Generative Video Motion Editing with 3D Point Tracks (2512.02015v1)
Abstract: Camera and object motions are central to a video's narrative. However, precisely editing these captured motions remains a significant challenge, especially under complex object movements. Current motion-controlled image-to-video (I2V) approaches often lack full-scene context for consistent video editing, while video-to-video (V2V) methods provide viewpoint changes or basic object translation, but offer limited control over fine-grained object motion. We present a track-conditioned V2V framework that enables joint editing of camera and object motion. We achieve this by conditioning a video generation model on a source video and paired 3D point tracks representing source and target motions. These 3D tracks establish sparse correspondences that transfer rich context from the source video to new motions while preserving spatiotemporal coherence. Crucially, compared to 2D tracks, 3D tracks provide explicit depth cues, allowing the model to resolve depth order and handle occlusions for precise motion editing. Trained in two stages on synthetic and real data, our model supports diverse motion edits, including joint camera/object manipulation, motion transfer, and non-rigid deformation, unlocking new creative potential in video editing.
Sponsor












Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clear Explanation of “Generative Video Motion Editing with 3D Point Tracks”
Overview
This paper introduces a new way to edit how things move in videos. Instead of only changing how the camera moves or only shifting an object a little, the method lets you change both at the same time—precisely and consistently. It uses 3D “point tracks” (think tiny dots that follow parts of objects through time) to guide a smart video model that can re-generate a video with the motion you want while keeping the original look and feel of the scene.
Key Objectives
Here are the main questions the paper tries to answer:
- How can we edit both camera motion (where the camera is looking) and object motion (how things move) in the same video without messing up the scene?
- How can we keep the video consistent over time (no flickering or lost details) when motion changes reveal new parts of the scene?
- Can using 3D information (depth—who is in front or behind) help the model handle occlusions (when one object hides another)?
- How can we train such a model, even though it’s hard to find perfect real-world examples of videos with labeled 3D tracks?
How the Method Works
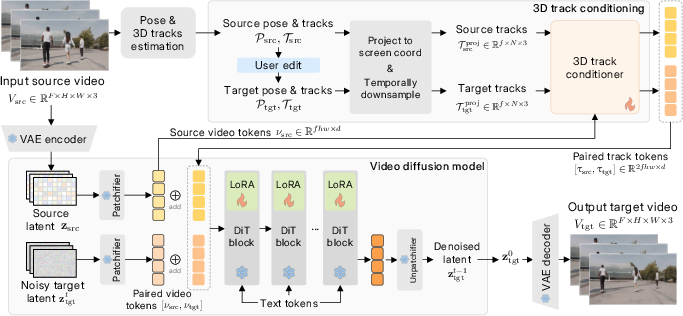
Think of a video like a flipbook and motion like the path a dot takes across its pages. This method uses 3D point tracks—like putting tiny GPS stickers on parts of objects and the background—to describe motion in a way the computer understands.
- 3D point tracks: These are coordinates in 3D space that follow points through video frames. Background points mainly show camera motion; points on the object show how the object moves. Because the tracks are 3D, the model knows who is closer or farther and can handle occlusions (who’s in front when things overlap).
- Using the source video’s “context”: Many older methods only use the first frame (one image) to generate a whole new video. That loses the full scene details. This method feeds the entire input video to the model, so it remembers the scene’s textures, lighting, and small details across time.
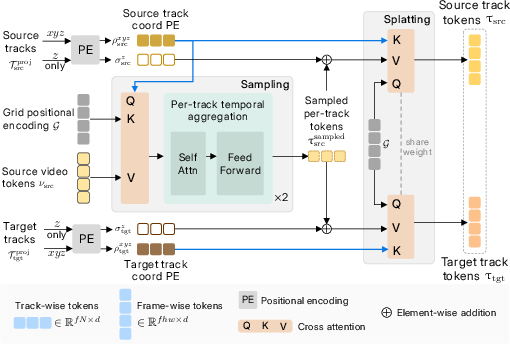
- A “track conditioner” that samples and splats:
- Sampling: Imagine a smart spotlight that looks at the source video and, guided by the 3D track positions, asks “what does this point look like here?” It gathers the right visual info (color, texture) for each track from the source video.
