AlcheMinT: Fine-grained Temporal Control for Multi-Reference Consistent Video Generation
Abstract: Recent advances in subject-driven video generation with large diffusion models have enabled personalized content synthesis conditioned on user-provided subjects. However, existing methods lack fine-grained temporal control over subject appearance and disappearance, which are essential for applications such as compositional video synthesis, storyboarding, and controllable animation. We propose AlcheMinT, a unified framework that introduces explicit timestamps conditioning for subject-driven video generation. Our approach introduces a novel positional encoding mechanism that unlocks the encoding of temporal intervals, associated in our case with subject identities, while seamlessly integrating with the pretrained video generation model positional embeddings. Additionally, we incorporate subject-descriptive text tokens to strengthen binding between visual identity and video captions, mitigating ambiguity during generation. Through token-wise concatenation, AlcheMinT avoids any additional cross-attention modules and incurs negligible parameter overhead. We establish a benchmark evaluating multiple subject identity preservation, video fidelity, and temporal adherence. Experimental results demonstrate that AlcheMinT achieves visual quality matching state-of-the-art video personalization methods, while, for the first time, enabling precise temporal control over multi-subject generation within videos. Project page is at https://snap-research.github.io/Video-AlcheMinT




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces AlcheMinT, a tool that can make short videos where specific people or objects (called “subjects”) appear and disappear exactly when you want them to. Imagine you’re a director: you can say “the dog should enter at 3 seconds and leave at 6 seconds, and the skateboarder should show up from 5 to 8 seconds.” AlcheMinT follows those instructions while keeping the look of each subject consistent across the video.
What questions does the paper try to answer?
The researchers focus on three simple questions:
- How can we make a video generator place different subjects at exact times instead of showing them the whole way through?
- How can we keep each subject’s identity (their face, color, shape, style) consistent, even with multiple subjects?
- How can we measure whether the generated video truly follows the timing and looks good?
How does AlcheMinT work?
Think of a video generator like a very smart painting robot that turns text and images into moving scenes. AlcheMinT gives this robot two kinds of instructions:
- What to show (reference images and text labels like “dog,” “woman,” or “logo”), and
