- The paper introduces an iterative method where a single LLM acts as generator, refiner, and critic to enhance output quality without extra training.
- It leverages few-shot prompting and self-generated feedback, achieving around a 20% performance boost and a 13% gain in code-generation tasks.
- This approach offers practical benefits for applications like dialog generation and mathematical reasoning by providing focused and actionable refinements.
Self-Refine: Iterative Refinement with Self-Feedback
Self-Refine is an innovative approach developed to improve outputs generated by LLMs such as GPT-3.5 and GPT-4 through iterative self-feedback and refinement. Unlike traditional methodologies that require extensive supervised training data, Self-Refine employs a single LLM to act as the generator, refiner, and feedback provider, thereby sidestepping the need for additional training or reinforcement learning.
Methodology
Self-Refine follows a straightforward process:
- Initial Generation: An LLM produces an initial output for a given task.
- Feedback Generation: The same LLM provides feedback on its output, identifying areas for improvement.
- Iterative Refinement: The feedback is then used to refine the output. This cycle repeats until a predefined number of iterations is reached, or the LLM determines further refinement is unnecessary.
This iterative process leverages few-shot prompting techniques to guide the LLM in enhancing output quality across diverse tasks, ranging from dialog response generation to mathematical reasoning.
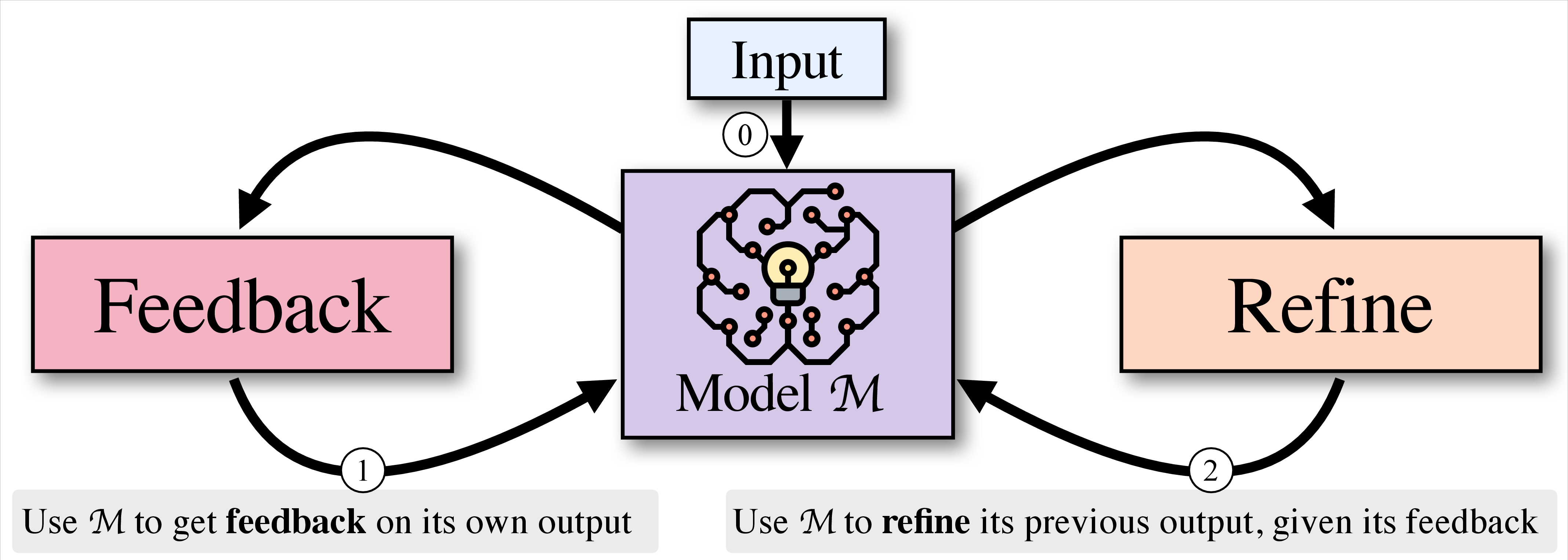
Figure 1: Given an input (.5pt{0
Evaluation and Results
Self-Refine was evaluated on seven diverse tasks, demonstrating significant improvements over direct generation methods:
- Outputs generated with Self-Refine were preferred by both human evaluators and automatic metrics over those generated using conventional methods.