- Splatting: Then it “paints” that sampled info onto the target video’s frames in the right places based on the edited tracks. This builds a bridge between the source video and the new motion you want.
- Depth-aware: The method encodes the “z” (depth) of each track so it can decide which things should appear in front or behind, making occlusions correct.
- A powerful video generator: The model is based on a diffusion model (a type of neural network that starts with noisy frames and gradually “cleans” them into a realistic video). This gives it imagination to fill in parts of the scene that weren’t visible before due to the motion change.
- Two-stage training (so it learns well even with limited perfect data):
- Stage 1: Synthetic training. The team makes animated scenes (like people from Mixamo in Blender) where ground-truth 3D tracks are known, teaching the model precise motion control.
- Stage 2: Real-world fine-tuning. They take regular videos and cut two clips that naturally have different camera/object motion. This helps the model generalize to real, messy footage.
Main Findings and Why They Matter
- Better joint motion editing: The model can change both camera motion and object motion at once, and it keeps the scene consistent. It avoids common problems like missing shadows, wrong depth ordering, or broken textures.
- Stronger control and realism: Compared to other methods, it produces videos that look sharper, more coherent over time, and more faithful to the intended motion. In tests, it achieves higher quality scores (like PSNR and SSIM) and lower error in following the desired tracks.
- Handles occlusions and new content: Because it uses 3D depth, it correctly shows which objects are in front, and the generative model fills in parts of the scene that become visible after editing.
- Versatile applications:
- Change camera paths and object trajectories together.
- Human motion transfer (make one person move like another).
- Shape deformation (subtly change an object’s form, like bending or widening).
- Object removal or duplication (erase something cleanly or duplicate it and move it).
Implications and Impact
This research opens up creative, practical video editing that feels like “motion puppeteering,” but with respect for the scene’s realism:
- Filmmakers and creators can fix camera moves or adjust an actor’s motion after filming without reshooting.
- Sports and education can visualize alternative motions clearly (e.g., how a dancer or athlete could move differently).
- AR/VR and game design can benefit from realistic motion edits that preserve scene detail.
- Future tools may let everyday users edit video motion as easily as dragging points on the screen.
The paper also notes current limits: very dense tracks on tiny objects can be tricky, and realistic physics (like splashes or complex cloth motion) can still be challenging. As generative models improve and more training data becomes available, these limitations should shrink, making motion editing even more accurate and accessible.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
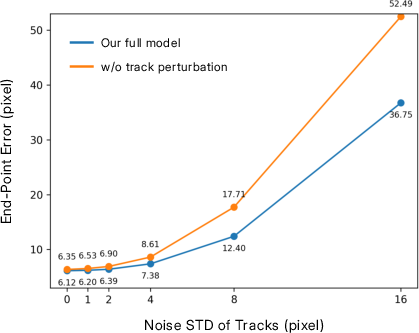
- Robustness to 3D track errors: The method relies on off-the-shelf depth/pose and 3D point tracking (e.g., SPA-Tracker2, TAP-IP3D). There is no formal analysis of failure modes under track noise, drift, outliers, or mis-associations, nor mechanisms to incorporate track uncertainty/confidence into conditioning.
- Occlusion/visibility modeling: The approach explicitly avoids using visibility labels post-edit, leaving occlusion reasoning entirely implicit. How to estimate and leverage edited visibility (including reprojected self-occlusions and inter-object occlusions) remains an open question.
- Depth scale and camera intrinsics: Tracks use normalized disparity (), which may cause scale ambiguity across scenes. The impact of inaccurate camera intrinsics/poses and the potential benefits of metric depth or intrinsic-aware conditioning are not studied.
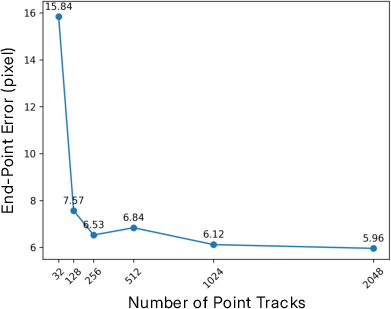
- Track density and small objects: The model struggles when tracks are densely clustered (especially on small or thin objects). A principled strategy for multi-scale track conditioning, track selection/pruning, and handling variable track densities is missing.
