- The paper presents a GPU-accelerated simulation framework for muon transport using precomputed 2D histograms and the Alias Method for rapid O(1) sampling.
- It validates the method against Geant4 in various geometries, showing excellent agreement in momentum and positional distributions.
- The approach achieves up to 48,000× speedup compared to traditional CPU-based Geant4 simulations, offering a scalable solution for high-statistics studies.
Ultra-Fast Muon Transport via Histogram Sampling on GPUs
Introduction and Motivation
Efficient modeling of muon transport through matter is essential for high-energy physics, nuclear instrumentation, and medical physics applications. The Geant4 toolkit is a de facto standard for high-fidelity simulation of particle-matter interactions, underpinning experiment design and analysis at large research laboratories. However, Geant4’s event-by-event particle transport incurs substantial computational cost, particularly in applications demanding statistical precision over billions of events or rapid turnaround for detector optimization. Previous work has sought to accelerate Monte Carlo (MC) transport through machine-learned surrogate models and hardware acceleration, notably with GPUs. These strategies have achieved substantial speedups but have struggled to combine physical interpretability and the full range of physical effects at scale.
The presented work introduces a GPU-accelerated particle transport framework for muons based on histogram sampling. This framework implements a data-driven particle simulation, leveraging precomputed two-dimensional histograms of energy loss and angular scattering, derived from high-statistics Geant4 simulations. The framework targets scenarios dominated by stochastic momentum loss and multiple scattering, such as active muon shields for neutrino experiments. The method achieves a substantive runtime reduction while maintaining high physical fidelity, with validations demonstrating strong agreement with Geant4 outputs.
Methodology: Histogram-Driven Transport on GPUs
The framework decomposes MC muon transport simulation into two main phases: offline precomputation and online parallel simulation. During the offline phase, high-statistics Geant4 runs generate joint histograms that capture the stochastic energy loss and scattering angular distributions for muons in various materials and over a specified momentum range. The step size d and choice of materials are fixed, and the histograms are constructed in logarithmically-spaced momentum bins, capturing the strong energy dependence of the underlying physics.
Key to online efficiency is the adoption of the Alias Method for rapid O(1) sampling from dense discrete probability tables, mitigating the cost of histogram sampling during simulation. Lookup structures for the alias tables are precomputed for each energy/material bin.
During the online GPU simulation, the CUDA kernel assigns each muon to an independent thread. Each particle’s transport loop proceeds by:
- Geometric material lookup based on the particle’s location,
- Sampling momentum loss and transverse scattering from the appropriate precomputed histogram bin using the alias table,
- Updating the particle’s momentum and direction,
- Integrating the effect of external electromagnetic fields via fourth-order Runge-Kutta (RK4), using a precomputed and interpolated B-field grid.
This procedure is repeated until termination criteria are met. This schematic workflow is displayed in (Figure 1).
