CLASH: Collaborative Large-Small Hierarchical Framework for Continuous Vision-and-Language Navigation
Abstract: Vision-and-Language Navigation (VLN) requires robots to follow natural language instructions and navigate complex environments without prior maps. While recent vision-language large models demonstrate strong reasoning abilities, they often underperform task-specific panoramic small models in VLN tasks. To address this, we propose CLASH (Collaborative Large-Small Hierarchy), a VLN-CE framework that integrates a reactive small-model planner (RSMP) with a reflective large-model reasoner (RLMR). RSMP adopts a causal-learning-based dual-branch architecture to enhance generalization, while RLMR leverages panoramic visual prompting with chain-of-thought reasoning to support interpretable spatial understanding and navigation. We further introduce an uncertainty-aware collaboration mechanism (UCM) that adaptively fuses decisions from both models. For obstacle avoidance, in simulation, we replace the rule-based controller with a fully learnable point-goal policy, and in real-world deployment, we design a LiDAR-based clustering module for generating navigable waypoints and pair it with an online SLAM-based local controller. CLASH achieves state-of-the-art (SoTA) results (ranking 1-st) on the VLN-CE leaderboard, significantly improving SR and SPL on the test-unseen set over the previous SoTA methods. Real-world experiments demonstrate CLASH's strong robustness, validating its effectiveness in both simulation and deployment scenarios.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “CLASH: Collaborative Large-Small Hierarchical Framework for Continuous Vision-and-Language Navigation”
Overview: What is this paper about?
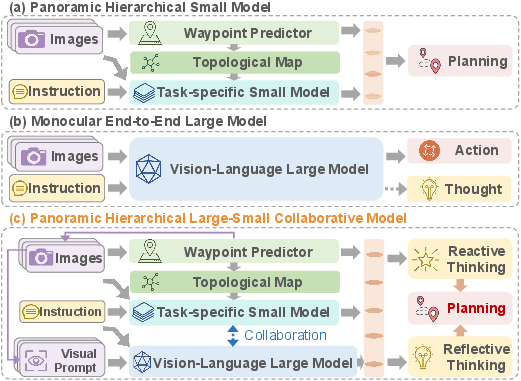
This paper is about teaching robots to follow spoken or written directions (like “Go out of this room and turn right into the kitchen”) while moving around in real buildings. The robot sees the world through cameras and sometimes lasers, and it has to figure out where to go without using a pre-made map. The authors propose a new system called CLASH that combines two kinds of AI models—one small and fast, and one large and smart—so the robot can both move reliably and reason well in tricky situations.
Key objectives: What questions are they trying to answer?
The paper focuses on three simple questions:
- How can a robot follow natural language directions in messy, real-world spaces without a map?
- Can we combine a small, task-focused model (good at the navigation task) with a large, general model (good at reasoning and understanding) to get the best of both worlds?
- How do we make the robot’s decisions safe and reliable, both in computer simulations and in real buildings?
Methods and approach: How does CLASH work?
Think of CLASH like a team with two players and a referee:
- The small specialist: RSMP (Reactive Small-Model Planner)
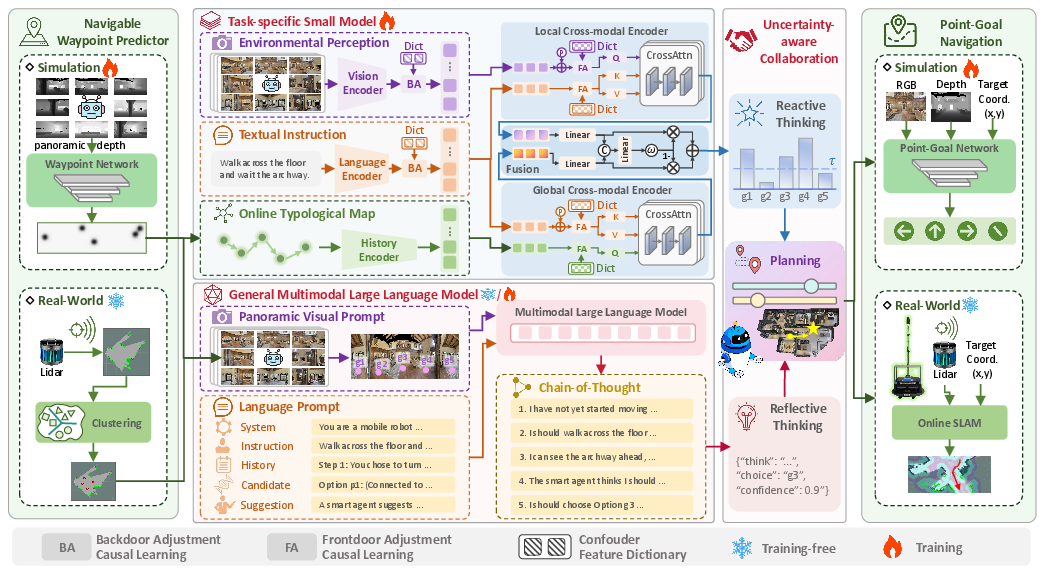
- Role: A fast, experienced driver. It’s great at turning what the robot sees and the instructions into immediate next steps (like picking the next waypoint).
- How it works: It looks at a 360-degree panorama (like a robot wearing a camera hat that sees all around) and the instruction, and uses a “dual-branch” design:
- Global branch: Keeps track of big-picture memory—where the robot has been.
- Local branch: Pays attention to nearby details—what’s in front right now.
- Causal learning: It tries to separate true causes from shortcuts or coincidences. For example, don’t assume “the kitchen is always to the right” just because that happened a lot in training. This helps it generalize to new buildings.
- The large reasoner: RLMR (Reflective Large-Model Reasoner)
- Role: A thoughtful navigator, like a coach who explains why a move makes sense. It’s a Multimodal LLM (MLLM), so it can understand both pictures and words.
