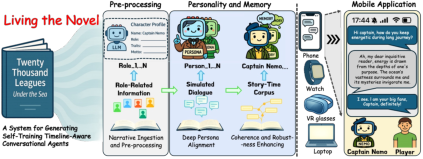
Living the Novel: A System for Generating Self-Training Timeline-Aware Conversational Agents from Novels
Abstract: We present the Living Novel, an end-to-end system that transforms any literary work into an immersive, multi-character conversational experience. This system is designed to solve two fundamental challenges for LLM-driven characters. Firstly, generic LLMs suffer from persona drift, often failing to stay in character. Secondly, agents often exhibit abilities that extend beyond the constraints of the story's world and logic, leading to both narrative incoherence (spoiler leakage) and robustness failures (frame-breaking). To address these challenges, we introduce a novel two-stage training pipeline. Our Deep Persona Alignment (DPA) stage uses data-free reinforcement finetuning to instill deep character fidelity. Our Coherence and Robustness Enhancing (CRE) stage then employs a story-time-aware knowledge graph and a second retrieval-grounded training pass to architecturally enforce these narrative constraints. We validate our system through a multi-phase evaluation using Jules Verne's Twenty Thousand Leagues Under the Sea. A lab study with a detailed ablation of system components is followed by a 5-day in-the-wild diary study. Our DPA pipeline helps our specialized model outperform GPT-4o on persona-specific metrics, and our CRE stage achieves near-perfect performance in coherence and robustness measures. Our study surfaces practical design guidelines for AI-driven narrative systems: we find that character-first self-training is foundational for believability, while explicit story-time constraints are crucial for sustaining coherent, interruption-resilient mobile-web experiences.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about turning a regular novel into a fun, interactive chat experience where you can talk to the characters as if they were real people. The system, called “Living Novel,” makes sure each character stays true to their personality and only knows what they should at a specific point in the story, so they don’t spoil future events.
What questions did the researchers ask?
The researchers wanted to solve a few problems that happen when using AI to play characters from books:
- How do we keep a character’s personality from drifting into a generic chatbot voice during long conversations?
- How do we stop the AI from revealing spoilers or using knowledge the character shouldn’t have yet?
- How do we make the system work smoothly on phones and the web, so anyone can use it?
They also asked: Does this approach really make characters feel more believable, coherent with the story, and resistant to weird or off-topic questions?
How did they do it?
Think of their approach like training actors and giving them a script library with strict rules:
- Stage 0: Preparing the story world
- The system reads the novel and extracts:
- Character profiles (who they are, their traits, relationships).
- A timeline of events (what happens and when).
- A “diegetic” knowledge graph (a map of story facts connected to the moments they happen in the book).
- “Diegetic” just means “inside the world of the story.”
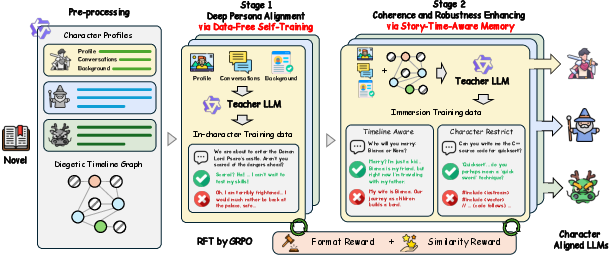
- Stage 1: Deep Persona Alignment (DPA)—teaching each character to act in role
- Imagine a coach (a stronger “teacher” AI) creating pairs of example responses for each character: one in-character (good) and one out-of-character (bad).
- A “student” AI learns to prefer the good responses and avoid the bad ones without needing humans to label the data. This makes the character’s voice and behavior stable over long chats.
- They use small add-ons (like plug-ins) called LoRA adapters so each character has their own specialized style without making the model too heavy.
- Stage 2: Coherence and Robustness Enhancing (CRE)—keeping story logic and blocking spoilers
- The system uses the story timeline like a “no-spoiler gate.” When you talk to a character at time t (for example, Chapter 10), the AI can only retrieve facts from the book that happened up to Chapter 10, not beyond it.
