- The paper introduces TV2TV, a unified framework that interleaves text planning and video chunk generation to enhance semantic consistency and enable mid-sequence user control.
- It employs a Mixture-of-Transformers with modality-specific towers and innovative autoregressive switching to facilitate dynamic reasoning and video synthesis.
- Empirical results show significant improvements in visual quality and intervention correctness over existing T2V and plan-then-render baselines across gameplay and real sports domains.
TV2TV: A Unified Generative Framework for Interleaved Language and Video Generation
Motivation and Problem Setting
Standard video generation methods, despite advances in visual fidelity, exhibit systematic limitations when tasked with generating sequences requiring high-level semantic reasoning, temporally extended planning, or controllable action-based interventions. Prior works attempt either pure text-conditioned video generation or structured action-to-video simulation, and neither approach is capable of optimal long-term semantic consistency or fine-grained, open-vocabulary user control. "{TV2TV: A Unified Framework for Interleaved Language and Video Generation" (2512.05103) introduces a unified multimodal formulation where video generation is decomposed into an interleaved process of text planning and video rendering, enabling the model to dynamically alternate between reasoning in language and synthesizing in pixels.








Figure 1: TV2TV interleaves language-based planning and video chunk generation, enabling user prompting and intervention at any stage for flexible video control.
Methodology
Architectural Design
TV2TV utilizes a Mixture-of-Transformers (MoT) backbone with dedicated transformer “towers” for text and video modalities, architecturally derived from Transfusion. Text tokens are initialized from a pretrained LLM (Llama), while video segments are tokenized using a VAE-based, causal 3D CNN-based quantizer, producing a temporally compressed latent representation (1 token per 0.25s of video at 16 FPS). Input sequences are chronologically interleaved: segments of text and frame chunks, utilizing a hybrid attention mask to maintain causality and allow intra-chunk bidirectional attention within videos. To train the model with efficient context and denoising, noisy and clean latent representations of each frame chunk are maintained in the sequence, enabling flow-matching training.