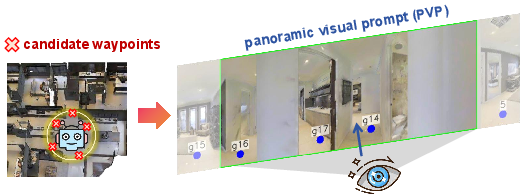
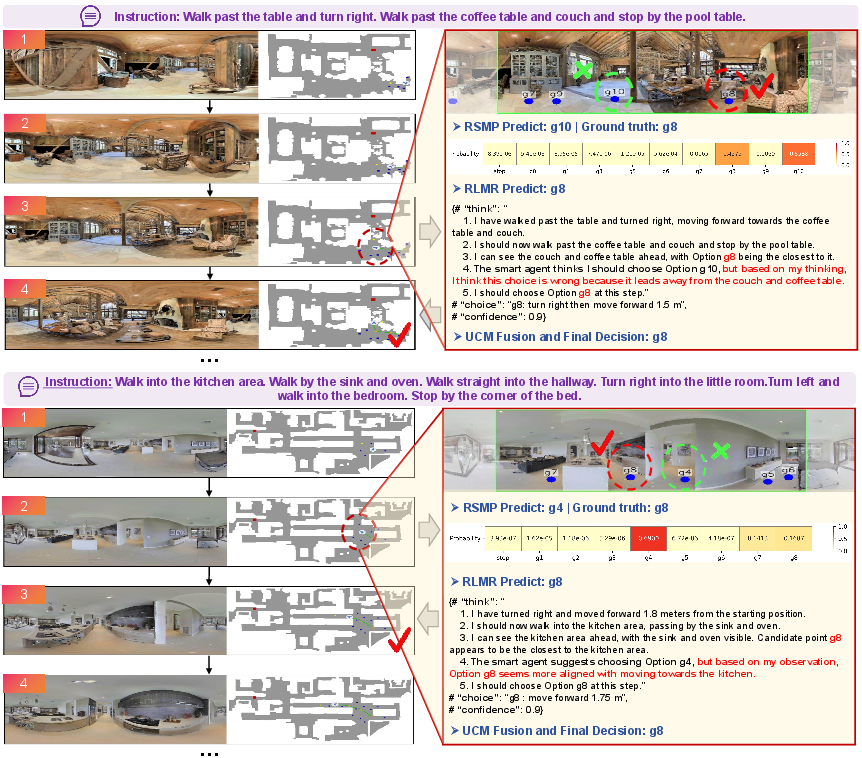
- Panoramic visual prompting: It feeds the whole 360-degree view into the large model, with markers for candidate places to go. The back part of the panorama gets softly dimmed so the model focuses more on what’s ahead.
- Chain-of-thought reasoning: It thinks step by step—what’s the current situation, which actions make sense, how the visuals match the instruction, whether the small model’s suggestion seems reasonable, and then gives a final decision with a confidence score.
- The referee: UCM (Uncertainty-Aware Collaboration Mechanism)
- Role: Decides whose plan to follow—small specialist or large reasoner—based on confidence.
- Conformal prediction (CP): Imagine the small model makes a shortlist of “likely good moves” with a built-in coverage guarantee. If it’s very sure (shortlist size = 1), just do it. If it’s unsure (shortlist has several options), ask the large model to weigh in. Then blend their answers, giving more weight to the large model when the small one is uncertain.
To handle real movement safely, CLASH also adds solid low-level control:
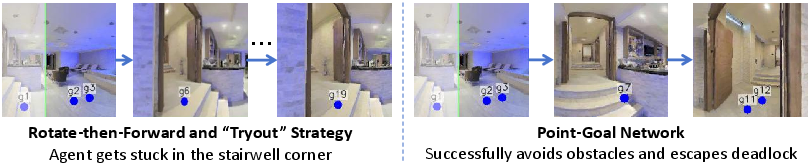
- In simulation: A learnable point-goal policy (DDPPO) replaces simple “spin and try again” rules. This reduces bumping into obstacles and helps recover from dead ends.
- In the real world: The robot uses LiDAR (a laser sensor that measures distances) to cluster safe spots into navigable waypoints and SLAM (Simultaneous Localization and Mapping) to build a map on the fly and plan safe paths. This avoids relying on perfect depth cameras that consumer hardware often doesn’t have.
Main findings: What did they discover and why does it matter?
