The Missing Layer of AGI: From Pattern Alchemy to Coordination Physics
Abstract: Influential critiques argue that LLMs are a dead end for AGI: "mere pattern matchers" structurally incapable of reasoning or planning. We argue this conclusion misidentifies the bottleneck: it confuses the ocean with the net. Pattern repositories are the necessary System-1 substrate; the missing component is a System-2 coordination layer that selects, constrains, and binds these patterns. We formalize this layer via UCCT, a theory of semantic anchoring that models reasoning as a phase transition governed by effective support (rho_d), representational mismatch (d_r), and an adaptive anchoring budget (gamma log k). Under this lens, ungrounded generation is simply an unbaited retrieval of the substrate's maximum likelihood prior, while "reasoning" emerges when anchors shift the posterior toward goal-directed constraints. We translate UCCT into architecture with MACI, a coordination stack that implements baiting (behavior-modulated debate), filtering (Socratic judging), and persistence (transactional memory). By reframing common objections as testable coordination failures, we argue that the path to AGI runs through LLMs, not around them.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper argues that LLMs aren’t a dead end for building very smart AI (AGI). Instead, they’re like a huge ocean full of patterns the AI has learned. What’s missing is a “coordination layer” that tells the model which patterns to use, checks its work, and keeps track of what happened before. The authors call this missing piece the System‑2 “coordination layer,” and they propose two things:
- A simple theory for when an LLM’s answers become grounded and goal‑directed (called UCCT).
- A practical system design that makes LLMs work together with checks and memory (called MACI).
Key questions in simple terms
The paper asks:
- Are LLMs useless for real reasoning, or are we just using them the wrong way?
- What extra “layer” would help LLMs turn their knowledge into reliable, goal‑focused thinking?
- Can we measure when an LLM is truly “locked onto” a task versus when it’s just guessing?
- How should we build systems—multiple AI “agents,” judges, and memory—to make their reasoning more trustworthy?
Methods and approach, explained with everyday ideas
To make these ideas easy to picture, the authors use a fishing metaphor:
- The ocean = the model’s learned patterns.
- The bait = the clues and goals you give it (examples, facts, tool results).
- The net = rules and filters that keep only the good catch (constraints, verification).
If you cast a net with no bait, you catch whatever is most common in that part of the ocean—often generic or obvious answers. Add the right bait, and your catch shifts toward what you actually want.
The authors formalize this bait-and-net idea with a simple “anchoring score” that predicts when the model stops drifting and starts following your goal:
In plain words:
- (effective support): How strongly your clues point to the right idea—the “pull” of your bait.
- (mismatch): How confusing or unstable the situation is—the tighter your net, the less junk slips through.
- (budget): How much context/extra info you supply, and is a “cost” that stops you from stuffing in too much and making things noisy.
When is high enough, the model “snaps into” the right mode—like flipping a switch.
They also turn this theory into an architecture called MACI, which adds:
- Baiting: behavior‑modulated debate among multiple AI agents to explore ideas.
- Filtering: a Socratic “judge” (CRIT) that checks clarity, logic, and evidence.
- Persistence: transactional memory that remembers what was tried and why.
Main findings and why they matter
Here are the core findings, described with simple examples:
- Small, smart hints can flip behavior like a switch. A few good examples can redefine what an operator means on the fly (like treating “−” as “+”) or teach a brand‑new symbol. This “abrupt flip” matches the anchoring score idea: once the bait is strong enough and the net is tight enough, the model locks on.
- Ambiguous hints lead to different answers in different models. If your bait points to more than one possible rule, different models may “catch” different rules. That’s not proof they can’t reason—it shows why you need anchoring and filtering to disambiguate.
- A child learning “cat” shows the same pattern. A 4‑year‑old can learn to recognize cats from a few labeled pictures because they already have lots of visual “building blocks” (fur, ears, faces). A little anchoring crosses the threshold to a stable concept. Rare or unusual animals (like pangolins) need more or better anchors.