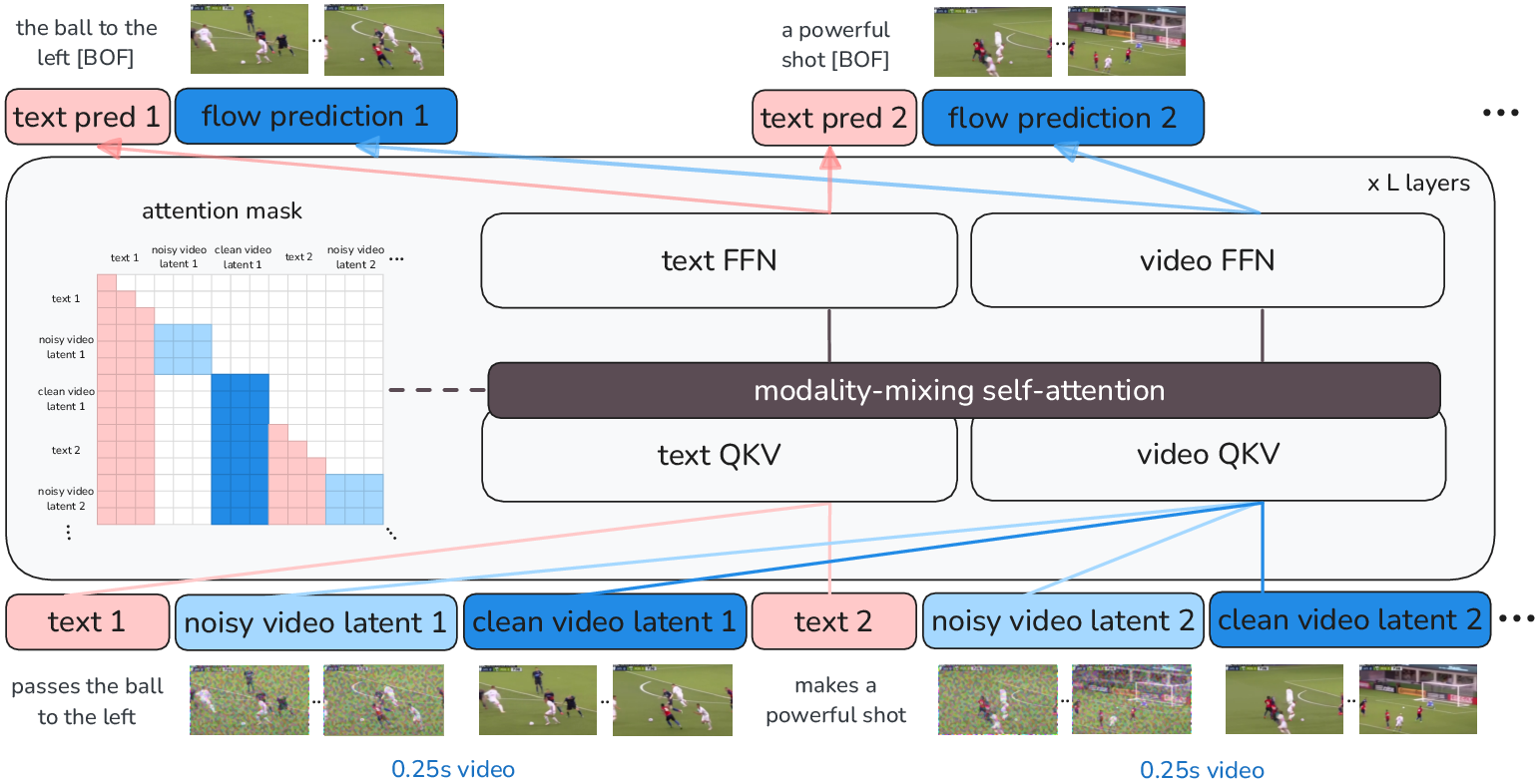
Figure 2: TV2TV builds upon a MoT architecture with modality-specific towers and a unified timeline for autoregressive interleaved generation.
Inference and Controllability
During inference, the model autoregressively generates tokens, dynamically switching between text and video generation using special control tokens (BOF/EOF). This design enables the model to “think” (i.e., produce next-step textual plans) and then “act” (produce corresponding video chunks) at will. At any step, users may insert or modify textual plan segments to steer ongoing video synthesis. The autoregressive formulation permits sliding-window inference, facilitating extensible video generation beyond strictly trained context size.
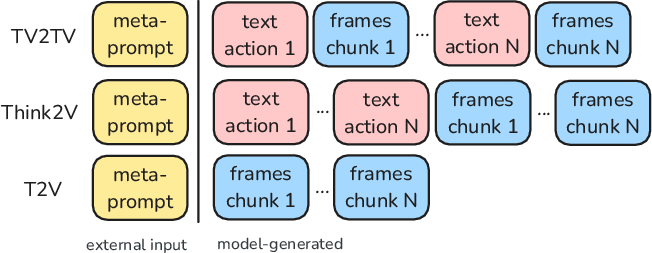
Figure 3: Sequence representations for TV2TV, T2V (no interleaving), and Think2V (plan-then-generate) highlight different planning strategies; TV2TV uniquely enables mid-sequence intervention.
Training and Datasets
Video Game Domain Experiments
For empirical validation, TV2TV and two baselines—T2V (no mid-sequence text) and Think2V (all text upfront, then video)—are trained on Counter-Strike: Global Offensive (CS:GO) gameplay data paired with temporally synchronized controller actions as text. The video sequences span 95 hours, upsampled and tokenized to the model’s input format.
Real-World Sports Domain Scaling
To extend interleaved training to open-domain video, the authors construct a dense interleaved text/video corpus by augmenting 8K hours of real sports videos (mined from YT-Temporal-1B) with meta-captions and differential segment captions generated by VLMs (Qwen3-VL) at fine-grained intervals. The data pipeline performs motion-, face-, and quality-based filtering, automated scene segmentation, and hierarchical chunking prior to VLM captioning.
