Task adaptation of Vision-Language-Action model: 1st Place Solution for the 2025 BEHAVIOR Challenge
Abstract: We present a vision-action policy that won 1st place in the 2025 BEHAVIOR Challenge - a large-scale benchmark featuring 50 diverse long-horizon household tasks in photo-realistic simulation, requiring bimanual manipulation, navigation, and context-aware decision making. Building on the Pi0.5 architecture, we introduce several innovations. Our primary contribution is correlated noise for flow matching, which improves training efficiency and enables correlation-aware inpainting for smooth action sequences. We also apply learnable mixed-layer attention and System 2 stage tracking for ambiguity resolution. Training employs multi-sample flow matching to reduce variance, while inference uses action compression and challenge-specific correction rules. Our approach achieves 26% q-score across all 50 tasks on both public and private leaderboards.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
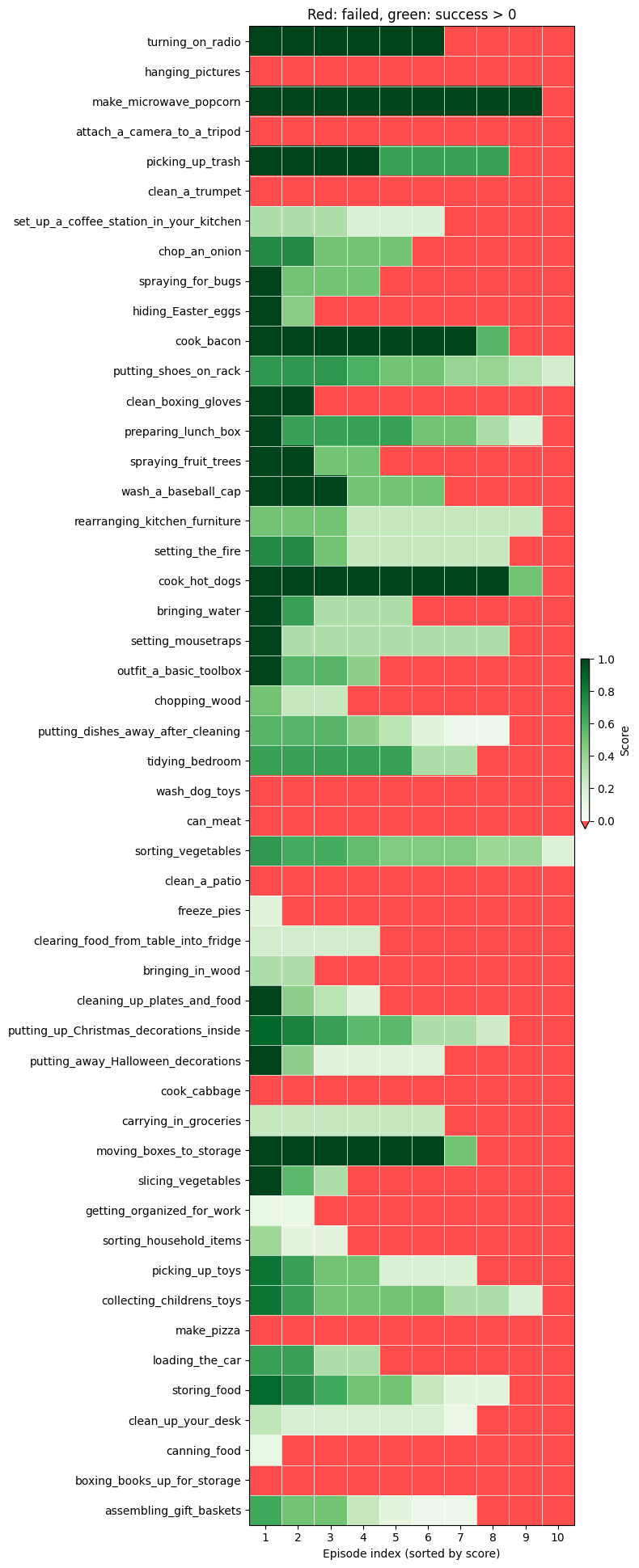
This paper explains how a small independent team built a robot control system that won 1st place in the 2025 BEHAVIOR Challenge. In that challenge, a simulated robot has to complete 50 different household tasks (like opening a microwave, turning on a radio, or cooking a hotdog) inside realistic homes. The tasks are long, complicated, and often look visually similar at different steps, which makes them hard for robots.
