is not optimized.
- Dataset and modality generalization: experiments are limited to class-conditional ImageNet at 256×256. Unconditional settings, higher resolutions (512/1024), other datasets (CIFAR, LSUN, COCO), and other modalities (audio, video, text) remain unexplored.
- Forward-model dependency: BiFlow is demonstrated with iTARFlow as F. How does performance vary with other NF families (e.g., Glow/RealNVP, surjective/coupling flows, CNFs)? What minimal properties of F are required for G to succeed?
- Two-stage training vs. joint training: the forward NF is frozen before training the reverse model. The benefits, risks, and algorithms for joint (co-)training of F and G (e.g., alternating updates, cycle consistency) are not investigated.
- Robustness to teacher quality: the reverse model learns from trajectories produced by F. How resilient is G when F is suboptimal, poorly calibrated, or trained with different noise schemes or conditioning?
- Hyperparameter sensitivity and stability: norm-control details (clip thresholds, normalization schemes), loss weights (MSE vs. perceptual), guidance scales, and block counts are not systematically studied or reported with stability ranges and failure modes.
- Memory and deployment constraints: inference wall-clock times are reported, but memory footprint, VRAM peaks, and edge-device feasibility (e.g., quantization, pruning) are not evaluated.
- Inversion accuracy metrics: reconstruction error G(F(x))→x is mentioned but not comprehensively reported; no trajectory-level or block-wise inversion accuracy analyses on held-out data, nor correlation to sample quality.
- BiFlow’s likelihood utility: while F retains tractable likelihood, the practical value of likelihood-based tasks (e.g., anomaly detection, OOD scoring) using BiFlow is unverified, especially when generation relies on G rather than F⁻¹.
- CFG and perceptual loss interplay: perceptual losses can reduce the need for CFG (optimal w≈0), but the mechanism is not analyzed. How do different feature spaces (VGG, ConvNeXt) affect class-discriminativity, fidelity-diversity trade-offs, and robustness?
- Architectural choices for G: only a ViT-based, bidirectional attention model is tested. The effects of alternative architectures (U-Nets, hybrid CNN/Transformer, cross-attention, multiscale designs) and sequence lengths/patch sizes are not explored.
- Trajectory supervision granularity: the number and depth of supervised intermediate states, and whether early vs. late alignments contribute differently to sample quality and stability, are not characterized.
- Extensibility to continuous-time flows: the suggested synergy with flow matching/CNFs is not empirically validated. How would BiFlow interact with pre-scheduled trajectories, ODE/SDE solvers, or rectified flows under the learned-inverse paradigm?
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage BiFlow’s current capabilities (1-NFE, high-fidelity, fast sampling; requires only a pre-trained forward NF and VAE tokenizer).
- Ultra-low-latency image generation for creative tools
- Sector(s): software, media/entertainment, advertising
- What: Replace slow AR/NF sampling or multi-step diffusion steps with BiFlow’s single-pass generator for instant previews, batch ideation, on-the-fly creative A/B testing, and UI responsiveness.
- Tools/products/workflows: “1-NFE Generator” module in content creation suites; plug-in that distills an existing TARFlow/STARFlow into a BiFlow reverse model; training-time CFG to keep guidance options with 1-NFE at inference.
- Assumptions/dependencies: A pre-trained forward NF (e.g., iTARFlow) and VAE tokenizer; quality shown at 256×256; VAE decoding may bottleneck end-to-end latency.
- On-device image synthesis for AR/VR and mobile apps
- Sector(s): mobile, XR, consumer apps
- What: Single-pass generation fits on-device compute budgets, reducing cloud costs and latency. Enables offline AR effects and low-latency content personalization.
- Tools/products/workflows: Mobile SDK integrating BiFlow reverse model + lightweight VAE decoder; quantization-aware training pipeline.
- Assumptions/dependencies: Efficient VAE (the paper’s VAE is ~49M params and 308 GFLOPs); memory and thermal constraints on mobile SoCs.
- Cost- and energy-efficient inference at scale
- Sector(s): cloud/edge, operations, sustainability
- What: Up to two orders-of-magnitude reduction in wall-clock sampling time (vs. TARFlow) translates to lower inference cost and power draw in production.
- Tools/products/workflows: Cloud inference endpoints using BiFlow reverse models; autoscaling policies for high-throughput batch generation.
- Assumptions/dependencies: Savings depend on replacing slow autoregressive inverse and score-based denoising; VAE overhead can dominate if not optimized.
