- The paper demonstrates that LLMs internalize hierarchical syntactic structures, as evidenced by near-perfect subject–auxiliary inversion judgments.
- It employs minimal pair designs to reveal robust performance in parasitic gap licensing, closely matching human acceptability ratings.
- The study identifies limitations in modeling abstract symmetry, with lower accuracy observed in across-the-board extraction tasks.
Grammaticality Judgments in Humans and LLMs: Structural Generalization without Innate Bias
Introduction
This paper addresses a core question in syntactic theory and computational linguistics: to what extent do LLMs replicate human-like sensitivity to syntactic structure, as evidenced by their grammaticality judgments? Rather than relying on surface-level sequence statistics, the research probes whether models such as GPT-4 and LLaMA-3 exhibit behavioral evidence of internalizing abstract syntactic constructs—particularly, those that motivated the development of generative grammar. The study targets linguistic phenomena (subject–auxiliary inversion and parasitic gap licensing) whose grammaticality profiles are diagnostic of hierarchical structure, and contrasts model outputs with native speaker judgments.
Theoretical Perspective: LLMs as Proxies for Grammatical Competence
The distinction between human syntactic competence and LLM performance is crucial. The paper situates LLMs not as full cognitive models, but as empirical proxies: systems that allow linguists to probe the learnability of particular structural generalizations from surface input alone. Under the “proxy view” (Ziv et al., 11 Feb 2025), observed alignment between LLM and human judgments on structural phenomena implies that statistical learning over large text corpora may suffice for the induction of certain grammatical regularities, challenging strong nativist positions on linguistic knowledge.