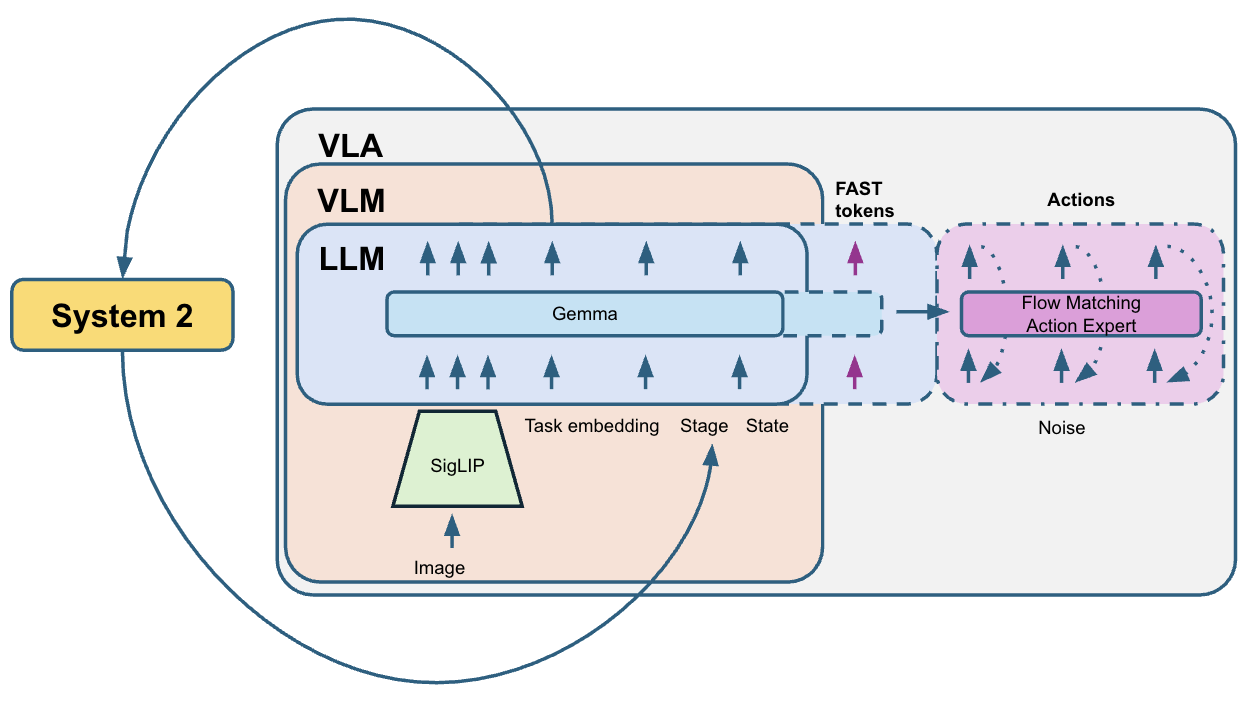
Their system is a Vision-Language-Action (VLA) model, meaning it looks at camera images, understands the task, and decides what actions to take next. The team added several smart ideas to help the robot make smoother, more reliable decisions over time.
What questions they wanted to answer
The team focused on a few practical questions:
- How can we make a robot’s actions smooth and coordinated, so it doesn’t jerk or get stuck?
- How can the robot remember what stage of a task it’s in, even when different stages look the same?
- How can we train the robot efficiently when the training data only shows perfect demonstrations, not recoveries from mistakes?
- How can we keep actions fast enough to finish long tasks within time limits?
How their method works (in everyday language)
Think of the robot’s plan as a playlist of movements it needs to perform. The system watches the robot’s cameras, knows which task it should do, and then predicts the next chunk of actions—like queuing up the next 30 steps in the playlist.
Here are the key ideas, explained simply:
- Correlated noise: During training, the model practices turning “random wiggles” into proper movements. Instead of using completely random wiggles, they use wiggles that resemble real robot motions (nearby steps are similar, and joints move together). This makes learning easier, because the “noise” looks more like what a robot actually does.
- Flow matching: Imagine blending between a noisy, messy version of a movement and a clean, ideal movement over time. The model learns the exact “direction” to push each step so the messy version becomes the clean one smoothly. This helps it produce realistic action sequences.
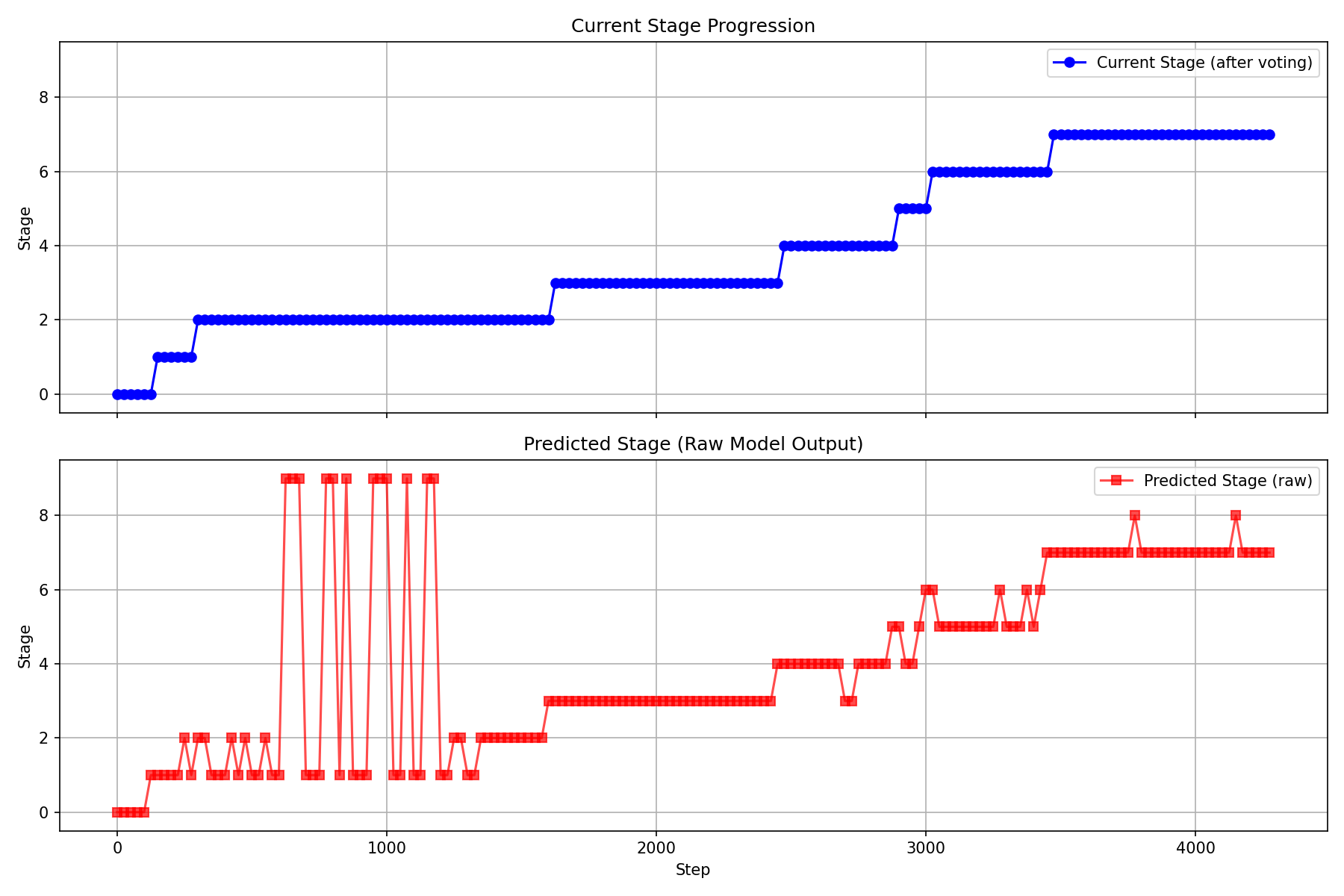