- Coordination beats raw generation. The authors argue that many LLM failures (like hallucinations) are “coordination failures” (weak bait, messy net, or noisy context), not hard limits of pattern models. Multi‑agent debate, judging, and memory can reduce these failures by strengthening anchors, filtering bad arguments, and keeping track of state.
- The path forward is testable. Instead of arguing “LLMs can’t reason,” the paper proposes experiments: measure the anchoring score, vary the amount/quality of context, and check if behavior flips at a predictable threshold. If coordination layers repeatedly boost reliability and stability, that’s evidence the bottleneck is coordination—not the LLM substrate.
Implications: what this could change
- Build on LLMs, don’t throw them out. LLMs are a powerful “pattern ocean.” The key is adding the right bait (helpful context), net (constraints and checks), and memory. This coordination layer can turn broad know‑how into reliable reasoning.
- Better AI systems will look like teams, not solo geniuses. Multiple agents debating, a neutral judge checking arguments, and shared memory can make answers more accurate, explainable, and auditable.
- Clear metrics will guide progress. If anchoring thresholds predict when models stop hallucinating and follow goals, researchers can design tighter tests, better retrieval strategies, smarter prompts, and more efficient tool use.
- Real‑world impact. In fields like medical diagnosis, structured debate can identify what evidence is missing, ask for the right tests, and reduce errors—showing how coordination turns “word prediction” into helpful decision‑making.
Bottom line
LLMs aren’t “just pattern matchers” to be discarded. They are the necessary foundation. Add a smart coordination layer—anchoring, debate, judging, and memory—and you can transform raw pattern completion into goal‑directed, testable reasoning. The authors’ message is simple: the path to more general intelligence runs through LLMs plus coordination, not around them.
Knowledge Gaps
Below is a single, concrete list of the paper’s unresolved knowledge gaps, limitations, and open questions that future researchers could address.
- UCCT parameterization remains underspecified: precise, task-agnostic definitions and measurement protocols for effective support ρ_d, mismatch d_r, adaptive regularizer γ, and anchoring budget k are not fully operationalized across diverse task types (classification, generation, planning).
- Learning γ online: there is no algorithm for adapting γ to environment noise/resource constraints, nor evidence that γ can be reliably learned or transferred across domains without overfitting.
- Identifiability of UCCT parameters: it is unclear whether different combinations of (ρ_d, d_r, γ, k) can produce indistinguishable anchoring scores S, complicating interpretation and policy control.
- Threshold calibration: the logistic surrogate in Eq. (phase) requires estimating θ and α; stability and generality of these parameters across tasks, models, and modalities are untested.
- Alternative estimators of ρ_d: using self-consistency clusters as a proxy for density support may be brittle for open-ended tasks; comparative evaluation against alternative estimators (e.g., posterior entropy, margin-based scores, entailment consensus) is missing.
- d_r metric selection: the mismatch term depends on chosen perturbations and distance metrics; best practices and sensitivity analyses across tasks (e.g., numerical reasoning vs. legal argumentation) are not provided.
- Phase-transition claims lack universal evidence: the paper asserts sigmoid-like flips but does not present large-scale, cross-domain empirical curves characterizing critical points, hysteresis, or scaling behavior.
- Formal link to dynamical systems and physics: beyond analogy, there is no mathematical derivation connecting UCCT to established phase-transition models (e.g., bifurcation analysis, order parameters, critical exponents).
- Posterior-shift verification: methods to empirically demonstrate that “reasoning” corresponds to grounded posterior shifts rather than superficial pattern overrides are not specified.
- Generalization across substrates: it is unclear whether UCCT applies to non-LLM substrates (vision models, world models) and mixed-modality substrates, or how parameters map across modalities.
- MACI behavior modulation lacks convergence guarantees: the contentiousness update rule has no theoretical analysis of convergence, stability, or avoidance of oscillatory/deadlock dynamics under disagreement.
- Agent collusion and mode collapse: safeguards preventing agents from converging on rhetorically fluent yet incorrect consensus (especially under shared priors) are not formalized or empirically stress-tested.