- When to show each subject (start and end times).
Here’s the approach in everyday terms:
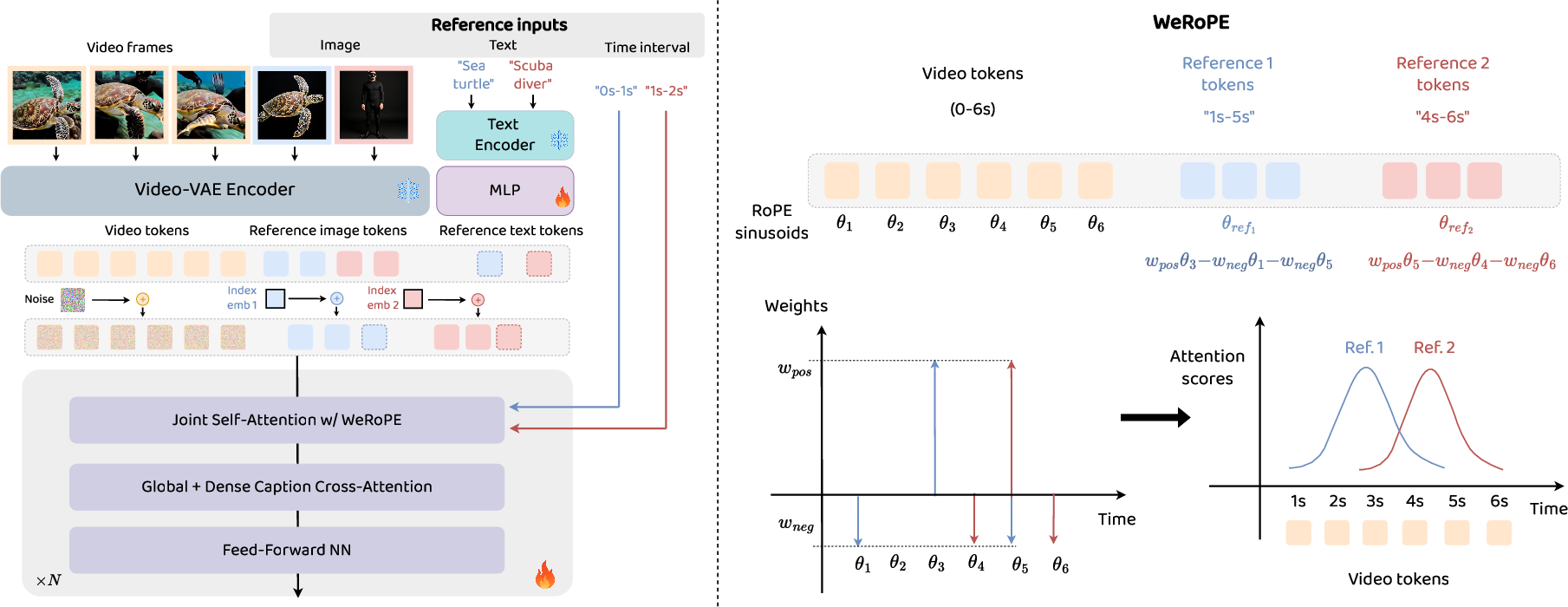
- Turning pictures and video into tokens: The model first compresses both the video and the reference images into small building blocks called “tokens” (like LEGO pieces with special markings). It uses the same compressor (called a VAE) for both, so the pieces fit together naturally.
- Joining everything together: Instead of adding complicated extra modules, AlcheMinT simply lines up the reference tokens and the video tokens into one long sequence (like putting all LEGO pieces on one track). This makes the model process them together, which helps preserve subject identity and keeps things simple and efficient.
- Teaching the model about time: The model uses “positional hints” to understand where each token belongs in space and time. AlcheMinT tweaks these hints for the reference tokens with a technique called Weighted RoPE. Here’s a friendly analogy:
- Picture a spotlight that shines brightest on the stage during the time a subject should be present. Inside that time window, the model pays strong attention to the subject’s reference image. Outside the window, the attention fades smoothly, so the subject naturally enters and exits without sudden jumps.
- Weighted RoPE builds this “spotlight” using three anchors: the middle of the time interval and both edges. By mixing these anchors with positive and negative weights, it forms a clear “on-stage” zone and gentle “off-stage” transitions.
- Labeling subjects with words: If your caption mentions “a man” and “a doctor,” the model needs to know which image goes with which word. AlcheMinT adds tiny tag tokens for each subject (like name badges) and teaches the model to bind the tag, the caption, and the reference image together. This reduces confusion when multiple subjects are similar.
- Building a training dataset with timestamps: The team created a pipeline to get real videos where multiple subjects are tracked over time. They:
- Extracted subject words from captions using an AI LLM.
- Detected subjects in frames using a detector (Grounding DINO).
- Tracked the subjects through the video with a segmenter (SAM2).
- From these tracks, they recorded when each subject appears, producing accurate timestamp labels.
- This data lets the model learn how to place subjects at the right times and keep their look consistent.
What did they find?
The team built a new benchmark called S2VTime to check four things:
- Does the subject look like the reference image?
- Does the video match the text description?
- Is the video visually smooth and high quality?
- Do subjects appear and disappear at the requested times?