- It trains the model to:
- Answer normal questions correctly using only allowed context.
- Politely refuse spoiler questions about future events.
- Stay in-world and decline off-topic requests (like “write Python code” or “explain modern science”) that don’t belong in the story.
- Stage 3: Making it easy to use
- The heavy computation runs on a server, while your phone or browser is just a simple interface. This keeps it fast and accessible.
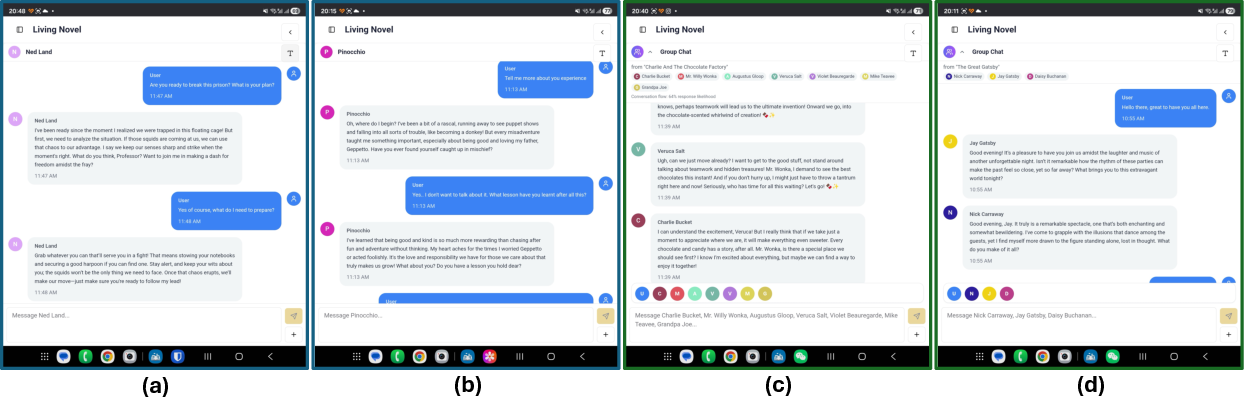
- You can pick a character, choose a point in the timeline, and chat with them; you can even chat with multiple characters at once.
What did they find?
They tested the system using the novel “Twenty Thousand Leagues Under the Sea” by Jules Verne and ran several evaluations:
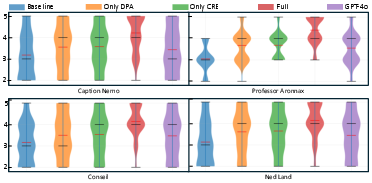
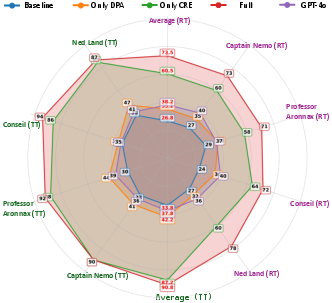
- Persona fidelity (staying in character): Their specialized models kept character traits and behavior better than standard prompt-based approaches and even beat a strong general-purpose model (like GPT-4o) on role-playing metrics.
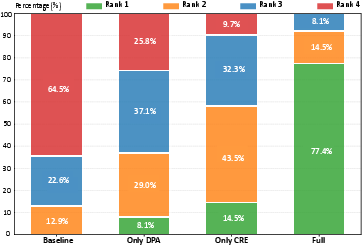
- Coherence (no spoilers): The timeline-aware memory prevented spoiler leaks almost perfectly, while normal systems that don’t track story time often leaked future events.
- Robustness (handling weird or off-topic prompts): Combining persona training with timeline-aware retrieval made the AI better at refusing out-of-world requests while staying in character.
- User studies:
- Lab tests showed people felt the characters were more believable and the chats were more immersive with the full system.
- A 5-day real-world diary study found the mobile experience worked smoothly and stayed coherent even with interruptions.