- CRIT judge specification: scoring rubrics, training/evaluation protocols, and independence from the generators (to avoid self-judging bias) are not detailed; inter-rater reliability and robustness to adversarial inputs remain untested.
- Transactional memory design: memory architecture, conflict resolution (merge/rollback), contamination prevention, decay/retention policies, and auditability interfaces are not specified or evaluated.
- Memory poisoning and drift: how MACI detects and repairs incorrect or adversarially injected memory entries over time is unclear.
- Precision RAG controller: criteria and policies for routing queries, rejecting noisy retrievals, and handling adversarial or contradictory documents are not defined; the impact of retrieval quality on UCCT variables is not quantified.
- Computational budget and latency: the cost of multi-agent debate, sampling for self-consistency, CRIT adjudication, and tool calls is not analyzed; scheduling policies linking k (anchors) and runtime constraints are missing.
- Tool-grounding reliability: the framework assumes tools can verify constraints, but there is no protocol for tool selection, trust calibration, sandboxing, error propagation, and fail-safe behavior when tools are unreliable.
- Robustness to distribution shift: UCCT/MACI have not been evaluated under domain shifts (multilingual, low-resource, non-Western norms, noisy inputs, long-horizon tasks) to test anchoring stability.
- Safety under adversarial anchoring: defenses against prompt injection, adversarial examples, deceptive debate tactics, and Goodharting of judge metrics are unspecified.
- Comparative baselines: systematic comparisons to strong alternatives (e.g., guided RL, verifier-augmented pipelines, program-of-thought, world-model agents) with ablations isolating anchoring, debate, judging, and memory components are absent.
- Negative results and failure modes: the paper does not catalog tasks where coordination fails even with ample anchors or where the substrate appears fundamentally insufficient.
- Sample efficiency and scaling laws: quantitative relationships between k (anchors) and reliability gains, and diminishing returns curves across tasks/models, are not reported.
- Online estimation and control of S: policies for measuring S during inference and adapting anchoring (e.g., increasing k, invoking tools, switching strategies) in closed loop are not specified.
- Evaluation metrics for “anchored reasoning”: standardized metrics for constraint satisfaction, citation verification, perturbation-stable correctness, and long-horizon consistency are not consolidated.
- Human cognition parallels are anecdotal: claims tying UCCT to neurocognitive mechanisms lack rigorous empirical tests linking measurable ρ_d/d_r to cognitive tasks and developmental data.
- Ethical alignment and Dike–Eris: normative frameworks are mentioned but practical implementations, cross-cultural calibration, and conflict resolution between principles and local norms are not formalized.
- Reproducibility: code, datasets, hyperparameters, and experiment protocols for UCCT/MACI are not provided; many references appear forward-dated or hypothetical.
- AGI relevance remains speculative: the path from improved coordination to generality is argued philosophically; empirical demonstrations on diverse, open-ended, multi-step tasks with robust verification are needed.
- Agent count and role specialization: guidelines for the number/types of agents, their specialization, and the diminishing returns/overhead trade-offs are not established.
- Interaction with training-time methods: the interplay between UCCT/MACI and fine-tuning/RL (e.g., catastrophic forgetting, teacher bottlenecks) lacks empirical clarity and best-practice recommendations.
- Multimodal anchoring: protocols and metrics for integrating vision/audio/embodiment into UCCT, and quantifying their effects on d_r and ρ_d, are absent.
- Long-context models vs. γ log k penalty: the framework posits a penalty on unbounded context, but does not reconcile this with emerging long-context models and retrieval strategies that expand k.
- Security and governance: policies for access control, audit trails, and red-teaming of MACI components (judge, memory, tools) are not discussed.
- Incomplete Section 6: the “Compositional generalization” test design (H3) is truncated, leaving experimental setup and success criteria unspecified.
Practical Applications
Immediate Applications
Below is a set of actionable, near-term use cases that can be deployed with current LLMs by layering the paper’s UCCT (anchoring control) and MACI (multi-agent coordination) mechanisms.
