Through the telecom lens: Are all training samples important?
Published 26 Nov 2025 in cs.LG and cs.AI | (2511.21668v1)
Abstract: The rise of AI in telecommunications, from optimizing Radio Access Networks to managing user experience, has sharply increased data volumes and training demands. Telecom data is often noisy, high-dimensional, costly to store, process, and label. Despite Ai's critical role, standard workflows still assume all training samples contribute equally. On the other hand, next generation systems require AI models that are accurate, efficient, and sustainable.The paper questions the assumptions of equal importance by focusing on applying and analyzing the roles of individual samples in telecom training and assessing whether the proposed model optimizes computation and energy use. we perform sample-level gradient analysis across epochs to identify patterns of influence and redundancy in model learning. Based on this, we propose a sample importance framework thats electively prioritizes impactful data and reduces computation without compromising accuracy. Experiments on three real-world telecom datasets show that our method [reserves performance while reducing data needs and computational overhead while advancing the goals of sustainable AI in telecommunications.
The paper introduces a gradient norm-based method to quantify and rank sample importance for selective retraining in telecom applications.
It demonstrates that discarding 23–35% of data can maintain test accuracy while reducing training time by up to 28% and cutting emissions by roughly 31%.
The work highlights sustainable AI by optimizing telecom data efficiency through targeted sample selection and reduced redundancy.
Gradient-Based Sample Importance in Telecom Data: A Technical Perspective
Introduction
The exponential growth of AI-driven applications in telecommunications has introduced acute pressures regarding computational efficiency, data curation, and sustainability. Addressing whether all training samples contribute equally to model performance, the paper "Through the telecom lens: Are all training samples important?" (2511.21668) analyzes per-sample gradient dynamics and proposes a computation- and energy-efficient framework for selective training. The methodology rigorously quantifies sample influence and empirically evaluates the reduction of training data and environmental footprint across realistic telecom prediction tasks.
Methodology
Gradient Norm-Based Sample Scoring
The core of the approach is a gradient-centric quantification of sample importance during model training. For each sample s and training epoch e, the Euclidean norm of the gradient of the loss Le,s with respect to model parameters is computed:
ge,s=j=1∑P∂θj∂Le,s22
where P is the number of trainable parameters. The average gradient norm over all epochs yields an importance score for each sample:
I(s)=E1∑e=1Ege,s
Samples are then ranked by I(s), and selective retraining is performed with only the top p%.
This technique is model-agnostic, introduces minimal overhead, and circumvents limitations found in influence functions and forgetting metrics, especially for high-dimensional, temporally structured telecom data.
Experimental Setup
Three representative datasets are considered:
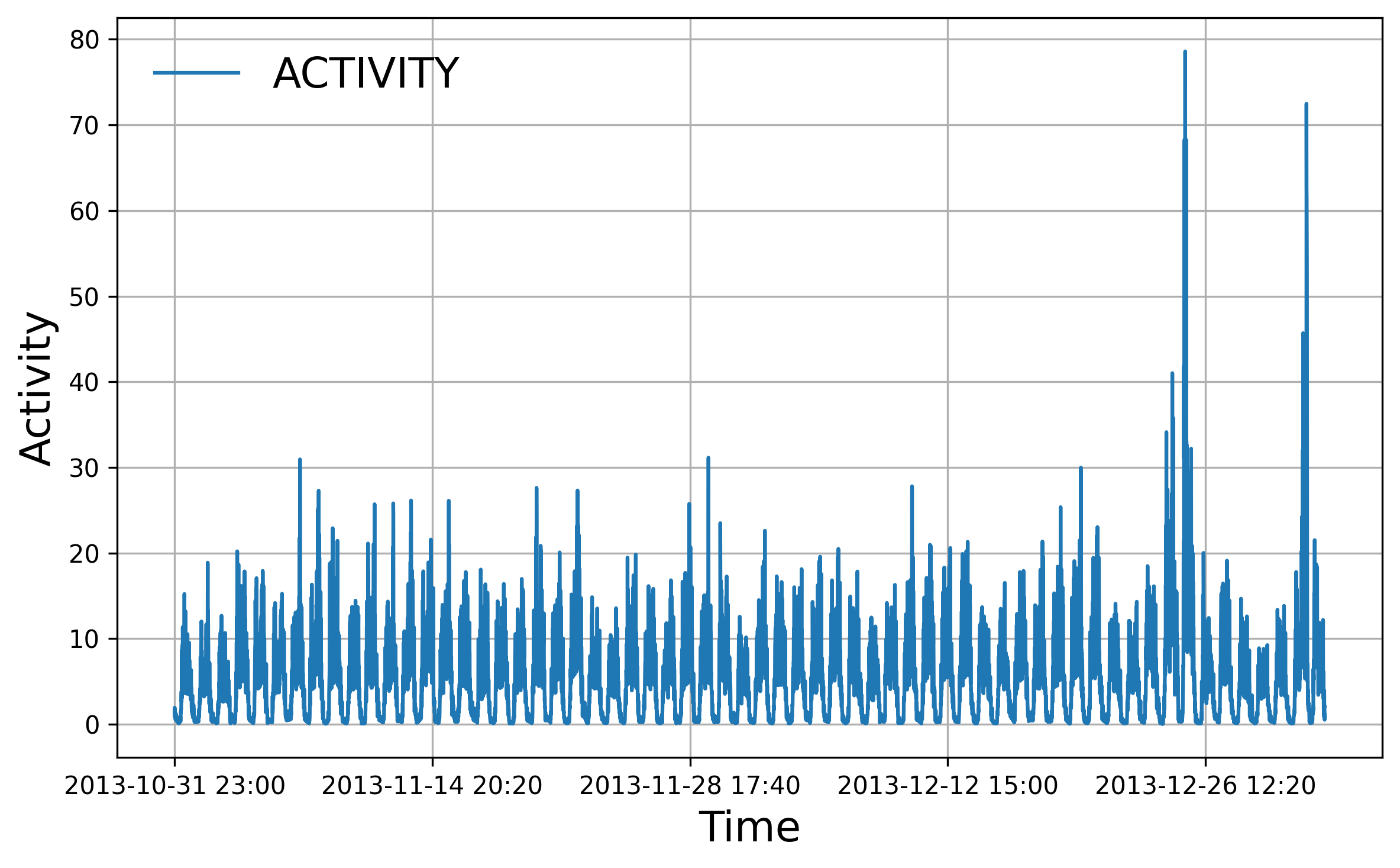
Telecom Italia Big Data Challenge: Univariate time series of internet activity, normalized and formatted for sliding-window forecasting.