- On average, task performance improved by approximately 20% absolute.
- For code-generation tasks, Self-Refine enhanced the initial generation by up to an absolute improvement of 13%.
These results indicate that even advanced models like GPT-4 can benefit from post-generation refinement using Self-Refine.
Analysis
The feedback generated by Self-Refine is designed to be actionable and specific, targeting exact phrases or logical points in the output that require modification. This approach ensures that the refinement process is not only iterative but also focused, minimizing unnecessary changes and enhancing overall output quality.
Self-Refine consistently improves model outputs across a range of applications. However, the impact is more pronounced in tasks with multifaceted objectives, such as dialog generation, where initial outputs often lack engagement or specificity. In scenarios where precise calculations or logical reasoning are required, such as mathematical tasks, the improvements can be modest if the feedback is unable to pinpoint errors accurately.
Implications and Future Developments
Self-Refine offers a paradigm shift in how LLMs can be utilized to maximize output quality post-generation. Its simplicity and effectiveness across various tasks highlight potential applications in real-world settings where rapid and adaptable content refinement is crucial. Future developments may focus on enhancing feedback granularity and exploring integration with external evaluative systems to further boost model performance.
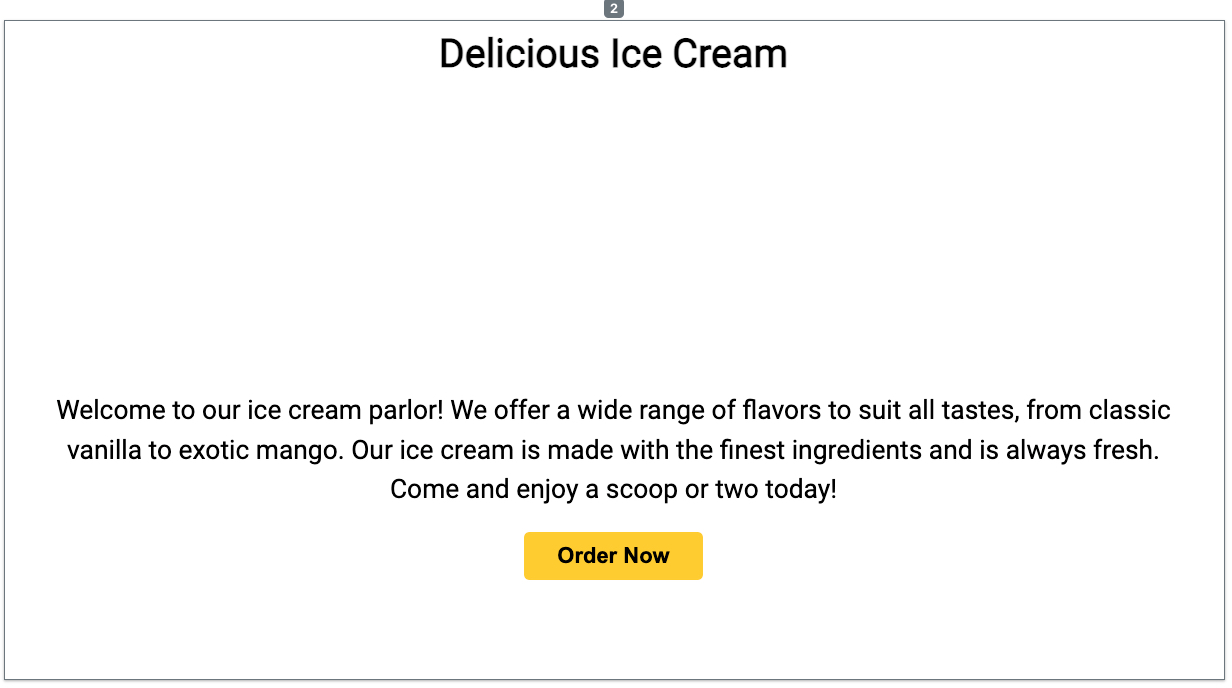
Figure 2: Initial web layout generated by our model for a fictional ice cream parlor.
