ORION: Teaching Language Models to Reason Efficiently in the Language of Thought
Abstract: Large Reasoning Models (LRMs) achieve strong performance in mathematics, code generation, and task planning, but their reliance on long chains of verbose "thinking" tokens leads to high latency, redundancy, and incoherent reasoning paths. Inspired by the Language of Thought Hypothesis, which posits that human reasoning operates over a symbolic, compositional mental language called Mentalese, we introduce a framework that trains models to reason in a similarly compact style. Mentalese encodes abstract reasoning as ultra-compressed, structured tokens, enabling models to solve complex problems with far fewer steps. To improve both efficiency and accuracy, we propose SHORTER LENGTH PREFERENCE OPTIMIZATION (SLPO), a reinforcement learning method that rewards concise solutions that stay correct, while still allowing longer reasoning when needed. Applied to Mentalese-aligned models, SLPO yields significantly higher compression rates by enabling concise reasoning that preserves the benefits of detailed thinking without the computational overhead. Across benchmarks including AIME 2024 and 2025, MinervaMath, OlympiadBench, Math500, and AMC, our ORION models produce reasoning traces with 4-16x fewer tokens, achieve up to 5x lower inference latency, and reduce training costs by 7-9x relative to the DeepSeek R1 Distilled model, while maintaining 90-98% of its accuracy. ORION also surpasses Claude and ChatGPT-4o by up to 5% in accuracy while maintaining 2x compression. These results show that Mentalese-style compressed reasoning offers a step toward human-like cognitive efficiency, enabling real-time, cost-effective reasoning without sacrificing accuracy.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
ORION: Teaching AI to Think Shorter and Smarter
What is this paper about?
This paper shows a new way to make AI “think” more like people: clearly, in small steps, and without wasting words. The authors create a system called ORION that teaches LLMs to solve hard problems (like math) using short, structured steps instead of long, chatty explanations. This makes the AI faster and cheaper to run, while keeping its answers accurate.
What big questions did the authors ask?
- Can we make AI solve problems using fewer words (fewer “tokens”) without getting worse at solving them?
