- The paper introduces a novel self-supervised framework that simulates task-specific missing depth in non-transparent regions to complete transparent object depth maps.
- The method leverages semantic segmentation and localized masking to accurately mimic real missing depth patterns, achieving impressive metrics on the TransCG dataset.
- Experiments demonstrate that SSL pre-training boosts performance in low-data scenarios, reducing manual annotation costs and enhancing scalability.
Self-Supervised Learning for Transparent Object Depth Completion via Non-Transparent Depth Simulation
Problem Motivation and Context
Depth acquisition for transparent objects remains a persistent challenge in computer vision due to their violation of the Lambertian assumption, rendering conventional RGB-D sensors ineffective because of refraction and reflection. Existing transparent object depth completion (TODC) methods largely depend on supervised paradigms, entailing significant annotation burdens as ground truth for transparent object depth maps cannot be directly captured and must be manually generated. While self-supervised learning (SSL) has gained traction to circumvent the labeling bottleneck, prior SSL approaches fail to capture the unique local, region-specific nature of transparent object depth absence—typically introducing global random masks that do not mirror transparent object depth loss patterns.
Core Contributions and Methodology
This work introduces a novel self-supervised strategy for TODC, leveraging non-transparent object regions to simulate transparent object depth absence. The critical insight is that scene regions corresponding to non-transparent objects, whose true depth is available, can be artificially masked to emulate patterns of missing depth observed in transparent objects. This masking is conducted with precision by employing semantic segmentation (using Segment Anything Model, SAM) to localize non-transparent and transparent regions, followed by morphological erosion to preserve boundary information and better mimic the partial depth loss characteristics.
