- The paper presents a comprehensive synthesis of methodologies for network inference and prediction, highlighting the synergy between statistical rigor and machine learning advances.
- It details challenges in network sampling and comparison, focusing on biases and limitations of traditional estimation techniques in complex systems.
- The review emphasizes unresolved issues in network reconstruction and dynamic prediction, calling for robust, scalable, and unified inferential frameworks.
Prediction and Inference in Complex Networks: A Technical Review
Introduction
The study of complex networks forms the backbone of structural and dynamical analysis in a broad array of real-world systems, from biological and social to economic and technological domains. The paper "Prediction and inference in complex networks: a brief review and perspectives" (2512.07439) provides a comprehensive synthesis of the methodological landscape underlying network inference and prediction. It elucidates how the pervasive challenges of incomplete, noisy, or indirect data acquisition necessitate robust inferential and predictive frameworks, underlining the continual need for principled statistical and machine-learning-based advancements.
The Duality of Inference and Prediction in Networks
Inference and prediction, while conceptually distinct, share intertwined aims in extracting actionable insights from partial and imperfect network data. Inference seeks to recover the global properties, latent variables, or unobservable structural features of networks using observed samples — a task complicated by dependency structures that violate i.i.d. assumptions. Prediction, on the other hand, targets anticipatory objectives such as forecasting future events, identifying missing or emergent links, and projecting system dynamics using observable patterns.
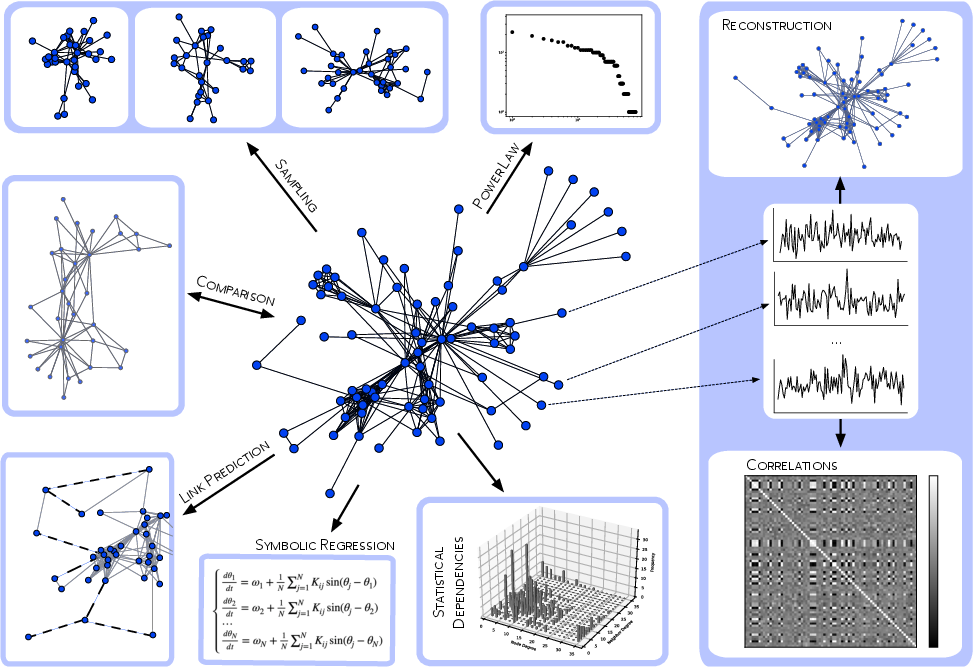
Figure 1: Key challenges in network inference and prediction; sampling, comparison, and link prediction use observed network structure, while techniques like symbolic regression, statistical dependency analysis, and network reconstruction leverage time series metadata.
The synergistic advancement of both domains is demonstrated by approaches such as graph neural networks and probabilistic graphical models, which enable latent representation learning and support predictions of attributes, link formation, or evolution, illustrating the narrowing conceptual divide.
Network Sampling: Structural Biases and Statistical Rigor
Network sampling is central to both empirical analysis and methodology development, given that comprehensive observation of large-scale networks is rarely feasible. The paper details how canonical sampling techniques — random node, random-walk, snowball, and edge-based sampling — privilege different structural motifs, introducing ascertainment biases that may skew inferential results by under- or over-representing network properties such as clustering, degree distribution, and community structure.
The lack of universal, unbiased sampling strategies amplifies the difficulty of statistical inference. Importantly, traditional estimation and hypothesis testing protocols carry limited validity for non-i.i.d. and highly dependent networked data. Progress is anticipated via the adaptation of MLE, information criteria, Bayesian updating, and robust resampling (bootstrap, jackknife), especially to augment inference reliability under incomplete or bias-prone observation regimes. However, optimal sampling tactics, minimal required subgraph sizes for accurate globally-informative inference, and methodologically robust evaluation metrics are all unresolved and important open research questions.