- Can we train AI to choose short solutions when possible, but still take longer paths when a problem is truly hard?
- Is there a better “format” for AI thinking than regular sentences?
- Can this approach make training and running AI models faster and cheaper?
How did they do it?
1) A new way to write thoughts: “Mentalese”
- Think of “Mentalese” as a neat, compact shorthand for reasoning. Instead of long sentences, the model writes steps like:
- SET: define variables;
- CALC: compute something;
- CASE: handle different cases;
- ANS: give the final answer.
- It’s like using math notes or code-like steps instead of full paragraphs. This cuts out fluff and keeps only what’s needed.
Why this helps:
- Fewer tokens: shorter thinking = faster AI.
- Clear structure: each step has a purpose.
- More human-like: people often think in quick, organized chunks, not essays.
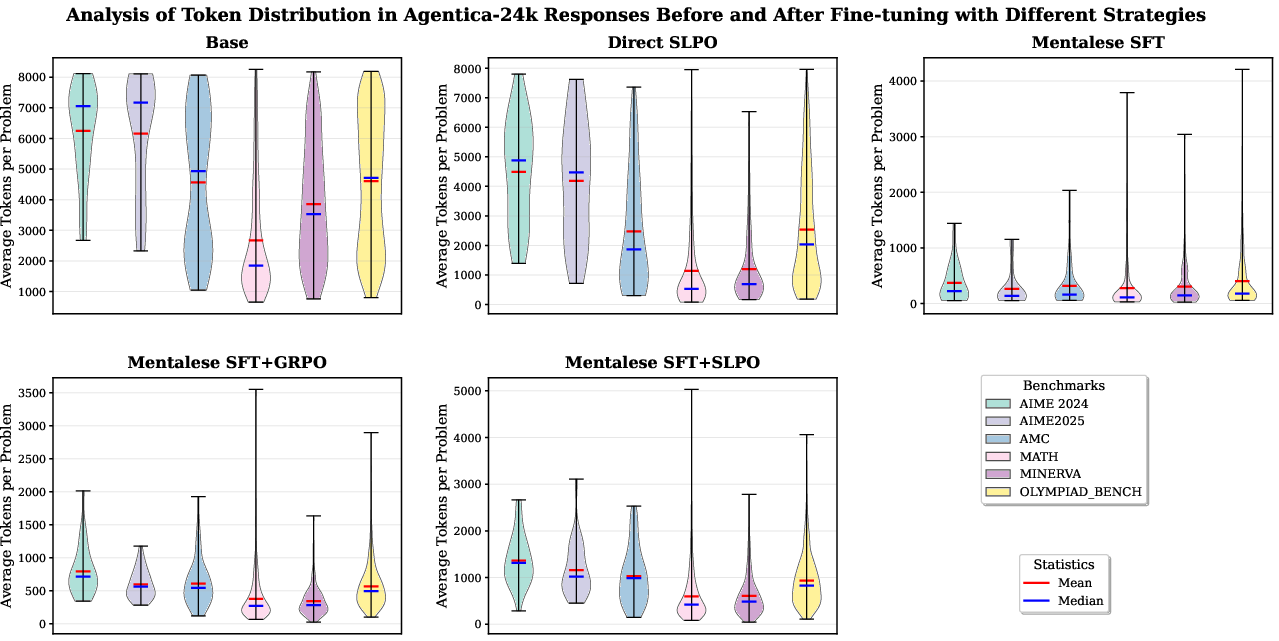
The authors also built a dataset called MentaleseR-40k with 40,000 math problems written in this short, symbolic style to teach the model.
2) Training in two stages
- Stage 1: Supervised Fine-Tuning (SFT)
- The model is taught to use Mentalese by copying examples (like practicing from a solution key).
- This makes the model concise, but at first it may get a bit less accurate.
- Stage 2: Reinforcement Learning with a Verifier (RLVR)
- Now the model “plays a game” where it tries to solve problems, gets checked by a verifier (right or wrong), and is rewarded.
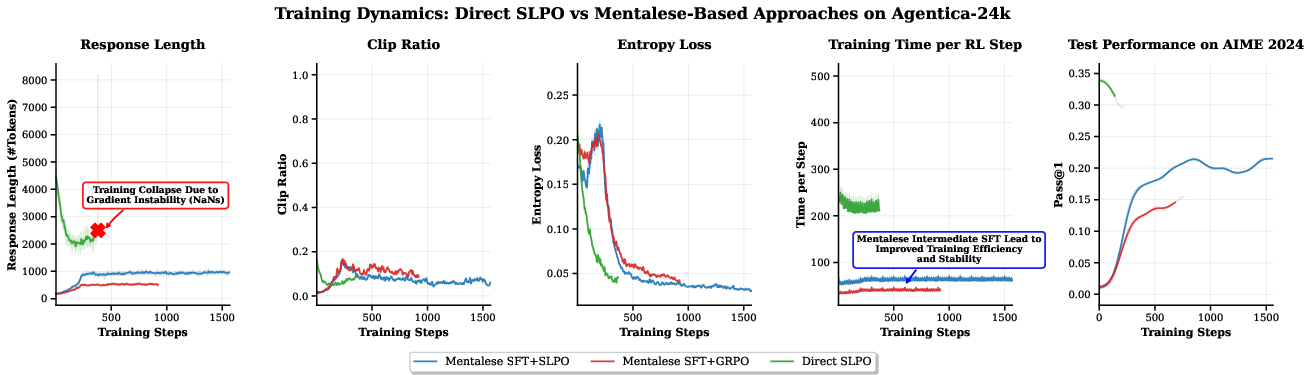
- This stage recovers accuracy while keeping the short style.
Think of it like learning a new way to take notes: first you learn the format, then you practice until you’re both fast and correct.
3) Rewarding short, correct thinking: SLPO
- SLPO stands for Shorter Length Preference Optimization.
- Simple idea: among the correct solutions, shorter ones get a bonus. But:
- If a problem truly needs a longer explanation, the model is NOT punished for it.
- If no correct solution appears, the model doesn’t get weird penalties for length.
- Analogy: you get full credit for a correct answer; if you show it clearly in fewer steps, you get a small extra credit—unless more steps were necessary.
This avoids two problems:
- Overthinking: writing too much for simple problems.