- Stage tracking (System 2): Some parts of a task look the same on camera, even though they mean different things (like holding the radio at the start vs. holding it to put it back). The model predicts which stage the task is in and uses a simple voting system to keep that stage stable over time. It’s like a checklist that stops the robot from skipping ahead or repeating steps by accident.
- Mixed-layer attention: The action predictor “listens” to different layers of the vision model. Instead of hard-coding which layers to use, they let the model learn the best mix on its own, like tuning into the right combination of signals for the current situation.
- Multi-sample training: Each time they process the camera images, they try 15 different “practice versions” of the action prediction with different random settings. This reduces luck and noise in training, leading to steadier learning without re-running the heavy vision part 15 times.
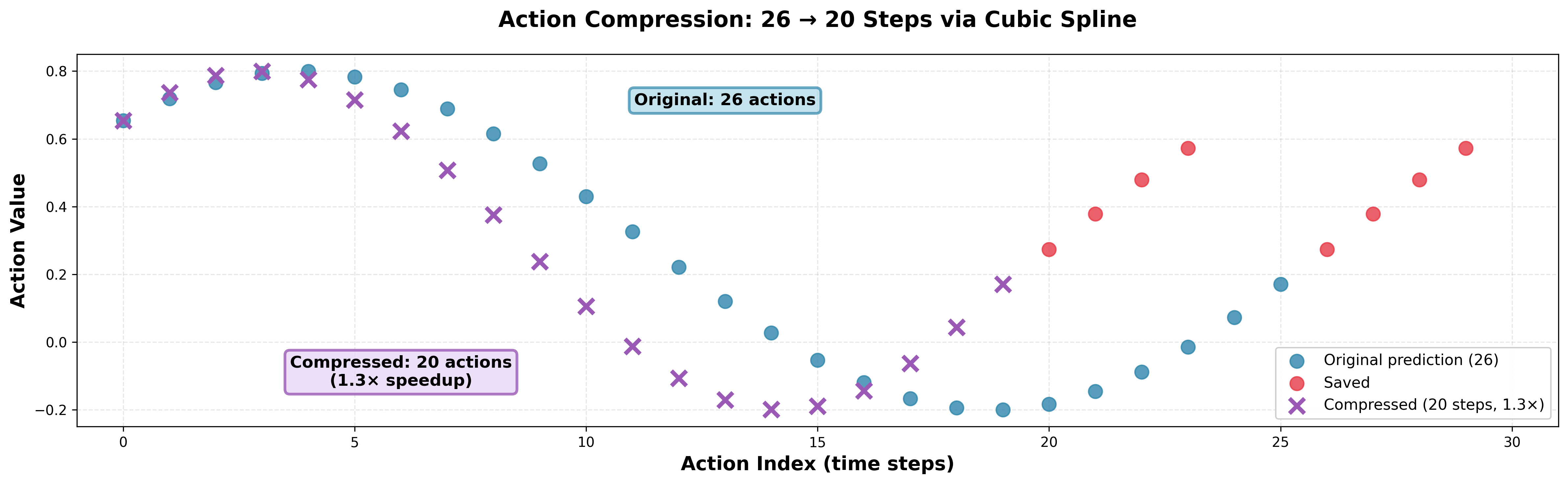
- Action compression: After predicting a 30-step action sequence, they execute fewer steps (like 20), using smooth curves to fill in the gaps. This makes the robot move about 1.3× faster, so it can get more done within the time limit.
- Simple correction rules: If the robot closes its gripper without holding anything (a common mistake), a basic rule opens it again. These small safety checks help the robot recover even though the training demos don’t include recovery examples.
- Task embeddings instead of language: Because the challenge uses the same 50 tasks in training and testing, they replaced text instructions with a learned “task ID embedding.” This is simpler and faster for this competition, even if it means the model isn’t reading or understanding new text commands.