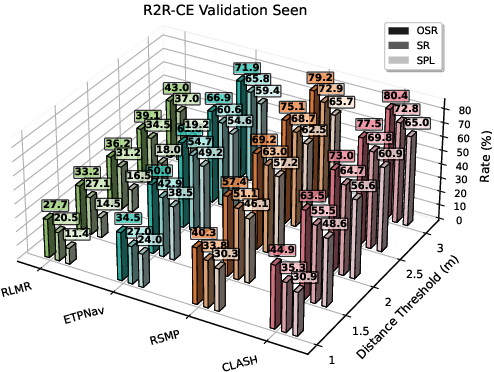
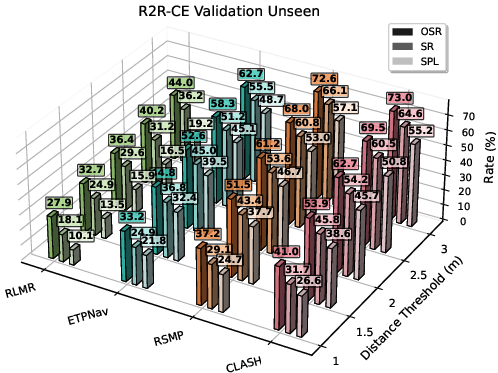
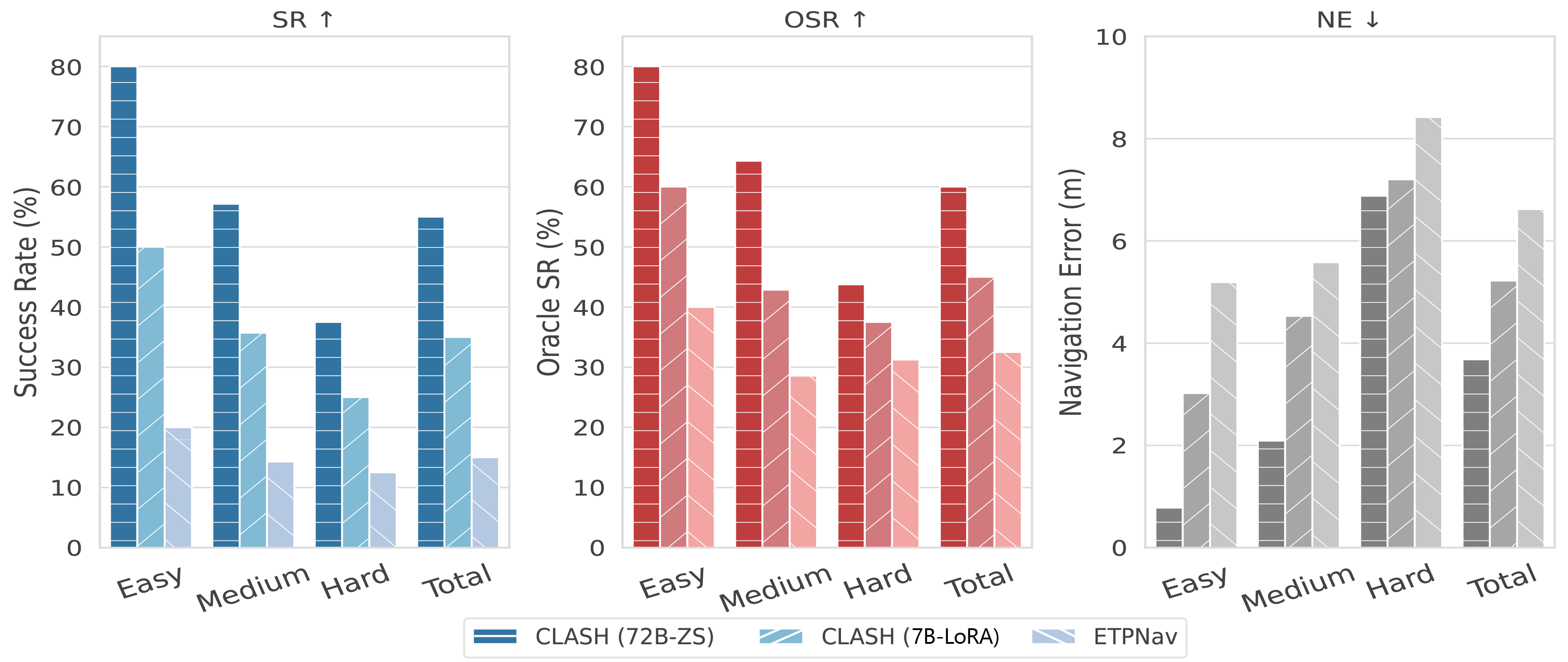
- Better performance: CLASH reaches state-of-the-art results on major navigation benchmarks (R2R-CE and REVERIE-CE), ranking first on the VLN-CE leaderboard. It notably improves two key scores:
- SR (Success Rate): How often the robot stops within the right spot.
- SPL (Success weighted by Path Length): Measures both success and efficiency.
- Strong sim-to-real transfer: The system works not just in simulation but also in real buildings, thanks to the LiDAR-based waypoint generation and SLAM-based control. It’s less likely to get stuck or collide.
- More interpretable decisions: The large model explains its reasoning, making it clearer why a move was chosen. This is important for trust and debugging.
Implications: Why is this research important?
- Reliable robot navigation: Combining a small, specialized model’s efficiency with a large model’s reasoning makes robots better at following complex instructions in new places.
- Safer real-world use: Replacing brittle rules with learned policies in simulation and using LiDAR+SLAM in the real world improves safety and practicality.
- Smarter collaboration: Using uncertainty as a “when to ask for help” signal is a powerful idea. It means robots can know when to rely on their fast instincts and when to think more deeply.
- A blueprint for future systems: The “large-small hierarchy” offers a general pattern other robotics tasks can follow—pair a quick expert with a thoughtful generalist and let a confidence-aware referee coordinate them.
In short, CLASH shows that a smart partnership between a fast specialist and a careful thinker can make robot navigation more accurate, safer, and easier to understand.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each point is concrete to guide future research.
- Coverage guarantees of conformal prediction under sequential, non-i.i.d. navigation: the CP calibration assumes exchangeability and uses a simple nonconformity score
S(x, y) = 1 - p_RSMP(y). It is unclear how coverage holds under covariate shift across timesteps, scenes, and long-horizon trajectories, and whether sequential/online CP variants are needed to maintain guarantees in embodied settings. - Calibration and reliability of
RLMRconfidence: the fusion relies on a self-reported MLLM confidencec^{RLMR}, but large models are known to be miscalibrated. There is no method to calibrate or validateRLMRconfidence (e.g., via CP, temperature scaling, or external verifiers), nor an analysis of its impact on UCM decisions. - Fusion weighting design and sensitivity: the uncertainty weight
α = min(|C(x)|/L_max, 0.9)and caps are heuristic. There is no principled derivation, sensitivity analysis, or learning-based alternative (e.g., meta-controller, bandits, or RL) to adaptively determine fusion weights based on task context, history, or risk. - RSMP probability calibration: CP uses softmax probabilities from RSMP to construct nonconformity scores, but softmax is often miscalibrated. The paper does not assess or improve RSMP calibration (e.g., temperature scaling, Dirichlet calibration), which directly affects CP set sizes and UCM behavior.