- Underthinking: skipping needed steps for hard ones.
4) Group-based learning (briefly)
- The model generates several answers to the same question and compares them.
- Better answers (more correct and shorter) get higher rewards.
- Think of it like ranking multiple drafts and learning from the best one.
What did they find?
Here are the key results across math benchmarks like AIME 2024/2025, Minerva-Math, OlympiadBench, MATH-500, and AMC:
- Much shorter thinking:
- 4–16× fewer tokens in the reasoning steps (sometimes over 10× shorter).
- Faster responses:
- Up to 5× lower inference latency (answers come faster).
- Cheaper training:
- 7–9× lower training cost compared to a strong baseline (DeepSeek R1 Distilled).
- Strong accuracy:
- Keeps about 90–98% of the original accuracy despite being way shorter.
- Beats big-name models at similar or shorter length:
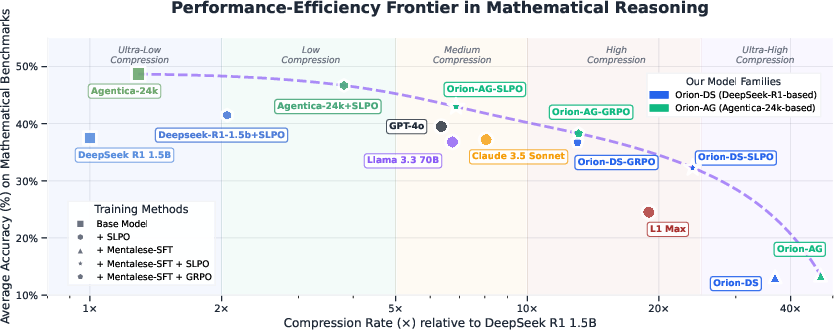
- ORION models surpassed GPT-4o and Claude 3.5 Sonnet by up to 5 percentage points in accuracy while still compressing the reasoning by about 2×.
- Works beyond math:
- On other tests (like GPQA, LSAT, MMLU), ORION stayed competitive and still used far fewer tokens.
Why this matters:
- Shorter, structured reasoning is faster, cheaper, and easier to use in real systems (like tutors, assistants, or planning tools).
- You don’t have to trade speed for smarts—ORION gets a strong balance. The paper calls this the “performance–efficiency Pareto frontier,” meaning ORION sits on the best-possible trade-off curve between accuracy and cost.
Why is this important?
- Real-time AI: Shorter thinking makes AI better for live use (less waiting, lower cost).
- Better for devices: More practical to run on limited hardware (e.g., phones or edge devices).
- Clearer reasoning: Structured steps are easier to understand and check.
- Scalable training: The Mentalese stage makes reinforcement learning more stable and much cheaper.
Takeaway
ORION teaches AI to “think” in a compact, symbolic language (Mentalese) and rewards it for giving correct answers with as few steps as needed (SLPO). This leads to:
- 4–16× shorter reasoning,
- similar or better accuracy,
- faster and cheaper operation.
In simple terms: the model learns to show its work like a smart student using clean, efficient notes—quick when it can be, detailed when it must be. This could make future AI systems more useful, affordable, and trustworthy in everyday tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it.
- Mentalese semantics are underspecified: no executable interpreter, formal type system, or proof of well-typedness/termination; develop a public spec and executor to verify step-by-step correctness and faithfulness.
- Expressivity of the operator set (e.g., SET, EQ, CASE, SOLVE, CALC, DIFF, ANS) is unproven; characterize coverage across math subdomains (algebra, geometry, proofs, combinatorics) and extend primitives as needed.
- Faithfulness claim (“each step is necessary and sufficient”) is not empirically validated; design step-level audits and minimality/necessity tests to quantify redundancy and correctness in traces.
- Dataset quality and contamination risk: MentaleseR-40k was auto-generated with GPT-4.1 and “lightly curated”; perform rigorous validation (human review, step execution checks), error-rate estimation, and train–test deduplication/contamination analyses (especially for AIME/AMC overlaps).
- Reproducibility gap: code and dataset are “to be released”; publish full pipeline (prompts, filters, executors, training scripts) with seeds and logs to enable independent replication.
