- The paper introduces a novel Tensor-NP classification framework that achieves finite-sample Type I error control for high-dimensional tensor data.
- It develops two models—T-LDA-NP and T-NN-NP—that combine tensor geometry with deep learning to enhance error control and classification accuracy.
- Extensive theoretical analysis and empirical validations demonstrate robust performance and improved reliability in asymmetric-risk biochemical screening.
Tensor Neyman-Pearson Classification: Theory, Algorithms, and Error Control
Introduction
The paper introduces a novel "Tensor Neyman-Pearson (Tensor-NP) Classification" framework which addresses the complex challenges posed by asymmetric error risks in biochemical data classification. Traditional methods lack finite-sample guarantees for controlling Type I errors in tensor classifiers, especially when dealing with molecular data represented as high-dimensional multiway arrays derived from molecular graphs. In applications such as mutagenicity and carcinogenicity screening, the risk of misclassifying harmful compounds is asymmetrically more critical than false alarms. Modern deep learning and tensor classifiers often fail to provide statistical reliability and finite-sample guarantees crucial for such high-stakes decisions.
Proposed Methods
The Tensor-NP classification framework establishes finite-sample control of Type I errors while leveraging the inherent multi-mode structure of tensor data. The framework is based on a tensor-normal mixture model, where the oracle NP discriminant is characterized by its Tucker low-rank manifold geometry. This geometric characterization enables deriving high-probability bounds on excess Type II error through conditional margin and detection conditions tailored for tensor data.
Tensor-Based Models and Algorithms
Two primary models are highlighted:
- Tensor Linear Discriminant Analysis (T-LDA-NP): The T-LDA-NP model assumes a tensor-normal distribution for predictors, allowing for a closed-form solution for the oracle classifier under controlled Type I error conditions. The Discriminant Tensor Iterative Projection (DTIP) estimator ensures Tucker low-rank manifold geometry, facilitating finite-sample NP oracle inequalities adapting to tensor dimensions and ranks.
- Tensor Neural Network NP Classifier (T-NN-NP): This utilizes deep learning integrated with tensor-specific architecture, including tensor contraction layers (TCLs) to maintain multi-mode dependencies. These layers significantly reduce parameters and enhance structural representation while the NP umbrella algorithm guarantees type I error control, making T-NN-NP model-agnostic and distribution-free.
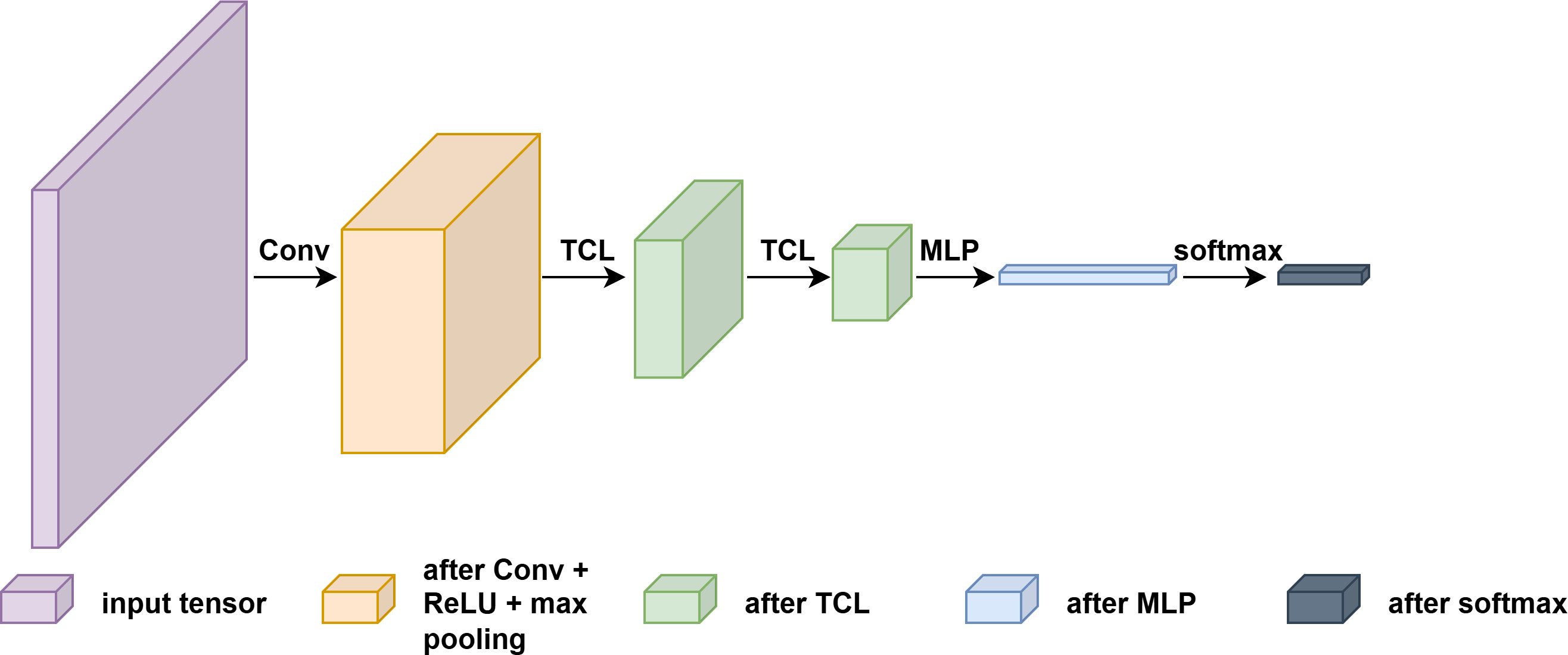
Figure 1: The architecture diagram of the tensor neural network model in T-NN and T-NN-NP.