- Confounder specification and validation in causal modules: back-door/front-door adjustments use pre-constructed confounder dictionaries and mediator sampling without a formal identification proof for VLN. The paper does not detail how confounders are discovered, validated, or how sensitive performance is to mis-specified confounders, nor does it quantify causal gains beyond standard ablations.
- Generalization beyond R2R-CE and REVERIE-CE: evaluation does not cover other embodied datasets (e.g., RxR-CE, touch/sound-augmented VLN, outdoor navigation), instruction languages beyond English, or instruction styles (noisy, colloquial, or multi-step). Cross-dataset and cross-language generalization remains open.
- Real-world evaluation scope and metrics: while real-world experiments are mentioned, the paper lacks quantitative safety and reliability metrics (collision rate, deadlock frequency, time-to-goal, human-interaction handling), diversity of scenes (crowded, dynamic, reflective/glass, multi-floor), and comparisons against baselines in deployment.
- Resource and latency constraints for
RLMR: the deployedQwen2.5-VL-72Bon 4 A800 GPUs is unlikely feasible on typical mobile robots. There is no analysis of latency, throughput, energy, or system-level constraints, nor exploration of smaller MLLMs, distillation, or on-device optimization strategies to meet real-time requirements. - Panoramic prompting geometry and alternatives: equirectangular distortion and rear-view masking are heuristic. It remains unexplored whether cube-map or spherical projections, learned attention masks, or panoramic pretraining improve
RLMRspatial reasoning; the effect size of the semi-transparent rear mask is not quantified. - Multisensor alignment for
RLMRprompts: projecting LiDAR-derived waypoints onto panoramas requires accurate camera–LiDAR extrinsic calibration and synchronization. Robustness to calibration errors, sensor drift, and time misalignment is not studied, yet these are common in real deployments. - Depth and 3D reasoning in
RLMR: the large model reasons only over RGB panoramas; depth or 3D structure is not incorporated. Open questions include adding monocular or stereo depth, NeRF/BEV reasoning, or multi-view geometry cues to improve object/space grounding and occlusion handling. - Dynamic obstacles and moving agents: both UCM and controllers assume quasi-static environments. The framework’s behavior under dynamic obstacles, human interaction, and social navigation constraints is not evaluated or modeled (e.g., predictive planning, intent recognition).
- Multi-floor, elevation, and 3D traversal: the real-world pipeline uses 2D LiDAR cost maps and SLAM, which can struggle with stairs, ramps, and multi-level spaces. The method’s handling of elevation changes and vertical navigation remains unexplored.
- Robust waypoint generation in cluttered or long-range environments: K-means clustering on navigable points with fixed
K=10may be suboptimal in varying scene complexity. There is no adaptiveKselection, robustness analysis in clutter, or integration of semantic cues (objects/doors) into waypoint proposals. - Closed-loop coupling between high-level decisions and low-level failures: the framework does not describe how
RSMP/RLMRreact when the low-level controller cannot reach a chosen waypoint (blocked paths, dynamic obstacles). Mechanisms for feedback, re-planning triggers, and escalation policies are unspecified. - Object-level grounding and instruction semantics: REVERIE-CE contains object-directed instructions, yet the paper does not detail explicit object detection/segmentation or referential grounding strategies, especially in panoramas, nor evaluate object localization errors and their impact on navigation.
- Handling ambiguous, underspecified, or erroneous instructions: while
RLMRprovides chain-of-thought reasoning, there is no stress-testing with adversarial paraphrases, ambiguous references, or conflicting cues, nor metrics for instruction disambiguation success. - Interpretability evaluation: CoT is claimed to improve transparency, but there is no human or automatic assessment of explanation quality, faithfulness to model internals, or utility for debugging and user trust in embodied settings.
- Allowing
RLMRto propose outside-candidate actions: UCM forwards only RSMP’s CP-filtered candidate set toRLMR. It remains unknown whether permittingRLMRto suggest novel waypoints or re-propose candidates improves performance, and how to safely integrate such proposals. - Failure detection when RSMP is confident but wrong: UCM consults
RLMRonly under RSMP uncertainty (|C(x)| > 1). Mechanisms to catch high-confidence RSMP errors (e.g., counterfactual checks, external validation, disagreement detectors) are not explored. - Risk-aware decision-making and epsilon selection: the CP miscoverage rate
εand its operational mapping to fusion behavior are not tied to task risk (e.g., collision risk zones, proximity to obstacles). Adaptiveεpolicies or risk-sensitive collaboration remain open. - Metrics beyond SR/SPL: the benchmark reporting focuses on SR/SPL/NE/TL. Important deployment metrics (time-to-decision, CPU/GPU load, memory footprint, battery drain, recoveries from deadlock, human-in-the-loop frequency) are not reported.
- Data efficiency and scaling laws: RSMP training uses only R2R; the paper does not study how performance scales with data, augmentation strategies, or instruction diversity, nor whether causal modules reduce data needs compared to non-causal baselines.
- Robustness to sensor noise and failure: LiDAR dropouts, reflective/glass surfaces, motion blur, and camera exposure changes are unaddressed. The impact of sensor anomalies on waypoint generation, SLAM, and
RLMRreasoning is unknown. - Security and safety considerations: no discussion on adversarial prompts/images for
RLMR, instruction spoofing, or safe fallback policies when uncertainty remains high over multiple steps. - Reproducibility of real-world experiments: details on environments, routes, instruction sources, repetition counts, and logs are limited. A standardized real-world benchmark or released dataset/protocol would enable rigorous comparison.
Practical Applications
Immediate Applications
Below are actionable, deployable-now applications that leverage CLASH’s findings and released code, grouped by sector. Each item includes potential tools/workflows and key assumptions/dependencies.
- Bold: Voice-directed indoor service robots for ad‑hoc tasks (healthcare, hospitality, facilities)
- What: Robots follow spoken or written instructions (e.g., “Go to the nurse station and bring this to Room 312,” “Guide guests to the elevator,” “Patrol the 3rd-floor corridor and check if the meeting room is free”) without pre-built maps.