- Temporal downsampling of tracks: Projected 3D tracks are temporally downsampled; the effect on fine-grained, high-frequency motion control and temporal coherence is not quantified or ablated.
- Edit magnitude vs. reliability: The paper shows “unrealistic editing scenarios” qualitatively but does not systematically characterize how edit magnitude (e.g., large viewpoint/pose changes) affects fidelity, stability, and failure rates.
- Longer videos and scalability: The backbone generates 81-frame videos at 384×672 and takes ~4.5 minutes on an A100. Scalability to higher resolution, longer durations, and multi-minute sequences, as well as memory/computation constraints, is not addressed.
- Real-time/interactive editing: The system’s latency precludes interactive editing workflows; strategies for acceleration (e.g., distillation, cached conditioning, sparse attention, incremental re-rendering) are not explored.
- Secondary physical effects: The method can preserve some “causal effects,” but it fails on complex physical phenomena (fluids, cloth, debris, contact dynamics). How to model or condition physical interactions arising from edited motion is unresolved.
- Multi-object interactions and collisions: There is no explicit modeling of inter-object contacts, constraints, or collisions under edits; producing physically plausible outcomes in multi-agent scenes remains open.
- Lighting and shadows after edits: Handling of edited object shadows, reflections, and relighting is inconsistent; no dedicated lighting-aware conditioning or evaluation is provided.
- Editing camera intrinsics and sensor effects: Beyond viewpoint changes, the system does not explore zoom/focal length changes, rolling shutter, lens distortion, exposure changes, or motion blur control.
- Shape deformation generality: Non-rigid edits rely on simple point group transforms and interpolation (akin to linear blending). Generalization to arbitrary deformables (e.g., soft bodies), topology changes, or muscle/cloth dynamics is not evaluated.
- Human motion transfer fidelity: SMPL-X–based transfers are demonstrated, but there is no quantitative assessment using human motion metrics (e.g., pose/kinematic accuracy, biomechanics plausibility), nor exploration of multi-person constraints or contacts.
- Edit faithfulness metrics: Motion control is evaluated via 2D EPE; 3D compliance (e.g., 3D track error, depth-consistent adherence) is not measured. Better metrics for 3D motion edit faithfulness and covisibility-aware evaluation are needed.
- Dataset construction and biases: Real data pairs are built by sampling non-contiguous clips from monocular videos. Potential selection bias, scene diversity, and the effect of temporal gaps on track correspondence and model generalization are not analyzed.
- Lack of ground-truth edited pairs: Evaluation relies on pseudo ground truth (non-contiguous clips) and masked metrics; the field lacks a benchmark with controlled joint camera/object motion edits and ground-truth targets for rigorous comparison.
- Segmentation dependence: Foreground masks from SAM2 are used to label tracks; segmentation errors and their propagation to motion edits (e.g., background leakage or missed parts) are not quantified or mitigated.
- Conditioning integration design: The track-conditioned tokens are simply added to video tokens. Alternative integration strategies (e.g., gating, cross-modal attention, adapter routing, confidence weighting) are not compared.
- Generalization across base models: The approach is tied to Wan-2.1 DiT via LoRA; portability to other T2V/V2V backbones (e.g., CogVideoX, HunyuanVideo, SVD, Lumiere) and the effect of backbone differences are untested.
- End-to-end training with trackers: The tracker and pose/depth estimation are not trained jointly with the generator. End-to-end learning (including differentiable visibility, occlusion, and track uncertainty) is unexplored.
- Editing UI and usability: While partial track input is supported, user interfaces for selecting/manipulating 3D tracks (e.g., semantic groups, constraints, keyframing, path smoothing) and usability studies are missing.
- Failure case taxonomy: The paper mentions failures (dense tracks, complex physics) but lacks a systematic categorization and quantitative breakdown of error types across datasets and edit categories.