Conclusion
Self-Refine proves to be an effective standalone approach for enhancing LLM output quality without further training or human intervention. Its ability to improve state-of-the-art models like GPT-4 at test time holds promise for broadening the capabilities of AI systems in creative and technical domains. As AI continues to evolve, methods like Self-Refine will be essential in pushing the boundaries of what LLMs can achieve autonomously.
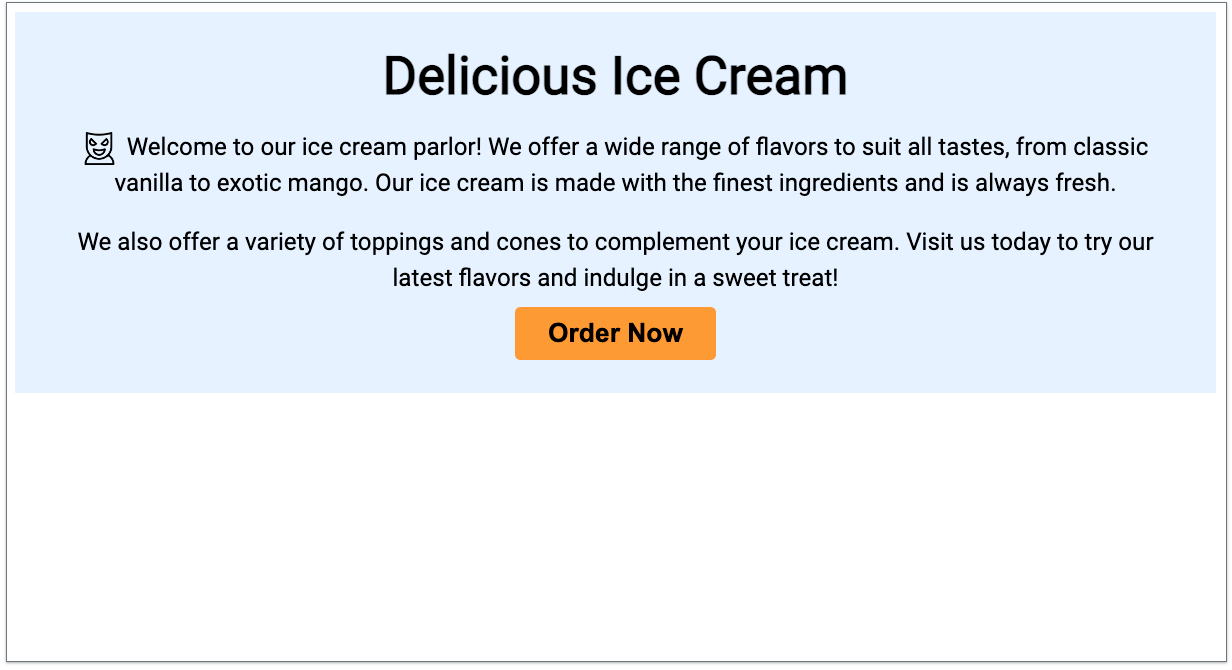
Figure 3: Refined web layout after applying model feedback. The feedback included changing the background color to light blue (#6f2ff), increasing the heading font size to 48px, adding an icon before the welcome text, enhancing the content with an additional paragraph, increasing the button text size to 24px, and updating the button color to #9933.