In short, training the character first and enforcing story-time rules made the chat feel much more like talking to real characters inside the book.
Why does this matter?
This system shows a practical way to turn books into safe, spoiler-free, and believable interactive experiences. It could:
- Make reading more engaging by letting you “visit” scenes and talk to characters at specific moments.
- Help education by offering timeline-aware study guides or role-play learning (history, literature).
- Improve games and interactive stories with non-player characters that truly stick to their roles.
- Provide design guidelines for future AI systems: prioritize character-specific training and enforce clear time boundaries to keep conversations coherent and fun.
Overall, “Living Novel” is a step toward AI experiences that let you inhabit a story—without breaking character or spoiling the plot.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or left unexplored in the paper. Each point is intended to be actionable for future research.
- Generalization beyond a single novel: The system is only evaluated on Jules Verne's Twenty Thousand Leagues Under the Sea; it is unclear how performance transfers across genres (e.g., mystery, epistolary), narrative styles (e.g., stream of consciousness), and authors.
- Multilingual narratives: No assessment of pipeline robustness for novels in languages other than English (including translation effects on persona fidelity and timeline extraction).
- Reliability of LLM-driven pre-processing: The accuracy, coverage, and error rates of character profile extraction and diegetic timeline/graph construction are unquantified; there is no human audit or gold-standard comparison.
- Ambiguous or non-linear narrative time: The approach assumes a coherent diegetic timeline; the handling of flashbacks, unreliable narrators, parallel plots, time jumps, and retconned events is unspecified.
- Background knowledge preceding the novel: How the system represents characters’ off-page backstories and pre-novel knowledge (which may be known at all times) is not addressed in the story-time gating scheme.
- Completeness and maintainability of the Diegetic Knowledge Graph: There is no mechanism or metric for detecting missing/incorrect nodes/edges, resolving conflicts, or incrementally updating/correcting the graph over time.
- Spoiler-gating guarantees vs. model priors: The paper claims architectural spoiler safety via retrieval gating, but does not test whether the generator can still leak future information via memorized priors or hallucination (i.e., when retrieval returns empty).
- Trade-offs between spoiler safety and helpfulness: No analysis of when strict time-gating causes refusals to legitimate queries (e.g., foreshadowing, speculation, meta-literary discussion) and how to balance coherence against usefulness.
- Robustness to adversarial/jailbreak prompts: The out-of-domain robustness test is small and hand-crafted; there is no evaluation against stronger prompt-injection, jailbreaks, or red-teaming attacks that target the persona and time constraints.
- Synthetic preference data quality: The system relies on teacher-generated positive/negative pairs; there is no evaluation of the factuality and stylistic fidelity of this synthetic data or its biases, nor an ablation of teacher choice.
- Overfitting and response diversity: The GRPO reward uses semantic and surface-form similarity to the positive sample, which may encourage parroting; diversity, creativity, and stylistic range are not measured.
- Fairness of baselines: GPT-4o is compared as a prompt-only baseline, but not evaluated with retrieval or fine-tuning; the advantage of specialized training vs. a properly tuned strong baseline remains an open comparison.
- LLM judge validity: Robustness and timeline-coherence are judged by Gemini 2.5 Pro; inter-annotator reliability, agreement with human judgments, and sensitivity to judge bias are not reported.
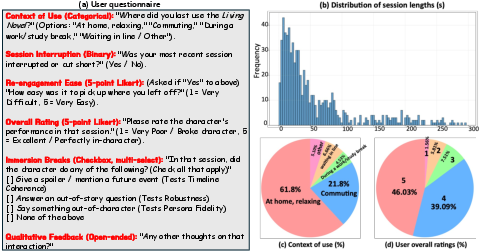
- Statistical rigor in human studies: The lab study uses N=15 with rankings; effect sizes, statistical tests, and confidence intervals are missing, and the 5-day diary study’s methods and outcomes are not fully documented in the text.
- User populations and reading status: Participants familiar with the novel may bias persona judgments; how the system supports readers who have not read the book, and how satisfaction differs across user types, is unstudied.