Network Comparison: Methodological Complexity
Meaningful comparison between networks underlies the elucidation of universal principles and system-specific behaviors. The non-trivial dependence of almost all structural metrics on system size and density complicates direct or naïve inter-network analysis. The review surveys a spectrum of comparison paradigms:
- Subgraph-based and embedding-based approaches: Effective if sampling is structurally unbiased, but challenge interpretability and robustness.
- Metaheuristic feature aggregation (e.g., genetic algorithms): Flexible but computationally intensive with weak theoretical guarantees.
- Spectral, information-theoretic, and taxonomy-based comparisons: Offer avenues for granularity and normalization, yet lack a unified statistical framework.
The paper notes recent interest in renormalization-group-inspired methodologies, which promise hierarchical multiscale analysis, but whose generalization remains hindered by a lack of geometric regularity and statistical homogeneity in empirical networks.
Link Prediction: Structural, Probabilistic, and Machine Learning Approaches
Link prediction constitutes a critical task with applications in bioinformatics, recommendation systems, and social network analytics. Methodologies range from local similarity indices and embedding-based latent-space models (e.g., Node2Vec, DeepWalk) to supervised ML-based classification and probabilistic generative models. Each strategy is contingent upon data characteristics and network properties, with key trade-offs between interpretability, generalizability, and computational tractability.
Hybrid approaches incorporating external/dynamic factors with advanced neural architectures and ensemble paradigms are identified as promising future directions. However, challenges remain in improving real-world predictive robustness, explainability, and integration of heterogeneous data sources, particularly under the high variability present in evolving social and biological systems.
Network Reconstruction from Time Series and Statistical Dependencies
Reconstructing network topology and quantifying statistical dependencies from time series data is a central inferential objective, essential for system diagnosis and understanding higher-order organization. The review distinguishes between:
- Topological reconstruction: Relies on simulated dynamics benchmarks and quantitative accuracy assessment against known ground-truths.
- Influence mapping: Extracts meaningful functional dependencies that may or may not correspond to physical connectivity (e.g., functional brain or climate networks).
Correlation-based measures are pervasively used but are vulnerable to confounding, indirect inference, and spurious associations. Bayesian inference and causal analysis (Granger causality, mutual information, transfer entropy) offer robust theoretical underpinnings but at considerable modeling and computational cost, predominantly restricting application to modest-sized systems. The development of scalable, assumption-agnostic causal inference and structure-learning algorithms for functional networks remains an important research priority.
Predictive Modeling of Dynamic Processes
The intrinsic relationship between network structure and system dynamics (e.g., epidemic, synchronization, cascade failures) provides the basis for structural prediction of dynamical outcomes. The potential of modern machine learning and symbolic regression approaches to yield interpretable, quantitatively accurate predictors of dynamic variables is highlighted. However, application beyond canonical processes remains nascent, and analytic, generalizable frameworks for broader classes of dynamics are largely undeveloped.
Quantification of Statistical Dependencies and Power Law Detection
Understanding assortativity, conditional degree distributions, and higher-order dependencies is crucial for the study of collective phenomena. Traditional estimators are sensitive to sample size, bias, and structural sparsity. The review identifies copula-based multivariate analysis as a theoretically appealing, yet practically unexplored, alternative for nonlinear, non-parametric dependence modeling.
Assessment of scale-free (power law) behavior in real networks is another contentious issue. The paper reiterates that empirical fits are often compromised by finite-size effects and data/sampling biases, resulting in possible overdiagnosis of power laws. Quantitative rigor in model selection and the relation of sampling protocol to inferred distributional properties remain as open topics demanding further attention.
Unresolved Directions and Theoretical Challenges
The paper raises several underdeveloped research frontiers:
- Community detection and pattern recognition: Despite the success of both exact and approximate inference protocols, challenges persist in uncovering and evaluating latent organizational patterns, particularly under uncertainty.
- Complex network structures: The incorporation of temporal, multilayer, multiplex, higher-order, directed, and weighted architecture in inferential and predictive methods is essential for real-world applicability, yet remains methodologically unfinished.
- Unified statistical foundation: There is a pressing need for integrative, theory-driven frameworks (e.g., Bayesian, information-theoretic, multivariate) that underpin all stages of inference and prediction in complex networks.
Conclusion
This review critically delineates the landscape and pressing challenges associated with prediction and inference in complex networks, emphasizing the methodological and theoretical demands imposed by incomplete, noisy, and indirect data. The synergy between statistical rigor and machine learning innovation is poised to yield continued advances, particularly in multiscale analysis, causal modeling, and structure-dynamics integration. Addressing the highlighted open problems—robust sampling, unbiased comparison, scalable causality, higher-order dependencies, and the extension to complex architectures—will be central for future developments in the empirical and theoretical analysis of complex systems.