What they found and why it matters
- The system placed 1st in the BEHAVIOR Challenge with a q-score of about 26% across all 50 tasks (public and private leaderboards matched closely). The q-score combines full task success and partial progress, so good partial completion matters.
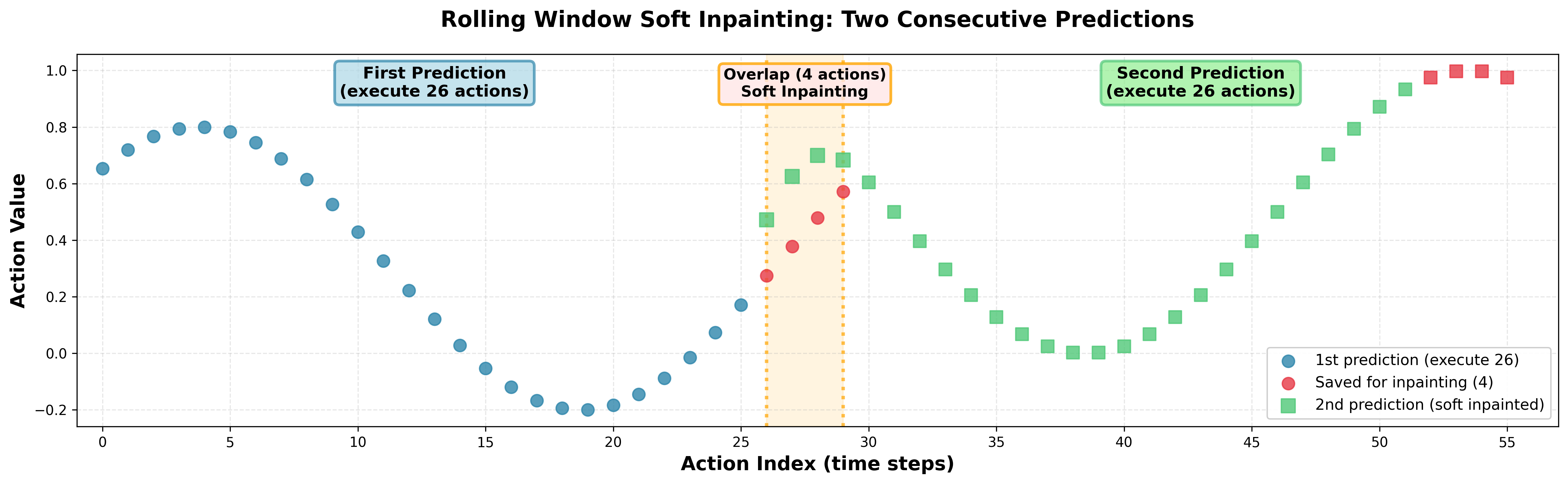
- Correlated noise made training more efficient and helped the robot produce smoother action sequences. It also improved “inpainting,” which is like filling in missing or carried-over parts of action plans between predictions without creating bumps.
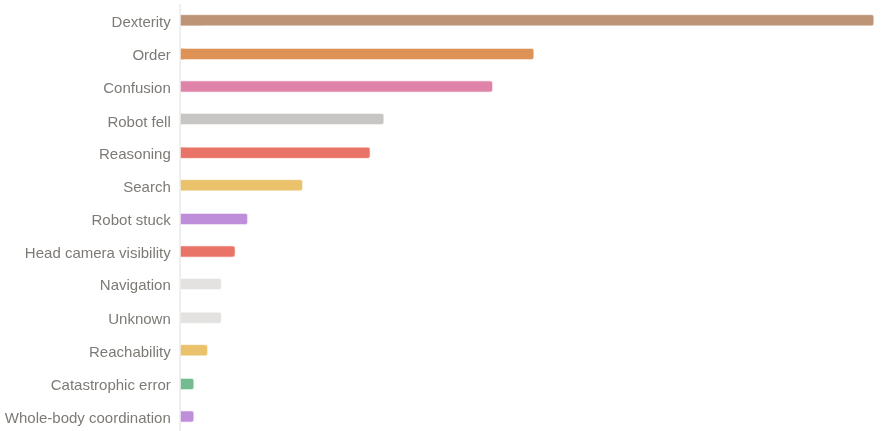
- Stage tracking greatly reduced confusion in visually similar moments, helping the robot pick the right next action.
- Action compression sped up execution without making movements jerky.
- Simple correction rules (like reopening an empty gripper) noticeably boosted success in tasks where grasping is hard.
These results show that a mix of smart training tricks, memory of task stages, and a few practical rules can significantly improve performance on long, multi-step robot tasks.
Why this could be important
- More reliable long tasks: The ideas here—especially stage tracking and correlated noise—could help robots handle multi-step jobs at home, in factories, or hospitals, where many stages look similar and require careful coordination.
- Better learning from limited data: Since real robot training demos often don’t include mistakes, methods that add realistic structure to training (like correlated noise) can make learning smoother and more robust.
- Practical speed-ups: Action compression shows that you can make robots faster without losing control quality, which is useful in time-limited scenarios.
- Reusable building blocks: Even though this was a competition entry without full scientific testing of each piece, the ideas are simple, honest, and available as open-source code and model weights. Other teams can test, refine, and combine them for real-world robots.
In short, this work demonstrates that careful attention to how actions are predicted, how task stages are tracked, and how small corrections are applied can push embodied AI forward—making robots more capable at long, realistic tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable directions for future work:
- Component-level attribution: No ablation studies isolating the impact of each innovation (correlated noise, mixed-layer attention, stage tracking, multi-sample FM, attention masks, action compression, heuristics) or their interactions on q-score and binary success.