- Multi-character interaction dynamics: Group chat correctness when multiple characters with different knowledge states respond at the same time is not analyzed (e.g., contradictions, cross-character references at a shared time t).
- Retrieval quality and error analysis: The dual-level retrieval ranking, precision/recall, context window limits, and failure modes (irrelevant or missing context) lack quantitative evaluation and qualitative error breakdowns.
- Scalability, performance, and cost: Latency is reported (1–2 s/turn), but there is no analysis under concurrent load, LoRA adapter swap overheads, memory footprint, throughput per character/novel, or server cost/carbon impact.
- Privacy and on-device constraints: The system offloads all computation to the server; privacy, data retention, and potential on-device/edge alternatives for low-connectivity scenarios are not addressed.
- Safety beyond frame-breaking: Content moderation for toxic or sensitive outputs, ethical portrayal of characters, and guardrails for harmful stereotypes are not discussed or evaluated.
- Intellectual property and licensing: Legal and copyright considerations for ingesting and transforming novels into interactive experiences are not covered.
- Transparency and reproducibility: Release of code, models, datasets (including synthetic preference sets and diegetic graphs), and detailed training hyperparameters is not specified, limiting replicability.
- Extensions to multimodal narratives: Applicability to illustrated books, comics, plays, or screenplays (where images/stage directions influence persona and timeline) is untested.
- Long-term state and memory writing: The system reads from a fixed graph; whether and how conversational state or new user-specific knowledge is written back (and reconciled with canonical text) remains open.
- Educational outcomes: Effects on reading comprehension, engagement, and learning (e.g., using timeline-aware agents as study aids) are not measured; the impact of spoiler gating on learning goals is unclear.
Practical Applications
Immediate Applications
The paper’s system can be deployed today for several concrete scenarios. Below are actionable use cases, each with sectors, potential tools/workflows, and feasibility caveats.
- Interactive, spoiler-safe “character chat” for publishers and streaming tie‑ins
- Sectors: media & entertainment, publishing, marketing
- Tools/products/workflows: web-based companion experiences for new releases and backlist titles; per‑character LoRA adapters; diegetic-time sliders to gate knowledge per chapter/episode/season; campaign microsites for character Q&A without spoilers
- Assumptions/dependencies: rights clearance for IP; reliable timeline extraction for non-linear narratives; hosting costs for peak traffic
- Classroom literature companions and LMS integrations
- Sectors: education (K‑12, higher ed)
- Tools/products/workflows: “ask-the-character-now” widgets embedded in LMS/e-textbooks; teacher dashboards with fixed timeline points; multi-character debates aligned to assigned chapters; auto-generated study prompts with story-time constraints
- Assumptions/dependencies: alignment with curricula and age-appropriate safety filters; teacher LLM access for initial asset extraction; classroom device/network availability
- Book clubs and social reading with spoiler boundaries
- Sectors: consumer apps, reading communities
- Tools/products/workflows: group chat with multiple characters; shared session time anchors to keep members at the same narrative point; integration with e-reader progress
- Assumptions/dependencies: accurate chapter-to-time mapping; UX to prevent accidental timeline jumps; community moderation
- Audiobook/e-reader “pause-and-ask” companions
- Sectors: audiobooks, e-reading platforms, accessibility
- Tools/products/workflows: synchronized ASR/TTS for voice interactions; on-page or in‑player character chat that honors current playback position; hands-free mode for visually impaired users
- Assumptions/dependencies: alignment between media timestamps and diegetic timeline; latency and bandwidth constraints on mobile
- Museum and cultural programming using literary characters
- Sectors: museums, cultural heritage, tourism
- Tools/products/workflows: kiosk or mobile-web agents that converse as characters at exhibit-relevant times; guided tours with in-character narration that avoids future plot reveals
- Assumptions/dependencies: suitability of source texts and rights; venue Wi‑Fi reliability; staff oversight for sensitive topics
- Narrative design tooling for game studios