The results show:
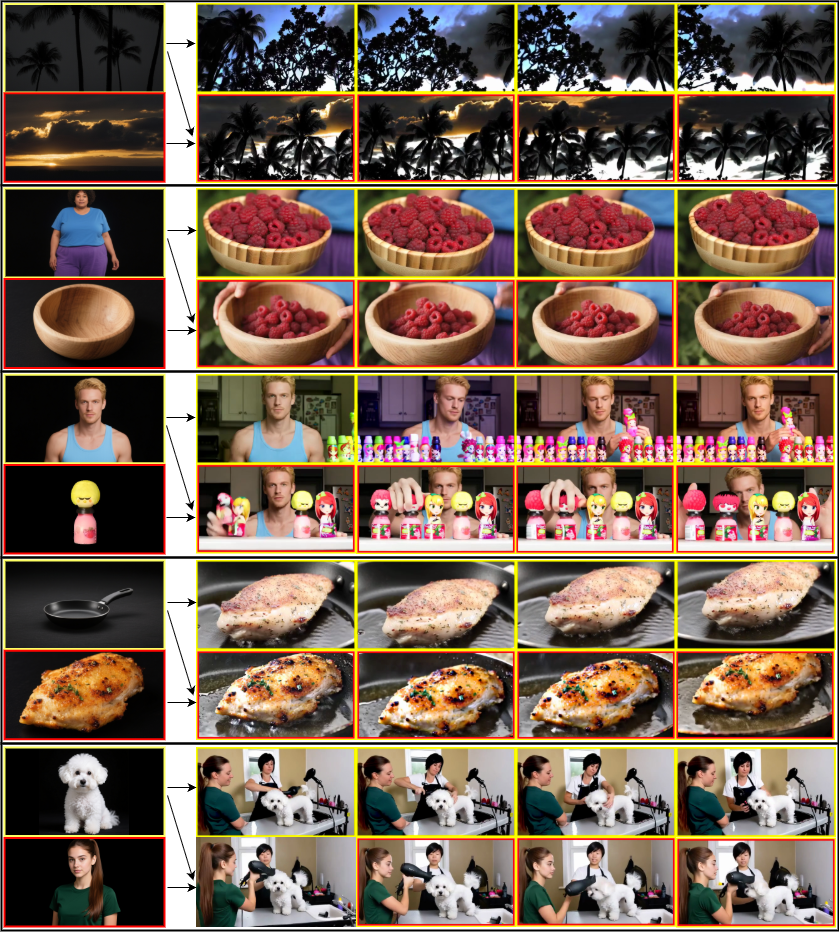
- AlcheMinT can control timing much better than previous methods. It follows the specified intervals more precisely, whether there’s one subject or multiple subjects.
- Visual quality and identity consistency are competitive with top personalized video generators.
- The timing control works even when multiple subjects overlap (both are on screen at the same time), which is tricky for other methods.
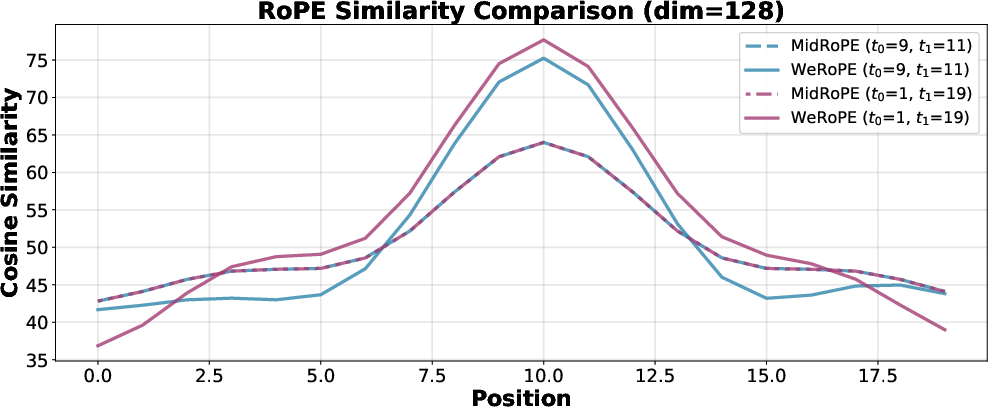
They also compared two time-control strategies:
- MidRoPE (centered at the middle of the interval) was simple but often got confused when different intervals had the same midpoint.
- Weighted RoPE (their method) improved timing accuracy and made entrances/exits more natural.
Why is this important?
This research makes personalized video generation more practical for real-world tasks:
- Storyboarding and filmmaking: Creators can plan scenes where characters enter, interact, and exit at specific moments.
- Advertising: Brands can place logos or products exactly when needed in a scene.
- Animation and compositing: Multiple characters can share the screen with reliable timing and consistent appearance.
By combining simple architecture (token concatenation) with smart time control (Weighted RoPE) and strong data preparation (accurate timestamp labels), AlcheMinT shows that we can generate high-quality, multi-subject videos where “who appears when” is under fine-grained control. This is a step toward longer, more complex, and more controllable AI-made videos.
Knowledge Gaps
Below is a single, concise list of the paper’s knowledge gaps, limitations, and open questions to guide future research.
- Learnable temporal conditioning: The Weighted RoPE (WeRoPE) uses fixed hyperparameters (positive w_p, negative w_n) without sensitivity analysis or learning. It remains unclear whether learning per-subject/per-interval weights, schedules, or conditioning functions would improve robustness, identity fidelity, or temporal adherence.