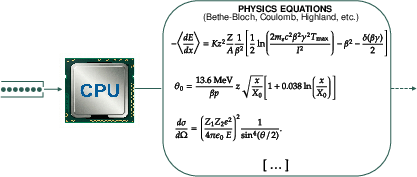
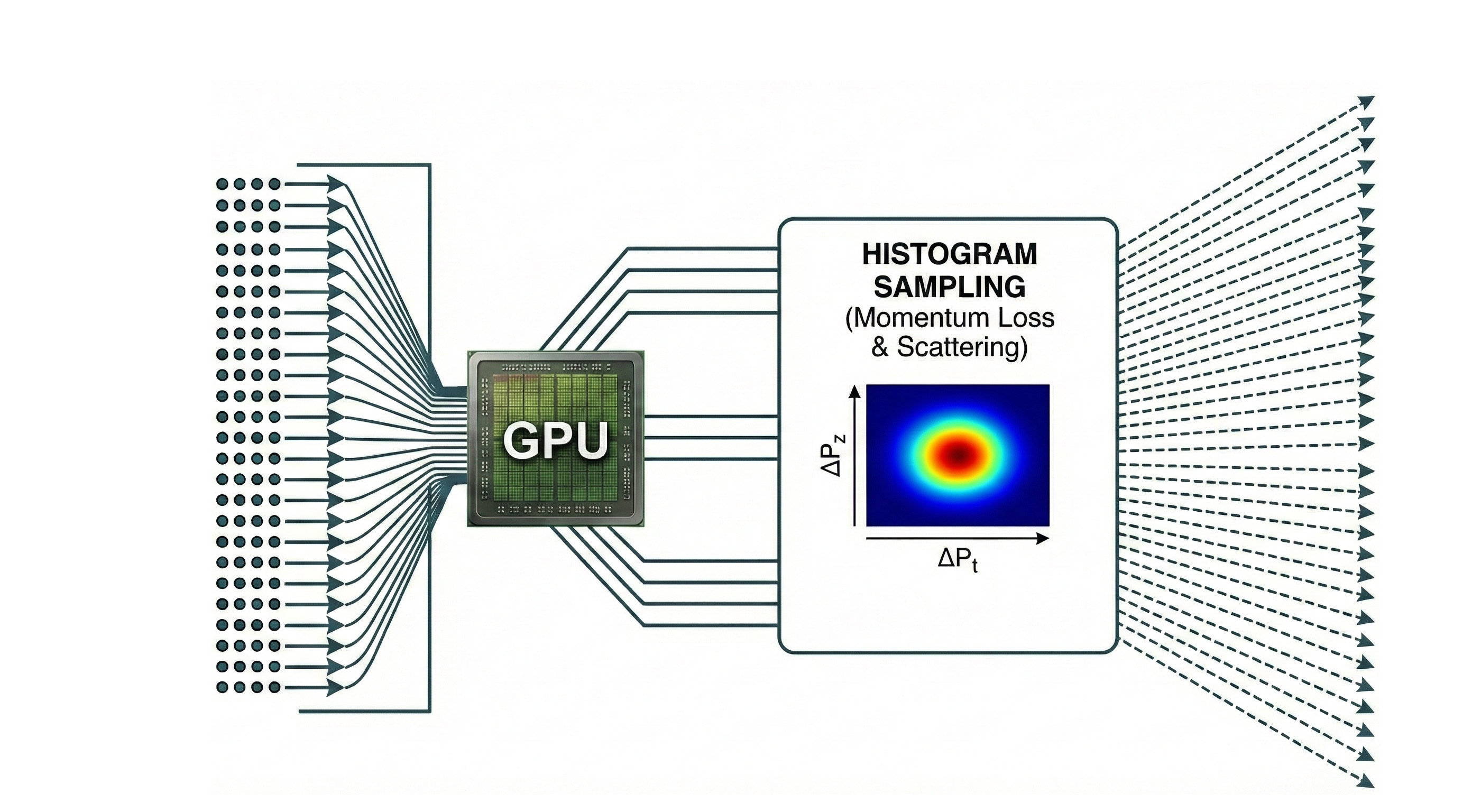
Figure 1: Schematic illustrating the sequential Geant4 simulation versus the fully parallelized GPU histogram sampling approach.
Histogram Construction and Binning Strategy
The core physical processes—energy loss (parameterized by the Bethe-Bloch formula) and multiple scattering—exhibit strong, nonlinear momentum dependence. The offline histogram construction phase uses Geant4 to propagate N=5×106 muons per bin, with momentum distributed uniformly in each logarithmic bin, through fixed materials and steps. Two-dimensional histograms of normalized longitudinal momentum loss and total transverse kick are then constructed and normalized, yielding empirical joint probability tables. Examples of these 1D and 2D histograms are shown in (Figure 2) and (Figure 3).