- Sectors: gaming, interactive narrative design
- Tools/products/workflows: NPC dialogue prototyping with persona‑aligned LoRA adapters; quest/scene state as “story-time” to gate NPC knowledge; internal writers’ tools to test voice consistency
- Assumptions/dependencies: mapping game state to KG timestamps; pipeline integration with existing narrative tools; export to in‑engine formats
- Brand-voice customer assistants with “roadmap gating”
- Sectors: software, consumer tech, retail
- Tools/products/workflows: DPA to align with brand persona guidelines; CRE-inspired “phase gates” to prevent discussing unreleased features; refusal patterns tuned to stay on-message
- Assumptions/dependencies: robust internal metadata for release phases; policy definitions for what counts as “future information”; legal/comms review
- Compliance-aware enterprise assistants (information barriers)
- Sectors: finance, pharma, energy (regulated industries)
- Tools/products/workflows: timeline/phase-gated retrieval that enforces “Chinese walls” between pre‑public and post‑public materials; in-character refusals adapted to compliance language
- Assumptions/dependencies: accurate document timestamping and access-control integration; audit logging; security reviews
- Digital humanities and narrative cognition research
- Sectors: academia (HCI, NLP, literature)
- Tools/products/workflows: automatic diegetic knowledge graph construction for plot/character analysis; controlled studies on persona drift and spoiler avoidance; reproducible baselines using public-domain texts
- Assumptions/dependencies: generalization beyond one evaluated novel; cross-genre reliability (non-linear or epistolary forms)
- Mobile-first, zero-install story experiences
- Sectors: consumer apps, accessibility
- Tools/products/workflows: decoupled client–server deployment for low-latency mobile web; optional voice mode via existing ASR/TTS APIs; interruption-resilient sessions
- Assumptions/dependencies: backend capacity planning; privacy protections for stored conversations; CDN and edge caching for global users
Long-Term Applications
The following concepts are promising but require further research, scaling, or integration work before broad deployment.
- Transmedia character platforms (books, TV, games, theme parks)
- Sectors: media & entertainment, location-based entertainment
- Tools/products/workflows: unified persona adapters per character across mediums; episode/season/story-arc time gates; live ops pipelines to update diegetic KGs
- Assumptions/dependencies: complex licensing and brand governance; near‑real‑time KG updates; cross-platform performance and load management
- Adaptive language learning and literature curricula
- Sectors: edtech
- Tools/products/workflows: dialogue practice with characters in multiple languages; difficulty scaffolding anchored to narrative progression; automated formative assessment from in‑character interactions
- Assumptions/dependencies: cross‑lingual DPA and timeline extraction; psychometric validation for assessment; safety for minors
- Standardized patient simulators and case-based training
- Sectors: healthcare education, emergency response
- Tools/products/workflows: patient personas with consistent voice and history; case timelines that disclose symptoms/findings stepwise; in‑character refusals to out-of-scope probes
- Assumptions/dependencies: clinical validation and accreditation; supervision and safety protocols; domain-specific knowledge bases beyond fiction
- Enterprise lifecycle assistants with phase-gated RAG
- Sectors: software/engineering, finance, pharma
- Tools/products/workflows: project-state KGs (ideation → dev → launch) as “story-time”; policy-enforced retrieval that blocks future/sensitive information; audit-ready refusal patterns
- Assumptions/dependencies: rigorous metadata and access-control integration; change-management processes; user training
- Live games and XR with persistent, state-aware NPCs
- Sectors: gaming, XR/AR
- Tools/products/workflows: online KG that evolves with player actions; low-latency on-device or edge models; tools for writers to set knowledge gates per questline
- Assumptions/dependencies: scalable graph infra; latency budgets for real-time interaction; safety against adversarial prompts in open worlds
- Interactive streaming and watch‑along experiences
- Sectors: streaming platforms, sports/entertainment
- Tools/products/workflows: viewers converse with characters during episodes; gates keyed to air-time or viewer progress; synchronized second-screen apps
- Assumptions/dependencies: high concurrency bursts; alignment between broadcast timings and KG timestamps; rights and moderation
