- The paper introduces ShadowDraw, a framework that synthesizes shadow-drawing art by unifying physical shadows with generative line drawings.
- It employs contour-based conditioning and scene parameter optimization using fractal dimension metrics to produce semantically coherent compositions.
- Quantitative and qualitative evaluations demonstrate significant user preference and improved concealment scores over baseline multimodal generators.
ShadowDraw: From Any Object to Shadow-Drawing Compositional Art
Introduction and Motivation
ShadowDraw presents a computational pipeline for synthesizing compositional shadow-drawing art, where cast shadows from arbitrary 3D objects are unified with generative line drawings, forming coherent and semantically interpretable visuals. The key distinction from traditional shadow art techniques lies in its approach: instead of optimizing an object or scene to match a predefined shadow target, ShadowDraw automatically discovers scene configurations—object pose, lighting parameters, and supporting line drawings—such that the resultant shadow completes the drawing into a recognizable image. This framework effectively bridges physical constraints with generative artistry, scaling beyond hand-crafted or purely algorithmic inverse design.

Figure 1: The evolution from treating shadows as the sole medium (a) to integrating them with generative line drawings such that the shadow completes the composition (b).
Methodology
ShadowDraw decomposes the shadow-drawing art generation problem into three principal components: (1) line drawing generation conditioned on shadow contours, (2) scene parameter optimization to induce semantically meaningful and visually rich shadows, and (3) automated evaluation and ranking of candidate outputs to select high-quality, shadow-coherent compositions.
Pipeline Overview
The system takes as input a 3D object and produces (i) an incomplete line drawing and (ii) scene parameters (object pose, lighting position/direction). When rendered, the object's cast shadow completes the partial drawing, forming a coherent, human-recognizable image.
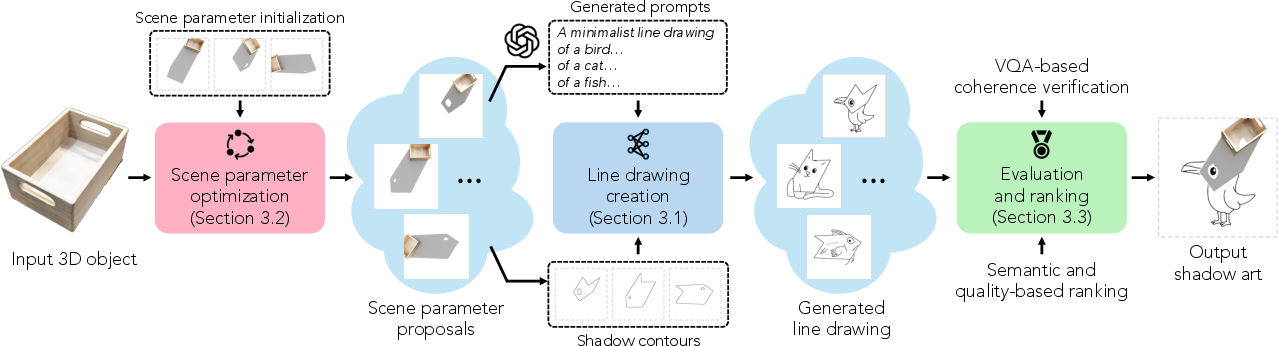
Figure 2: The pipeline: scene parameter optimization yields rendered shadows; shadow contours are fed with text prompts into a line drawing generator; generated candidates are filtered and ranked to produce high-quality outputs.
Shadow Contour Conditioning
Empirical analysis revealed that conditioning line drawing generation directly on raw shadow images or object-shadow composites provides weak structure for downstream synthesis, often resulting in incoherent or trivial compositions. Instead, the pipeline extracts clean shadow boundary contours and leverages them as geometric priors. This not only improves alignment between the shadow and generated drawing but also facilitates scalable paired dataset construction using synthetic line drawings with extracted contours.