- Fairness of baseline comparisons: Some baselines are adapted (e.g., inpainting with optical flow or solver extensions). A standardized protocol ensuring fair inputs, masking, and covisibility treatment across methods is needed.
- Ethical considerations and misuse: The capability to manipulate motion (including object removal/duplication) raises risks of deception and misuse. Guidelines, detection, watermarking, or provenance tools are not discussed.
- Reproducibility and release: Details on code, model weights (LoRA adapters, conditioner), and datasets (especially the internal stock video subset) are insufficient for full reproducibility; release plans are not specified.
Glossary
- 3D point tracks: Trajectories of identifiable points through 3D space across video frames, used to represent and control motion. "Our novel framework enables precise video motion editing via 3D point tracks."
- 3D track conditioner: A model component that encodes and aligns 3D point tracks with video tokens to control motion during generation. "3D track conditioner."
- 3D track conditioning: The process of transforming projected 3D tracks into screen-aligned tokens for motion control. "3D track conditioning."
- Bounding boxes: 2D rectangular regions used to select or guide object motion and deformation. "Object-centric approaches~\cite{magicstick,shape-for-motion} enable simple object motion editing (\eg, shifting and resizing) using bounding boxes or 3D meshes, but lack control over camera viewpoints."
- Classifier-free guidance (CFG): A sampling technique that balances conditional and unconditional model predictions to control output strength. "text classifier-free guidance (CFG)~\cite{cfg} scale of 5."
- ControlNet: An adapter architecture that injects explicit control signals (e.g., motion conditions) into diffusion models. "adapters such as ControlNet~\cite{controlnet}, to control the camera and scene dynamics in the generated videos."
- Cross-attention: An attention mechanism that retrieves context from one set of tokens (e.g., video) conditioned on another (e.g., tracks). "our 3D-track conditioner uses cross-attention to perform a learnable sampling-and-splatting process"
- Disparity: Inverse depth values used to encode relative distance in projected tracks. "normalized disparity "
- DiT: Diffusion Transformer; a transformer-based video diffusion architecture with denoising blocks. "Wan-2.1~\cite{wan}, a transformer-based video diffusion model (DiT)"
- End-Point Error (EPE): A metric measuring the distance between predicted and target tracks to assess motion control accuracy. "End-Point Error (EPE), which measures the distance"
- Fréchet Video Distance (FVD): A video-level distributional metric evaluating visual quality and temporal consistency. "Fréchet Video Distance (FVD)~\cite{fvd}"
- Gaussian Splatting: A rendering approach that represents scenes with Gaussian primitives and projects them into views. "lifted into a 4D Gaussian Splatting field~\cite{cat4d,4realvideo,dimensionx,lyra}"
- Generative prior: Learned distributional knowledge in a pretrained model that helps synthesize plausible unseen content. "leverage the strong generative prior of a pretrained text-to-video (T2V) diffusion model~\cite{wan}"
- Image-to-Video (I2V): Models that generate a video sequence from a single input image plus conditioning signals. "image-to-video (I2V) approaches"
- Inpainting: Filling in missing or masked regions of frames to complete content after warping or editing. "Inpainting-based methods~\cite{nvssolver,viewcrafter,reangle,trajcrafter,gen3c,followyourcreation}"
- Latent: A compressed representation in the model’s feature space used during diffusion and decoding. "noisy video latent at step "
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method for large models. "We employ LoRA (rank=64) fine-tuning for our V2V model"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric for visual similarity. "LPIPS~\cite{lpips}"
- Monocular videos: Single-camera videos without synchronized multi-view inputs, used for scalable pair construction. "monocular videos."
- Multi-view diffusion models: Generative models that produce consistent multi-view video outputs from an input. "Multi-view diffusion models~\cite{stablevirtualcam,syncammaster,cat4d,4realvideo,dimensionx,lyra} input a video to generate multi-view videos"
- Nearest-neighbor sampling: A simple sampling method that selects the closest frame or point without interpolation. "via nearest-neighbor sampling"
- Novel view synthesis: Generating videos from new camera viewpoints not present in the input. "Editing camera viewpoints of an input video, often known as novel view synthesis"
- Occlusions: Visibility events where objects block each other in depth, complicating motion and correspondence. "handle occlusions for precise motion editing."