- Interval model generality: The method encodes a single interval [t0, t1] per subject. It is not evaluated or adapted for multiple disjoint intervals per subject, recurrent appearances, or complex temporal patterns (e.g., entering–exiting–reentering).
- Overlapping references: Although claimed to support overlapping subject intervals, there is no targeted benchmark or analysis isolating overlapping cases (e.g., two or more subjects co-occurring with different interval lengths) to quantify failure modes.
- Scalability in number of references: The approach relies on sequence-wise concatenation of VAE tokens; runtime/memory scaling and quality degradation as the number of references increases (e.g., 3–10+) are neither characterized nor benchmarked.
- Long-video stability: The paper focuses on relatively short clips. It leaves unexplored how WeRoPE and token concatenation behave for long durations (tens of seconds to minutes), including drift, temporal consistency, and adherence near far-end timestamps.
- Boundary and extreme intervals: Performance for very short intervals (e.g., <0.5s), intervals close to video start/end, or zero-length/near-zero-length intervals is not quantified, though such cases are common in compositional editing.
- Robustness to timestamp noise: The system assumes accurate user-specified timestamps; how errors or uncertainty in timestamps (e.g., ±0.5s) affect adherence and identity preservation is not explored.
- Spatial control and region specificity: The method provides temporal control but no mechanism for spatially constraining where a subject appears (e.g., region/mask-based placement or time-varying spatial trajectories). Integrating spatiotemporal masks/trajectories remains open.
- Identity-text trade-offs: Reference text tokens improve disentanglement but can reduce image-based identity fidelity. Strategies to jointly optimize identity preservation (image CLIP) and semantic alignment (text CLIP) without sacrificing timestamp adherence are not investigated.
- Evaluation realism: S2VTime uses references synthesized by a text-to-image model and automatic detectors/tracking (GroundingDINO, SAM2, CLIP). The benchmark’s representativeness for real user images (e.g., faces, personal objects) under occlusions, lighting changes, and motion blur is unverified.
- Label/eval noise quantification: The data collection and evaluation pipelines rely on automated detection, tracking, and CLIP similarity. The paper does not quantify annotation noise, tracking failures, or evaluation errors (e.g., false positives/negatives) or their impact on metrics (t-IOU, t-L2, CLIP).
- Attention behavior with negative weights: WeRoPE uses negative weights to suppress out-of-interval attention, but there is no analysis of attention maps, stability, or unintended artifacts (e.g., oversuppression, oscillations). Theoretical grounding and diagnostics are missing.
- Portability to other backbones: The approach targets DiT-style self-attention models with 3D RoPE and VAE latents. Its compatibility with cross-attention-heavy architectures, different positional encodings (e.g., ALiBi, learned PEs), or non-DiT video backbones is untested.
- Interplay with motion/camera control: The method is not evaluated with explicit trajectory or camera controls (poses, depth, motion embeddings). How timestamp conditioning composes with motion guidance (e.g., Tora2-like trajectory inputs) remains open.
- Multi-CFG design: The paper sets fixed CFG weights for text, reference, and joint conditions without automated tuning, uncertainty handling, or adaptive strategies. The sensitivity of results to CFG choices and better guidance schemes are not studied.
- Video realism metrics: Beyond CLIP and the new timestamp metrics, established video quality measures (e.g., FVD, KVD) and human evaluations are missing, leaving uncertainty about perceived realism, motion smoothness, and artifact rates.
- Occlusion/interactions: Robustness to occlusions, inter-subject interactions, collisions, and identity swaps is not systematically tested. Failure modes in crowded scenes or fast interactions remain unknown.
- Copy-paste risk quantification: While augmentations are claimed to prevent copying the reference image, the frequency and conditions under which the model still copy-pastes (or excessively anchors to the reference) are not quantitatively analyzed.
- Ambiguity in WeRoPE formulation: The definitions t_l = t0/2 and t_r = (T − t1)/2 are introduced without derivation or justification, and alternatives (e.g., directly using t0 and t1 frequencies or learned boundary ramps) are not compared.
- Multilingual/generalization: The reference word-tag binding and captioning rely on English and a specific LLM. Robustness to multilingual prompts, synonyms, and domain-specific vocabularies is unexamined.