- UCCT-guided Precision RAG (Retrieval-Augmented Generation) — adaptive retrieval that increases or trims context based on measured anchoring strength
- Sectors: software, knowledge management, customer support, enterprise search
- Tools/products/workflows: instrumentation for ρ_d via self-consistency clustering; d_r via paraphrase/ordering perturbation tests; adaptive γ·log(k) budget controller; thresholded stopping rule; evidence-ranking UI
- Assumptions/dependencies: access to a high-quality knowledge base; willingness to pay for extra sampling/perturbation compute; simple logistic calibration of thresholds per domain
- MACI debate with Socratic judging (CRIT) for high-stakes content generation — multi-agent drafting, critique, and judge-gated synthesis to improve reliability
- Sectors: education (explanations, grading rubrics), legal research (brief outlines), finance (company memos), scientific summaries
- Tools/products/workflows: dual or tri-agent roles (advocate/skeptic/synthesizer); CRIT checklists for clarity, assumptions, evidence, falsifiability; “reject-and-revise” loop; provenance tracking
- Assumptions/dependencies: human-in-the-loop oversight; domain verification tools (calculators, legal citers, data APIs); guardrail policies for escalation
- Transactional memory and provenance audit — stateful assistants that commit, roll back, and version claims with linked evidence
- Sectors: enterprise AI assistants, compliance, software engineering, legal operations
- Tools/products/workflows: claim graph store (IDs, evidence links, counterevidence), commit/rollback semantics, diff views, audit logs; Saga-like long-term memory
- Assumptions/dependencies: secure storage; privacy/compliance controls; robust identity and session management
- Prompt and workflow optimization via UCCT metrics — reduce hallucinations by measuring support (ρ_d), mismatch (d_r), and anchor budget (k)
- Sectors: LLM app development, marketing/content ops, analytics
- Tools/products/workflows: self-consistency sampling dashboard; perturbation harness; per-task logistic fit (α, θ) to determine minimal effective context; prompt A/B experimentation
- Assumptions/dependencies: moderate compute overhead; labeled evaluation sets to fit transition parameters
- Disagreement-driven data acquisition — use agent debates to surface uncertainty and route discriminating queries/tests
- Sectors: healthcare (clinical decision support), customer support (clarifying questions), business analytics
- Tools/products/workflows: MACI controller that, upon stable disagreement, generates targeted queries (labs, clarifications, filters); re-anchors after new evidence; EVINCE-like loop
- Assumptions/dependencies: tool integrations (EHR, data warehouses, KB search); policies for ordering tests or asking users follow-ups
- Verified citation and fact-check pipelines — judge-gated content that must pass evidence checks before publication
- Sectors: journalism, research ops, corporate communications, public policy briefs
- Tools/products/workflows: CRIT gate enforcing explicit premises; citation verification tools (link-resolvers, corpus entailment checks); “publish only if S > θ and verification passes”
- Assumptions/dependencies: reliable source libraries; calibration of S thresholds per topic risk; editorial sign-off
- Multimodal/tool-grounded anchoring — systematically reduce mismatch by binding language outputs to external sensors/tools
- Sectors: software (code execution), analytics (SQL/data viz), operations (ticketing), robotics (limited)
- Tools/products/workflows: UCCT-aware tool router (lower γ in high-trust tools); calculators, browsers, code runners; “tool-first” anchoring for quantitative tasks
- Assumptions/dependencies: reliable tool outcomes and sandboxes; latency tolerance for iterative calls
- Education tutors with adaptive exploration/yield — stance modulation to challenge misconceptions and consolidate mastery
- Sectors: education (K–12, higher ed, corporate training)
- Tools/products/workflows: agent roles (Coach vs Skeptic); contentiousness parameter α_c tuned by anchoring signals; Socratic prompts; memory of student error patterns and prior anchors