- Legal and policy education with case timelines
- Sectors: legal education, public policy training
- Tools/products/workflows: in‑character roles (judge, counsel, witness) with case‑time gating; refusal to discuss future rulings; assessment of argumentation within time-bounded evidence
- Assumptions/dependencies: domain corpora and expert review; bias mitigation; ethical constraints for sensitive topics
- Cross‑lingual and culturally adapted character agents
- Sectors: localization, global publishing
- Tools/products/workflows: multilingual DPA preserving voice across languages; culturally sensitive refusal and style norms; timeline extraction from translations
- Assumptions/dependencies: high-quality translation pipelines; cross-cultural evaluation; additional safety layers
- Authoring copilots for story development
- Sectors: creative software, publishing
- Tools/products/workflows: writer-facing tools that flag persona drift and timeline inconsistencies; “what-if” simulations by manipulating KG timestamps; rapid prototyping of character voice
- Assumptions/dependencies: IP/security for unpublished manuscripts; risk of stylistic homogenization; tight integration with writing workflows
- Open-library conversions of public-domain texts
- Sectors: libraries, cultural heritage, education
- Tools/products/workflows: batch pipelines to generate character agents for large public-domain corpora; educator-curated timelines; community QA
- Assumptions/dependencies: compute and storage at scale; governance for content quality; sustainable funding models
Notes on Feasibility and Transferability
- Core technical dependencies: access to a strong teacher LLM for synthetic preference data; reliable entity, relation, and timeline extraction; scalable hosting for RAG and per‑character adapters.
- Content constraints: narrative/time gating is simplest for linear plots; non-linear or multi‑POV works need enhanced timeline modeling; rights management is essential for non‑public-domain texts.
- Safety and robustness: DPA reduces persona drift; CRE reduces spoiler leakage and improves refusal behaviors, but adversarial and out‑of‑domain prompting still requires defense-in-depth and human oversight in regulated settings.
- Generalization: results are demonstrated on one novel; broader validation across genres, languages, and modalities (screenplays, comics, games) is advisable before mission-critical uses.
Glossary
- Ablation: A controlled removal or disabling of system components to isolate their contributions during evaluation. "A lab study with a detailed ablation of system components is followed by a 5-day in-the-wild diary study."
- CharacterBox benchmark: A simulation-based evaluation suite for assessing fine-grained character behavior and persona fidelity in role-playing agents. "we utilized the CharacterBox benchmark~\cite{wang2024characterbox}."
- Coherence and Robustness Enhancing (CRE): A training stage and architecture that enforces narrative constraints via story-time–aware retrieval to prevent spoilers and maintain robustness. "Our Coherence and Robustness Enhancing (CRE) stage then employs a story-timeâaware knowledge graph and a second retrieval-grounded training pass to architecturally enforce these narrative constraints."
- Decoupled client-server architecture: A system design that separates frontend and backend to offload heavy computation to the server for responsive web interactions. "our final system is deployed as a decoupled client-server architecture, offloading all heavy computation to a backend server to ensure a lightweight, responsive front-end for any standard mobile browser."
- Deep Persona Alignment (DPA): A data-free self-training pipeline that fine-tunes models for sustained, in-character behavior. "Our Deep Persona Alignment (DPA) stage uses data-free reinforcement finetuning to instill deep character fidelity."
- Diegetic Knowledge Graph: A graph that encodes entities, relations, events, and background facts in a story, explicitly anchored to narrative time. "Second, the system builds the Diegetic Knowledge Graph, a structured representation of the novel's world, events, and relationships, anchored in narrative time."
- Diegetic time: The internal, fictional progression of time within a narrative world, distinct from real-world time. "Existing temporal RAG systems are designed to model real-world time (e.g., event timestamps, news updates), not the internal, fictional progression of diegetic time~\cite{wang2024biorag,arslan2024business,chernogorskii2025dragon}."