- Alternative positional encodings: The paper does not compare WeRoPE to other time-aware encodings (e.g., learned temporal PEs, event-aware ALiBi) or hybrid schemes, leaving open whether simpler or learned encodings could offer better control or stability.
- Comprehensive ablations: Key components (index embeddings for disentanglement, unconditional pass choices, dropout schedules) lack thorough ablation to isolate their contributions and interactions with WeRoPE.
- Inference efficiency and latency: The method uses 40 rectified flow steps at 288×512 resolution and multiple conditions; practical latency, throughput, and real-time feasibility are not reported, especially as references scale.
- Transition naturalness: The claimed “smooth attention decay” is not quantitatively evaluated (e.g., jerk/acceleration of motion, perceptual smoothness scores), leaving entry/exit transition quality as an open measurement problem.
- Reproducibility: The paper does not clearly state public release plans for code, models, or the timestamped dataset, limiting reproducibility and external validation of the benchmark and method.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that can be implemented with the paper’s current methods and evaluation pipeline.
- Time-controlled ad creatives and product placement — sectors: advertising, retail, media
- Description: Generate ads where brand assets (logos, products, mascots) enter/exit at precise timestamps for compositional storytelling or compliance with campaign specifications.
- Tools/workflows: Timeline-based creative editor using AlcheMinT; asset library of reference images; scheduling UI; export to social formats.
- Assumptions/dependencies: Access to a capable text-to-video DiT backbone; rights to brand assets; adequate compute for inference; adherence to platform content policies.
- Storyboarding and animatics with precise entrances/exits — sectors: film/TV, animation, game previsualization
- Description: Rapidly prototype sequences where characters or props appear/disappear at specified intervals, enabling shot planning and narrative pacing.
- Tools/workflows: Script-to-timeline pipeline; entity extraction via LLM; reference image curator; AlcheMinT generation previews integrated with NLEs (e.g., Premiere/After Effects).
- Assumptions/dependencies: Reliable entity word tags; creative direction prepared as timestamps; consistency of identities across shots; compute resources.
- Social media personalization with scheduled appearances — sectors: consumer apps, social platforms
- Description: Users’ avatars/pets/objects appear only during selected segments of short-form videos (e.g., “join between 2–4s”), enabling playful, controlled cameo effects.
- Tools/workflows: Mobile UI timeline slider; reference image capture; in-app AlcheMinT backend; content safety moderation.
- Assumptions/dependencies: Efficient inference or server offload; privacy-safe handling of faces/identities; robust identity preservation across varied prompts.
- Educational microvideos with timed visual aids — sectors: education, e-learning
- Description: Produce instructional clips where visual aids (diagrams, tools, vocabulary cards) appear at specific times aligned to narration or learning objectives.
- Tools/workflows: Teacher-facing timeline editor; asset repository; integration with LMS; batch generation for lesson modules.
- Assumptions/dependencies: Accurate text binding of entity words; alignment with audio or lesson scripts; content accessibility standards.
- Synthetic testbeds for CV pipelines (timed events) — sectors: software, computer vision, QA
- Description: Generate controlled videos with multiple entities and timestamped appearances to validate trackers, detectors, and event understanding models.
- Tools/workflows: AlcheMinT generation + S2VTime evaluation; built-in Grounding DINO/SAM2-based tracking to derive reference metrics (t-IOU, t-L2).
- Assumptions/dependencies: Reliability of downstream tracking (Grounding DINO, SAM2); representative prompts; domain gap vs. real data.
- Benchmarking and evaluation adoption (S2VTime) — sectors: academia, model evaluation
- Description: Use S2VTime to quantify timestamp adherence, identity preservation, and video fidelity for existing and new S2V systems.
- Tools/workflows: Integration of S2VTime protocol into lab pipelines; baselining with CLIP-based metrics and time overlap (t-IOU/L2); reports and leaderboards.
- Assumptions/dependencies: Agreement on evaluation thresholds; reproducible prompt/entity generation; license/access to supporting models (CLIP, Grounding DINO, SAM2).
- Multi-subject scene prototyping with overlaps — sectors: media, advertising, education
- Description: Compose scenes where multiple subjects appear concurrently or transition smoothly based on overlapping intervals (enabled by WeRoPE).