- Correlated noise sensitivity: Quantify how performance varies with the shrinkage parameter β, covariance estimation method (global vs per-task/per-stage), sample size, and regularization; assess robustness to dataset bias and distribution shift.
- Theoretical grounding of correlated noise in flow matching: Analyze whether sampling from alters the flow-matching objective or introduces bias; provide convergence guarantees or empirical diagnostics (e.g., training stability curves).
- Covariance scaling and tractability: Evaluate computational/memory costs and numerical stability of estimating and inverting large as action horizon/dimensions grow; explore low-rank, block-structured, or kernel approximations and online/streaming updates.
- Conditional correction correctness: Validate the inpainting correction rule against the conditional Gaussian formulation; measure numerical stability and error propagation in practice.
- Inpainting schedule design: Ablate the “soft inpainting” time threshold (), the number of inpainted steps, and strength of corrections; study effects on smoothness and reactivity, especially under observation changes and OOD states.
- Mixed-layer KV transformation efficacy: Measure benefits vs identity initialization across tasks and model scales; compare scalar layer mixing to per-head/per-token mixing, gating, or learnable routing; examine when it materially improves over Pi0.5’s layer-to-layer attention.
- Custom attention masks: Empirically compare the proposed mask to standard/fused attention patterns; test whether restricting images from attending to robot state/stage harms timely adaptation or contributes to OOD brittleness.
- Stage definition and accuracy: The stage boundaries are derived from demonstration length, not explicit semantics; evaluate stage prediction accuracy on validation/test episodes, measure its contribution to policy performance, and explore automatic/unsupervised stage discovery.
- Stage tracking generalization: Assess robustness on tasks without clear discrete stages or with looping/subtasks; compare voting-based tracking to memory-based architectures (RNNs, transformers with longer context) or explicit history inputs.
- Removal of language inputs: Quantify the trade-off between efficiency and generalization; test reintroducing language prompts for unseen tasks/instructions and investigate chain-of-thought stage guidance with a unified VLM policy.
- Recovery behavior learning: Systematically address the lack of recovery demos via data augmentation (synthetic recoveries, DAgger), offline RL with negative examples, or interactive learning; quantify improvements over heuristic rules.
- Heuristic correction scalability: Develop a general, learnable framework for detecting and correcting failure modes (e.g., event detectors, constraint monitors, rule learning) and measure how it scales beyond gripper-specific fixes.
- Action compression trade-offs: Ablate speedup factors (e.g., 1.1–2.0×), interpolation method (cubic vs linear), and adaptive policies; assess impacts on success, safety, and controller stability across manipulation and navigation subtasks.
- Multi-sample flow matching design: Quantify gradient variance reduction, optimal number of samples per VLM pass, compute/memory trade-offs, and correlation among samples; explore adaptive sampling strategies over and noise.
- Per-timestamp normalization effects: Study interaction with correlation modeling, especially for dimensions excluded (velocities, gripper); evaluate whether normalization distorts and if per-stage/per-dimension normalization works better.
- Global vs task-/stage-specific covariance: Test whether per-task or per-stage improves inpainting and training; assess dynamic covariance estimation conditioned on observations or predicted stages.
- Simulation-only validation: Investigate sim-to-real transfer on physical robots—sensor noise, delays, contact dynamics, compliance—and evaluate domain randomization or sim-to-real adaptation methods needed for robustness.
- Limited sensing modalities: Explore adding depth, point clouds, tactile/force feedback, and state estimation; assess whether multi-modal fusion mitigates occlusions and improves grasp stability and precise manipulation.
- Explicit bimanual coordination: Introduce architectural priors or constraints for coordinated two-hand control (shared latents, symmetry constraints, contact-aware planning) and quantify improvements on tasks requiring handoffs or synchronized motions.
- Navigation integration: Evaluate long-horizon navigation components (mapping, path planning) and their coordination with manipulation; measure performance on cluttered scenes and dynamic obstacles.
- Metric alignment: The method yields strong partial success but modest binary success; analyze optimization strategies that better target full completion (curricula, reward shaping, subgoal tracking).
- Dataset bias and curriculum: Quantify the bias toward simpler training instances, evaluate its effect on generalization, and design balanced/curriculum datasets to cover challenging configurations and failure-prone steps.
- Multi-task vs per-task checkpoints: The final solution uses four task-specific checkpoints; assess feasibility and performance of a single unified model (catastrophic interference, task conditioning, adapter layers).
- Hyperparameter robustness: Systematically sweep key choices (β=0.5, threshold 0.3, stage window size 3, horizon H=30, compression 1.3×) and publish sensitivity analyses to guide reproducibility.
- FAST auxiliary contribution: Determine the marginal benefit of FAST (loss weight, compression settings) under per-timestamp normalization; compare to alternative auxiliary objectives (e.g., predictive coding, future state prediction).
- Failure taxonomy and targeted augmentation: Complete and publish a comprehensive taxonomy of failure reasons; use it to drive selective data collection and augmentation (e.g., grasps under occlusion, tight tolerances).
- Robustness and OOD detection: Add mechanisms for detecting OOD states and triggering re-planning/recovery; evaluate safety constraints (e.g., control barrier functions) integrated with the policy.
- Modeling multimodality: Gaussian-correlated noise does not capture discrete action choices (e.g., hand selection, object order); investigate mixture-of-flows, latent discrete variables, or expert routing for multi-modal action distributions.
