- The paper introduces the Latency-Response Theory (LaRT) model that jointly evaluates LLMs using response accuracy and chain-of-thought (CoT) length.
- The methodology uses a probit link for accuracy and a log-normal distribution for CoT length, optimized via a SAEM algorithm with spectral initialization.
- The results demonstrate improved LLM ranking and predictive power by revealing a significant negative correlation between latent ability and latent speed on challenging datasets.
Latency-Response Theory Model: Evaluating LLMs
Introduction
The evaluation of LLMs has become increasingly complex with the advancement of various models across diverse tasks. Traditional evaluation methods primarily focus on response accuracy; however, they often fail to capture the nuances of model reasoning capabilities. The "Latency-Response Theory Model: Evaluating LLMs via Response Accuracy and Chain-of-Thought Length" (2512.07019) introduces a novel evaluation framework, Latency-Response Theory (LaRT), that integrates both response accuracy and chain-of-thought (CoT) length to assess LLMs comprehensively. This approach provides a more granular understanding of model performance, especially in complex reasoning tasks.
The Latency-Response Theory (LaRT) Framework
LaRT expands on the Item Response Theory (IRT) by incorporating CoT length as a critical metric. CoT length serves as an indicator of the reasoning process, akin to response time in psychometrics. The model introduces latent traits such as latent ability and latent speed, representing proficiency and reasoning process time, respectively. A significant aspect of LaRT is the correlation parameter between these traits, allowing for a nuanced interpretation of LLM capabilities.
LaRT employs a hierarchical structure, where the response accuracy is modeled using a probit link, while CoT length follows a log-normal distribution. This dual modeling captures both the endpoint (correctness) and the process (reasoning length) of LLM outputs. Such a comprehensive approach is crucial for accurately ranking LLMs and understanding their reasoning pathways.
Estimation and Algorithmic Innovations
A key challenge in the implementation of LaRT is the computational complexity involved in estimating population parameters and individual latent traits. To address this, the authors develop a stochastic approximation expectation-maximization (SAEM) algorithm optimized for the LaRT framework. This algorithm is enhanced by a data-driven initialization strategy derived from spectral methods, which improves the convergence and accuracy of parameter estimation.
The SAEM algorithm iteratively updates parameter estimates by leveraging Monte Carlo approximations, avoiding computationally expensive calculations while maintaining algorithmic stability. This approach ensures that the LaRT model can be efficiently scaled to large datasets typical in LLM evaluations.
Simulation Study and Real-World Application
Simulation studies demonstrate LaRT's superior estimation accuracy over traditional IRT models, especially when latent ability and latent speed are correlated. These advantages translate to real-world scenarios, where LaRT is applied to datasets such as MATH500, AMC23, AIME24, and AIME25. The results reveal strong negative correlations between latent ability and latent speed, underscoring the model's capability to detect nuanced relationships between LLM reasoning and proficiency.
A critical insight from the application of LaRT is its ability to yield different LLM rankings compared to IRT. The inclusion of CoT length information enhances predictive power, item efficiency, ranking validity, and evaluation efficiency. For instance, LaRT achieves better prediction accuracy for unseen items and requires fewer items to accurately estimate LLM abilities, highlighting its practical efficacy.
Theoretical Contributions and Implications
LaRT contributes theoretical advancements such as rigorous identifiability results and asymptotic analyses ensuring statistical validity. The model's identifiability guarantees mean that distinct parameter configurations correspond to unique data distributions, crucial for reliable inferencing. Additionally, LaRT's framework suggests trends in LLM evaluation: as benchmarks become more challenging, the correlation between reasoning speed and accuracy strengthens, advocating for increased test-time computation to improve reasoning.
The paper suggests future exploration into multi-dimensional latent traits, which could further dissect LLM abilities across various dimensions such as reasoning depth and speed. Moreover, integrating additional covariates like environmental impact or direct CoT reasoning assessment can refine the evaluation metrics, enabling a more holistic LLM assessment.
Conclusion
The Latency-Response Theory model marks a significant step forward in LLM evaluation, offering a robust framework that encompasses both outcome and process metrics. By effectively integrating response accuracy and CoT length, LaRT provides a comprehensive tool for assessing the proficiency and reasoning capabilities of LLMs, addressing key limitations of existing evaluation approaches. As the field of AI continues to evolve, methodologies like LaRT will be critical in benchmarking and advancing the capabilities of LLMs.