- Patchifier: A component that splits latents into patch tokens for transformer processing. "encoded by a VAE and patchifier into source tokens "
- Point trajectories: Time-indexed sequences of point positions (2D or 3D) used to represent motion. "we adopt point trajectories~\cite{sand2008particle,harley2022particle,tapip3d} as a general motion representation"
- Positional encoding: Encodings that inject coordinate or index information into tokens for attention. "We first apply positional encoding to map the 3D track's into token embeddings"
- PSNR: Peak Signal-to-Noise Ratio; a fidelity metric comparing generated and reference videos. "We report PSNR, SSIM~\cite{ssim}, and LPIPS~\cite{lpips}"
- Rectified Flow: A training objective for diffusion models improving convergence and sample quality. "Rectified Flow objective~\cite{rectflow}"
- Sampling-and-splatting: A two-step process to gather context at track coordinates and project it into frame space. "sampling-and-splatting process"
- SMPL-X: A parametric 3D human body model with expressive shape and pose. "SMPL-X~\cite{smplx}"
- Sparse correspondences: Limited point-to-point matches used to transfer context between motions. "These 3D tracks establish sparse correspondences that transfer rich context from the source video to new motions"
- Spatiotemporal coherence: Consistency across space and time in edited videos. "preserving spatiotemporal coherence."
- SSIM: Structural Similarity Index; a perceptual metric comparing structural fidelity. "SSIM~\cite{ssim}"
- Text-to-Video (T2V): Models that synthesize video directly from text prompts. "text-to-video (T2V) diffusion model~\cite{wan}"
- Tokens: Discrete units (patch embeddings) processed by transformers for video generation. "video tokens"
- Transformer: Attention-based neural network architecture used in the diffusion pipeline. "Transformer~\cite{transformer} blocks"
- VAE: Variational Autoencoder; an encoder-decoder used to map images/videos to and from latents. "decoded back to the target RGB video, by the VAE decoder."
- Video-to-Video (V2V): Models that transform an input video into an edited output with controlled motion. "motion-controlled video-to-video (V2V) model"
Practical Applications
Immediate Applications
Below is a set of actionable use cases that can be deployed now, grounded in the paper’s Edit-by-Track framework and its demonstrated capabilities. Each item names sectors, suggests potential tools/products/workflows, and notes assumptions or dependencies that affect feasibility.
- Joint camera and object motion editing for post-production (media/entertainment, advertising)
- Use case: Correct camera trajectories (e.g., stabilize or reframe), change viewpoints, and finely edit object motion in existing footage to fix timing, blocking, or continuity without reshoots.
- Tools/products: “Edit-by-Track” plugin for Adobe Premiere Pro/After Effects; a cloud API that ingests source video plus edited 3D tracks and returns the final cut.
- Workflow: Ingest the entire video → auto-estimate 3D tracks, depth, and camera poses → user edits camera/object tracks → generate target video with spatiotemporal coherence.
- Assumptions/dependencies: Quality of 3D point tracking and depth/pose estimation (e.g., SpaTracker2, TAPIP-3D); moderate GPU compute (~4.5 minutes for 81 frames at 672×384 on A100); limitations in reproducing complex physical effects (splashes, shadows) after edits.
- Viewpoint change with simultaneous object removal or duplication (media/entertainment, advertising, social platforms)
- Use case: Remove a distracting object while reframing to a new camera angle, or duplicate an object for compositional balance without re-shooting.
- Tools/products: Object removal/duplication module integrated into motion-aware V2V editor; production-ready “Remove-and-Reframe” workflow.
- Workflow: Segment targets (e.g., via SAM2) → move 3D tracks off-screen for removal or replicate/edit tracks for duplication → render with desired camera motion.
- Assumptions/dependencies: Reliable segmentation and track labeling; generative prior to hallucinate unseen content; careful QA for edge cases (thin structures, occlusions).