Key in this perspective is the role of minimal pairs and classic construction types. Acceptability contrasts between grammatical and ungrammatical sentences, especially in cases where surface order conflicts with hierarchical constituency (e.g., subject–auxiliary inversion), are interpreted as evidence for internal representations not directly observable in model weights or parameters.
Experimental Design
The paper constructs a controlled evaluation suite comprising 80 sentence sets in both English and Norwegian, systematically varying three structure-sensitive configurations:
- Parasitic gaps, with diagnostic manipulation of gap order and pronoun ‘plugging’;
- Across-the-board (ATB) extraction from coordinated clauses, examining symmetry effects;
- Subject–auxiliary inversion in main and embedded yes/no questions.
Each sentence was rated by instruction-tuned LLMs (GPT-4, LLaMA-3), using explicit prompts eliciting 1–5 acceptability scores. Minimal pair design ensures that judgments reflect syntactic differences rather than merely lexical or frequency-based cues.
Results
Parasitic Gaps: Robust Structural Sensitivity
Both GPT-4 and LLaMA-3 display strong alignment with expected grammaticality profiles for parasitic gap constructions. GPT-4 achieves near-perfect accuracy for English and high, albeit more variable, consistency for Norwegian. LLMs rated grammatical variants highly and penalized ungrammatical “plugged” variants, indicating an ability to track gap licensing and structural dependencies beyond linear adjacency.
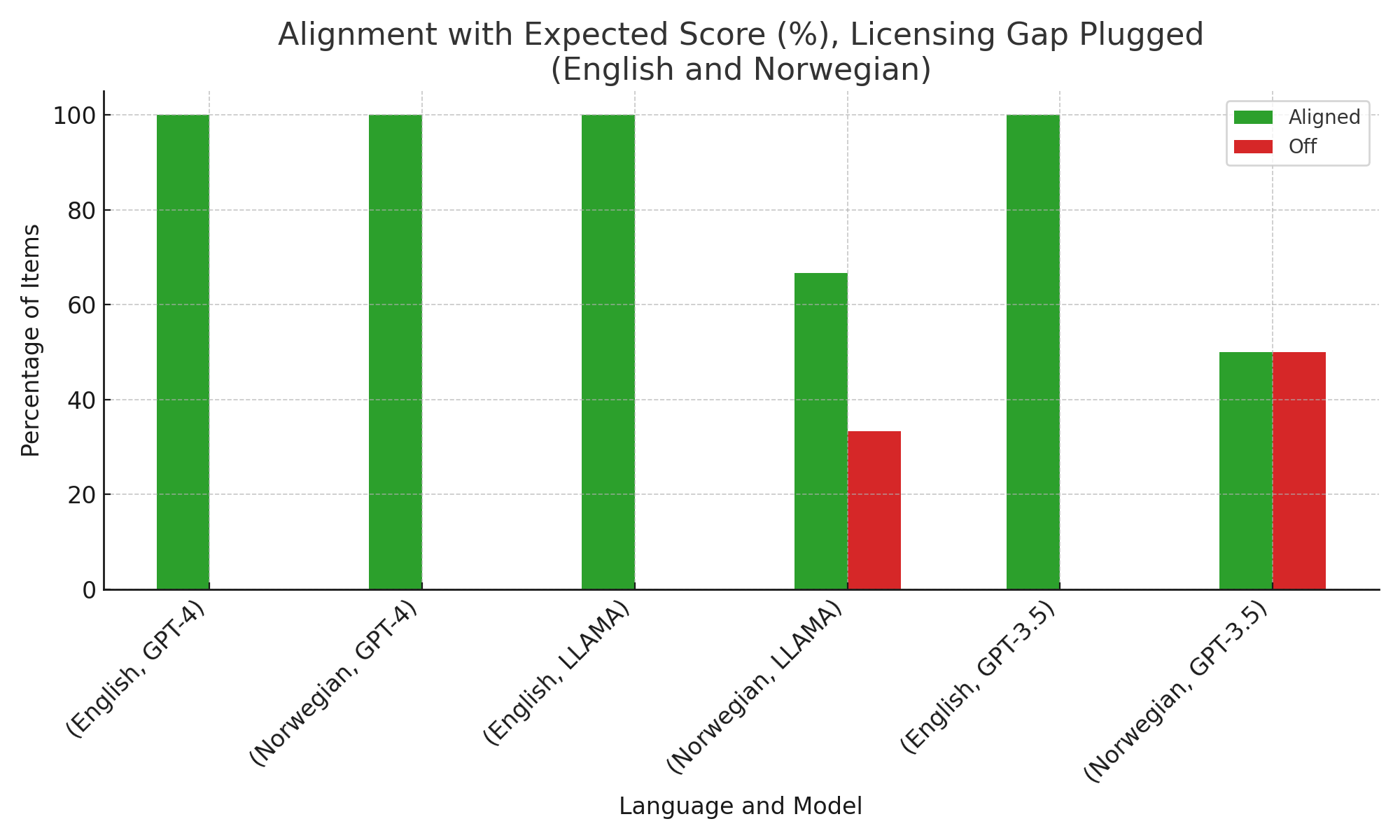
Figure 1: Accuracy of LLM judgments on parasitic gap constructions, by language and model.
Model judgments are graded, closely matching human acceptability gradience, rather than defaulting to binary well-formedness. The accuracy holds across both licensing gap–first (LP) and parasitic gap–first (PL) types, indicating abstraction over linear order.
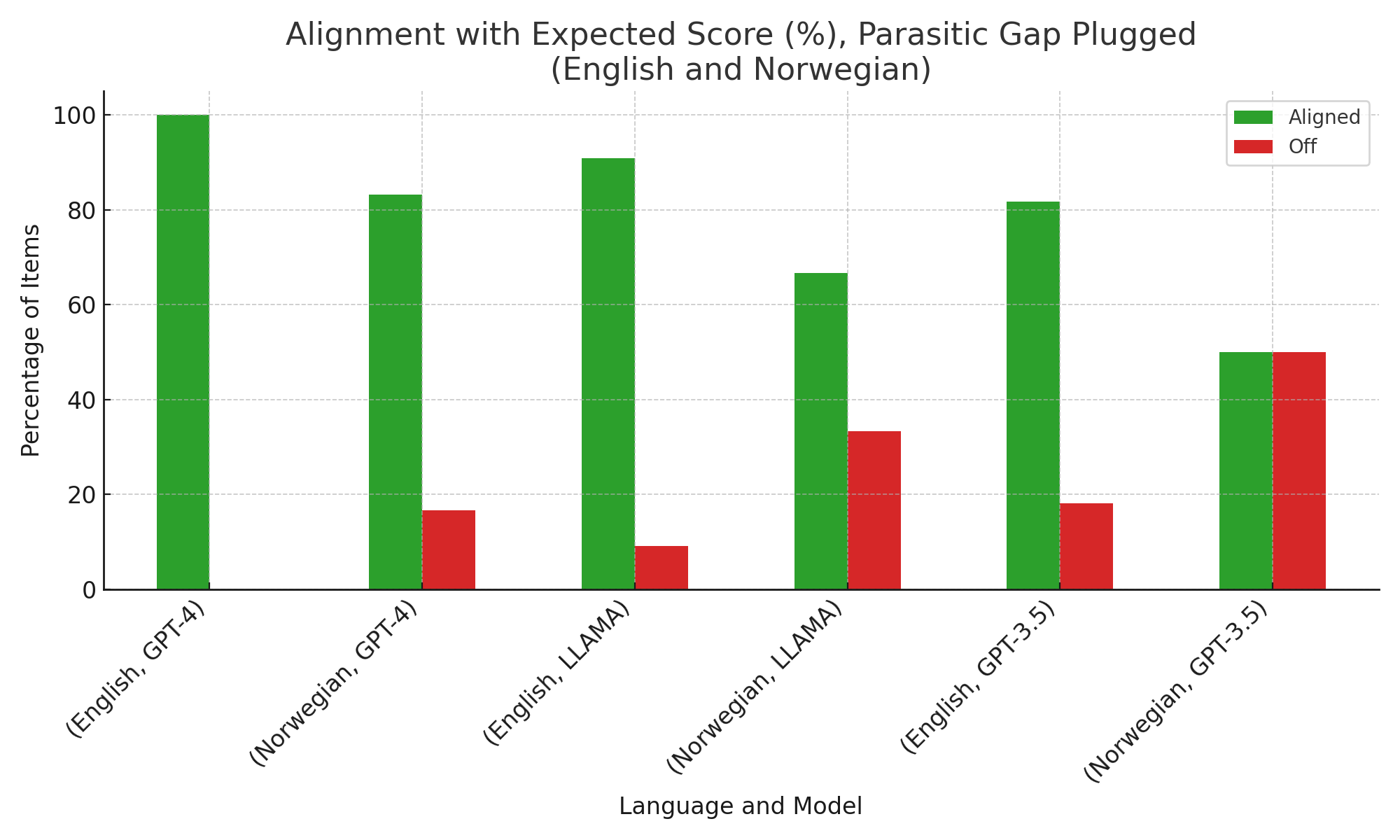
Figure 2: Accuracy of LLM judgments on parasitic gap constructions, by language and model.