- Stage-task fusion design: Ablate fusion methods (sinusoidal encodings, gating, learned embeddings) to identify effective combinations and generalize fusion beyond handcrafted components.
- Time sampling schedule: Compare with alternative schedules or curricula tailored to early/late denoising difficulty, especially when using correlated noise.
- Conditional correction under distribution shift: The inpainting assumes stationary ; evaluate conditioning corrections on current observations or learned conditional models to handle state-dependent correlations.
- Scaling and resource efficiency: Provide guidance to reproduce results with smaller budgets (model scaling, pruning/quantization, lighter backbones), and quantify performance vs compute curves for accessibility.
Glossary
- Action chunking: Predicting sequences of future actions in chunks to improve temporal consistency. "Action Chunking and Temporal Consistency"
- Action compression: Reducing the number of executed actions via interpolation to speed up execution. "At inference, we apply action compression via cubic splines to speed up action execution by 1.3."
- Action correlation matrix: A matrix capturing temporal and cross-dimensional correlations in actions over a horizon. "Action correlation matrix computed from training data (30 timesteps 23 action dimensions = 690)."
- Action Expert: A transformer head that predicts action sequences using flow matching. "Action Expert: Separate transformer that predicts action sequences via flow matching"
- Beta shrinkage: Regularizing a covariance matrix by blending it with the identity to improve stability. "Beta Shrinkage for Robustness"
- Bimanual manipulation: Coordinated control of two robotic arms to perform tasks. "requiring bimanual manipulation, navigation, and context-aware decision making."
- Cholesky decomposition: Factorizing a positive-definite matrix into a lower-triangular matrix and its transpose to sample correlated noise. "we use the Cholesky decomposition:"
- Correlated noise: Noise sampled with action-dependent covariance to reflect structure in actions. "Our primary contribution is correlated noise for flow matching"
- Correlation-aware inpainting: Guiding inpainted action segments using learned correlations to ensure smooth transitions. "enables correlation-aware inpainting for smooth action sequences."
- Cross-attention: An attention mechanism where one sequence attends to another (e.g., action head to VLM outputs). "Attends only to the last VLM layer via standard cross-attention, like in the classic encoder-decoder transformer architecture"
- Cubic spline interpolation: Smoothly interpolating actions with cubic splines to reduce steps while preserving trajectories. "Action compression via cubic spline interpolation."
- Delta actions: Predicting changes from the current state instead of absolute positions. "Instead of predicting absolute joint positions, we predict delta actions:"
- Denoising steps: Iterative steps in flow/diffusion models that transform noise into structured outputs. "Authors of Pi0 and Pi0.5 mention that first denoising steps are more difficult for the model to solve than the rest"
- Diffusion: Generative process modeling distributions via iterative noise removal, applied to action prediction. "Flow matching~\cite{lipman2023flow} and diffusion~\cite{chi2024diffusionpolicy} provide expressive action distributions that handle multi-modality better than regression."
- Encoder-decoder transformer architecture: A transformer design with a separate encoder and decoder connected via cross-attention. "like in the classic encoder-decoder transformer architecture~\cite{vaswani2017attention}."
- FAST auxiliary training: An auxiliary objective using compressed action tokens to aid learning. "We implemented FAST~\cite{pertsch2025fast} auxiliary training with loss weight 0.05."
- Flow matching: Training a model to predict velocities that transform noise into target actions via a continuous-time flow. "We build upon Pi0.5~\cite{pi05_2025}, a vision-language-action (VLA) model that uses flow matching to predict action sequences."
- KV cache: Stored key/value tensors from transformer layers used to speed attention at inference/training. "During both training and inference we first compute Key-Value cache for all layers of the VLM part."
- Mixed-layer attention: Allowing an action head to attend to learned combinations of multiple VLM layers. "We apply learnable mixed-layer attention that allows each action expert layer to attend to learned linear combinations of all VLM layers"
- Non-Markovian states: States where observations alone don’t determine the next action due to missing history. "Non-Markovian states. Many task states are visually ambiguous"
- OmniGibson: A simulation platform for embodied AI tasks with realistic physics and rendering. "The benchmark uses OmniGibson simulation built on NVIDIA Isaac Sim"
- Per-timestamp normalization: Normalizing action targets separately for each horizon step to stabilize learning. "Per-timestamp normalization~\cite{tri2025lbm} addresses the fact that action distributions change over the prediction horizon"
- Proprioceptive state: Internal robot state measurements (e.g., joint positions/velocities) used for control. "along with robot proprioceptive state"
- q-score: The challenge’s overall metric combining binary success and partial success across tasks. "performance is measured by a q-score that combines success rate with partial credit for subtask completion."
- SigLIP-So400m/14: A vision backbone model used to encode multi-camera RGB inputs. "SigLIP-So400m/14~\cite{zhai2023sigmoid} encoder processes images from three cameras"
- System 2 stage tracking: Auxiliary stage prediction with voting to provide non-Markovian context to the policy. "We introduce System 2 stage tracking"
- Teleoperation: Human-controlled demonstrations used to collect expert trajectories. "10,000 expert demonstrations via teleoperation."