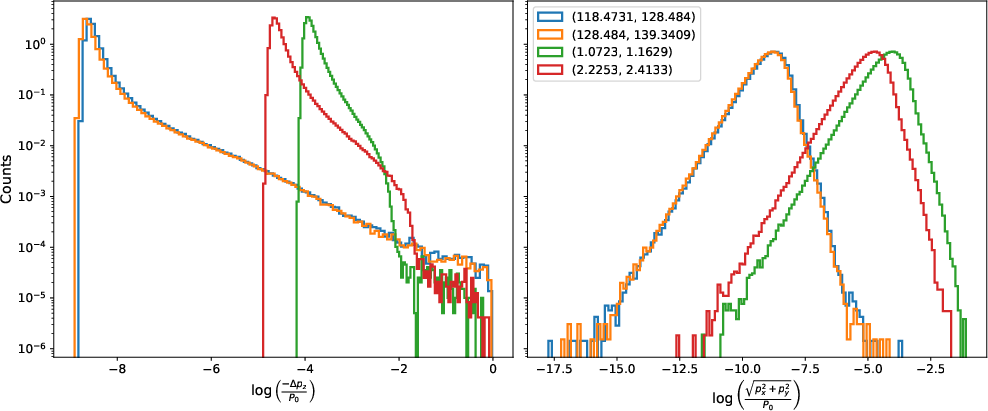
Figure 2: Momentum loss and transverse scattering histograms for varying input momentum bins.
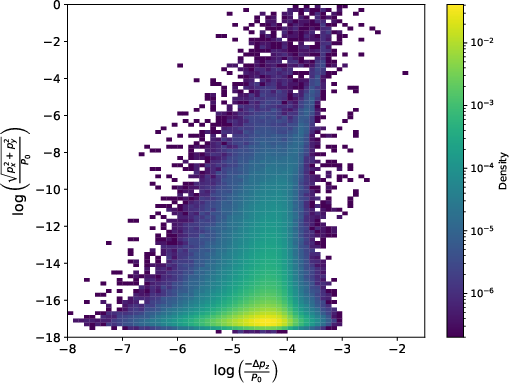
Figure 3: Two-dimensional histogram of momentum loss versus scattering for muons in iron over a fixed distance.
Logarithmic momentum binning is justified both by physical behavior and by empirical sampling studies. The mean stopping power varies rapidly at low energies, requiring dense binning, but becomes nearly logarithmic at high momenta, where wide bins suffice. This efficiency is evident in sampled energy loss versus momentum (Figure 4), which directly compares uniform and logarithmic binning strategies.

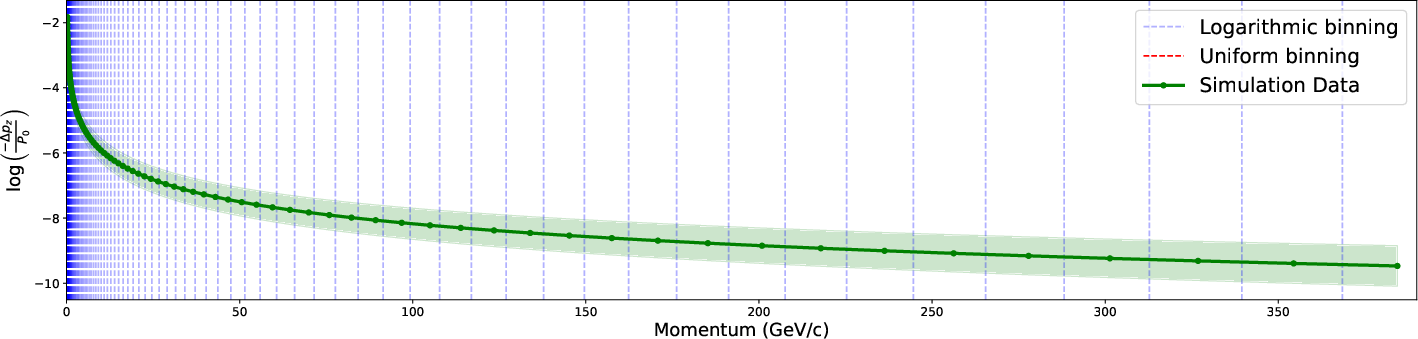
Figure 4: Comparison of uniform and logarithmic binning strategies in capturing energy loss as a function of muon momentum.