- Tools/workflows: Multi-entity timeline editor; per-reference word tags and index embeddings; quick iteration on pacing.
- Assumptions/dependencies: Clear textual disambiguation of entities; robust multi-reference disentanglement; overlapping intervals tested for edge cases.
- “WeRoPE” drop-in enhancement for existing DiTs — sectors: software, generative AI tooling
- Description: Add weighted RoPE to reference tokens for temporal control without extra cross-attention modules, enabling minimal-parameter integration.
- Tools/workflows: Developer SDK/plugin; model-side changes to positional encoding; unit tests for temporal adherence.
- Assumptions/dependencies: Access to model internals; compatibility with MM-DiT-like architectures; validation on proprietary backbones.
- Logo/brand compliance checks via synthetic scenarios — sectors: ad ops, compliance
- Description: Generate synthetic test clips to verify automated brand safety checks and placement timing rules in ad delivery systems.
- Tools/workflows: Scenario generator; rule checker; metric dashboard; audit logs using S2VTime metrics.
- Assumptions/dependencies: Alignment of synthetic content to real-world conditions; acceptance of synthetic QA by stakeholders.
- Dataset augmentation for event/timing models — sectors: machine learning, CV research
- Description: Create time-labeled, multi-entity synthetic datasets to train sequence-aware models (e.g., action or event detectors).
- Tools/workflows: Prompt program for diverse events; AlcheMinT generation; automatic timestamp/mask labels via pipeline; training integration.
- Assumptions/dependencies: Domain transfer effectiveness; careful prompt curation; potential need for fine-tuning with real data.
- Corporate communications and training videos — sectors: enterprise learning, HR
- Description: Assemble explainer videos where specific visuals (policy icons, steps, roles) appear at dictated times to match scripts.
- Tools/workflows: Slide-to-video conversion; timeline scheduling; versioning for localization; governance workflows.
- Assumptions/dependencies: Script quality; identity permissions; brand guidelines and watermarking.
- Generative art with timed motifs — sectors: creative arts, daily life
- Description: Create art videos where characters or objects enter on beats or narrative moments using manual timestamp control.
- Tools/workflows: Lightweight desktop tool; artist prompt notebooks; curated reference packs.
- Assumptions/dependencies: Artist familiarity with prompts; compute scheduling; exporting and sharing rights.
Long-Term Applications
These opportunities are feasible but require further research, scaling, or integration (e.g., audio conditioning, real-time constraints, or broader ecosystem alignment).
- Long-form narrative generation with precise character timing — sectors: film/TV, streaming
- Description: End-to-end episodes with multi-character arcs and shot-level entrances/exits, consistent identities across scenes.
- Tools/workflows: Script ingestion, scene breakdown, global/dense captions; per-scene AlcheMinT control; continuity management and identity tracking.
- Assumptions/dependencies: Scaling to long videos; memory-efficient architectures; cross-scene identity persistence; editorial review pipelines.
- Audio-conditioned timing (beat- and speech-aligned entrances) — sectors: music videos, education, marketing
- Description: Align subject appearance to audio signals (beats, phonemes) for karaoke, explainers, or commercials.
- Tools/workflows: Audio-to-timestamp controller; multimodal positional encoding (extend WeRoPE with audio cues); alignment metrics.
- Assumptions/dependencies: Robust audio feature extraction; training on audio-conditioned datasets; synchronization fidelity.
- Interactive, branching video content — sectors: gaming, edutainment
- Description: Subjects appear/disappear based on user choices with dynamic timelines and consistent identity rendering.
- Tools/workflows: Real-time inference or caching; stateful timeline management; branching narrative editor.
- Assumptions/dependencies: Low-latency generation; scalable serving; UX for choices; content moderation safeguards.
- Generative insertion into existing footage (video editing augmentation) — sectors: post-production, user-generated content
- Description: Insert or remove subjects in real videos at specified times while matching motion, lighting, and camera dynamics.
- Tools/workflows: Robust video-to-latent alignment; motion/optics estimation; compositing tools; scene-consistent identity mapping.
- Assumptions/dependencies: High-quality tracking and relighting; tight control of copy-paste artifacts; advanced VAE alignment.