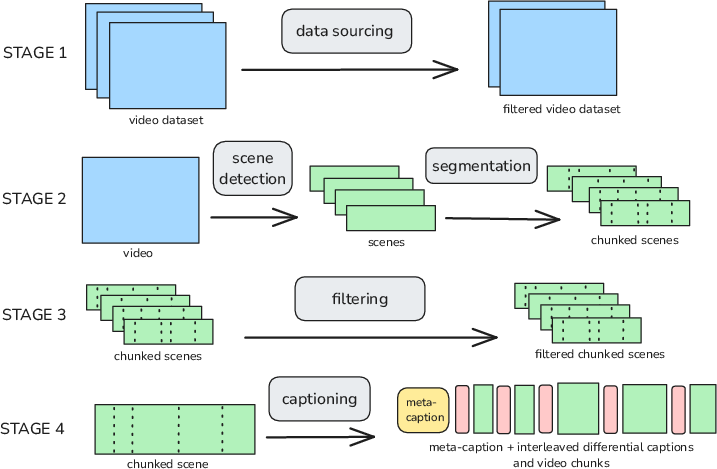
Figure 4: Interleaved data pipeline uses VLM-based captioning and content-aware segmentation for synthetic annotation of large-scale real-world video.
Experimental Results
Human Evaluation: Video Quality and Controllability
Paired human studies on CS:GO reveal that TV2TV achieves strong visual qualitative advantages and controllability improvements:
- In pairwise preference, TV2TV is chosen for visual quality over T2V in 91% of cases and over Think2V in 48% (with 8% and 38% ties, respectively), for both short (6s) and long (64s) rollouts.
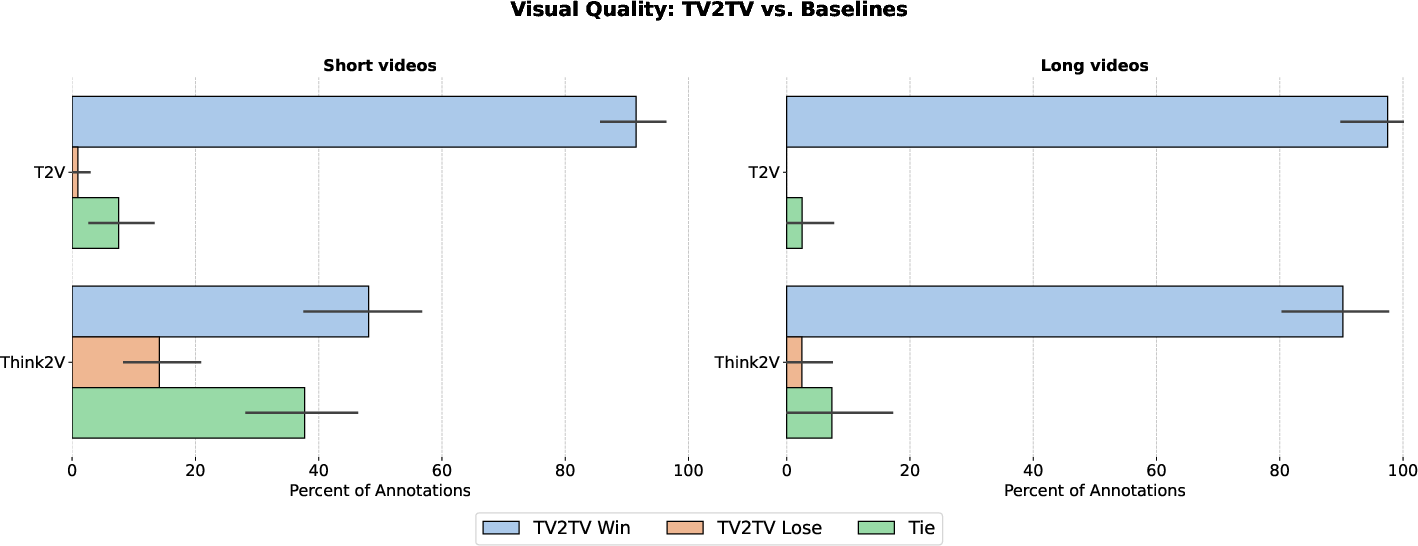
Figure 5: Human visual quality preference rates for TV2TV significantly outperform T2V and Think2V in both short and long-form settings.