- Verification fidelity: RL rewards depend on final boxed answer equality; add process-level validators (symbolic executors, proof checkers, unit checks) to discourage spurious short-but-wrong reasoning.
- SLPO reward formulation is ambiguous in text (typos/misaligned brackets) and fixed to α=0.1; clarify the exact formula, provide sensitivity analyses over α, group size, KL penalty, and length caps.
- Theoretical properties of SLPO are not analyzed; study convergence, stability, and bias introduced by brevity preferences relative to GRPO/PPO.
- Reward hacking risk: models might emit ANS prematurely or compress by skipping essential steps; implement anti-cheating constraints (e.g., require executable intermediate steps, penalize invalid traces).
- Collapse under direct SLPO is observed but not diagnosed; perform ablations (entropy regularization, KL scheduling, gradient clipping, value baselines, temperature/top-p) to isolate causes and remedies.
- Length budget effects are ad hoc (1k for GRPO, 2k for SLPO, 8k at eval); formalize length-annealing schedules and evaluate train–test budget mismatch impacts on behavior and accuracy.
- Scaling laws are unknown: results are only at 1.5B; test generality across model sizes (≤1B, 7B, 70B) and architectures, mapping accuracy–compression Pareto curves as scale increases.
- Cross-domain generalization is limited (GPQA, LSAT, MMLU only); evaluate on code generation, theorem proving, planning, common-sense reasoning, and multimodal tasks to test applicability beyond math.
- Human-likeness claims (Language of Thought alignment) lack empirical grounding; run cognitive/behavioral studies and expert ratings to assess interpretability, conciseness, and human resemblance.
- Comparative baselines are incomplete; include and fairly reproduce recent length-aware RL methods (e.g., DAST, ShorterBetter, O1-Pruner) under identical settings.
- Latent reasoning alternatives (implicit computation in hidden states) are not compared; benchmark Mentalese+SLPO against latent reasoning approaches on efficiency–accuracy–faithfulness trade-offs.
- Tool-use integration is unexplored; assess whether Mentalese can orchestrate calculators/CAS/solvers and whether SLPO still achieves compression with external tools.
- Tokenization confounds may inflate compression (operators may be token-dense); report tokenizer effects and normalize compression across tokenizers.
- Inference latency claims (up to 5×) and training cost reductions (7–10×) are hardware-dependent; publish standardized wall-clock measurements, energy usage, memory footprint, and throughput across setups.
- Statistical rigor is limited: no significance tests, variance across runs, or confidence intervals; report multiple seeds, bootstrap CIs, and effect sizes for Pass@1 and length metrics.
- Error analyses are missing; provide qualitative/quantitative breakdowns of failure modes (premature answers, algebraic slips, geometry missteps, invalid traces) to guide operator/design improvements.
- Mentalese restricts branching/self-verification observed in R1; explore adding symbolic branching/check operators to recover exploration while retaining compactness.
- OOD gains are small (≈1 pp on average); investigate which tasks benefit/hurt and whether different operator sets or reward schedules improve transfer.
- Safety/ethics implications are not addressed; evaluate whether compressed reasoning reduces transparency or increases deceptive concise outputs, and design safeguards.
- Robustness to adversarial prompts or noisy inputs is untested; stress test Mentalese+SLPO under adversarial/perturbed problems and ambiguity in formatting (e.g., boxed answer variations).
- Training resource demands (32×H100) limit accessibility; explore distillation, curriculum learning, or low-resource variants to democratize adoption.
- Evaluation uses Pass@1 only; assess Pass@k with sampling/tree-search, calibration, and confidence estimation under compressed reasoning regimes.
- Impact on downstream conversational quality is unclear; study how Mentalese traces interact with user-facing text (readability, acceptability, controllability) and when to expose or hide traces.
- Operator extensibility and compositional generalization are untested; measure performance on tasks requiring novel operator compositions and incremental operator learning.
- Integration into agentic systems is hypothesized but not demonstrated; run end-to-end agent benchmarks (planning, tool-calling, multi-agent coordination) to quantify real-world benefits of compression.
Practical Applications
Immediate Applications
Below is a focused list of deployable applications that leverage the paper’s findings (Mentalese, SLPO, and the two-stage RLVR pipeline) to reduce latency, cost, and verbosity while maintaining high accuracy.