GPU Kernel: Implementation and Transport Logic
During execution, the entire secondary physics model is collapsed into table samples, with random jitter added to suppress discretization artifacts. The simulation kernel incorporates:
- Spatial hashing combined with point-in-polygon tests for fast material lookup in complex geometries,
- O(1) lookup-based histogram sampling per step,
- Randomized rotation of the transverse momentum kick (isotropically distributed in azimuth),
- High-order RK4 integration of charged particle trajectories in magnetic fields.
This approach enables efficient simulation of millions of particles in parallel, leveraging the GPU’s massive throughput. Static data, including histograms, geometry, and field maps, are loaded once into device memory.
Validation is performed in both simplified (uniform iron blocks) and complex (SHiP Active Muon Shield) geometries. In a basic test, 5×106 50 GeV muons are propagated through 10 m of iron, and final momentum and positional distributions from the histogram-driven GPU model exhibit excellent agreement with Geant4 references (Figure 5).
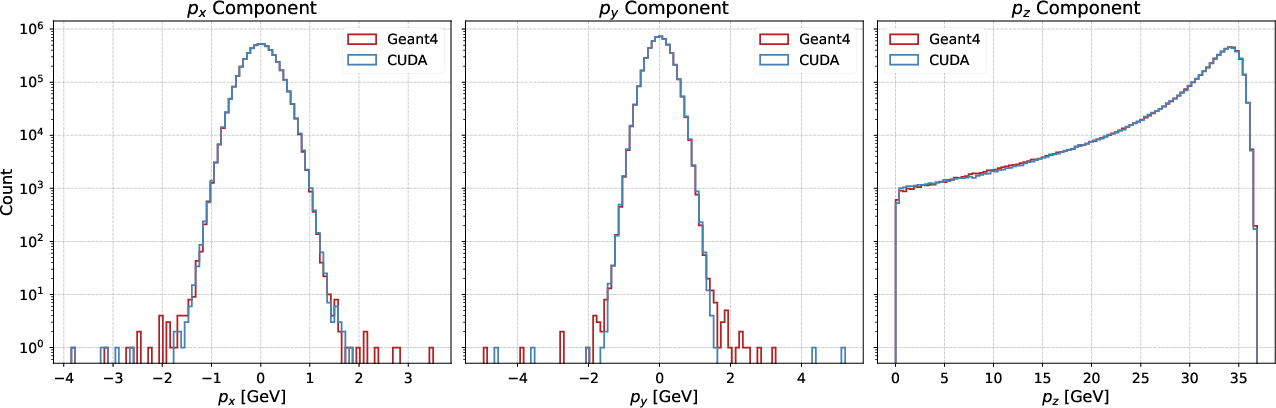
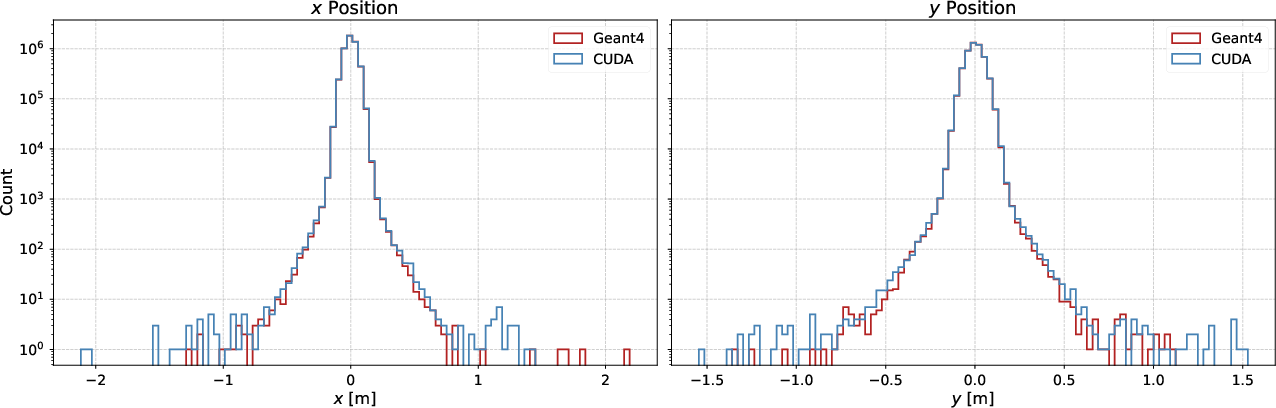
Figure 5: Comparison of final momentum and position histograms between the histogram-sampling GPU model and Geant4 over a 10 m iron target.