The models’ small deviations (typically no more than one scale point from expert judgments) further support the hypothesis that deep syntactic relationships—such as those underlying movement and dependency islands—are reflected in model behavior.
Performance drops sharply for ATB extraction, a phenomenon that relies on parallel movement across coordinated conjuncts. GPT-4 correctly matches human judgments on 83% of English items but only 29% in Norwegian; for LLaMA-3, the trend is similar but more pronounced. This asymmetry highlights an important empirical boundary: while LLMs robustly encode local and licensing-based dependencies, they are less reliable in capturing the symmetry constraints and abstract mirroring required by coordination structures. Average deviation from expected scores confirms models’ relative uncertainty on these constructions.
Subject–Auxiliary Inversion: Hierarchical Awareness
The strongest evidence for constituent-based generalization comes from subject–auxiliary inversion. LLMs consistently front only the matrix auxiliary, never the embedded one, echoing the classic linguistic observation that even children never overgeneralize to linear-first auxiliary fronting [crain1987structure]. GPT-4 achieves perfect accuracy in English and Norwegian; LLaMA’s scores are comparably high except for minor variability in Norwegian.
This pattern cannot be explained by local sequence statistics or mere token-level learning: the LLMs must, in some form, represent hierarchical clause boundaries and constrain possible movement accordingly. The models thus exhibit functional sensitivity to the internal structure of clauses, confirming their utility as empirical probes of induced syntax.
Discussion and Implications
The paper’s main claim is that autoregressive LLMs acquire knowledge of structure-sensitive constraints—parasitic gap licensing and subject-auxiliary inversion—by exposure to surface forms alone. This supports a view of grammar as an emergent statistical regularity, rather than an innate, biologically-encoded module. The results are compatible with the “syntax from data” hypothesis, aligning with the argument that certain grammatical phenomena long thought to depend on Universal Grammar are, in fact, within reach of domain-general learning mechanisms.
Importantly, the limits observed with ATB extraction suggest these emergent generalizations are not unbounded. Structures that depend on global symmetries, abstract mirroring, or less frequent input patterns exhibit diminished LLM performance. This boundary invites further research into what aspects of human grammar are induction-accessible and which may require more than statistical exposure—whether via explicit instruction, architectural bias, or richer world knowledge.
The strong model performance on inversion and gap licensing also has implications for the methodology of theoretical syntax. LLMs serve as experimental instruments: their graded ratings can supplement human introspective judgments, expanding the empirical domain for theory testing. The observed alignment (with fine-grained deviations) reinforces the value of distributional data for discovering syntactic generalizations, but also flags cases (like ATB) where corpus-based learning may undershoot human competence.
Methodologically, the paper reinforces the practical value of instruction-tuned LLMs for acceptability rating tasks, echoing findings that such models provide stable, gradiently informative judgments under prompt-based elicitation [qiu2024evaluating].
Conclusion
The study presents evidence that LLMs, when trained on large-scale text corpora and tested on classic syntactic constructions, show robust sensitivity to grammatical contrasts diagnostic of constituent structure. The emergence of such generalizations from data alone challenges strong nativist proposals and bolsters a statistical learning account of grammar. However, gaps remain in capturing globally symmetrical dependencies, pointing to the ongoing need for both theoretical and empirical refinement in using LLMs as proxies for linguistic knowledge. Continued work at this interface is likely to yield insights both for NLP architectures and for the theory of grammar acquisition and representation.