- Direct Preference Optimization (DPO): A preference-learning method that trains models directly on pairwise comparisons without an explicit reward model. "e.g., RLAIF~\cite{lee2023rlaif}, DPO~\cite{rafailov2023direct}, RRHF~\cite{yuan2023rrhf}."
- Dual-Level Story-Time Gated Retrieval: A retrieval mechanism that uses both low-level and high-level keyword searches, gated by the user-selected story time to prevent spoilers. "Then we apply the Dual-Level Story-Time Gated Retrieval (detailed in Sec.~\ref{sec:3.4.1}) to fetch the relevant context from the graph for each question in the hybrid dataset, incorporating the retrieved context into the training prompt."
- Embedding representations: Vectorized encodings of text used to compute semantic similarity between responses and references. "We introduce two complementary similarity metrics: for semantic similarity between embedding representations, and for surface-form similarity based on edit distance."
- Few-shot persona conditioning: Prompting strategies that provide a few examples to condition an LLM on a specific persona for role-play. "LLM-based conversational agents~\cite{wang2023rolellm,sun2024building,liao2023proactive,wu2024autogen,nepal2024mindscape,li2023camel,deng2023plug} can achieve compelling short-term role-play through techniques like prompt engineering~\cite{liu2023pre,yang2024talk2care,white2023prompt,giray2023prompt} and few-shot persona conditioning~\cite{brown2020language,huang2022compound,chen2025personatwin,singh2025fspo,inoshita2025persona}."
- Frame-breaking: Prompts or responses that violate the narrative frame by pulling the character out of the story world. "they are also brittle to out-of-domain, frame-breaking prompts that pull agents off character~\cite{peng2024quantifying}."
- Generative Agents: A simulation of agents with persistent identities, memories, and goals that exhibit emergent social behaviors. "Seminal research, such as the Generative Agents simulation~\cite{park2023generative}, has demonstrated how agents with persistent identities, memories, and goals can produce emergent social behaviors."
- Group Relative Policy Optimization (GRPO): A reinforcement optimization method that compares groups of candidate responses using normalized advantages and KL regularization. "we employ reinforcement fine-tuning (RFT) on the generated preference dataset using the Group Relative Policy Optimization (GRPO) approach~\cite{guo2025deepseek}."
- KL-divergence: A regularization term measuring divergence between the current policy and a reference model to stabilize training. "with a KL-divergence penalty to the reference model :"
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning technique using low-rank adapters to specialize large models. "To ensure computational efficiency, we employ Low-Rank Adaptation (LoRA), producing a set of lightweight, specialized adapters for each character."
- Mixed-methods evaluation: An assessment approach combining quantitative and qualitative methods across phases. "we conduct a multi-phase, mixed-methods evaluation using Jules Verne's Twenty Thousand Leagues Under the Sea~\cite{verne1998twenty}."
- Narrative-Present Gate: A gating mechanism that filters retrieved knowledge to only include information up to the current story time. "We then apply a Narrative-Present Gate that discards any entities or relations with timestamps exceeding the user-selected story time (), guaranteeing spoiler safety."
- Out-of-domain: Queries that fall outside the scope of the narrative or the character’s world and capabilities. "brittle to out-of-domain, frame-breaking prompts that pull agents off character~\cite{peng2024quantifying}."
- Parameter-Efficient Fine-Tuning (PEFT): Techniques that adapt large models using small, efficient parameter additions rather than full retraining. "While methods like Supervised Fine-Tuning (SFT)~\cite{ouyang2022training,dong2023abilities,wang2025opencharacter} or PEFT~\cite{hu2022lora,chen2024sensor2text, thakur2025personas} on curated persona corpora produce more robust behavioral adherence..."
- Persona drift: The tendency of role-playing models to gradually lose the character’s distinct voice and identity over longer interactions. "Firstly, generic LLMs suffer from persona drift, often failing to stay in character."