- On fine-grained controllability, TV2TV yields a 19-point higher intervention correctness (0.782 vs. 0.591) over Think2V when evaluated for user-directed mid-video action changes (jump, left-click, reload, backward), with robust gains for highly dynamic interventions.
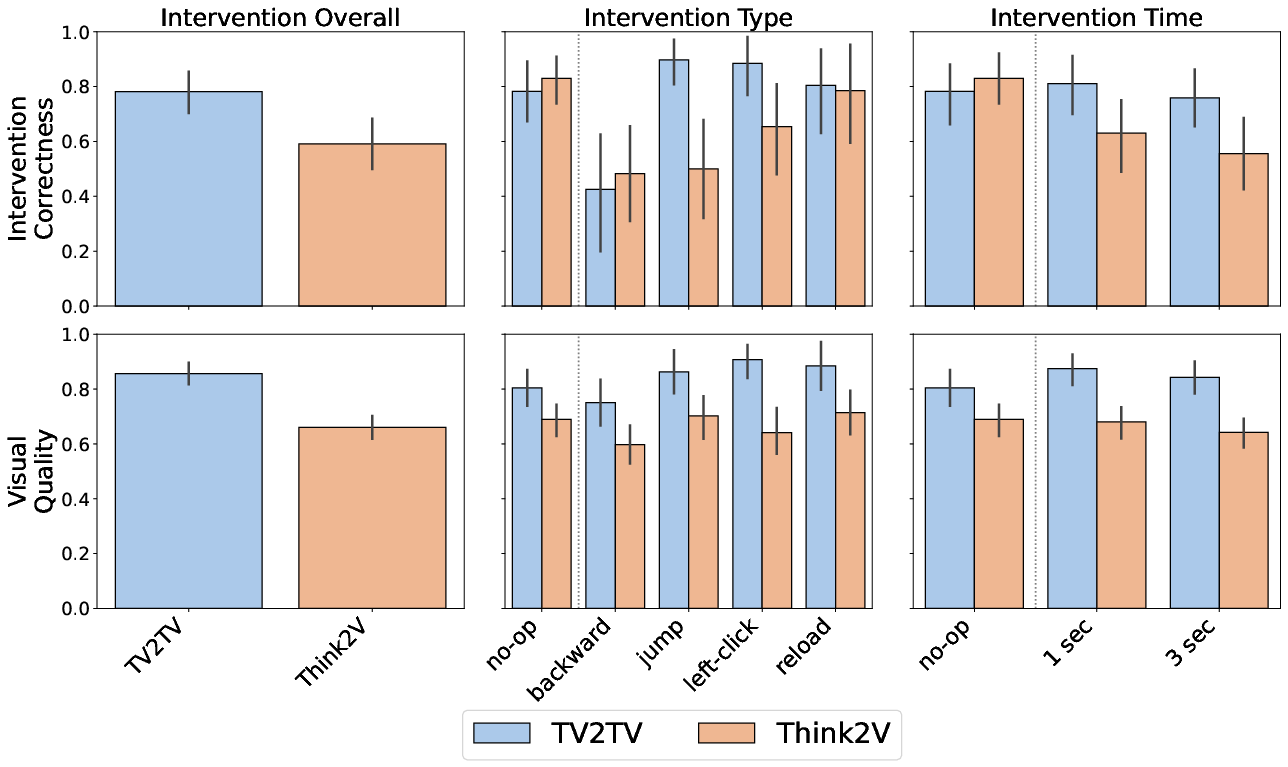
Figure 6: TV2TV provides strong improvement in intervention correctness and visual quality during user-driven interventions compared to Think2V.