- Healthcare — real-time triage and intake chatbots on constrained infrastructure
- Use case: Faster, lighter triage, intake, and symptom-checking in telehealth portals and hospital kiosks, especially in low-bandwidth settings.
- Tools/workflows: ORION-style models with Mentalese alignment; RLVR with verifier-based correctness checks; length caps and SLPO to dynamically adjust reasoning steps; vLLM for efficient serving.
- Assumptions/dependencies: High-quality medical verifiers and guardrails; compliance (HIPAA, GDPR); domain-specific Mentalese operators for clinical tasks; careful evaluation given OOD performance gains are modest in the paper.
- Education — math tutoring with concise, interpretable steps
- Use case: Step-by-step tutoring that shows structured reasoning traces for math problems, enabling quicker hints and feedback at scale.
- Tools/workflows: MentaleseR-40k (as a starting point), Mentalese-to-natural-language renderer for student-facing explanations, SLPO to keep reasoning efficient while correct; teacher dashboards that visualize and audit symbolic steps.
- Assumptions/dependencies: Mapping from symbolic Mentalese to accessible explanations; curriculum alignment; domain verifiers (math solvers/unit tests).
- Software/Developer tools — low-latency code assistants and unit-test checkers
- Use case: On-dev environments where assistants must reason (e.g., explain bugs, propose fixes) with minimal tokens and fast turnaround.
- Tools/workflows: Two-stage pipeline (SFT to domain Mentalese + RLVR via SLPO), correctness verifiers using unit tests/static analysis; Pareto frontier selection to tune accuracy vs. compression.
- Assumptions/dependencies: Robust code verifiers; domain-specific Mentalese operators for programming tasks; handling non-math reasoning where gains may vary.
- Finance — portfolio analytics and risk dashboards with cost-aware reasoning
- Use case: Real-time portfolio diagnostics or scenario analysis that must remain responsive and computationally frugal.
- Tools/workflows: SLPO with simulation-based correctness verifiers; enforce generation length caps; deploy via vLLM; tune α for brevity vs. correctness.
- Assumptions/dependencies: Reliable simulators for verifying answers; compliance (model auditability, record-keeping); acceptance of structured traces in workflows.
- Agent platforms — bandwidth-efficient multi-agent orchestration
- Use case: Tool-using agents and planning systems that exchange short, structured messages to avoid “overthinking” and message bloat.
- Tools/workflows: Adopt Mentalese as an inter-agent message format; SLPO to keep messages concise when multiple valid plans exist; group-relative scoring (GRPO/SLPO) for coordination.
- Assumptions/dependencies: Human-readable rendering when needed; domain verifiers for agent actions; integration with existing orchestration frameworks.
- Edge/on-device assistants — mobile and embedded deployments
- Use case: Personal assistants running on phones, kiosks, or IoT devices where energy and latency are critical.
- Tools/workflows: 1.5B-scale ORION-like models; strict token budgets; SLPO-based preference for shorter correct traces; caching/verifier-lite strategies.
- Assumptions/dependencies: Memory constraints and quantization; acceptable accuracy on non-math tasks; local or lightweight verifiers.
- LLM training/inference pipelines — cost and time reductions in RL post-training
- Use case: Teams running RLHF/RLAIF can cut training time by 7–10× and stabilize updates by first aligning to Mentalese before RL.
- Tools/workflows: LLaMA-Factory for SFT; Verl for RL; vLLM inference; GRPO/SLPO reward shaping; strictly enforced max generation length (1–2k tokens during RL) to prevent drift/collapse.
- Assumptions/dependencies: Availability of domain Mentalese data; verifier coverage; GPU resources (though less than baseline RLVR).
- Audit/compliance — structured, checkable reasoning logs
- Use case: Producing compact, structured traces that are easier to audit for correctness and decision provenance than free-form CoT.
- Tools/workflows: Mentalese trace viewer, automated checkers that validate ANS against verifiers; storage of structured logs for audit.
- Assumptions/dependencies: Auditors trained to interpret symbolic traces; domain-specific operators and verifiers; privacy-preserving logging.