The self-supervised pipeline comprises three steps: (1) segmentation mask generation, (2) selective depth value masking inside non-transparent regions (excluding edges, which depth sensors often capture even for transparent objects), and (3) training a TODC network (here TDCNet) to predict the complete depth map from the masked RGB-D input, with the original depth map (with only non-transparent objects' depth present) as supervision. Notably, transparent regions in both input and supervision are consistently masked out to avoid spurious gradients.
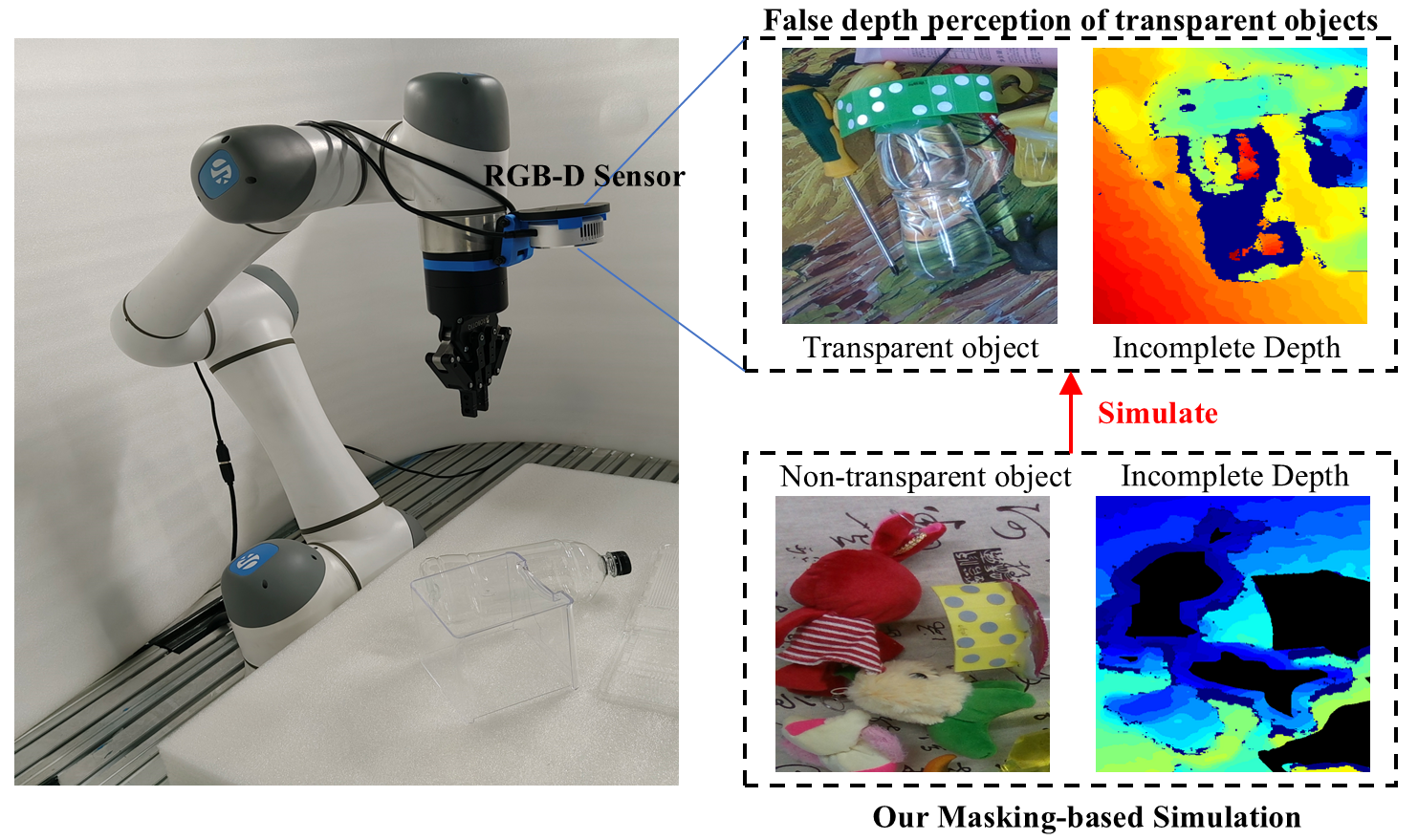
Figure 1: When the RGB-D sensor captures the depth of a transparent object, a localized depth deficit occurs. We simulate this effect in the non-transparent object region through artificial masking.
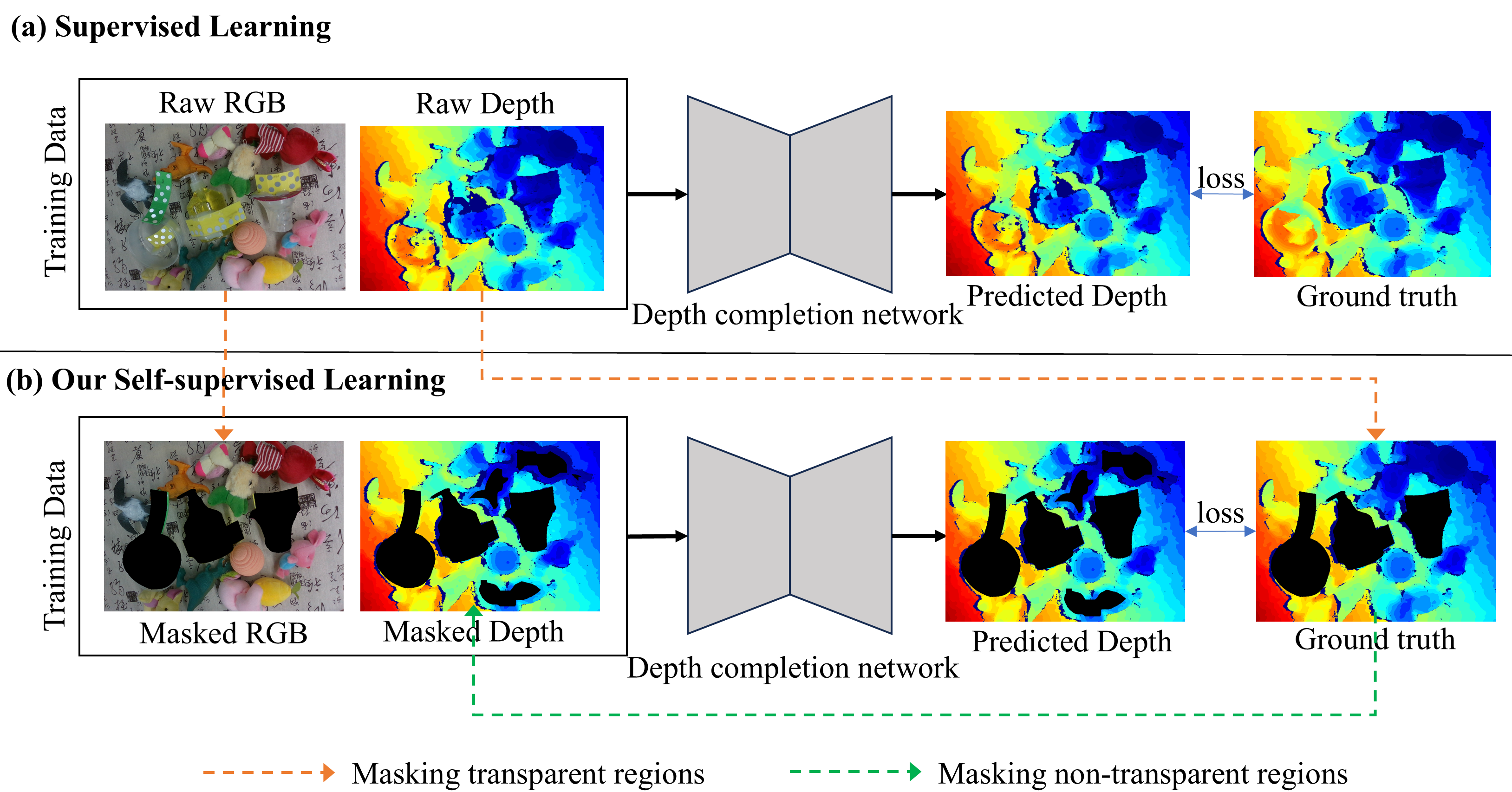
Figure 2: Pipelines of supervised learning and our self-supervised learning. We use masked input data from the supervised process to perform self-supervised learning, without relying on the full transparent object depth map at any point.
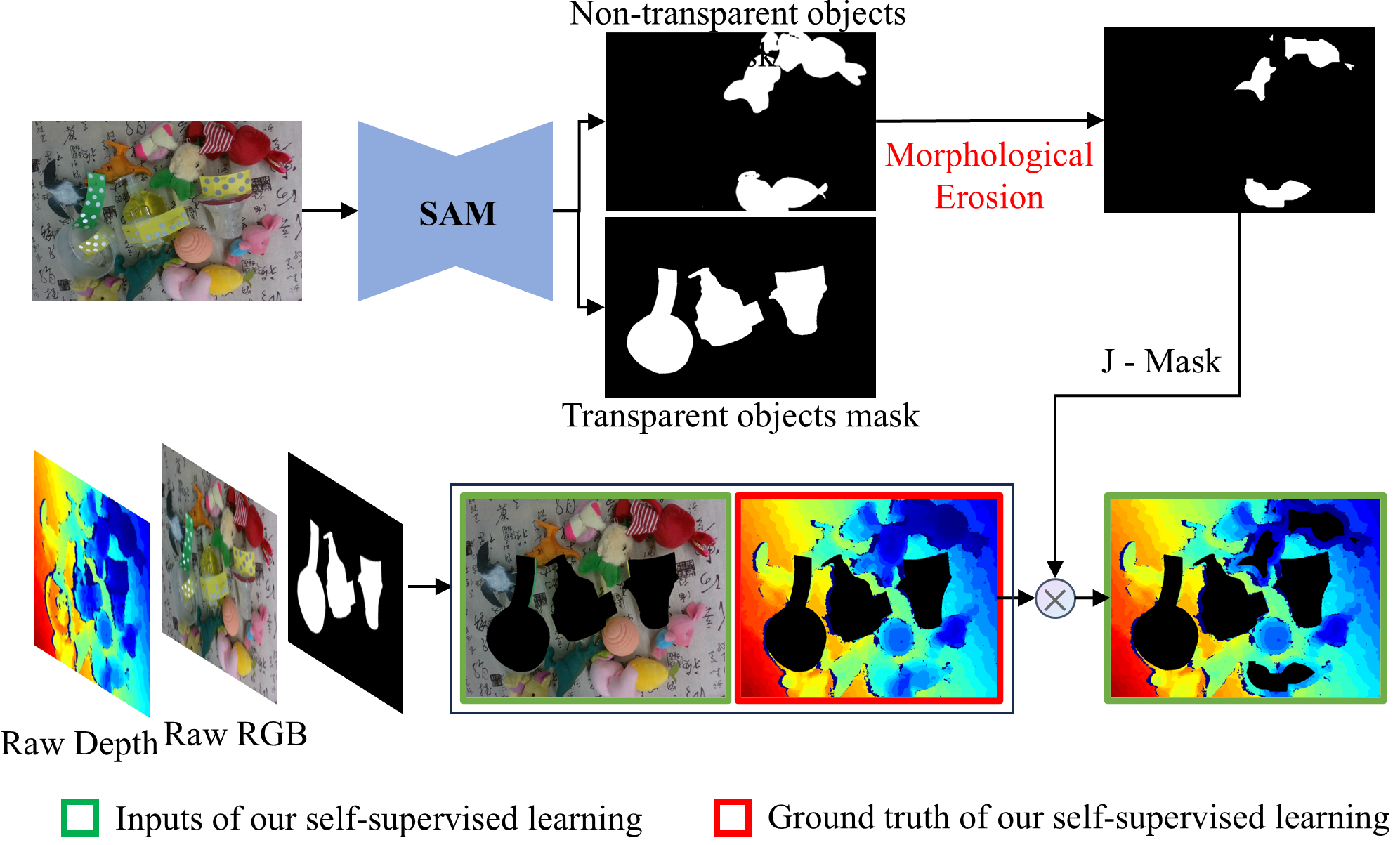
Figure 3: The proposed masking strategy, which non-randomly removes depth inside non-transparent regions while eroding their boundaries.