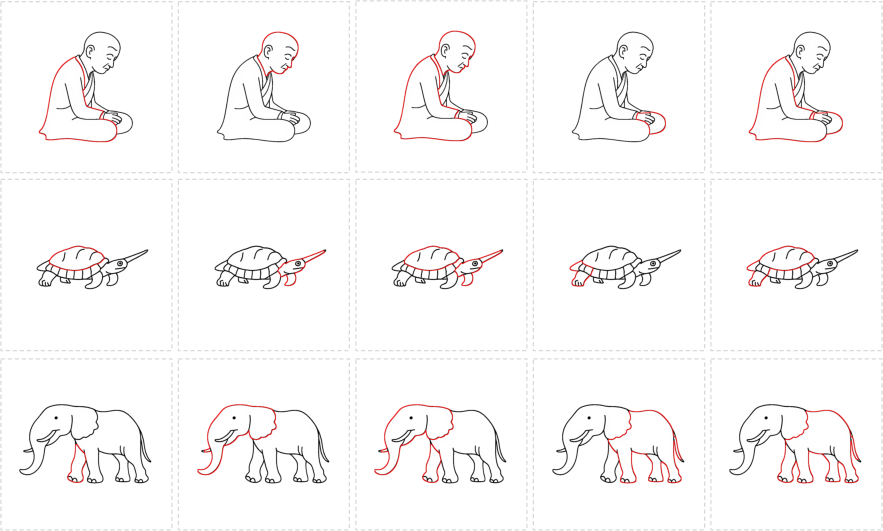
Figure 3: Training data pairs consist of a line drawing and extracted closed contour, forming a paired input for conditional generation.
The backbone generator is a latent-flow diffusion model (based on FLUX-1-Canny, with LoRA/DoRA adapters) trained to synthesize line drawings conditioned on both the shadow contour and a VLM-produced textual prompt. During inference, a binary object mask enables the system to inpaint only outside the object’s projected region, ensuring that generated lines do not overlap with physical geometry.
Scene Configuration Optimization
ShadowDraw jointly optimizes over light azimuth, elevation, and object pose, adopting a differentiable rendering strategy grounded in maximizing contour complexity through the fractal dimension metric. The optimization is initialized with a diverse set of lighting and pose configurations to traverse a broad range of shadow shapes.
The system also automates the generation of textual prompts for the drawing component via a VLM, using in-context chain-of-thought style instructions to ensure the generated description is tailored to the shadow’s geometry and semantically meaningful.
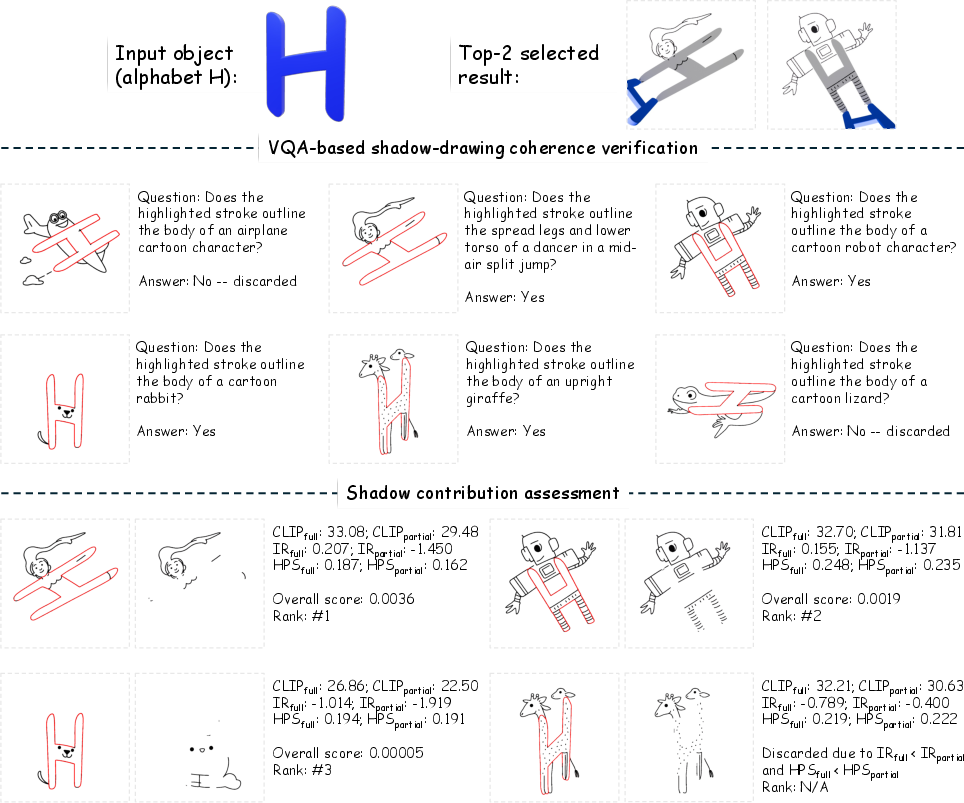
Automated Evaluation and Ranking
Three filters determine compositional viability:
Results and Analyses
Extensive evaluation is performed on 200+ objects spanning curated 3D asset libraries, scanned real-world objects, and synthetic assets. The framework delivers strong quantitative and qualitative improvements over baselines and ablated variants.