- Why CLASH helps: Panoramic reactive planner (RSMP) gives robust waypoint choices; reflective large-model reasoner (RLMR) with CoT improves handling of ambiguous or novel instructions; UCM uses conformal prediction to switch trust between models, improving robustness and safety.
- Tools/workflows: ROS-based stack with LiDAR-based clustering waypoint node, SLAM-based local controller (move_base), RSMP policy, RLMR inference with PVP-CoT, UCM gating/fusion. Use CLASH codebase for integration.
- Assumptions/dependencies:
- Robot with 2D LiDAR (for waypoint generation), panoramic RGB camera (for PVP-CoT), and onboard compute or edge server for MLLM.
- Calibration data for conformal prediction coverage; exchangeability assumption for CP.
- On-prem or private-cloud MLLM for privacy if sensitive areas involved.
- Bold: Interpretable patrol/inspection with audit-ready logs (security, utilities, manufacturing)
- What: Patrol robots execute natural-language checklists (e.g., “Inspect fire exits then scan storage area A; report obstacles”) while generating transparent reasoning traces.
- Why CLASH helps: CoT logs from RLMR make decisions audit-able; UCM quantifies decision confidence; panoramic prompting grounds calls to specific spatial cues.
- Tools/workflows: “CoT log + uncertainty” dashboard; periodic CP threshold validation; operator handoff when UCM flags low confidence.
- Assumptions/dependencies:
- Storage of CoT and sensor data with privacy controls.
- Safety policy to escalate to human operator under low confidence or conflict.
- Bold: Zero-training waypoint generation for brownfield sites (construction, events, pop‑up retail)
- What: Rapid deployment in unmapped or reconfigured environments; robots extract navigable waypoints from LiDAR without training.
- Why CLASH helps: Training-free LiDAR-based clustering module enables bootstrapped navigation in changing layouts.
- Tools/workflows: K-means clustering node over occupancy cost maps; ROS TF transforms for local/global frames; waypoint refinement filters.
- Assumptions/dependencies:
- Adequate LiDAR coverage; dynamic obstacle updates in SLAM cost map.
- Grid resolution and K for clustering tuned for site scale.
- Bold: Safety-aware autonomy gatekeeping (risk management across sectors)
- What: A controller of controllers that decides when to trust the reactive model vs. invoke reflective reasoning, or defer to human.
- Why CLASH helps: Conformal prediction gives calibrated, statistically grounded uncertainty estimates for decision handoffs.
- Tools/workflows: UCM with programmable miscoverage ε; escalation policy rules; incident replays using CoT plus CP records.
- Assumptions/dependencies:
- Calibration set similar enough to deployment distribution; periodic recalibration where distributions shift.
- Operational thresholds agreed with safety officers/regulators.
- Bold: Human-robot interaction studies with explainable navigation (academia, UX/HRI labs)
- What: Run controlled experiments on user trust, instruction design, and explainability using CoT and panoramic visual grounding.
- Why CLASH helps: PVP-CoT produces interpretable, spatially anchored rationales; UCM exposes confidence.
- Tools/workflows: Prompt templates for instruction variants; intervention points at low-confidence steps; metrics (SR, SPL) plus human-rated clarity.
- Assumptions/dependencies:
- Access to an MLLM capable of reproducible CoT; consistent prompt templates.
- Bold: Benchmarking and baselines for hybrid large–small models (academia, embodied AI R&D)
- What: Use CLASH as an open-source SOTA baseline to test new causal modules, uncertainty estimators, or panoramic prompt designs.
- Why CLASH helps: Modular RSMP (with back-door/front-door causal adjustments), PVP-CoT, UCM with CP; clear sim and real-world tracks.
- Tools/workflows: Ablation harness on R2R-CE/REVERIE-CE; Habitat for sim; ROS for real robots; conformal calibration pipeline.
- Assumptions/dependencies:
- GPU availability for training RSMP and running MLLMs; dataset access and licenses.
- Bold: Campus/museum wayfinding robots (education, public venues)
- What: On-demand escort and informative guidance (“Take me to the robotics lab,” “Show the Impressionist gallery”), adapting to dynamic crowds.
- Why CLASH helps: Panoramic inputs improve situational awareness; UCM handles uncertain disambiguation (e.g., multiple corridors).
- Tools/workflows: Venue-specific intent library; geofencing and safe zones; CoT-based explanations for visitors.
- Assumptions/dependencies:
- Venue permissions; fallback routes where LiDAR occlusion is severe.
- Bold: Rapid prototyping for instruction-to-waypoint planners (software, robotics integrators)
- What: Integrate the RSMP waypoint planner with existing SLAM stacks as a drop-in “brain” for language tasks.
- Why CLASH helps: RSMP is lightweight and panoramic; causal modules increase generalization; easy to wrap via ROS actions.
- Tools/workflows: RSMP gRPC/ROS2 wrapper; instruction interface; logging hooks.
- Assumptions/dependencies:
- Panoramic input or stitched views; instruction encoding (BERT/CLIP) available.
- Bold: Data-efficient deployment in privacy-sensitive sites (healthcare, finance, defense)
- What: On-premise reasoning with minimal task-specific data; no need for RGB-D panoramic depth.
- Why CLASH helps: LiDAR-based waypoints and SLAM reduce reliance on RGB-D; MLLM can run locally; CP avoids retraining for uncertainty.
- Tools/workflows: Local VLLM or equivalent; privacy audits of logs.
- Assumptions/dependencies:
- Sufficient compute for local MLLM or a distilled variant.
Long-Term Applications
These require additional research, scaling, or productization (e.g., miniaturization, regulatory alignment, expanded training).
- Bold: General-purpose home assistants with robust language navigation (consumer robotics)
- What: Household robots reliably follow natural instructions in diverse home layouts and styles, coping with clutter and rapid changes.