- Synthetic data generation for vision model training/augmentation
- Sector(s): enterprise AI, e-commerce, robotics (perception), industrial inspection (non-sensitive domains)
- What: Rapidly generate class-conditional images to augment training sets, reduce class imbalance, or stress-test classifiers.
- Tools/products/workflows: Data augmentation pipeline that seeds BiFlow with class labels, uses perceptual-loss-tuned models for realism; automated dataset curation.
- Assumptions/dependencies: Domain shift from ImageNet; retraining BiFlow forward/reverse on target domain improves utility.
- Likelihood-based anomaly/OOD scoring with fast sampling
- Sector(s): industrial inspection, quality control, cybersecurity (vision), research
- What: Use the forward NF for exact likelihoods (for OOD detection) while the BiFlow reverse model provides quick counterfactual/synthetic examples for debugging, data synthesis, or simulation.
- Tools/products/workflows: Dual-head service (NF-forward for scoring, BiFlow-reverse for generation) in inspection lines; incident triage UIs showing synthetic “typical” samples vs. anomalies.
- Assumptions/dependencies: Forward NF must be trained on in-domain data; OOD performance depends on known limitations of likelihood-based detection.
- Distillation toolkit for NF-based generators
- Sector(s): ML platforms, MLOps
- What: Package hidden alignment, learned denoising, norm control, and training-time CFG into a general-purpose “NF-to-1NFE” distillation recipe.
- Tools/products/workflows: Library that takes a trained NF (e.g., TARFlow/STARFlow) and emits a 1-NFE BiFlow reverse model; supports multi-loss (MSE + perceptual), projection heads, and CFG conditioning.
- Assumptions/dependencies: Access to intermediate states during forward passes; sufficient memory/IO to log trajectories.
- Rapid creative generation with guidance but single pass
- Sector(s): media, marketing
- What: Maintain classifier-free guidance (CFG) benefits without doubling NFEs by training with CFG scales as conditions.
- Tools/products/workflows: Guidance-aware 1-NFE APIs; sliders in UI that map to learned guidance scales (within trained range).
- Assumptions/dependencies: Must train over a range of CFG scales; out-of-range scales at inference may degrade results.
- Research benchmarking and teaching
- Sector(s): academia
- What: A strong, open benchmark for 1-NFE NF-based generation, enabling fair comparisons to diffusion/flow matching and AR methods; a teaching example of learning an inverse without explicit invertibility.
- Tools/products/workflows: Course labs implementing hidden alignment; ablation studies on norm control, denoising strategies, and perceptual losses.
- Assumptions/dependencies: Availability of code and checkpoints for reproducibility.
Long-Term Applications
These use cases require further research, scaling to new modalities/resolutions, or product engineering beyond the paper’s scope.
- High-resolution, photorealistic generation (e.g., 1024×1024+) with 1-NFE
- Sector(s): design, media, e-commerce
- What: Extend BiFlow to larger VAEs and higher-res latents for print-quality images, product shots, and catalog generation at low latency.
- Tools/products/workflows: Multi-scale latents, tiled VAEs, or pyramid architectures; progressive distillation across scales.
- Assumptions/dependencies: Empirical scaling behavior indicates diminishing returns with certain perceptual losses; more work needed to stabilize large-scale training and avoid overfitting.
- Cross-modal conditional generation (text-to-image, layout-to-image, image-to-image)
- Sector(s): creative tooling, advertising, education
- What: Replace text-conditioned diffusion with NF-forward + BiFlow-reverse pipelines that accept multimodal conditions (text, layout, style exemplars) in a single pass.
- Tools/products/workflows: Conditioning encoders (e.g., text encoders), multi-token in-context conditioning; guidance-aware conditioning at training time.
- Assumptions/dependencies: Requires pretraining on large paired datasets (e.g., text–image); extending training-time CFG and hidden alignment to multimodal conditions.
- Video, audio, and 3D generation with 1-NFE
- Sector(s): media, gaming, robotics simulation, XR
- What: Adapt BiFlow to spatiotemporal latents (video), waveform/latent audio, and 3D (NeRFs/meshes) for single-pass synthesis.
- Tools/products/workflows: Temporal/3D-aware Transformers in reverse model; trajectory alignment across time/space; efficient VAEs for non-image modalities.
- Assumptions/dependencies: Suitable NF-forward models and tokenizers/VAEs for each modality; memory-efficient training and inference.
- Real-time generative co-pilots embedded in devices
- Sector(s): consumer electronics, automotive, wearables
- What: Always-on visual personalization and content synthesis with tight latency and power budgets (e.g., in-cabin personalization, heads-up displays).