Baseline and Ablation Results
When compared against state-of-the-art multimodal generators (e.g., Gemini), ShadowDraw achieves substantially higher concealment scores (3.0059 vs. 0.2421), and is preferred by users in over 70% of cases. Both quantitative metrics and user studies confirm that baseline models, even when provided with precise shadow contours, rarely produce outputs where the shadow is integral to the completed drawing.

Figure 5: Qualitative comparison showing baselines fail to integrate the shadow, while ShadowDraw produces structurally and semantically coherent compositions.
Ablation experiments underscore the importance of each component:
Application Domains
ShadowDraw demonstrates operational flexibility:
- One-to-many mapping: A single object can produce diverse artworks via varying light/pose (Figure 5c).
- Multi-object scenes: Multiple objects can be composed, with shadow regions apportioned to different visual semantics (Figure 5b).
- Animation: By integrating shadow contours over time, temporally coherent shadow-drawing art is synthesized with dynamic objects (Figures 5d, 10).
- Physical deployment: Real-world prototypes validate that computationally derived scene parameters transfer to tangible, reproducible artworks.
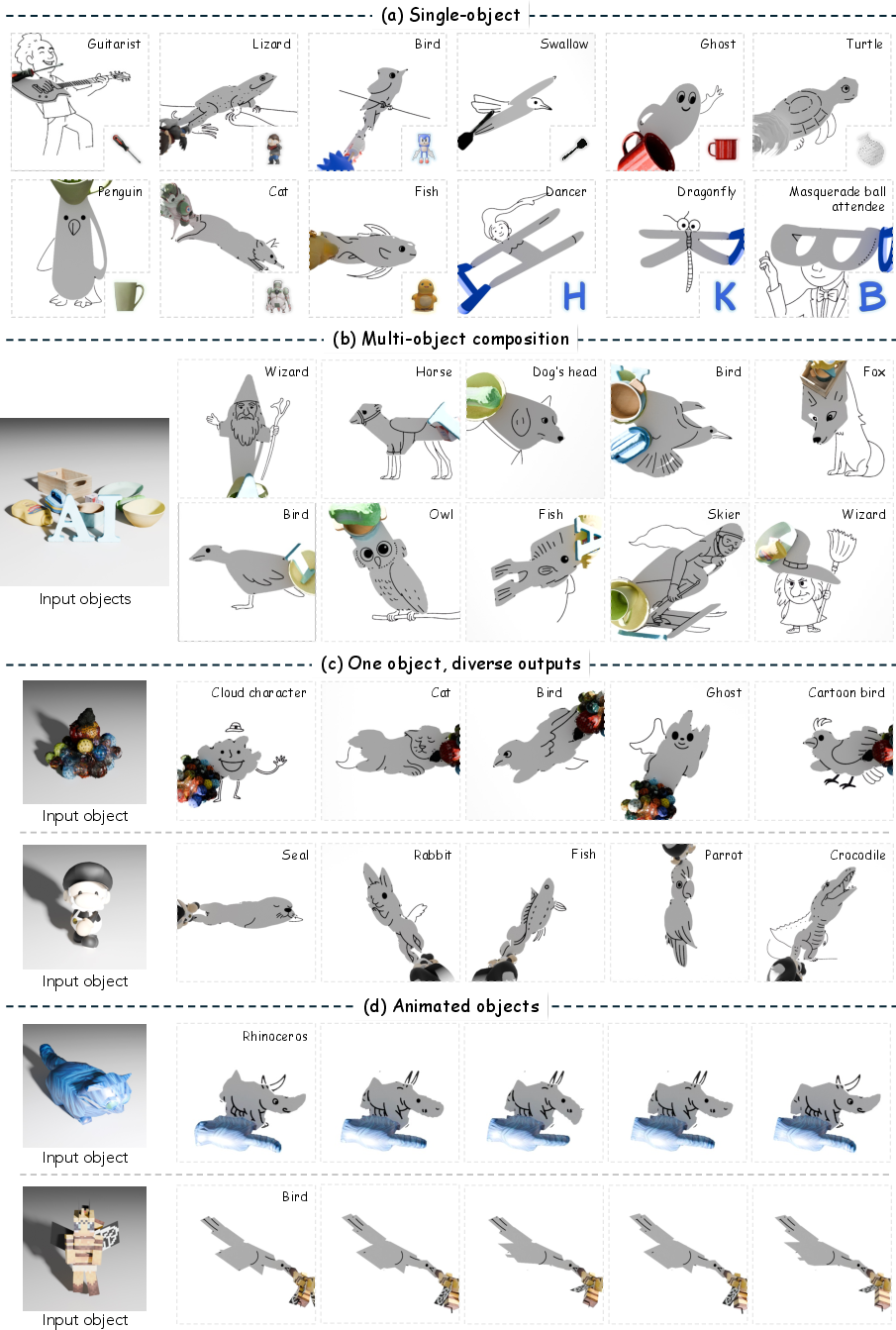
Figure 7: Gallery of results, covering single-/multi-object, pose variation, and animation scenarios.