- What’s needed: Distilled/edge-ready RLMRs, improved domain adaptation for RSMP causal modules, self-calibrating CP under drift, tighter SLAM integration with semantic grounding.
- Dependencies:
- Affordable 360° sensing (multi-camera rigs) and compact compute; privacy-preserving local inference.
- Bold: Assistive navigation for the visually impaired via voice + robot escort (healthcare, public services)
- What: Safe, interpretable, uncertainty-aware guidance through complex indoor spaces, with on-the-fly clarification dialogues.
- What’s needed: Human factors validation, formal safety cases using CP coverage, integration with tactile/voice UX, redundancy and fail-safe handoffs.
- Dependencies:
- Regulatory approvals; robust obstacle detection in crowded settings.
- Bold: Multi-robot coordination via shared uncertainty and reflective reasoning (logistics, emergency response)
- What: Teams that divide tasks and routes, share CP-calibrated uncertainty, and resolve conflicts with distributed CoT reasoning.
- What’s needed: Conformal prediction for multi-agent settings, communication-efficient CoT summarization, conflict-resolution policies.
- Dependencies:
- Reliable V2V/V2X; common semantic map layers.
- Bold: Outdoor/large-scale extensions with hybrid localization (smart cities, infrastructure)
- What: Natural-language navigation across campuses/cities using GPS/vision/IMU fusion and panoramic reasoning.
- What’s needed: Robust PVP for outdoor panoramas, weather/lighting invariance, hierarchical route planning, safety compliance for public roads/sidewalks.
- Dependencies:
- GNSS and multi-sensor fusion; municipal policies for sidewalk robots.
- Bold: Standardized “explainable autonomy” records for compliance (policy, governance)
- What: CoT + calibrated uncertainty as a standardized audit artifact for robotic decisions, aiding liability, post-incident analysis, and certification.
- What’s needed: Consensus on logging schemas, retention/privacy rules, and acceptable CP coverage thresholds per risk class.
- Dependencies:
- Sector-specific regulations; third-party audit tooling.
- Bold: Distilled and specialized RLMRs for embedded platforms (semiconductors, edge AI)
- What: Compact multimodal LMs delivering reflective reasoning with PVP-CoT at mobile power budgets.
- What’s needed: Knowledge distillation from 70B-scale models, quantization-aware training, on-device prompt optimization and attention steering.
- Dependencies:
- Hardware accelerators; robust benchmarking on energy/latency.
- Bold: Learning-based local controllers with safety guarantees (robotics, autonomy software)
- What: Replace SLAM-based local control with robust learned policies (e.g., DDPPO-like) possessing formal safety constraints.
- What’s needed: Safe RL under partial observability, sim-to-real transfer methods, online verification integrated with UCM.
- Dependencies:
- Rich simulation-to-real pipelines; certifiable safety envelopes.
- Bold: AR-guided human navigation using panoramic prompting (education, retail, venues)
- What: Wearable or phone-based AR provides step-by-step, explainable guidance derived from PVP-CoT reasoning.
- What’s needed: Real-time panorama stitching or 360 sensors on-device, lightweight VL models, UI for uncertainty explanations and user choice.
- Dependencies:
- On-device compute; privacy-aware scene capture.
- Bold: Digital-twin–aware CLASH for operations optimization (industrial, building management)
- What: Fuse live SLAM with digital twins to constrain search, provide semantics, and reduce ambiguity in long-horizon tasks.
- What’s needed: Robust twin alignment, semantic API between RSMP and twin, CP recalibration when twins are stale.
- Dependencies:
- Up-to-date BIM/twin models; API and governance.
- Bold: Navigation analytics and CP lifecycle management platforms (software, DevOps for autonomy)
- What: Products to monitor coverage, recalibrate thresholds, and trace CoT outcomes over time to mitigate drift.
- What’s needed: Tooling for CP diagnostics, automated calibration data curation, alerting when miscoverage rises.
- Dependencies:
- MLOps integration; data governance.
Cross-cutting assumptions and constraints
- Sensor stack: Real-world deployment assumes 2D LiDAR for waypoint generation and panoramic RGB for PVP; if either is missing, substitute pipelines or sensor fusion are required.
- Compute: Full-strength RLMR (e.g., Qwen2.5-VL-72B) typically needs multi-GPU servers; practical deployments may need distilled or cloud-hosted variants with strong privacy controls.
- Conformal prediction: Calibration relies on data that is exchangeable with deployment data; distribution shifts reduce guarantees and necessitate periodic recalibration.
- Safety and compliance: CoT logs and CP metrics support explainability but must be paired with physical safety constraints, escalation policies, and data privacy measures.
- Domain shift: RSMP causal adjustments mitigate spurious correlations but still benefit from in-domain validation and, when feasible, light fine-tuning.
Glossary
- Aleatoric uncertainty: Uncertainty arising from inherent noise in observations or data. "Although capable of capturing both aleatoric and epistemic uncertainty, these methods require model modification, retraining, and ground-truth labels for supervision."
- Attention prompting: A technique that steers model attention to relevant visual or textual regions to improve reasoning. "Our design is theoretically motivated by recent advances in attention prompting~\cite{yu2024attention}, which demonstrate that explicit visual prompts or region-wise masking can steer the attention distribution of large vision-LLMs and improve spatial reasoning."
- Back-door Adjustment (BA): A causal inference method that controls for observed confounders to estimate causal effects. "Back-door Adjustment (BA) is used for observable confounders ."
- Calibration set: A held-out dataset used to calibrate confidence thresholds in conformal prediction. "We randomly sample 50\% of the training data as a calibration set ."
- Chain-of-thought (CoT) prompting: A prompting strategy that elicits step-by-step reasoning from LLMs. "Instead, we apply chain-of-thought (CoT) prompting~\cite{wei2022chain} to enhance reasoning and interpretability."