- Assumptions/dependencies: curriculum mapping; accessibility controls; human educator oversight
- Customer support copilots with anchoring-aware escalation — dynamic questioning, evidence anchoring, and human handoff
- Sectors: retail, telecom, SaaS
- Tools/products/workflows: UCCT confidence gating; discriminating follow-ups; policy KB anchoring; audit trail of session state
- Assumptions/dependencies: updated policy/product KB; escalation pathways; privacy/PII handling
- Software design and code review assistants — multi-agent design critiques with judge-gated acceptance and provenance memory
- Sectors: software engineering, DevOps
- Tools/products/workflows: agents proposing alternative architectures; CRIT judge enforcing well-posedness (latency, scalability, trade-offs); link to code repositories; decision log memory
- Assumptions/dependencies: repo access; build tools; developer-in-the-loop approvals
- Scientific literature triage and synthesis — anchored summaries with contradiction detection via perturbations
- Sectors: academia, pharma R&D
- Tools/products/workflows: retrieval clusters; self-consistency across sampled syntheses; CRIT gate for claims; contradiction reports; living reviews with transactional updates
- Assumptions/dependencies: access to full texts; domain ontologies; verification tools (trial registries, statistics checkers)
- Personal assistants leveraging anchoring signals — plan-making that asks clarifying questions until S crosses the threshold
- Sectors: daily life (scheduling, travel planning, purchases)
- Tools/products/workflows: UCCT-aware clarifications (“Which constraint matters most?”); structured memory of preferences; tool-grounded quotes and bookings
- Assumptions/dependencies: user data permissions; integration with calendars, travel APIs; transparent opt-in memory
Long-Term Applications
These applications require further research, scaling, integration, or regulatory alignment before broad deployment.
- General coordination layer for robust AGI — UCCT+MACI as the organizing “System-2” atop large pretrained substrates
- Sectors: cross-sector general intelligence platforms
- Tools/products/workflows: standardized anchoring APIs; multi-agent orchestration; judge frameworks; transactional state; universal verification interfaces
- Assumptions/dependencies: advances in large-scale memory, multimodal grounding, safety, and governance
- Clinical diagnostic copilots embedded in EHRs — evidence-seeking, test-ordering, and revision with full auditability
- Sectors: healthcare
- Tools/products/workflows: EVINCE-style debate; lab/imaging ordering policies; anchoring thresholds tied to risk; post-test re-anchoring; differential diagnosis memory
- Assumptions/dependencies: regulatory approval; liability frameworks; integration with EHR systems; rigorous prospective trials
- Policy-making assistants that simulate multi-stakeholder debate — option generation with judge-gated premises and impact analysis
- Sectors: public policy, governance, corporate strategy
- Tools/products/workflows: agent roles representing stakeholders; CRIT gate on assumptions; scenario tools; provenance and public audit trails
- Assumptions/dependencies: access to credible data; transparency mandates; ethics oversight (Dike–Eris)
- Autonomous research agents — hypothesis generation, experiment planning, tool execution, and transactional knowledge graphs
- Sectors: science, biotech, materials
- Tools/products/workflows: lab toolchains (robotics, LIMS); anchoring-based stopping rules; memory of hypotheses and falsification attempts; debate-driven experimental branching
- Assumptions/dependencies: reliable lab automation; data quality; institutional governance for autonomy
- Robotics with anchoring-aware control policies — reduce representational mismatch via sensorimotor grounding and memory
- Sectors: manufacturing, logistics, service robots
- Tools/products/workflows: multimodal UCCT signals; behavior modulation tied to environmental feedback; embodied memory; tool/action verification
- Assumptions/dependencies: robust perception; safe learning in-the-loop; standardized simulators and testbeds
- Auditable AI standards based on UCCT metrics — industry-wide benchmarks and model cards that report anchoring stability