Out-of-Domain and Baseline Comparisons
When scaled to real sports data, TV2TV demonstrates:
- Superior prompt alignment, real-world fidelity, and holistic preference over Cosmos2 variants, competitive results with MAGI-1, and only lags behind WAN 2.2 5B in raw visual quality when evaluated blind by external annotators on the sports domain.
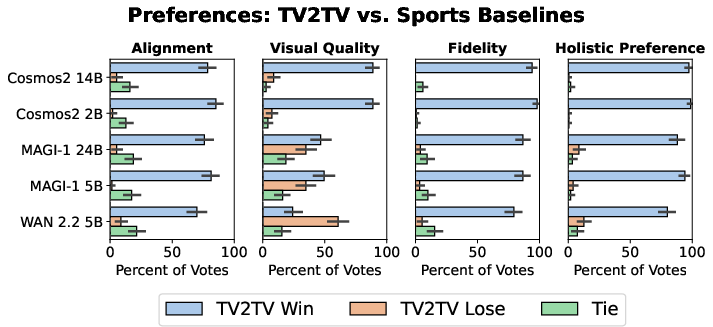
Figure 7: TV2TV surpasses Cosmos2 baselines and performs competitively with MAGI-1 and WAN 2.2 5B for sports generation alignment and quality.
- Against controlled baselines (T2V and Think2V), TV2TV achieves an overall preference win-rate +19 points over T2V and +12 points over Think2V, with improved alignment and comparable fidelity, even though VLM-generated captions are less temporally dense and noisier than CS:GO action text.
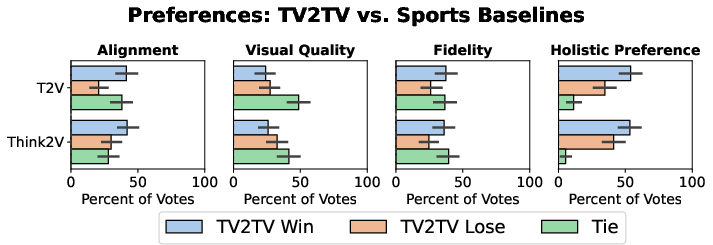
Figure 8: TV2TV provides improved holistic preference and alignment compared to T2V and Think2V in a controlled sports setup.
Discussion and Implications
TV2TV’s unified interleaved planning and synthesis paradigm leverages LLM reasoning to reduce entropy in video generation and exposes high-level control handles to the user, a capability previously reserved for pipeline designs with explicit, rigid action interfaces. Strong empirical results establish both the architectural efficiency of the MoT-autoregressive flow hybrid and the practical value of flexible, text-driven control, especially for tasks requiring mid-sequence intervention and robust long-horizon planning.
The quality of interleaved text annotations directly impacts downstream controllability and semantic consistency; hand-structured action text (as in CS:GO) produces larger gains vs. synthetic VLM captions (as in sports), suggesting that future research should focus on obtaining richer, more temporally dense action descriptions. Advances in VLMs for event detection and differential captioning will facilitate further improvements.
Practically, the framework unlocks accessible user steering for real-world video generation systems, blurring the boundary between reasoning and rendering and enabling applications in dynamic media authoring, interactive simulation, and vision-language agent planning. Theoretically, TV2TV strengthens the link between autoregressive LLMs and multimodal world models, providing evidence that explicit text-based reasoning at generation time confers sample-efficiency and controllability advantages over monolithic video diffusion or plan-then-render splits.
Conclusion
TV2TV is a unified multimodal generative model that integrates linguistic plan formulation and video synthesis through autoregressively interleaved text and video chunks. Evaluation demonstrates robust improvements in visual quality, prompt alignment, and fine-grained controllability over traditional T2V and non-interleaved baselines across both synthetic (CS:GO) and real (sports) domains. The architecture's flexibility makes it a credible candidate for future interactive video synthesis and agent control scenarios, with downstream success contingent on more granular and accurate interleaved annotation pipelines and advances in joint vision-language representation learning.