- Vision-Language-Action (VLA) model: A model combining vision, language/task signals, and an action head for robot control. "We build upon Pi0.5~\cite{pi05_2025}, a vision-language-action (VLA) model"
- Vision-LLM (VLM): A pretrained model that processes visual (and optionally language) tokens to provide features. "different architectures choose different ways to combine VLM and action head:"
- Voting logic: Majority-based rules applied to stage predictions to stabilize transitions. "applies voting logic to filter out incorrect predictions"
Practical Applications
Immediate Applications
Below are deployable uses that can be implemented with today’s tools, largely leveraging the authors’ released code and weights.
- Robotics (industrial/service): Stage-tracking add-on for long-horizon policies
- What: Integrate auxiliary stage prediction with voting logic to resolve visually ambiguous, non-Markovian states in multi-step tasks.
- Where: Assembly lines (sequence adherence), appliance operation (e.g., kitchens in corporate cafeterias), lab automation, hotel/service robots.
- How: Train a lightweight stage classifier on existing observation streams (multi-camera RGB) and feed the stage token(s) back into the policy; add a 3-prediction voting buffer to stabilize transitions.
- Dependencies/assumptions: Requires stage definitions per task (or proxy labels from demonstration timing); assumes relatively fixed task sets and access to multi-camera views; sim-to-real calibration needed; current model removes language prompts (best for fixed-task deployments).
- Robotics software: Correlation-aware inpainting as an action “smoother” for chunked control
- What: Use the learned action correlation matrix to guide rolling window inpainting so that new chunks align with previously executed actions without discontinuities.
- Where: Any policy using action chunks (ACT-style, diffusion/flow-based controllers), including pick-and-place lines, mobile manipulators in logistics, and household robots.
- How: Precompute Σ-OO and Σ-UU blocks for inpainting; apply soft constraints at early denoising flow times and propagate corrections to free dimensions with M_corr = ΣUO ΣOO{-1}.
- Dependencies/assumptions: Requires a representative empirical correlation matrix from your action distribution; assumes similar kinematics and action parameterization between training and deployment.
- ML tooling (software/graphics/robotics): Correlated-noise flow-matching trainer
- What: Replace standard N(0, I) noise with shrinkage-regularized N(0, βΣ + (1−β)I) during flow/diffusion training to ease early denoising steps and reduce variance.
- Where: Robotics action models, motion synthesis/animation, speech/audio generative models, trajectory prediction in autonomy.
- How: Estimate Σ from normalized training trajectories; use Cholesky sampling; set β≈0.5 as a robust default.
- Dependencies/assumptions: Needs enough diverse training data to estimate a stable Σ; monitor numerical stability (e.g., shrinkage, regularization).
- Robotics runtime optimization: Action compression via cubic splines
- What: Execute fewer, spline-interpolated action steps (e.g., 26→20) for ~1.3× faster task progression while keeping smoothness; adaptively disable compression during delicate phases (e.g., grasps).
- Where: Any long-horizon robot loop with periodic re-planning or chunked inference (warehouses, service robots with time budgets).
- How: Insert a spline resampler node in the control stack (e.g., ROS2); add a simple state machine to disable compression during critical state transitions.
- Dependencies/assumptions: Safety constraints must be respected; requires detection of critical phases (e.g., via gripper-force or visual cues).
- Robotics reliability: Rule-based recovery for common failure modes
- What: Add simple correction rules for high-frequency failures (e.g., auto-open gripper if closed without contact in stages that never required closure).
- Where: Fixed workflows with well-defined substeps (manufacturing cells, repetitive service tasks).
- How: Mine demonstrations to detect “impossible/unused” state transitions; add low-latency rule checks in the control loop.
- Dependencies/assumptions: Task-specific; not scalable to open-world tasks; needs careful safety analysis.
- Model architecture improvement: Learnable mixed-layer attention adapter
- What: Replace fixed layer-to-layer attention with lightweight, learnable linear combinations of all VLM layers for the action head.
- Where: Existing VLA/VLM-based controllers (RT-2 style, Pi0/Pi0.5 derivatives), multimodal planners downstream of transformer encoders.
- How: Insert KV transformation weights per action-expert layer; initialize as identity; fine-tune with existing data.
- Dependencies/assumptions: Requires access to intermediate KV caches and a re-train/fine-tune cycle; benefits are larger when starting from non-robotics VLMs.
- Training efficiency for researchers/SMEs: Multi-sample flow matching per VLM forward pass
- What: Reuse expensive vision-language forward passes across multiple (t, ε) samples to reduce gradient variance and improve throughput.
- Where: Academic labs, startups with limited GPU budgets training diffusion/flow action heads.
- How: Implement N>1 flow samples per batch element post-encoder; average losses; backprop through all samples.
- Dependencies/assumptions: Memory increases with N; tune N (e.g., 8–16) given GPU capacity.
- Benchmarking and reproducibility: Turnkey evaluation and training stack
- What: Adopt the released code/weights, evaluation harness, and elastic on-demand cluster setup for rapid, low-cost experimentation and benchmarking.
- Where: Academia, robotics startups, internal R&D groups.
- How: Use the provided GitHub and HuggingFace artifacts; replicate the on-demand multi-GPU evaluation with object storage (e.g., R2/S3) and simple balancer scripts.
- Dependencies/assumptions: Requires containerization and GPU-capable infrastructure; task set currently tied to BEHAVIOR-like simulations.
- Education/teaching labs: Hands-on modules in long-horizon embodied AI
- What: Course labs demonstrating stage tracking, action chunking, and correlated-noise flow matching using open weights.
- Where: CS/robotics curricula; capstone projects.
- How: Provide pre-configured notebooks and minimal tasks; visualize stage transitions and chunk inpainting effects.