- Sectors: regulation, compliance, MLOps
- Tools/products/workflows: standardized measurement of ρ_d, d_r, k; logistic transition fits (α, θ); perturbation suites; domain-specific thresholds
- Assumptions/dependencies: consensus on metrics; third-party auditors; dataset governance
- Coordination-centric training (beyond token prediction) — RL or curriculum learning that optimizes anchoring and debate policies
- Sectors: AI tooling, academia
- Tools/products/workflows: reward shaping for stability under perturbations; teacher-less verification via tools; learned γ scheduling; stance modulation policies
- Assumptions/dependencies: scalable training loops; avoidance of catastrophic forgetting; robust evaluation
- Agent marketplaces with routable anchoring profiles — route tasks to agents with high support in target domains
- Sectors: software platforms, B2B AI services
- Tools/products/workflows: agent capability cards (anchoring profiles); task routers; judge services; settlement and provenance layers
- Assumptions/dependencies: interoperability standards; trust and reputation systems; billing and SLAs
- Longitudinal learning OS for education — persistent, anchored student models across years with debate-driven mastery checks
- Sectors: education
- Tools/products/workflows: student knowledge graphs; misconception memories; stance modulation per concept; verified assessment pipelines
- Assumptions/dependencies: privacy by design; district adoption; teacher training and control
- Safety and jailbreak defense via dynamic anchoring thresholds — real-time risk gating using S and CRIT
- Sectors: platform safety, cybersecurity
- Tools/products/workflows: increase γ in high-noise or adversarial contexts; judge blocks ill-posed prompts; forensic memory; red-team perturbation harnesses
- Assumptions/dependencies: robust adversarial testing; incident response workflows; continual updates
- Energy and infrastructure planning with multi-agent coordination — constraint-driven, judge-gated plans for grids and transport
- Sectors: energy, mobility, urban planning
- Tools/products/workflows: scenario debates; anchoring to physical constraints and regulatory codes; tool-grounded simulations; provenance and stakeholder audit
- Assumptions/dependencies: trusted models; regulatory buy-in; cross-agency data sharing
- Financial strategy copilots under strict verification — agent debates, risk constraints, and transactional memory for decisions
- Sectors: finance, asset management
- Tools/products/workflows: CRIT-gated theses; tool-grounded backtests; anchoring thresholds for deployment; audit trails of changes
- Assumptions/dependencies: compliance approvals; market data licenses; rigorous model risk management
Notes on Assumptions and Dependencies across applications
- Measurement fidelity: accurate estimation of ρ_d (support) and d_r (mismatch) requires additional sampling and perturbation; organizations must budget for computation and latency.
- Tool reliability: many workflows depend on external tools/APIs (calculators, browsers, databases, lab systems); their correctness and sandboxing are critical to overall safety.
- Human oversight and governance: for high-stakes domains (healthcare, law, finance, policy), human review and institutional processes remain necessary until strong evidence supports autonomous operation.
- Privacy, security, and compliance: transactional memory and provenance introduce sensitive data handling; systems must implement access controls, retention policies, and auditability.
- Domain calibration: UCCT thresholds (θ) and regularizer schedules (γ) are task- and context-dependent; teams must calibrate per domain and maintain them as data and risk profiles evolve.
Glossary
- Adaptive Regularizer: A penalty term that scales with context size to prevent over-baiting. "Adaptive Regularizer (): is the anchoring budget; is learnable or context-dependent."
- Anchored Reasoning: The regime where behavior is controlled by anchors and constraints rather than priors. "Above threshold, the system locks onto the Anchored Reasoning regime."
- Anchoring budget: The count or weight of anchors (examples, retrievals, tool outputs) supplied to a run. "Anchoring budget ."