Theoretical Foundations
The theoretical analysis substantiates the finite-sample error control as follows:
Results
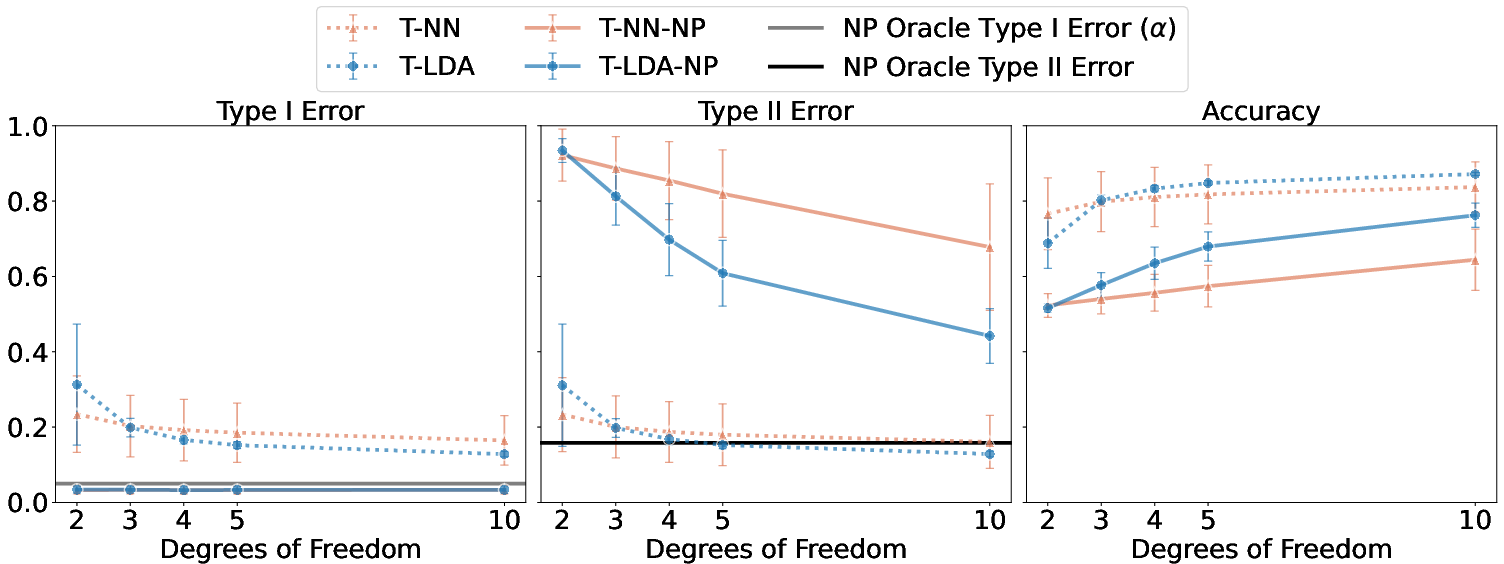
Extensive empirical analyses validate the efficacy of Tensor-NP classifiers across synthetic datasets representing tensor data and real-world biochemical datasets like MUTAG, COX2, and BZR:
- Under varying sample sizes and tensor shapes, Tensor-NP classifiers consistently control type I error within target levels, demonstrating adaptability to structural data complexity.
- When compared to traditional neural network models that violate type I error constraints, Tensor-NP frameworks exhibit balanced performance managing asymmetric risks with robust accuracy.
Practical Implications
The Tensor-NP approach greatly impacts asymmetric-risk decision-making scenarios in biochemical applications, promoting reliable classifications in drug discovery pipelines, toxicity screening, and enzyme activity prediction. By uniting tensor structures and NP theoretical guarantees, the framework notably improves reliability and interpretability in high-dimensional data settings that characterize molecular bioscience applications.
Conclusion
Tensor Neyman-Pearson classification represents a significant advance in both deep learning and statistical methodology by delivering reliable type I error control, proving crucial for informed and balanced decisions in asymmetric-risk scenarios. Future work lies in extending tensor NP classification to other structured prediction models ensuring robust asymmetric error control in various scientific domains.