- Virtual production integration (LED volumes, real-time backdrops) — sectors: film/TV production
- Description: Time-controlled generative elements (props/characters) on stage, synchronized with actor blocking and camera moves.
- Tools/workflows: On-set controllers; low-latency inference; timing signals from stage managers; content cache and playback.
- Assumptions/dependencies: Real-time performance on specialized hardware; safety and reliability standards; orchestration with VFX pipelines.
- Dynamic creative optimization (DCO) with personalized subject timing — sectors: ad tech, marketing automation
- Description: Serve variants where different subjects appear at specific moments tailored to user segments or contexts.
- Tools/workflows: Creative versioning; programmatic decision engine; measurement of lift via A/B tests.
- Assumptions/dependencies: Privacy-compliant personalization; scalable generation or pre-render; attribution models and measurement rigor.
- Timestamp metadata standards and synthetic media disclosures — sectors: policy, platform governance
- Description: Standardize embedded timing metadata for generated videos to aid transparency, auditing, and moderation.
- Tools/workflows: Watermarking/timecode embedding; disclosure labels; platform APIs for metadata inspection.
- Assumptions/dependencies: Industry agreement on standards; regulatory alignment; resilience against tampering.
- Large-scale synthetic datasets for sequence-aware perception — sectors: robotics, autonomous systems
- Description: Generate richly timed multi-entity videos (with masks) for training and evaluating temporal perception models.
- Tools/workflows: Domain-specific prompt libraries; curriculum schedules; dataset curation and validation against real-world performance.
- Assumptions/dependencies: Domain gap mitigation; simulation-to-real transfer; safety evaluations.
- Cross-modal time control beyond video (e.g., robotics simulations) — sectors: robotics, simulation
- Description: Extend WeRoPE-like temporal conditioning to control event timing in simulators (scene actors entering/leaving).
- Tools/workflows: Transformer-based controllers; token concatenation for multi-modal inputs; time-weighted positional encodings.
- Assumptions/dependencies: Mapping video-centric mechanisms to other modalities; simulator integration; robust policy learning.
- Edge/mobile deployment via model distillation — sectors: consumer apps, IoT
- Description: On-device generation with timeline control for AR/VR or mobile storytelling.
- Tools/workflows: Distillation/pruning pipelines; hardware-aware quantization; progressive generation strategies.
- Assumptions/dependencies: Significant efficiency gains; acceptable quality loss; battery/latency constraints; privacy considerations.
Notes on Assumptions and Dependencies (common across applications)
- Model availability and licensing: A capable text-to-video DiT with 3D VAE must be accessible and legally usable; integration of WeRoPE requires model internals.
- Compute: Current training/inference costs are non-trivial (e.g., H100 GPUs for training); production deployment may require optimization/distillation.
- Data quality: Entity extraction (LLMs), detection (Grounding DINO), and tracking (SAM2) underpin timestamp reliability; failure modes can impact adherence metrics.
- Identity binding: Successful multi-reference disentanglement relies on supplying accurate, unique word tags and using the textual binding mechanisms.
- Safety and compliance: Rights and consent for identities, brand assets, and faces; watermarking or disclosures for synthetic media; platform policy alignment.
- Generalization: Open-set entity handling is strong but still limited by base model priors and training diversity; domain adaptation may be necessary for niche sectors.
Glossary
- ArcFace: A face recognition embedding model used to encode identity features for people. "ArcFace~\cite{arcface},"
- Classifier-free guidance (CFG): A guidance technique mixing conditional and unconditional predictions to steer diffusion sampling. "Classifier-free guidance is applied in the usual way by randomly dropping $c_{\text{text}$ during training."
- CLIP: A vision–LLM that embeds images and text into a shared representation for similarity and conditioning. "CLIP~\cite{clip}"
- Decoupled Attention Module (DAM): An attention module that separately binds visual and textual concept representations to improve conditioning. "Decoupled Attention Module (DAM)."
- Diffusion Transformer (DiT): A transformer-based backbone for diffusion models that operates on token sequences of latents. "Diffusion Transformer (DiT)."
- DINO: A self-supervised vision model used to extract semantic features from images for conditioning. "DINO~\cite{dino_v2}"
- flow-matching loss: An objective used in rectified-flow training to learn the velocity field that transports noise to data. "The training objective is the flow-matching loss"
- gated self-attention mechanism: A variant of self-attention where gating controls attention strength using auxiliary signals. "using a gated self-attention mechanism."