- Conformal prediction (CP): A distribution-free framework that provides calibrated confidence sets with coverage guarantees. "In contrast, we adopt conformal prediction (CP)~\cite{shafer2008tutorial,huang2024conformal} for uncertainty estimation."
- Conformity threshold: The quantile-based threshold on nonconformity scores used to construct prediction sets in CP. "the -quantile of the calibration scores is computed to obtain the conformity threshold :"
- Coverage guarantees: Formal assurances that the prediction set contains the true label with a specified probability. "provides statistically calibrated confidence measures with formal coverage guarantees"
- DDPPO: A reinforcement learning algorithm for point-goal navigation using distributed proximal policy optimization. "we adopt DDPPO~\cite{wijmansdd2019ddppo}, an end-to-end policy that maps RGB-D inputs and goals to actions, improving obstacle avoidance and deadlock handling in simulation."
- Deadlock recovery: The capability of a navigation system to escape from states where progress halts due to obstacles or local minima. "which demonstrates robust obstacle avoidance and deadlock recovery."
- do-operator: A causal inference operator that simulates interventions to distinguish causation from correlation. "Causal inference introduces the do-operator to model interventional reasoning and decouple such entangled effects."
- Egocentric views: First-person visual observations aligned with the agent’s perspective. "research has since shifted to continuous settings (VLN-CE)~\cite{krantz_beyond_2020}, where agents perceive egocentric views and execute low-level motor commands."
- Epistemic uncertainty: Uncertainty stemming from limited knowledge or model parameters, reducible with more data. "Although capable of capturing both aleatoric and epistemic uncertainty, these methods require model modification, retraining, and ground-truth labels for supervision."
- Equirectangular panorama: A 360° image projection where latitude and longitude map linearly to a rectangle. "we observe that the lateral edges of the equirectangular panorama correspond to the agent’s backward view"
- Evidential modeling: Methods that learn to predict uncertainty and evidence using specialized network heads or distributions. "Other methods leverage auxiliary-head or evidential modeling to learn additional network parameters for predicting confidence scores"
- Front-door Adjustment (FA): A causal technique using mediator variables to identify causal effects despite unobserved confounders. "Front-door Adjustment (FA) addresses unobservable confounders by introducing a mediator "
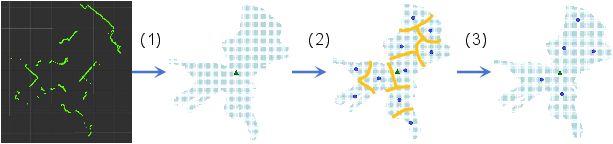
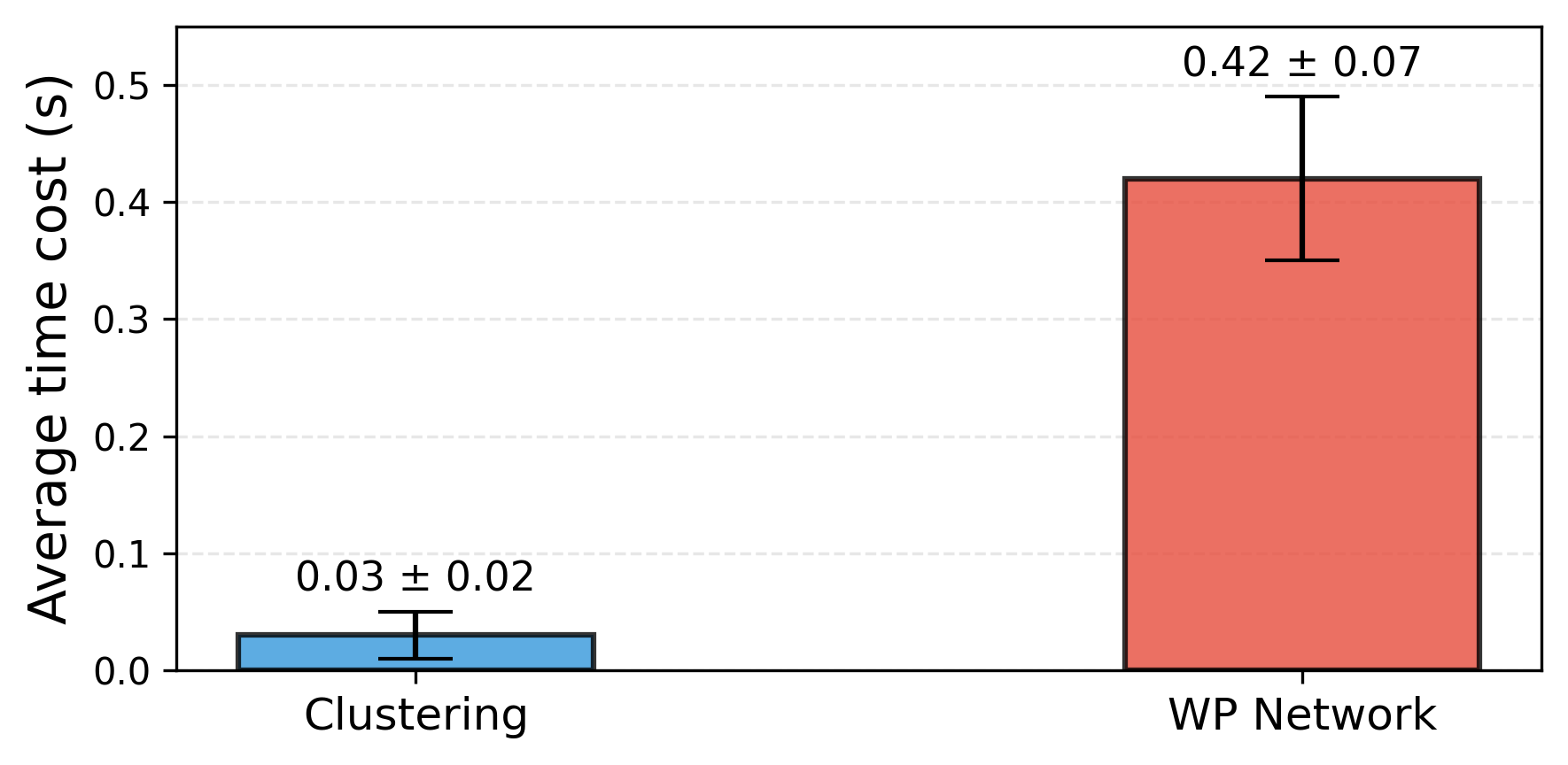
- K-means clustering: An unsupervised algorithm that partitions data into K clusters by minimizing within-cluster variance. "we propose a LiDAR-based clustering method for waypoint generation. This training-free approach applies K-means clustering over LiDAR cost maps to extract traversable candidates."