The loss function used in self-supervised training is a combination of pixel-wise L2 depth errors and normal vector consistency outside transparent regions. Upon SSL pre-training, optional supervised fine-tuning is feasible if limited annotated data become available.
Experimental Evaluation
Evaluation is conducted on the TransCG dataset, which contains both transparent and non-transparent objects, providing an ideal test bed for this paradigm. The quantitative metrics employed are RMSE, REL, MAE, and thresholded accuracy on transparent object regions. The proposed self-supervised method achieves 81.74% 1.05-thresholded accuracy, RMSE of 0.026, and REL of 0.029, surpassing the global MAE-based self-supervision strategy which yields 73.88%, 0.029, and 0.037, respectively. The best supervised method (TDCNet) achieves 92.37% threshold-1.05 and 0.012 RMSE, indicating that the proposed SSL pipeline narrows the gap, reaching approximately 70–88% of the top supervised performance, and outperforms previous non-end-to-end methods (e.g., CG).

Figure 4: Qualitative results of our full self-supervised learning method compared to other methods on the TransCG dataset; lower relative error regions are visually evident.
In low-data supervised fine-tuning scenarios (5%–10% labeled data), pre-training with the proposed SSL approach consistently yields superior results over MAE pre-training or random initialization. For instance, with 10% of labeled data, fine-tuning after this SSL pre-training reaches 81.79% threshold-1.05 and RMSE of 0.018.
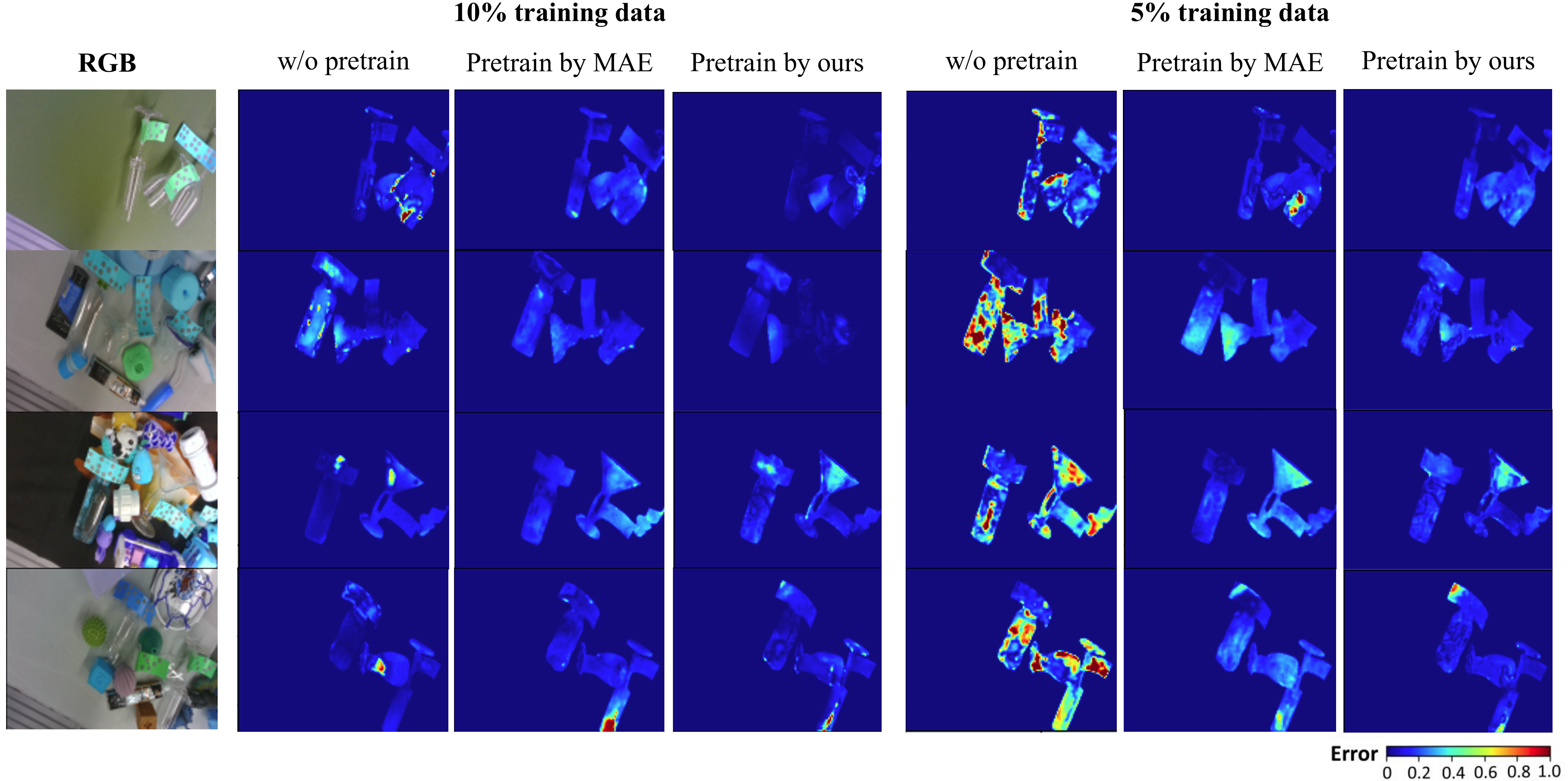
Figure 5: Qualitative comparison of fine-tuning results using the self-supervised pre-training versus other methods, highlighting improved reconstructions with SSL pre-training.
An ablation study confirms that the proposed local erosion-based masking improves performance over full central masking, underscoring the importance of mimicking real missing-depth structures.
Practical and Theoretical Implications