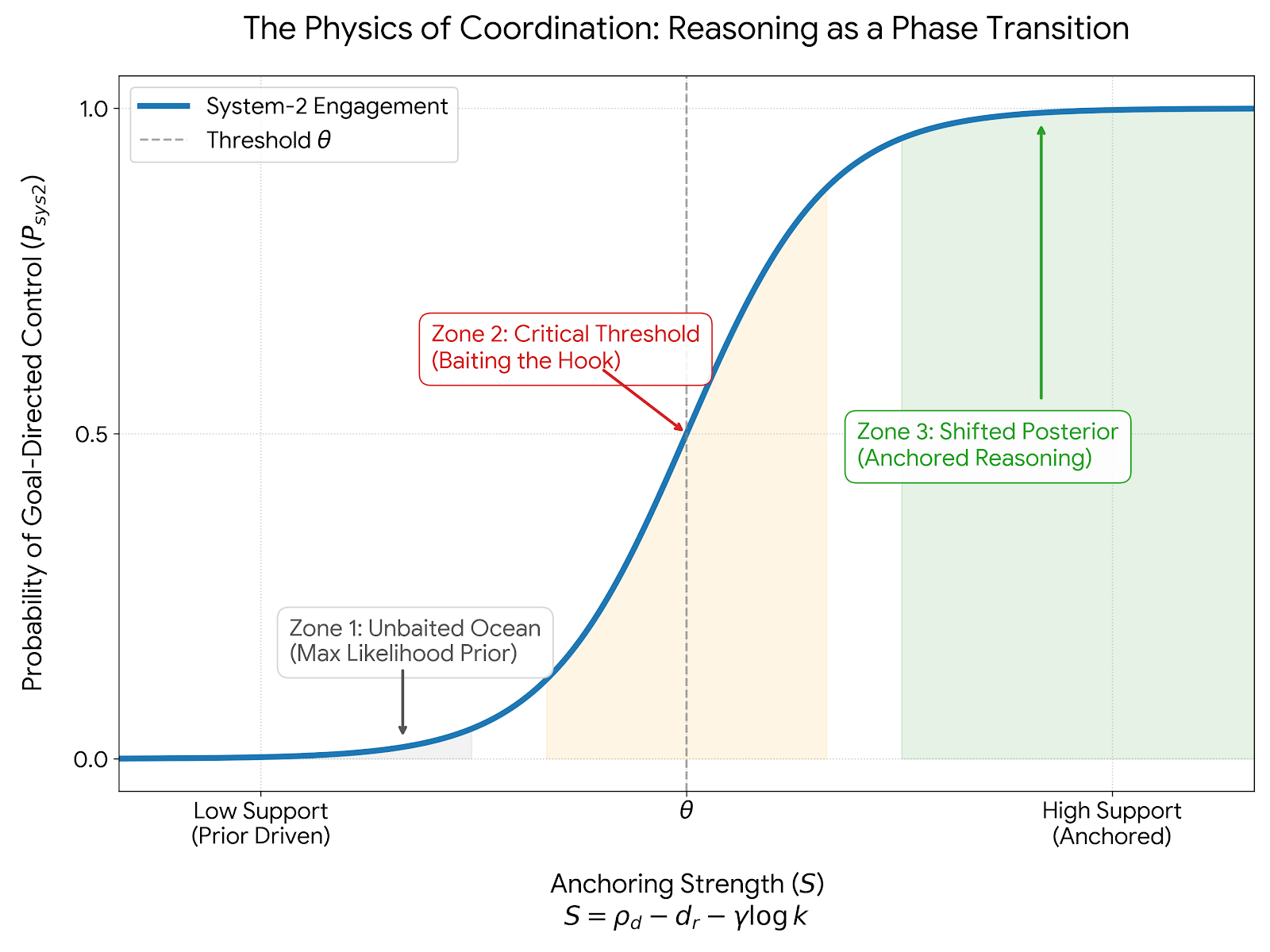
- Anchoring score: A scalar that quantifies anchoring strength by combining support, mismatch, and regularization. "We use the UCCT (Unified Contextual Control Theory) anchoring score to formalize when a pretrained pattern repository transitions from hallucination to goal-directed control:"
- Anchoring strength: The defined measure of how strongly external structure binds latent patterns. "We define anchoring strength as:"
- Behavior-modulated debate: A debate mechanism whose aggressiveness adapts to evidence and anchoring signals. "baiting (behavior-modulated debate)"
- Catastrophic forgetting: Loss of previously learned capabilities after aggressive fine-tuning. "(i) catastrophic forgetting and benchmark regressions under aggressive fine-tuning"
- Contentiousness parameter: An agent-level control variable governing how strongly a hypothesis is defended. "Each agent maintains a contentiousness parameter "
- CRIT (Critical Reading Inquisitive Template): A judging framework that evaluates clarity, consistency, grounding, and falsifiability. "MACI therefore introduces an explicit judge role grounded in CRIT (Critical Reading Inquisitive Template) that evaluates reasonableness independent of stance~\cite{crit2023}."