- Tools/products/workflows: Edge inference stacks; hardware-aware distillation and quantization; on-device privacy-preserving customization.
- Assumptions/dependencies: Robustness and safety evaluations; efficient VAE decoders; privacy/consent management.
- Synthetic medical imaging and anomaly simulation (with caution)
- Sector(s): healthcare
- What: Domain-specific retraining to synthesize realistic, label-controlled medical images for data augmentation and simulator-based training; use forward NF likelihoods for anomaly/OOD screening.
- Tools/products/workflows: De-identified datasets, clinical validation pipelines, uncertainty reporting; combined likelihood-thresholding and clinician-in-the-loop review.
- Assumptions/dependencies: Strict regulatory and ethical compliance; domain shifts vs. ImageNet; rigorous bias and safety assessments.
- Financial and sensor time-series modeling via NF + 1-NFE generation
- Sector(s): finance, IoT/industry
- What: Apply the BiFlow idea to tabular/time-series NFs for fast scenario generation, stress testing, and simulation; forward NF for density estimation/anomaly detection, reverse for rapid synthesis.
- Tools/products/workflows: Time-series tokenizers, temporal hidden alignment; CFG-like conditioning on market regimes or device states.
- Assumptions/dependencies: Adapting VAEs/tokenizers and NF-forward designs beyond images; careful evaluation of likelihood reliability on time-series data.
- Privacy-preserving, on-device personalization and fine-tuning
- Sector(s): policy, consumer
- What: Localized refinement of the reverse model (or conditioning adapters) to user preferences, reducing data transfer and improving privacy.
- Tools/products/workflows: Federated or on-device fine-tuning; lightweight adapters for conditions/styles; policy-compliant telemetry.
- Assumptions/dependencies: Mechanisms to prevent memorization/leakage; constraints on compute/storage; user consent frameworks.
- Sustainable AI policy and carbon accounting
- Sector(s): policy, sustainability
- What: Use 1-NFE NF-based generation to cut inference energy, contributing to greener AI deployments; inform procurement and sustainability reporting.
- Tools/products/workflows: Carbon accounting dashboards comparing AR/diffusion vs. BiFlow; procurement guidelines favoring low-NFE models for suitable workloads.
- Assumptions/dependencies: Realized gains depend on replacing multi-step pipelines and optimizing the VAE; end-to-end measurements and verification.
- General-purpose “learned inverse” research agenda
- Sector(s): academia, foundational research
- What: Extend hidden alignment to other invertible or partially-invertible pipelines (e.g., compression, cryptographic transforms for watermarking robustness, scientific simulators).
- Tools/products/workflows: Projection-headed alignment modules; norm control as a standard stabilization; benchmark suites contrasting explicit vs. learned inverses.
- Assumptions/dependencies: Availability of forward trajectories and meaningful hidden states; domain-specific distance metrics and supervision signals.
Glossary
- 1-NFE (single function evaluation): A setting where generation requires only one forward pass through the model; enables fast sampling. "naturally enabling high-quality, single function evaluation (1-NFE) generation."
- Affine coupling: A flow-layer design that enables tractable, invertible transformations by coupling subsets of variables with affine mappings. "This requirement motivates specialized designs such as affine coupling \cite{nice,realnvp} and autoregressive flows \cite{arflow,maf}, which preserve tractable Jacobians."
- Autoregressive flows (AF): Flow models that transform variables one at a time conditioned on previously transformed variables, ensuring triangular Jacobians and tractable likelihoods. "TARFlow~\cite{tarflow} integrates Transformer architectures into autoregressive flows (AF), substantially improving their expressiveness and scalability."
- Bidirectional attention Transformer: A Transformer that uses non-causal (bidirectional) attention, enabling parallel inference across tokens. "Our bidirectional attention Transformer design allows for fully parallelized computation across the sequence dimension, which leads to significant speedups on modern accelerators."
- Bidirectional Normalizing Flow (BiFlow): A framework that learns both forward (data-to-noise) and reverse (noise-to-data) processes without requiring an explicit analytic inverse. "In this work, we introduce Bidirectional Normalizing Flow (BiFlow), a framework that removes the need for an exact analytic inverse."
- Bijective transformation: A one-to-one and onto mapping ensuring invertibility between distributions in flow models. "Normalizing Flows (NFs) are a class of generative models that establish a bijective transformation between a Gaussian prior distribution and a complex data distribution $p_{\text{data}$."
- Change-of-variables formula: The formula used to compute data likelihood under an invertible transformation via Jacobian determinants. "The model assigns the data likelihood through the change-of-variables formula."