This method obviates the necessity of annotated depth maps of transparent objects by converting the SSL task to one solvable using only conventional object depth observations, thus lowering data collection cost for TODC and increasing scalability to new environments. The work demonstrates that simulation of task-relevant depth absence using precise, context-aware masking is substantially more effective than global random maskings for transferable feature learning. Theoretically, this raises potential for task-driven SSL in other scenarios where ground-truth acquisition is inherently difficult or infeasible.
However, the approach is dataset-dependent; it requires the simultaneous presence of both transparent and non-transparent objects to simulate the masking regimes. Additionally, simulated masking inevitably diverges from the physical optics of transparent objects (e.g., central masking cannot fully replicate refractive boundary phenomena), suggesting room for more physically-accurate simulation techniques in future work.
Speculation on Future Directions
Potential avenues include adapting the masking simulation process via generative modeling to further close the distributional gap between artificial and real missing-depth patterns, extending to other adverse sensing scenarios (e.g., specular, translucent surfaces), and developing fully unsupervised or self-adaptive pipelines that can refine masks without reliance on off-the-shelf detectors like SAM. Integration with domain adaptation or self-training may further improve zero-shot generalization. There is also opportunity to port this framework to robotic applications requiring robust depth sensing in manipulation scenarios with limited annotated data.
Conclusion
The paper presents a self-supervised learning framework for transparent object depth completion that exploits the depth from non-transparent objects to simulate training conditions that mirror the unique challenges of transparent object perception. By introducing task-mimetic, region-specific masking and leveraging high-quality semantic segmentation, the method achieves performance close to supervised baselines, particularly excelling in low-label regimes. The approach signals an efficient, scalable path for TODC, sets foundation for SSL approaches tailored to challenging visual phenomena, and opens prospects for more generalizable SSL strategies in physically-plausible depth completion.