User-specified Subject Control and Failure Modes
Prompt editing enables subject control, though feasible mappings depend on geometric affordances provided by the object’s shadow. Ambiguous or uninformative shadows can prevent successful composition, representing an intrinsic limit.
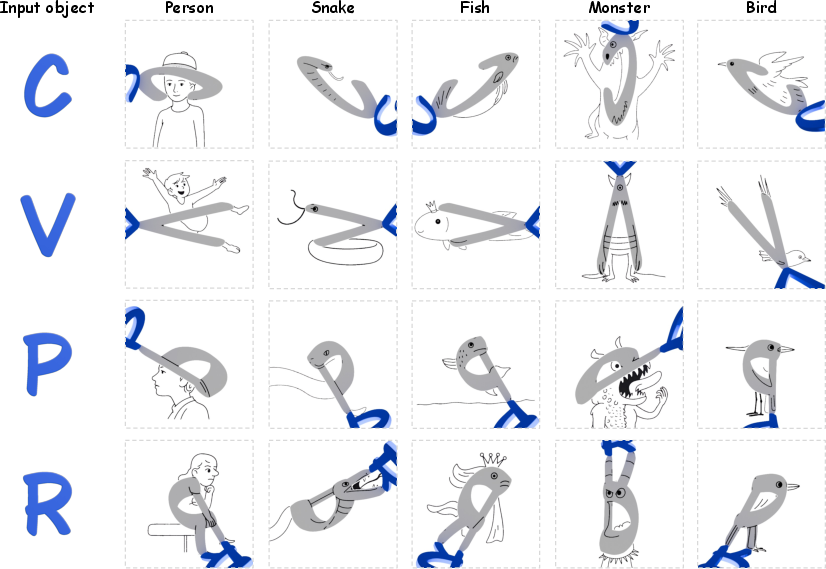
Figure 8: Alphabet-shaped objects, with shadow drawings conditioned on specified subjects; geometry limits achievable compositions in certain cases.
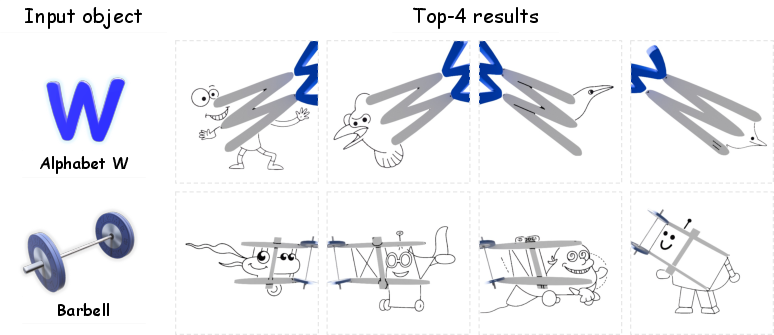
Figure 9: Failure cases arise where object geometry yields uninformative or ambiguous shadows.
Implications and Prospective Directions
ShadowDraw has significant implications for computational art pipelines and generative design:
- It demonstrates that integrating physics-grounded rendering (actual shadow casting) with generative models unlocks a new hybrid compositional paradigm.
- Automated ranking and filtering, coupled with VLM-based semantic reasoning, enables the scaling of subjective, highly creative workflows and provides a strong template for similar endeavors in computational art and design.
- The method’s accessibility—requiring minimal physical setup—broadens participation in computational visual art and allows direct real-world deployment.
Future research may develop improved shadow quality metrics, faster generative architectures (to mitigate diffusion runtime costs), and richer user-in-the-loop systems for ranking and subject control. There is also strong potential for extending this paradigm to broader classes of physical effects (reflections, caustics) and more richly structured multimodal compositions.
Conclusion
ShadowDraw advances the state of computational visual art by algorithmically composing shadow-drawing art from arbitrary 3D objects without a predetermined target, unifying physical rendering with semantic conditioning and robust filtering. It sets a new methodology for bridging generative AI and physical phenomena, delivering both practical creative tooling and expanding the design space for AI-driven art. Limitations remain—most notably the dependency on source object geometry for shadow affordance and runtime constraints—but the framework establishes a scalable, extensible approach for generative hybrid artistry (2512.05110).