- Energy/IT operations — compute and carbon footprint reduction
- Use case: Reduce inference latency and token count to lower energy consumption and cost in data centers.
- Tools/workflows: Compression knob (α, generation caps) to select operating points along the performance–efficiency Pareto frontier; workload profiling before/after ORION-style adoption.
- Assumptions/dependencies: Acceptable accuracy trade-offs; monitoring frameworks to quantify energy impacts.
- Customer support/knowledge bases — concise reasoning for retrieval and triage
- Use case: Faster answers with compact reasoning chains during triage, escalation, or policy lookup.
- Tools/workflows: Mentalese-aligned models wrapped around retrieval; SLPO to favor shorter correct paths; correctness checks via policy verifiers/FAQ matchers.
- Assumptions/dependencies: Strong retrieval/verifier setup; clear mapping from symbolic steps to customer-friendly language when needed.
Long-Term Applications
The following applications require additional research, scaling, domain adaptation, or standardization before broad deployment.
- Cross-domain Mentalese standards and tooling
- Opportunity: Define operator sets and syntax for medicine, law, robotics, and software engineering to generalize beyond math.
- Tools/products: Domain-specific DSL specifications, compilers/interpreters, validators; shared benchmarks and datasets.
- Assumptions/dependencies: Community consensus on operator semantics; robust verifiers per domain; open-source ecosystem support.
- Regulation and policy — structured reasoning as an audit requirement
- Opportunity: High-stakes AI systems mandated to emit verifiable, compact, and standardized reasoning traces for accountability and safety.
- Tools/products: Certification frameworks; logging standards; conformance tests; third-party audit services.
- Assumptions/dependencies: Legislative adoption; privacy and security guarantees; alignment with sector-specific regulations.
- Robotics and autonomous systems — planning via symbolic Mentalese
- Opportunity: Map Mentalese operators to planning primitives (e.g., ROS actions), enabling low-latency, verifiable action plans.
- Tools/products: Mentalese-to-ROS bridge; closed-loop verifiers; safety kernels; SLPO-tuned planners for concise correct plans.
- Assumptions/dependencies: Safety validation; real-world robustness; integration with perception and control stacks.
- Multi-agent ecosystems — Mentalese as a lingua franca
- Opportunity: Standardized, compressed inter-agent protocol for negotiation, planning, and tool use under bandwidth constraints.
- Tools/products: Protocol specs; coordination libraries; SLPO-based message shortening; shared verification services.
- Assumptions/dependencies: Interoperability standards; failure-mode analysis; secure channels and identities.
- Latent compressed reasoning (minimal external tokens)
- Opportunity: Internalize Mentalese-like reasoning in hidden states while emitting only final answers or minimal summaries.
- Tools/products: Distillation methods from explicit to latent reasoning; verifier-aware training; trust calibration tools.
- Assumptions/dependencies: Advances in verification without full external traces; interpretability techniques; guardrails against reward hacking.
- Hardware/software co-design for symbolic tokens
- Opportunity: Accelerate decoding and verification for structured reasoning formats via specialized kernels and scheduling.
- Tools/products: Token-type-aware decoding; operator-level caching; verifier accelerators.
- Assumptions/dependencies: Vendor support; stable Mentalese standards; measurable ROI over general-purpose acceleration.
- Clinical decision support with verified Mentalese
- Opportunity: Deploy compact, auditable reasoning in diagnostic aids and guideline-based recommendations.
- Tools/products: Clinical operator libraries; guideline verifiers (e.g., care pathways); hybrid neuro-symbolic controllers.
- Assumptions/dependencies: Clinical trials; bias/fairness evaluation; regulatory approval; liability frameworks.
- Education platforms — automated grading and formative feedback via symbolic steps
- Opportunity: Auto-grade proofs and derivations; generate targeted, concise hints; detect reasoning gaps from symbolic traces.
- Tools/products: Step checkers; teacher dashboards; student-facing Mentalese renderers and translators; curriculum-integrated DSLs.
- Assumptions/dependencies: Acceptance by educators; alignment with standards; accessibility and localization.
- Finance — verified strategy generation and compliance-friendly audit trails
- Opportunity: Generate trading or risk strategies with compact, verifiable reasoning and compliance-ready logs.