- Class-conditional generation: Generative modeling conditioned on class labels to control output categories. "Our experiments are conducted on class-conditional ImageNet~\cite{imagenet} generation at 256256 resolution."
- Classifier-free guidance (CFG): A technique to trade off fidelity and diversity by mixing conditional and unconditional predictions during sampling. "Classifier-free guidance (CFG)~\cite{cfg} was originally proposed for diffusion models to control the trade-off between sample diversity and fidelity."
- CFG interval: A strategy to vary guidance strength across layers/blocks during sampling. "The subscript indicates that can differ among blocks, supporting CFG interval~\cite{interval}."
- Continuous Normalizing Flows (CNFs): Flow models defined by continuous-time dynamics governed by ODEs, enabling flexible architectures with tractable likelihoods. "Continuous Normalizing Flows (CNFs)~\cite{ffjord,rnode,steer} generalize discrete flows by modeling transformations as continuous-time dynamics governed by ordinary differential equations (ODEs) \cite{neuralode}."
- ConvNeXt V2: A modern convolutional network whose features can be used for perceptual loss to improve realism. "we adopt both VGG~\cite{vgg} and ConvNeXt V2~\cite{convnextv2} feature spaces for perceptual loss"
- Denoising (score-based denoising): A refinement step that removes noise from generated outputs using gradients of log-density (scores). "then performs an additional score-based denoising step:"
- DiT (Diffusion Transformer): A Vision-Transformer-based diffusion backbone often used in modern generative models. "BiFlow achieves an FID of 2.39 using a DiT-B size~\cite{dit} model"
- Flow Matching (FM): A training paradigm for continuous-time flows and diffusion that matches vector fields instead of maximizing explicit likelihood. "FM \cite{fm,recitifiedflow,sd3} reformulates the explicit maximum-likelihood training objective into an equivalent implicit objective."
- Flow trajectories: The paths taken by samples when transformed from data to noise (and back), learned by NFs. "A notable property of NFs is that the underlying flow trajectories from data to noise are learned rather than imposed."
- Forward-backward pass: A computation involving both forward and gradient backpropagation used to evaluate score terms or losses. "This post-processing almost doubles the inference cost, becoming a clear computational bottleneck for efficient generation."
- Gaussian prior distribution: The simple reference distribution (usually standard Normal) to which data is mapped in flow models. "establish a bijective transformation between a Gaussian prior distribution "
- Glow: A convolutional flow architecture with invertible 1x1 convolutions and non-volume-preserving transforms. "Real NVP~\cite{realnvp} and Glow~\cite{glow} extended this framework with non-volume-preserving transformations and convolutional architectures."
- Guidance scale: The scalar weight in CFG controlling the balance between conditional and unconditional predictions. "where is the class condition and is the guidance scale"
- Hidden alignment: A training strategy that aligns reverse-model hidden states to forward-model states via learnable projections, avoiding repeated projections to input space. "Our hidden alignment strategy (\cref{fig:hidden_align}) combines the strengths of \cref{fig:naive_distill} and \cref{fig:hidden_distill}, leveraging the entire trajectory for supervision without repeatedly returning to input space."
- Hidden distillation: A supervision method that matches reverse intermediate states directly to forward states in input space at each block. "Hidden distillation supervises the reverse model using the entire forward trajectory."
- IAF (Inverse Autoregressive Flow): An autoregressive flow variant enabling tractable likelihoods with high expressivity. "IAF~\cite{arflow} and MAF~\cite{maf} introduced autoregressive flows to improve expressivity while maintaining tractable likelihoods."
- In-context conditioning: Conditioning strategy that injects conditioning tokens or signals directly into Transformer context rather than additive biases. "we replace additive conditioning with in-context conditioning~\cite{dit}"
- Inception Score (IS): A metric evaluating generative image quality and diversity using a classifier’s predictions. "Frechet Inception Distance (FID)~\cite{fid} and Inception Score (IS)~\cite{improvedgan} on 50000 generated images."
- Jacobian determinant: The determinant of the Jacobian matrix of a transformation; its log contributes to likelihood under change of variables. "its Jacobian determinant must be computable, tractable, and differentiable."
- Log-likelihood: The logarithm of data likelihood under a model; maximized in flow training. "Training is performed by optimizing $#1 F$ to maximize the log-likelihood over data samples."
