- The paper introduces SQ-format, a unified data format that integrates post-training quantization and sparsification to reduce computational requirements while preserving accuracy.
- It divides matrices into high-precision and low-precision components, enabling efficient hardware acceleration through dedicated processing paths.
- Experimental results demonstrate a Pareto improvement in throughput and accuracy, achieving less than a 1% accuracy gap compared to the W4A8 baseline while reducing latency.
Introduction
The paper "SQ-format: A Unified Sparse-Quantized Hardware-friendly Data Format for LLMs" (2512.05409) addresses the significant challenges posed by LLMs in terms of memory and computational requirements. To alleviate these issues, post-training quantization (PTQ) and sparsification are employed to enable the efficient deployment of LLMs on fewer or more cost-effective hardware resources. Current PTQ methods manage to maintain accuracy using 8-bit formats for weights and activations, but striving towards lower bit-widths like W4A4 could cause substantial performance degradation due to hardware limitations.
The proposed SQ-format seeks to bridge the gap between efficiency and accuracy by introducing a novel data format that is compatible with existing and future hardware. Unlike traditional approaches that apply uniform quantization, SQ-format utilizes a hybrid precision compression method that incorporates sparse and quantized representations. This format optimizes matrix multiplication by splitting matrices into high-precision and low-precision components, thereby allowing tasks to be processed efficiently using hardware-accelerated low-precision paths.

Figure 1: An example of a weight matrix using SQ-format (hhigh=INT8, hlow=INT4, s=0.5).
Two specific PTQ algorithms leveraging SQ-format are presented: one for weights and one for activations. The weight-based algorithm utilizes a symmetric quantization to ensure ease of hardware implementation, where the highest value in a low-precision format indicates the presence of high-precision elements. For activations, a dynamic strategy dynamically computes high-precision masks during inference, while a static strategy precomputes these masks based on the calibration set.
Hardware Implementation and Co-design
The effective deployment of SQ-format depends on the availability of compatible hardware. As such, dedicated accelerators are vital to manage high-precision components efficiently. The paper discusses potential hardware implementations that can support the execution of SQ-format more efficiently by utilizing parallel computation paths for high and low-precision components.
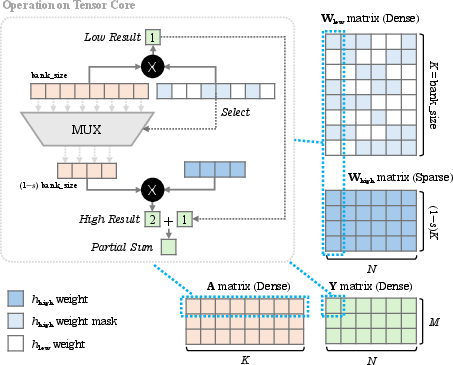
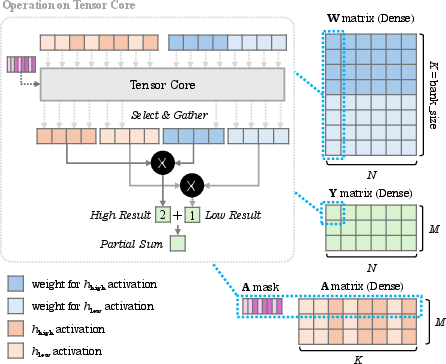
Figure 2: SQ-format for weights.
In terms of computational efficiency, SQ-format aims to achieve a balance between throughput and system cost, providing an improvement over existing quantization methods on typical GPUs and suggesting a pathway for future AI accelerators.
Experimental Results
The experimental evaluations demonstrate that SQ-format achieves Pareto improvements between accuracy and throughput compared to existing methods. The paper reports superior throughput with performance levels comparable to higher precision settings, noting less than a 1% accuracy gap against the W4A8 baseline.
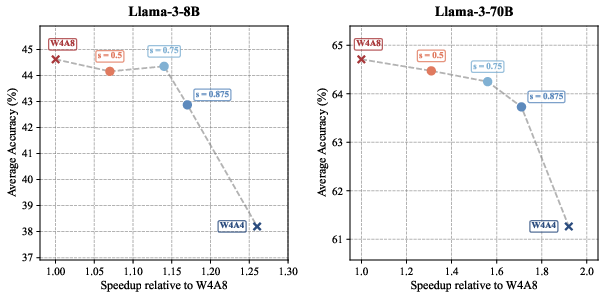
Figure 3: Accuracy-Speed Pareto frontier on Llama-3 models.
The static strategy for activation quantization effectively eliminates the runtime overhead associated with dynamic value selection, making SQ-format more appealing for hardware integration. Comparative latency analyses indicate that SQ-format substantially reduces end-to-end computation times, bringing performance closer to the efficient W4A4 execution while maintaining high model accuracy.
Conclusion
Overall, SQ-format provides a promising approach for enhancing the efficiency and practicality of deploying LLMs on contemporary hardware. By incorporating sparsification and quantization into a unified format, this research not only proposes a viable solution for current hardware limitations but also sets the stage for future advancements in AI hardware design. Given its successful demonstration across several benchmark tests, SQ-format is poised to influence future strategies in LLM deployment and hardware optimization.