- Dependencies/assumptions: Requires simulator or recorded datasets; local GPU availability for students.
Long-Term Applications
These opportunities are promising but require further R&D, scaling, or adaptation for broader deployment.
- Consumer/home robotics: General-purpose household assistants
- What: Extend stage tracking + correlation-aware chunking to robustly execute multi-step chores (cooking assistance, tidying, laundry sorting).
- Potential products/workflows: Home assistant robots with safer failure recovery and smoother action plans; task libraries with per-home adaptation.
- Dependencies/assumptions: Strong sim-to-real transfer, perception robustness in unstructured lighting/clutter, language grounding (re-introduce “L” for open tasks), safety certification, affordable hardware (bimanual arms, multi-camera rigs).
- Healthcare and eldercare: Assistive manipulation and routine support
- What: Long-horizon manipulation for meal prep, medication organization, or environment set-up with stage-aware execution.
- Potential products/workflows: Bedside assistants, kitchen support in assisted living facilities.
- Dependencies/assumptions: Medical-grade safety, compliance, human-in-the-loop oversight, reliable grasp and contact sensing; bias mitigation and explainability for clinical acceptance.
- Retail/logistics: Robust bimanual picking, packing, and replenishment
- What: Stage-aware multi-step workflows (e.g., open container → grasp → reorient → place → verify) with smoother chunk transitions.
- Potential products/workflows: Drop-in policy modules for WMS/robotic cell controllers; correlation-aware inpainting to reduce cycle time variance.
- Dependencies/assumptions: Diverse SKU handling; sensing for slip/failure; retraining correlation models per SKU set and gripper type.
- Field operations and maintenance: Sequenced manipulation in semi-structured environments
- What: Multi-step procedures (panel operations, valve sequences, tool use) executed reliably with stage memory.
- Potential products/workflows: Mobile maintenance robots for facilities, energy (e.g., plant inspections/operations).
- Dependencies/assumptions: Robust perception in outdoor/industrial conditions; compliance control; task libraries; regulatory approval.
- Autonomy and motion planning: Correlated-noise training for trajectory generators
- What: Apply β-shrinkage correlated noise to diffusion/flow planners for vehicles and drones to ease early-step denoising and improve smoothness.
- Potential products/workflows: Planning modules with better training stability and trajectory continuity.
- Dependencies/assumptions: High-quality trajectory datasets to estimate Σ; safety-critical validation; integration with model predictive controllers.
- Graphics/animation and VR: Smoother motion synthesis and retargeting
- What: Use correlation-aware inpainting for human/creature motion diffusion to reduce boundary artifacts; stage-like conditioning for episodic actions.
- Potential products/workflows: Game-engine plugins for seamless motion chunking; animation tools with correlation-guided transitions.
- Dependencies/assumptions: Domain-specific correlation matrices; artist controls; real-time constraints.
- Foundation VLA evolution: Mixed-layer attention as a general adapter
- What: Generalize the learnable KV mixing to multimodal backbones (audio, tactile) for downstream action heads; automated “which layer to attend” selection.
- Potential products/workflows: Adapter libraries for multimodal transformers; plug-in heads for new domains with minimal architecture search.
- Dependencies/assumptions: Access to intermediate KV caches; extensive pretraining data across modalities.
- Safer autonomy via hybrid learning+rules: Structured recovery libraries
- What: Formalize a library of low-level, verifiable correction rules (beyond gripper heuristics) that complement learned policies across tasks.
- Potential products/workflows: Safety layers that guard against high-frequency, high-risk failure modes, certified for regulated sectors.
- Dependencies/assumptions: Task-specific hazard models; standards compliance (e.g., ISO 10218, ISO 13482); verification and validation toolchains.
- Language-conditioned generalization: Reintroducing “L” for open-set tasks
- What: Combine stage tracking with language-conditioned goal and subgoal prediction (chain-of-thought style), enabling unseen tasks specified in natural language.
- Potential products/workflows: General household assistants, flexible manufacturing lines reconfigured by verbal instructions.
- Dependencies/assumptions: Large-scale instruction-following data for manipulation; reliable grounding; robust subgoal verification; compute and data scaling.
- Dataset and evaluation standards: Policy and benchmarking frameworks
- What: Standardize long-horizon benchmarking practices (partial success scoring, elastic evaluation clusters, open weights) as part of procurement and research policy.
- Potential products/workflows: Public testbeds and reproducibility toolkits for funding agencies and corporate R&D.
- Dependencies/assumptions: Community buy-in; maintenance funding; alignment with simulation and hardware vendors.
Cross-cutting assumptions and dependencies (affecting most applications)
- Hardware/sensors: Bimanual arms with parallel-jaw grippers, multi-camera RGB; accurate calibration; reliable proprioception. Adapting Σ and stage models to different kinematics/grippers is required.
- Data: High-quality demonstrations covering stage variance; stable estimation of action correlation matrices; scarcity of recovery data remains a bottleneck.
- Generalization: The reported solution targets a fixed set of 50 tasks and removes language; open-world deployment will require language conditioning and additional data.
- Compute: Training used substantial GPU resources (e.g., 8×H200 for weeks). Smaller deployments can adopt fine-tuning and the multi-sample efficiency trick but still need GPUs.
- Safety & compliance: Any real-world deployment must incorporate safety layers, fail-safes, and meet regulatory standards appropriate to the sector.
Collections
Sign up for free to add this paper to one or more collections.