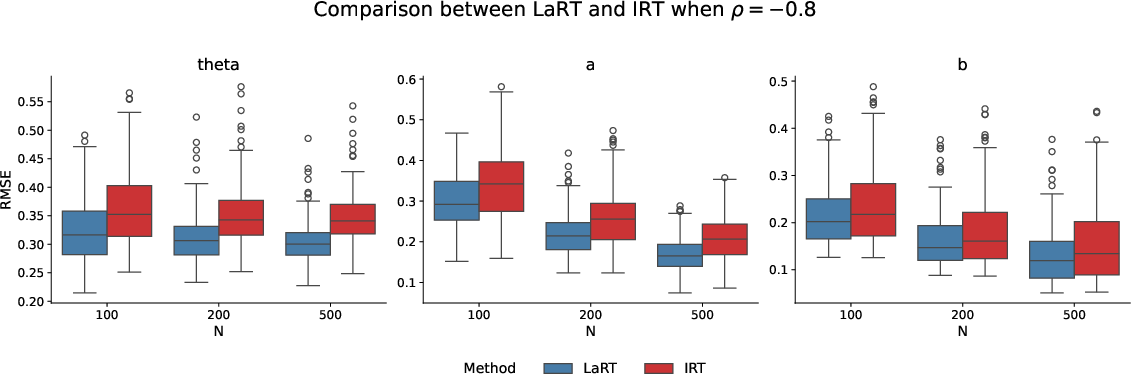
Figure 1: RMSEs of IRT and LaRT when ρ=−0.8. LaRT performs uniformly better than IRT. As N grows, RMSE of $\hat{\ba}$ decreases.
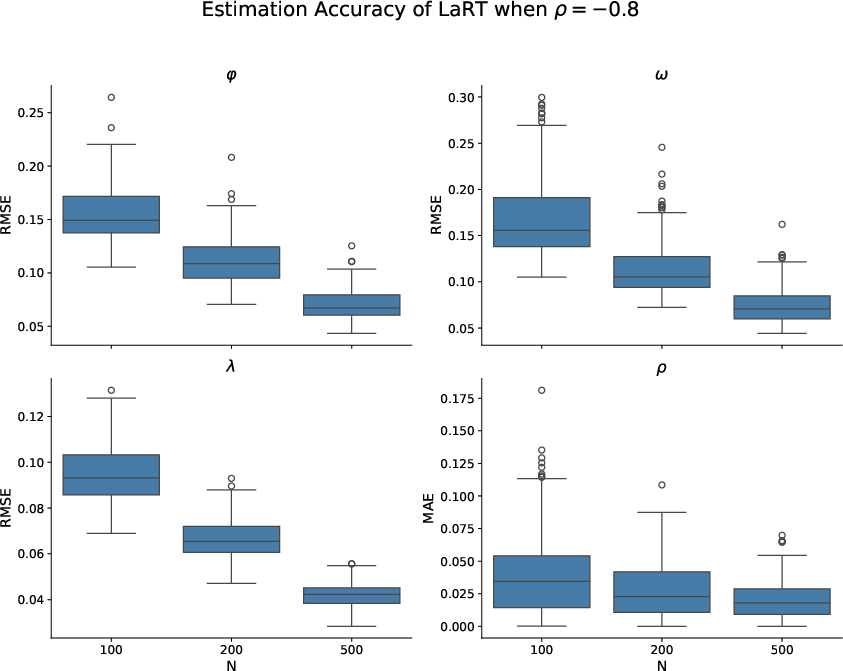
Figure 2: Boxplot of estimation accuracy of other parameters of LaRT when ρ=−0.8 in RMSE and MAE. The metric is presented in the plot. As N grows, the estimation error of all parameters decreases.
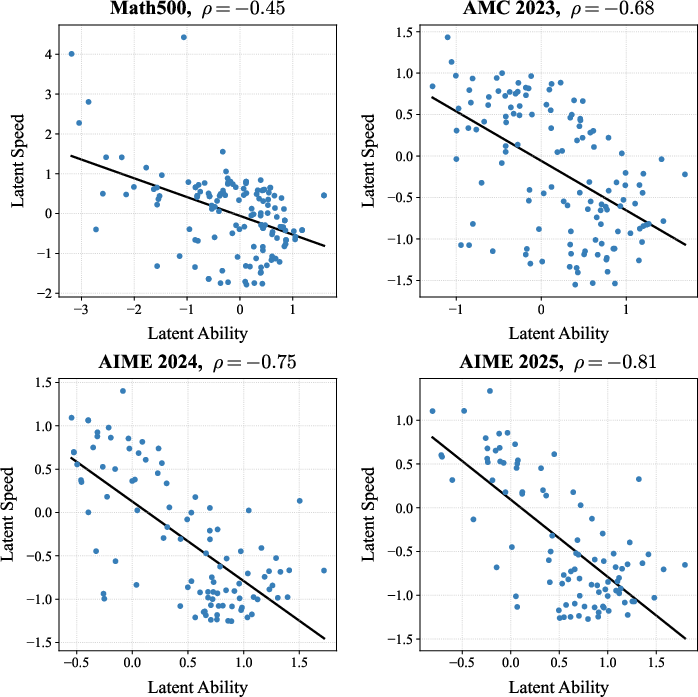
Figure 3: Scatter plot of estimated latent speed against latent ability for each dataset. The estimated correlation for each dataset is presented in the subtitle. LLMs with stronger latent ability have a smaller latent speed (longer CoT length). As the dataset becomes more difficult, the estimated correlation ρ increases in absolute value.