A large-scale test is performed using the SHiP Active Muon Shield geometry (Figure 6), propagating 5×108 muons through the realistic field and absorber configuration. Again, the sampled output distributions match closely to Geant4 (Figure 7), demonstrating preservation of physical accuracy even in non-trivial configurations.
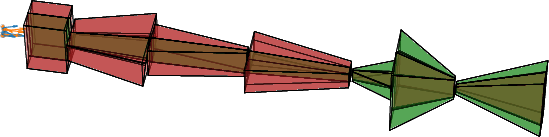
Figure 6: Schematic of the SHiP Active Muon Shield magnet arrangement, with color-coded magnet polarization.
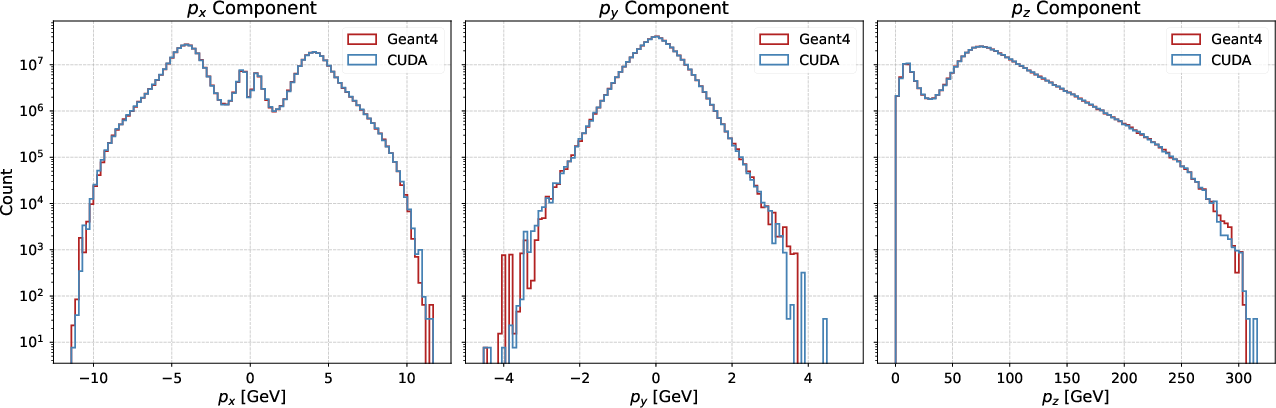
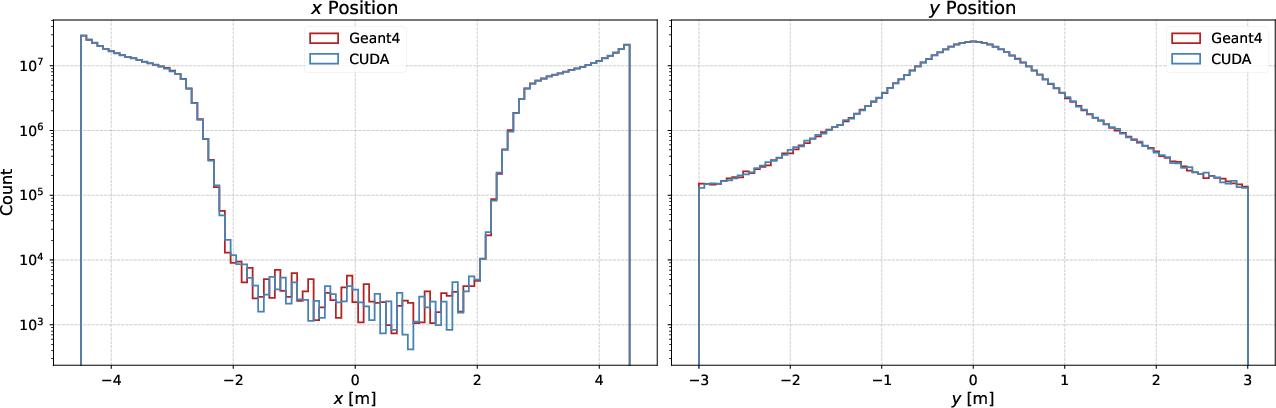
Figure 7: Distribution comparisons at the sensitive detector plane after transport through the SHiP shield for 5×108 muons.