- Dike--Eris framework: A checks-and-balances alignment framework pairing general principles with context-sensitive application. "In our Dike--Eris framework~\cite{DikeErisChang2025}, Dike specifies general principles and constraints, while Eris interprets and applies them in a context-sensitive manner."
- Effective Support: The density of the target concept recruited by the anchors. "Effective Support (): the density of the target concept recruited by the anchors (the bait's attraction)."
- Entailment-based inconsistency score: A metric for measuring representational mismatch via logical inconsistency. "semantic similarity loss, or an entailment-based inconsistency score"
- Log-probability margin: The difference in log-probabilities between top candidates used to estimate support concentration. "For classification, this is the log-probability margin between the best and second-best token."
- Maximum Likelihood Prior: The unanchored default distribution of the pretrained substrate. "Without semantic anchors, the model retrieves the Maximum Likelihood Prior of the substrate (common, generic tokens)."
- Multi-Agent Collaborative Intelligence (MACI): A coordination stack architecture implementing anchoring, debate, judging, and memory. "This paper formalizes the coordination layer through our Multi-Agent Collaborative Intelligence (MACI) framework~\cite{maci2026}."
- Phase transition: An abrupt regime change when a control variable crosses a threshold. "we show that semantic anchoring admits a phase-transition structure: as crosses a critical threshold, behavior shifts from hallucination to anchored control."
- Posterior distribution: The distribution after conditioning on anchors and constraints. "This shifts the posterior distribution, allowing the system to capture a rare, goal-directed target (the shark) that would otherwise be drowned out by the training priors."
- Precision RAG: Targeted retrieval-augmented generation guided by debate/control signals. "debate functions as a controller for precision RAG and measurement"
- Representational mismatch: The instability or resistance of a representation under perturbation. "representational mismatch ()"
- Self-Consistency: A decoding/evaluation method that aggregates multiple reasoning paths to estimate support. "For open-ended reasoning, we use Self-Consistency:"
- Semantic anchoring: The binding of model generation to external evidence, goals, or constraints. "a theory of semantic anchoring"
- Sigmoid curve: An S-shaped performance curve indicating thresholded behavior. "performance follows a sigmoid curve."
- Socratic judging: A filtering mechanism that evaluates arguments with Socratic questions to ensure well-posedness. "filtering (Socratic judging)"
- Symbol rebindings: Prompt-driven reinterpretation of symbols or operators. "including symbol rebindings and sensitivity to prompt construction."
- System-1 substrate: The fast, unconscious pattern repository underlying competence. "LLMs are the necessary System-1 substrate (the pattern repository)."
- System-2 coordination layer: The slower executive layer that selects, constrains, verifies outputs, and maintains state. "the absence of a System-2 coordination layer that binds these patterns to external constraints, verifies outputs, and maintains state over time."
- Teacher bottleneck: A limitation where stronger training relies on an even stronger teacher model. "the teacher bottleneck for frontier models, where âwho teaches the best teacherâ becomes a circular dependency in the limit."
- Transactional memory: A persistent memory component that records and audits assertions and revisions. "persistence (transactional memory)."
- Unified Contextual Control Theory (UCCT): A theory modeling semantic anchoring and its thresholded regime changes. "We use the UCCT (Unified Contextual Control Theory) anchoring score to formalize when a pretrained pattern repository transitions from hallucination to goal-directed control:"
Collections
Sign up for free to add this paper to one or more collections.