- Grounding Dino: A text-conditioned detector for localizing entities via bounding boxes in images or frames. "We use Grounding Dino to detect bounding boxes at several timestamps within the video."
- IP-Adapters: Adapter modules that inject image reference features into diffusion pipelines without full fine-tuning. "via IP-Adapters, Q-formers, additional Attention blocks, resulting in additional parameters to the model."
- MM-DiT-like: A self-attention-only multimodal conditioning approach that concatenates token streams instead of using cross-attention. "MM-DiT-like~\cite{mmdit} (self-attention-only) conditioning mechanisms."
- MidRoPE: A RoPE variant that centers reference tokens at the midpoint of the specified time interval. "We term this type of rope as MidRoPE."
- Multi-CFG: Extending classifier-free guidance to multiple conditioning groups (e.g., text and reference). "we obtain the multi-CFG equation as"
- non-maximum suppression (NMS): A post-processing step that removes redundant detections by keeping the highest-scoring boxes. "we apply non-maximum suppression (NMS) to remove duplicate boxes,"
- open-set: A setting where subject categories are unrestricted, allowing arbitrary entities to be conditioned. "open-set entities."
- patchifier: A module that splits inputs into fixed-size patches to produce tokens for transformer processing. "The DiT backbone consists of a patchifier with spatial downsampling"
- Q-formers: Query-based transformer modules that derive compact representations from encoders for conditioning. "Q-formers"
- Qwen-Image: A text-to-image model used to synthesize reference images for benchmarking and training. "Qwen-Image~\cite{qwen_image_edit}"
- rectified flow sampling: A deterministic sampling procedure used at inference for rectified-flow models. "Inference is done with rectified flow sampling for 40 steps"
- rectified-flow formulation: A training setup that linearly interpolates between data and noise to learn transport via a velocity field. "We adopt the rectified-flow formulation in latent space."
- ReRoPE: A time-aware RoPE variant that rescales positional frequencies to encode event intervals in attention. "time-based positional encoding scheme (ReRoPE)"
- Rotary Positional Embeddings (RoPE): A positional encoding scheme that rotates feature pairs using sinusoidal phase to enable relative positions. "Rotary Positional Embeddings (RoPE)."
- SAM2: A segmentation model used to track instance masks across video frames given prompts like boxes. "We subsequently run SAM2 to track the entity across the video"
- sequence-wise concatenation: Combining tokens from video, image, and text streams into one sequence for unified processing. "simple sequence-wise concatenation for identity injection"
- spatiotemporal self-attention: Self-attention layers that jointly attend across spatial and temporal dimensions in video tokens. "a stack of spatiotemporal self-attention blocks"
- Subject-to-Video (S2V): The task of generating videos that preserve identities from given subject references. "Subject-to-Video (S2V) generation."
- S2VTime: A benchmark for evaluating timestamp-conditioned subject-to-video generation, including timing and identity metrics. "We introduce S2VTime, a benchmark for time-stamp conditioned Subject-to-Video generation."
- t-IOU: Temporal intersection-over-union measuring overlap between predicted and ground-truth time intervals. "IoU overlap (t-IOU)"
- t-L2: Temporal L2 distance between predicted and ground-truth start/end times, normalized to [0,1]. "L2 error (t-L2)"
- time-shifting value: A parameter controlling the sampling schedule during rectified-flow inference. "with a time-shifting value of 5.66."
- token-wise concatenation: Fusing modalities by concatenating their tokens to avoid additional cross-attention modules. "Through token-wise concatenation, AlcheMinT avoids any additional cross-attention modules and incurs negligible parameter overhead."
- Variational Autoencoder (VAE): A generative model that encodes inputs to a latent space and decodes them back, here used for video/image latents. "3D variational autoencoder (VAE)"
- velocity field: The vector field predicted by the model that transports noisy latents toward data latents. "The DiT predicts the target velocity field"
- Weighted RoPE (WeRoPE): A RoPE scheme combining midpoint and edge frequencies with weights to bias attention within intervals. "Weighted RoPE (WeRoPE)."
Collections
Sign up for free to add this paper to one or more collections.