- Human motion transfer with identity preservation (media/entertainment, creator tools, education)
- Use case: Transfer local pose (θ) from one dancer/performer to another while maintaining shape (β) and global pose using SMPL-X, enabling choreography remixes or synchronized ensembles.
- Tools/products: “Motion Transfer Studio” for dance/music videos; classroom demos for movement studies.
- Workflow: Estimate SMPL-X on source and target → swap local poses → reconstruct mesh vertices → generate edited video via track-conditioned V2V model.
- Assumptions/dependencies: Accurate SMPL-X estimation and consistent 3D tracking; ethical use and consent for identity/motion transfer; compute resources for batch production.
- Non-rigid shape deformation and stylization (media, social content, branding)
- Use case: Stylize moving objects (e.g., exaggerate a dog’s gait, reshape props) to achieve comedic or brand-specific visual effects without standalone 3D modeling.
- Tools/products: “Shape Deformer” UI with track group selection and bounding-box-driven transformations.
- Workflow: Select grouped 3D tracks via bounding boxes → apply transformations (similar to linear blend skinning) → render edited motion.
- Assumptions/dependencies: Track coverage over deformable regions; robustness under occlusion; user-friendly controls to avoid artifacts.
- Partial control editing for novice users (consumer apps, social platforms)
- Use case: Adjust only coarse motion aspects (e.g., shift a character’s body) while the system synthesizes plausible motion for unedited parts (e.g., legs).
- Tools/products: “Simple Motion Slider” with minimal controls; presets for common actions (walk, run, turn).
- Workflow: Select coarse region with a bounding box → specify simple transforms → system infers remaining motion.
- Assumptions/dependencies: Model’s learned priors for plausible motion completion; depends on training diversity and robust estimators.
- Multi-version creative generation from one shoot (advertising, e-commerce)
- Use case: Produce A/B variations by changing camera moves and object motion to test different narratives or product emphases without additional filming.
- Tools/products: Batch “Motion Remix” service for agencies; e-commerce video spinner that varies trajectories, pace, and viewpoints.
- Workflow: Define edit sets of camera/object tracks → render variants → push to ad platforms.
- Assumptions/dependencies: Scale-out GPU inference; version control and asset management; approval pipelines for brand compliance.
- Sports highlights re-editing and anonymization (sports media, compliance/privacy)
- Use case: Recompose highlights by adjusting camera paths; anonymize audiences or players (e.g., remove faces or identifiers) while preserving action coherence.
- Tools/products: Broadcast-side “Motion Recomposer & Privacy Editor.”
- Workflow: Estimate tracks and segmentation → edit camera path and remove/blur selected objects → render coherent edits.
- Assumptions/dependencies: Rights and permissions; accurate segmentation; public-interest/privacy policies.
- Education and training content (education, corporate learning)
- Use case: Demonstrate how changes in motion (camera/object) affect perception, narrative, or attention; produce multiple angles of the same procedure for instruction.
- Tools/products: Classroom-ready motion editing kit; corporate training asset generator.
- Workflow: Capture a single demonstration → generate multiple viewpoint/object-motion variants → annotate differences.
- Assumptions/dependencies: Instructor guidance to avoid unrealistic physical consequences; platform integration for LMS delivery.
- Dataset augmentation for computer vision/ML (software/AI research)
- Use case: Augment datasets by varying camera viewpoints and object trajectories to improve robustness of trackers, detectors, and scene understanding models.
- Tools/products: “Synthetic Motion Augmentor” pipeline that takes monocular videos and produces diverse motion variants with labels (tracks, segmentation).
- Workflow: Batch processing of stock/real videos → edit-by-track variants → export annotations.
- Assumptions/dependencies: Annotation transfer consistency; controlling domain gap; licensing for training use.
- Pre-visualization and storyboarding from rehearsal footage (media production)
- Use case: Quickly iterate camera blocking and object motion on rehearsal clips to plan final shots and coverage.
- Tools/products: “Previz by Track” integrated with production planning tools.
- Workflow: Capture rehearsal → edit tracks to explore alternative blocking → evaluate continuity and coverage.
- Assumptions/dependencies: Turnaround time acceptable for production schedules; alignment with DP/director intent.