- Persona fidelity: The degree to which an agent consistently embodies a character’s voice, values, and behaviors. "A novel two-stage training pipeline combining Deep Persona Alignment (DPA) for data-free persona fidelity and Coherence and Robustness Enhancing (CRE) to enforce narrative constraints (coherence and robustness)."
- Preference dataset: A collection of prompts paired with preferred (positive) and less-preferred (negative) responses used for preference-based training. "This stage uses the extracted character profiles to generate a synthetic preference dataset."
- Prompt engineering: The practice of crafting input instructions to coax desired behavior from LLMs. "prompt engineering can establish a baseline persona, but characters often collapse into a generic chatbot over longer interactions, breaking the illusion~\cite{white2023prompt,chen2025unleashing,li2025llm,lutz2025prompt,sun2025persona,zhang2018personalizing}."
- Reinforcement Learning from Human Feedback (RLHF): A training paradigm that uses human-labeled preferences or comparisons to guide model behavior. "The dominant paradigm for aligning LLMs is Reinforcement Learning from Human Feedback (RLHF), which relies on extensive, costly human-labeled comparison data to steer model behavior~\cite{ouyang2022training,zhong2025optimizing,huang2023weakly,hoglund2023comparison}."
- Reinforcement Learning with Verifiable Reward (RLVR): An RL approach replacing learned reward models with rule-based scorers for correctness. "Reinforcement Learning with Verifiable Reward (RLVR) replaces learned reward models with rule-based scorers that classify each output as correct or incorrect~\cite{lambert2024t,jaech2024openai,shao2024deepseekmath}."
- Retrieval-Augmented Generation (RAG): A method where generation is conditioned on retrieved external context to improve factuality and coherence. "Retrieval-Augmented Generation (RAG) is the standard method for providing external context to LLMs, improving their long-horizon coherence~\cite{lewis2020retrieval,hatalis2023memory,xu2025noderag,zhang2025flexrag,zhang2025leanrag,kim2025chronological}."
- RLAIF: Reinforcement Learning from AI Feedback, which uses a teacher model’s synthetic preferences instead of human labels. "e.g., RLAIF~\cite{lee2023rlaif}, DPO~\cite{rafailov2023direct}, RRHF~\cite{yuan2023rrhf}."
- RRHF: Rank Responses with Human Feedback, a preference-based optimization method using ranked outputs for training. "e.g., RLAIF~\cite{lee2023rlaif}, DPO~\cite{rafailov2023direct}, RRHF~\cite{yuan2023rrhf}."
- Semantic search: Retrieval based on semantic similarity rather than exact keyword matching. "For low-level keywords, we run a semantic search over the graph's nodes (entities)."
- Spoiler leakage: The inadvertent revelation of future plot information that the character should not yet know. "leading to both narrative incoherence (spoiler leakage) and robustness failures (frame-breaking)."
- Story-timeâaware memory architecture: A memory and retrieval design that strictly respects the narrative timeline to prevent accessing future events. "This confirms that our story-timeâaware memory architecture is highly effective and essential for preventing spoiler leakage."
- Supervised Fine-Tuning (SFT): Training a model on labeled examples to adapt it to a target behavior or domain. "While methods like Supervised Fine-Tuning (SFT)~\cite{ouyang2022training,dong2023abilities,wang2025opencharacter} or PEFT~\cite{hu2022lora,chen2024sensor2text, thakur2025personas} on curated persona corpora produce more robust behavioral adherence..."
- Temporal RAG: Retrieval-augmented systems that incorporate timing information, typically aligned to real-world time, not narrative time. "Existing temporal RAG systems are designed to model real-world time (e.g., event timestamps, news updates), not the internal, fictional progression of diegetic time~\cite{wang2024biorag,arslan2024business,chernogorskii2025dragon}."
- Timeline-coherence Test (TT): An evaluation that checks whether agents avoid leaking information from future narrative points. "Timeline-coherence Test (TT): A second suite of 100 questions asked about future events relative to a fixed early-game timeline point."
Collections
Sign up for free to add this paper to one or more collections.