- Tools/products: Strategy verifiers; audit vaults; policy engines; SLPO controls to manage reasoning budget under market latency constraints.
- Assumptions/dependencies: Market simulators; compliance alignment; robust failure handling.
- Sustainability frameworks — standardized measurement of “thinking” efficiency
- Opportunity: Sector-level reporting on token efficiency, latency, and energy footprint for AI reasoning systems.
- Tools/products: Metrics and dashboards (compression rate, latency, energy per query); Pareto frontier selectors; certification marks for efficient reasoning.
- Assumptions/dependencies: Agreed metrics and disclosure practices; third-party validation; alignment with ESG reporting.
Notes on Assumptions and Dependencies (cross-cutting)
- Verifier availability is central: SLPO and RLVR hinge on reliable, domain-specific correctness checks (math solvers, unit tests, simulators, guideline verifiers).
- Mentalese generalization requires domain operator design: math results won’t directly transfer to medicine, law, or robotics without new operator sets and datasets.
- Training stability depends on generation caps and pipeline design: enforce 1–2k token caps during RL to avoid reversion to verbosity or collapse; tune α for brevity vs. correctness.
- Accuracy vs. compression is a product choice: use the Pareto frontier to pick operating points that meet service-level objectives; communicate trade-offs to stakeholders.
- Safety and compliance need structured governance: high-stakes domains require audits, privacy-preserving logging, and bias/fairness evaluation before deployment.
- Open-source code/dataset availability: adoption depends on the release and maintenance of the ORION codebase, MentaleseR-40k, and example verifiers.
Glossary
- Advantage (RL): The excess expected return of an action over a baseline, used to guide policy updates in reinforcement learning. "it operates at the single-sample level: each rollout is evaluated independently using a value function to estimate its advantage."
- Agentic LLM systems: Language-model-based autonomous agents that plan, act, and interact in environments, where latency and cost often hinder deployment. "especially relevant for agentic LLM systems"
- Back-patching: A technique that modifies internal activations to steer or edit a model’s reasoning without changing its weights. "back-patching~\citep{biran2024hopping}"
- Chain-of-Thought (CoT): A prompting and training paradigm that elicits explicit, step-by-step reasoning from LLMs. "chain-of-thought (CoT) prompting"
- Clip Ratio: A PPO-style training diagnostic indicating the fraction of updates that are clipped, often used to assess training stability. "Clip Ratio indicates more controlled updates in Mentalese methods, driven by reduced response truncation.;"
- Compression Rate (CR): A metric quantifying how much shorter a model’s outputs are relative to a reference model. "Compression Rate (CR) quantifies the degree of response shortening relative to DeepSeek-R1-1.5B, with higher values indicating greater compression (e.g., a CR of 10 means the model’s responses are ten times shorter on average)."
- DAST: Difficulty-Adaptive Slow Thinking; a method that adapts reasoning token budgets based on problem difficulty. "DAST~\citep{shen2025dastdifficultyadaptiveslowthinkinglarge} adapts budgets based on problem difficulty,"
- Filler tokens: Special tokens inserted to shape computation or timing without adding semantic content. "filler tokens~\citep{pfau2024fillers}"
- Forking tokens: Tokens like “wait”, “but”, or “so” that introduce branches or self-corrections in a model’s reasoning. "âforking tokensâ such as wait, but, or so,"
- Group Relative Policy Optimization (GRPO): A PPO-style RL algorithm that computes advantages relative to a group of rollouts for the same prompt. "Group Relative Policy Optimization (GRPO), a group-based extension of PPO for reasoning optimization."
- KL penalty: A regularization term that penalizes divergence from a reference policy to stabilize RL training. "a clipped surrogate objective similar to PPO but with a directly imposed KL penalty:"
- Knowledge distillation: Transferring capabilities from one model (often larger or differently trained) to another; here into implicit (“latent”) reasoning. "knowledge distillation into latent reasoning"
- Language of Thought Hypothesis (LOTH): A cognitive theory positing that human reasoning operates over a structured, symbolic internal language. "Language of Thought Hypothesis (LOTH)"
- Latent reasoning: Intermediate computation performed implicitly in hidden representations rather than exposed as text tokens. "latent reasoning, where intermediate computation is implicit in hidden representations rather than externalized tokens"
- LCPO: Length-Controlled Policy Optimization; methods that constrain reasoning length via fixed or maximum token budgets. "LCPO constrain reasoning lengths by enforcing unnatural fixed or maximum token budgets."