A detailed timing benchmark quantifies the scale of the achieved speedup. For the SHiP geometry, histogram-driven GPU transport requires $88.3$ seconds for 5×108 muons on a single NVIDIA L40S. Equivalent Geant4 simulations take 4.27×106 seconds (single core) and $11,279$ seconds even on a 1024-core cluster—yielding speedups of ∼48,000× and 128×, respectively (Figure 8).
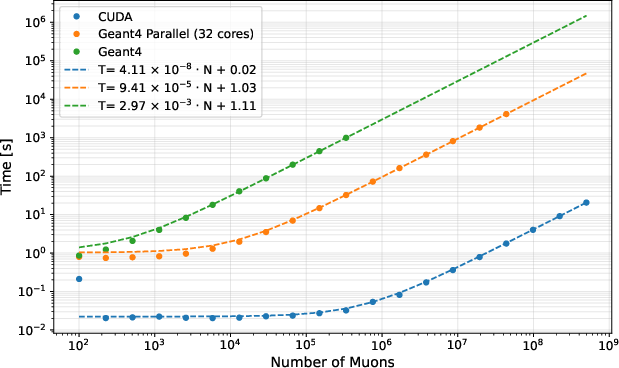
Figure 8: Linear scaling of transport runtime as a function of muon count for histogram sampling (GPU) versus Geant4 (single and multi-core).
Theoretical and Practical Implications
The histogram sampling approach, while less granular than event-by-event MC, achieves a physically faithful yet highly performant representation of continuous stochastic muon transport. It bridges the gap between fully generative models (e.g., GANs) and first-principles MC codes: it is physics-informed, interpretable, and rapidly adaptable to new scenarios via changes in the precomputed tables.
A salient implication of this methodology is its potential extensibility: such sampling schemes could be generalized to additional processes (e.g., particle decay or secondary generation) or adapted to other lepton or hadron species. Of particular interest is the conceptual compatibility with differentiable programming. Since the physics kernel is reduced to sampling from static probability distributions, modern techniques for differentiable sampling (e.g., Gumbel-Softmax, reparameterizations) could enable gradient-based optimization directly through the simulation loop. This would allow, for example, end-to-end optimization of detector geometries or field configurations within larger ML-emulated analysis pipelines.
In practical terms, this framework provides a scalable, accessible route to perform high-statistics simulations within the limitations of single-workstation GPU hardware, democratizing simulation access and minimizing infrastructure requirements. The design is also amenable to multi-GPU scaling for further throughput increases.
Conclusion
The histogram-based, GPU-accelerated framework for muon transport delivers several orders of magnitude acceleration over canonical Geant4 CPU simulations, matching their physical fidelity for continuous stochastic processes such as energy loss and scattering. Validation in both toy and complex detector geometries confirms its reliability. The method constitutes a pragmatic and extensible middle ground in fast simulation: interpretable, physically grounded, yet massively performant. This approach offers compelling prospects for scalable MC, optimization-driven design, and future differentiable simulation workflows. Extensions to additional physics processes and target domains (such as neutrino transport, dose estimation, or cosmic ray studies) are natural next steps.