Long-Term Applications
These use cases are feasible with further research, scaling, or productization, particularly in real-time performance, physically grounded effects, and multi-view/4D integration.
- Real-time or near-real-time live broadcast editing (media)
- Vision: Adjust camera/object motion during live events (e.g., alternative angles for a single camera feed).
- Needed advances: Model efficiency (quantization, distillation), streaming architectures, edge GPU hardware; faster, reliable 3D trackers.
- Assumptions/dependencies: Low-latency pipelines; robust occlusion handling in dynamic crowded scenes.
- Physics-aware motion editing (media, simulation, education)
- Vision: Edit motion while correctly synthesizing secondary effects (splashes, shadows, collisions) and causal outcomes.
- Needed advances: Physically grounded generative priors; hybrid simulation+diffusion models; learned light transport for shadow and reflection consistency.
- Assumptions/dependencies: High-quality training data with physical annotations; integration of differentiable physics engines.
- Multi-view and 4D asset generation from monocular inputs (XR, VFX, gaming)
- Vision: Convert edited videos into consistent multi-view sequences or lift to 4D Gaussian Splatting/NeRF-like representations for re-lighting and interactive playback.
- Needed advances: Stable multi-view diffusion from monocular footage; tighter coupling between 3D tracks and 4D fields; temporal coherence under large edits.
- Assumptions/dependencies: Multi-view consistency checks; robust scene reconstruction under edits.
- Interactive XR/VR video experiences (XR, education, museums)
- Vision: Provide viewers interactive control over camera motion and object behavior within edited volumetric scenes.
- Needed advances: Real-time volumetric rendering; consistent occlusion/depth reasoning; lightweight client rendering.
- Assumptions/dependencies: HMD performance constraints; motion sickness considerations; content licensing.
- Motion-aware creative collaboration platforms (creative software)
- Vision: Shared motion graphs and editable 3D track timelines across teams; versioning and provenance for motion edits.
- Needed advances: Standardized motion track formats; collaborative GUIs; integration with NLEs and asset pipelines.
- Assumptions/dependencies: Interoperability with existing toolchains; user training on track-centric workflows.
- Policy and provenance tooling (policy, compliance, content authenticity)
- Vision: Embed edit provenance (e.g., C2PA) in outputs; watermark motion-edited content; provide audit trails for regulatory compliance.
- Needed advances: Standardization of provenance for motion edits; seamless integration into post-production pipelines.
- Assumptions/dependencies: Adoption by platforms and regulators; balancing privacy and transparency.
- Synthetic data generation for robotics and autonomous systems (robotics, automotive)
- Vision: Create diverse dynamic scenes with controlled motion variations to train perception stacks (tracking, SLAM, occlusion reasoning).
- Needed advances: Domain adaptation pipelines; physically plausible motion edits; scene semantics aligned with robotics datasets.
- Assumptions/dependencies: Label transfer fidelity; alignment with safety-critical evaluation protocols.
- Healthcare and rehabilitation motion coaching (healthcare, sports science)
- Vision: Use motion transfer to demonstrate correct movements while preserving patient identity; generate alternative viewpoints for better instruction.
- Needed advances: Clinical validation; privacy-preserving pipelines; integration with motion capture/EMR systems.
- Assumptions/dependencies: Regulatory compliance (HIPAA/ GDPR); consent and ethical guidelines.
- Advanced educational labs for visual perception and cinematography (academia, film schools)
- Vision: Research and teach how camera/object motion influences perception, attention, and narrative through controlled edits on real footage.
- Needed advances: Benchmarks for motion-edit fidelity; perception studies; tooling for rapid classroom use.
- Assumptions/dependencies: Robustness across diverse scenes; measured learning outcomes.
- Market analytics and creative optimization (finance/ad tech)
- Vision: Systematically test motion variants to optimize engagement metrics and ROI, linking motion parameters to performance.
- Needed advances: Motion parameter logging, A/B testing infrastructure, causal analytics.
- Assumptions/dependencies: Integrations with ad platforms; guardrails for responsible content manipulation.
Collections
Sign up for free to add this paper to one or more collections.