- LPIPS (Learned Perceptual Image Patch Similarity): A perceptual metric based on deep features used to align generated and target images. "our implementation for VGG features follows LPIPS~\cite{lpips}"
- MAF (Masked Autoregressive Flow): An autoregressive flow that yields tractable likelihoods via masked networks. "IAF~\cite{arflow} and MAF~\cite{maf} introduced autoregressive flows to improve expressivity while maintaining tractable likelihoods."
- Maximum likelihood estimation (MLE): Training principle that fits model parameters by maximizing the likelihood of observed data. "first, similar to classical NF, we train the forward model using maximum likelihood estimation"
- Mean squared error (MSE): A pixel/feature-wise distance metric commonly used for reconstruction loss. "Our default choice for the distance metric in \cref{eq:hidden_align_loss} is simply mean squared error (MSE)."
- NICE (Non-linear Independent Components Estimation): A foundational normalizing flow with volume-preserving coupling layers. "Planar flows~\cite{nf} and NICE~\cite{nice} pioneered the use of simple reversible mappings to construct deep generative models."
- Non-volume-preserving transformations: Flow layers that intentionally alter volume (Jacobian determinant ≠ 1) to increase expressivity. "Real NVP~\cite{realnvp} and Glow~\cite{glow} extended this framework with non-volume-preserving transformations and convolutional architectures."
- Norm control: Techniques to stabilize intermediate state magnitudes to balance supervision across blocks. "To mitigate this issue, we introduce two complementary norm-control strategies applied to the forward and reverse models to ensure stable and consistent supervision strength"
- Naive distillation: A simple training approach that minimizes reconstruction error between reverse output and original data. "A straightforward strategy is to impose a direct distillation loss:"
- Ordinary differential equations (ODEs): Continuous-time equations governing CNF dynamics and enabling likelihood computation via ODE solvers. "continuous-time dynamics governed by ordinary differential equations (ODEs) \cite{neuralode}"
- Planar flows: Simple flow layers that add a scalar nonlinearity composed with affine transformations to achieve invertibility. "Planar flows~\cite{nf} and NICE~\cite{nice} pioneered the use of simple reversible mappings to construct deep generative models."
- Projection heads: Learnable mapping modules used to align hidden representations across models or stages. "we introduce a set of learnable projection heads "
- Real NVP: A popular flow architecture using affine coupling with tractable Jacobians and non-volume-preserving transforms. "Real NVP~\cite{realnvp} and Glow~\cite{glow} extended this framework with non-volume-preserving transformations and convolutional architectures."
- Score function: The gradient of log-density with respect to inputs, used for denoising and likelihood-related objectives. "eliminates the need for calculating the score function through a whole forward-backward pass"
- STARFlow: An extension of TARFlow that further scales autoregressive flows with Transformers. "TARFlow~\cite{tarflow} and STARFlow~\cite{starflow} further revitalized the NF family by incorporating Transformer into autoregressive flows."
- TARFlow: A Transformer-based autoregressive normalizing flow that achieves strong likelihoods but requires sequential sampling. "Recently, the gap between NFs and other generative models has been largely closed by TARFlow~\cite{tarflow} and its extensions~\cite{starflow}."
- Transformer with causal masks: A Transformer that restricts attention to past tokens to implement autoregressive conditioning. "which can naturally be realized through Transformer layers with causal masks."
- U-Net: An encoder–decoder convolutional architecture widely used in diffusion and generative models. "in their ability to use powerful, general-purpose architectures (e.g, U-Nets~\cite{unet} or Vision Transformers~\cite{vit})"
- Variational Autoencoder (VAE): A latent-variable generative model whose encoder/decoder can serve as a tokenizer/decoder for image latents. "Following~\cite{ldm,sd3,starflow}, we implement our models on the latent space of a pre-trained VAE tokenizer."
- VGG: A convolutional network whose feature activations are used for perceptual similarity metrics. "we adopt both VGG~\cite{vgg} and ConvNeXt V2~\cite{convnextv2} feature spaces for perceptual loss"
- Vision Transformer (ViT): A Transformer architecture for images that operates on patch tokens. "Our reverse model adopts a ViT backbone with modern Transformer components~\cite{rope,rmsnorm}"
- VAE decoder: The generative half of a VAE that maps latents back to pixel space and incurs inference cost. "VAE decoding is omitted from this figure; comprehensive inference cost comparison appears in \cref{tab:biflow_vs_itarflow}."
- Causal decoding: Sequential token-by-token generation enforced by autoregressive dependencies, limiting parallelism. "Recent developments in TARFlow and its variants have revitalized NF methods by combining Transformers and autoregressive flows, but have also exposed causal decoding as a major bottleneck."
Collections
Sign up for free to add this paper to one or more collections.