- L1 (length-control method): A post-training approach that enforces user-specified length budgets via an L1-style penalty. "L1~\citep{aggarwal2025l} enforces user-specified budgets,"
- Mentalese: A compact, symbolic reasoning format that encodes steps as canonical operations and expressions for ultra-compressed reasoning. "Mentalese encodes abstract reasoning as ultra-compressed, structured tokens,"
- MentaleseR-40k: A curated dataset of ultra-compressed symbolic reasoning traces for math problems, used for alignment and RL. "We release MentaleseR-40k, a dataset of ultra-compressed reasoning traces for 40k math problems,"
- Pareto frontier: The curve of optimal trade-offs between two objectives—here, accuracy and compression—where no improvement in one is possible without hurting the other. "The dotted curve indicates the Pareto frontier, which illustrates the trade-off between higher compression rates and loss in accuracy."
- Pass@1: The fraction of problems correctly solved on the first attempt under single-sample decoding. "Pass@1 measures the fraction of problems correctly solved under single-sample decoding,"
- Proximal Policy Optimization (PPO): A popular RL algorithm using clipped objectives to stabilize policy updates. "While PPO \citep{schulman2017proximalpolicyoptimizationalgorithms} provides a strong baseline for policy optimization,"
- Reward hacking: Exploiting imperfections in the reward function to achieve high reward without performing true desired reasoning or behavior. "reward hacking under fixed budgets"
- RLHF: Reinforcement Learning from Human Feedback; training that optimizes models using human or proxy preferences as reward. "Intermediate SFT followed by RLHF methods (SLPO/GRPO)"
- RLVR: Reinforcement Learning with Verifier Rewards; a two-stage pipeline that aligns to Mentalese then optimizes with correctness-verifying rewards. "we propose RLVR, a two-stage pipeline that first aligns models to Mentalese via supervised finetuning, then applies GRPO or SLPO with verifier feedback."
- Rollout: A sampled sequence of tokens (a candidate response) generated by a policy during RL training. "rollout generation leaving GPUs idle for long periods"
- Shorter Length Preference Optimization (SLPO): An RL objective that prefers shorter correct traces when multiple valid derivations exist, without penalizing necessary longer ones. "we propose Shorter Length Preference Optimization (SLPO), a reinforcement learning method that directly optimizes models to generate concise yet correct reasoning"
- Supervised finetuning (SFT): Post-training via labeled examples that aligns output format or behavior—here to the Mentalese style. "SFT alignment anchors the model to a compact single-chain reasoning format"
- Surrogate objective: The clipped optimization objective used in PPO/GRPO that approximates true policy improvement while controlling update size. "optimizes a clipped surrogate objective similar to PPO"
- Token-level importance ratio: The per-token likelihood ratio between current and old policies, used to compute PPO-style updates. "where $r_{i,t}(\theta) = \tfrac{\pi_\theta(o_{i,t}|q,o_{i,<t})}{\pi_{\mathrm{old}(o_{i,t}|q,o_{i,<t})}$ is the token-level importance ratio."
- Tree search and planning: Test-time methods that explore multiple reasoning branches and plan solutions to improve accuracy. "tree search and planning~\citep{yao2023treethoughtsdeliberateproblem, Besta_2024}"
- Thinking tokens: Special intermediate tokens used by reasoning models to “think” before answering, often verbose and costly. "long chains of verbose ``thinking'' tokens"
- vLLM: A high-throughput LLM inference engine enabling efficient large-scale generation. "the vLLM \citep{kwon2023efficientmemorymanagementlarge} engine"
- Value function: An estimator of expected return used to compute advantages in policy-gradient RL. "using a value function"
- Verifier: An automatic checker that determines correctness of a model’s answer and supplies a reward signal for RL. "a verifier checks the boxed answer"
Collections
Sign up for free to add this paper to one or more collections.