- LiDAR: A laser-based sensing technology that measures distances to build maps and detect obstacles. "we design a LiDAR-based clustering module for generating navigable waypoints"
- LiDAR-based clustering method: A training-free approach that clusters navigable points from LiDAR cost maps to produce waypoints. "we propose a LiDAR-based clustering method for waypoint generation."
- Mediator: An intermediate variable on a causal path used to identify causal effects via front-door adjustment. "by introducing a mediator that lies on the causal path ."
- Miscoverage rate: The allowed probability that a conformal prediction set fails to include the true label. " is a user-specified miscoverage rate (i.e., the allowed probability of the prediction set not containing the true action)."
- Multimodal LLMs (MLLMs): Large models that jointly process vision and language for cross-modal reasoning. "multimodal LLMs (MLLMs)~\cite{Qwen2.5-VL,wang2024qwen2,chen2024internvl}, pretrained on large-scale image–text datasets, have exhibited strong cross-modal reasoning abilities."
- Navigation Error (NE): A metric measuring the distance between the agent’s stop location and the goal. "Navigation Error (NE) calculates the distance (m) between the predicted and actual stop locations."
- Non-maximum suppression (NMS): A post-processing step that removes redundant detections by retaining only local maxima. "Finally, non-maximum suppression (NMS) is applied to the heatmap to extract the top-P candidate waypoints."
- Nonconformity score: A measure of how atypical a prediction is relative to calibration data in CP. "A nonconformity score is defined as for each example in the calibration set."
- Occupancy cost map: A 2D grid map encoding obstacle proximity and traversability from range sensor data. "A 2D occupancy cost map is first constructed from LiDAR scans, encoding obstacle proximity to indicate traversability."
- Oracle Success Rate (OSR): The fraction of trajectories that pass near the goal, regardless of the final stop action. "Oracle Success Rate (OSR) determines the frequency with which any point on the predicted path is within a certain distance of the goal."
- Panoramic Visual Prompt (PVP): A 360° visual input format used to provide holistic spatial context to an MLLM. "An illustration of PVP and the masking effect is shown in Fig.~\ref{fig_pwvp}."
- Panoramic visual prompting with chain-of-thought reasoning (PVP-CoT): A prompting scheme combining 360° visual context with stepwise reasoning for spatial tasks. "we propose the panoramic visual prompting with chain-of-thought reasoning (PVP-CoT)"
- Partially Observable Markov Decision Process (POMDP): A formalism for decision-making under uncertainty with incomplete state observability. "VLN is a sequential decision-making problem that can be formulated as a partially observable Markov decision process (POMDP)."
- Point-goal policy: A navigation strategy that maps sensor inputs and goal coordinates directly to low-level actions. "we replace the rule-based controller with a fully learnable point-goal policy"
- Prediction set: The set of labels/actions deemed plausible under CP, guaranteed to contain the true label with high probability. "CP constructs a prediction set "
- Reactive Small-Model Planner (RSMP): A compact, task-specialized planner that produces fast navigation decisions. "combines a Reactive Small-Model Planner (RSMP) with a Reflective Large-Model Reasoner (RLMR)."
- Reflective Large-Model Reasoner (RLMR): An MLLM-based component that provides interpretable, high-level reasoning and decisions. "combines a Reactive Small-Model Planner (RSMP) with a Reflective Large-Model Reasoner (RLMR)."
- ROS move_base: A ROS navigation stack component for path planning and execution in real-world robots. "we adopt an online SLAM-based pipeline using ROS move_base for waypoint navigation."
- ROS TF tree: The ROS transform framework organizing coordinate frames and their spatial relationships. "Waypoint coordinates are recorded in both the robot's local and global frames using the ROS TF tree."
- Semi-transparent mask: A visual prompt technique that attenuates less relevant regions in a panorama to guide attention. "we introduce a semi-transparent mask that attenuates the visual saliency of rear-view regions while preserving global scene continuity."
- SLAM-based controller: A navigation controller leveraging Simultaneous Localization and Mapping for robust real-world execution. "pair it with an online SLAM-based local controller."
- Success Rate weighted by Inverse Path Length (SPL): A metric combining success and trajectory efficiency. "Success Rate weighted by Inverse Path Length (SPL) measures navigation effectiveness by combining success rate with the length of the route."
- Trajectory Length (TL): The total path length traveled by the agent in meters. "Trajectory Length (TL) presents the length (m) of the navigation trajectory."
- Uncertainty-aware Collaboration Mechanism (UCM): A decision fusion strategy that adapts model weighting based on uncertainty. "We further introduce an uncertainty-aware collaboration mechanism (UCM) that adaptively fuses decisions from both models."
- Vision-and-Language Navigation (VLN): A task where agents follow natural language instructions to navigate environments. "Vision-and-Language Navigation (VLN) requires robots to follow natural language instructions and navigate complex environments without prior maps."
- VLN-CE: The continuous VLN setting where agents operate with low-level actions in fine-grained 3D space. "research has since shifted to continuous settings (VLN-CE)~\cite{krantz_beyond_2020}"
Collections
Sign up for free to add this paper to one or more collections.