Figure 1: Example univariate time series from the Telecom Italia dataset used in gradient-based sample importance analysis.
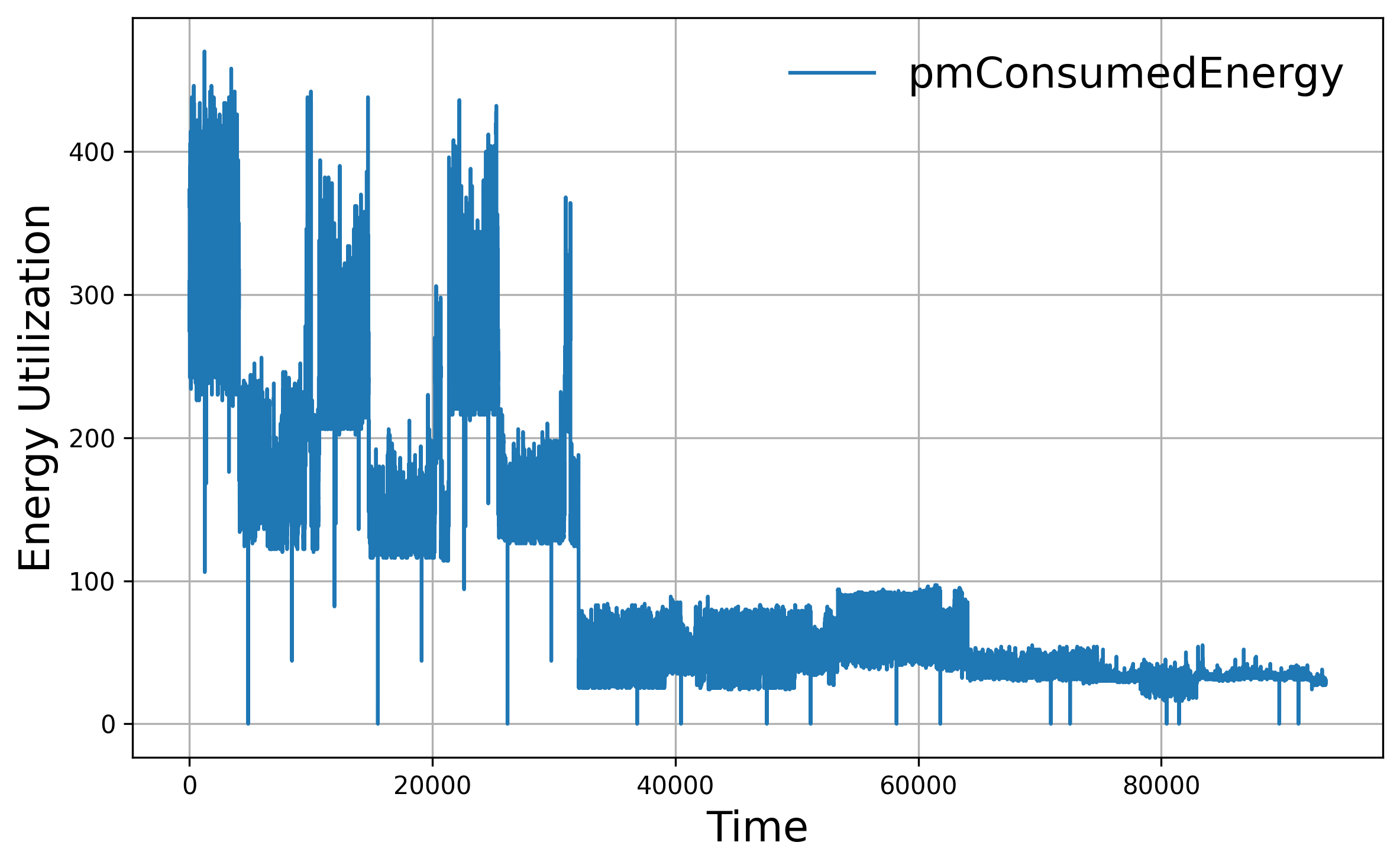
Proprietary Telecom Vendor Dataset: Multivariate time series from 249 base stations, including energy consumption and KPIs at 15-minute intervals.
Figure 2: Representative multivariate time series of energy consumption from a telecom vendor dataset.
5G Beam Selection Dataset: Synthetic mmWave MIMO dataset with ray-tracing and vehicular mobility, used for beam selection prediction.
For the forecasting and time-series regression tasks, LSTM architectures are benchmarked. The selective sample approach is compared to full-data baselines, focusing on Mean Absolute Error (MAE), RMSE, training time, and carbon emissions.
Empirical Results
Predictive Performance
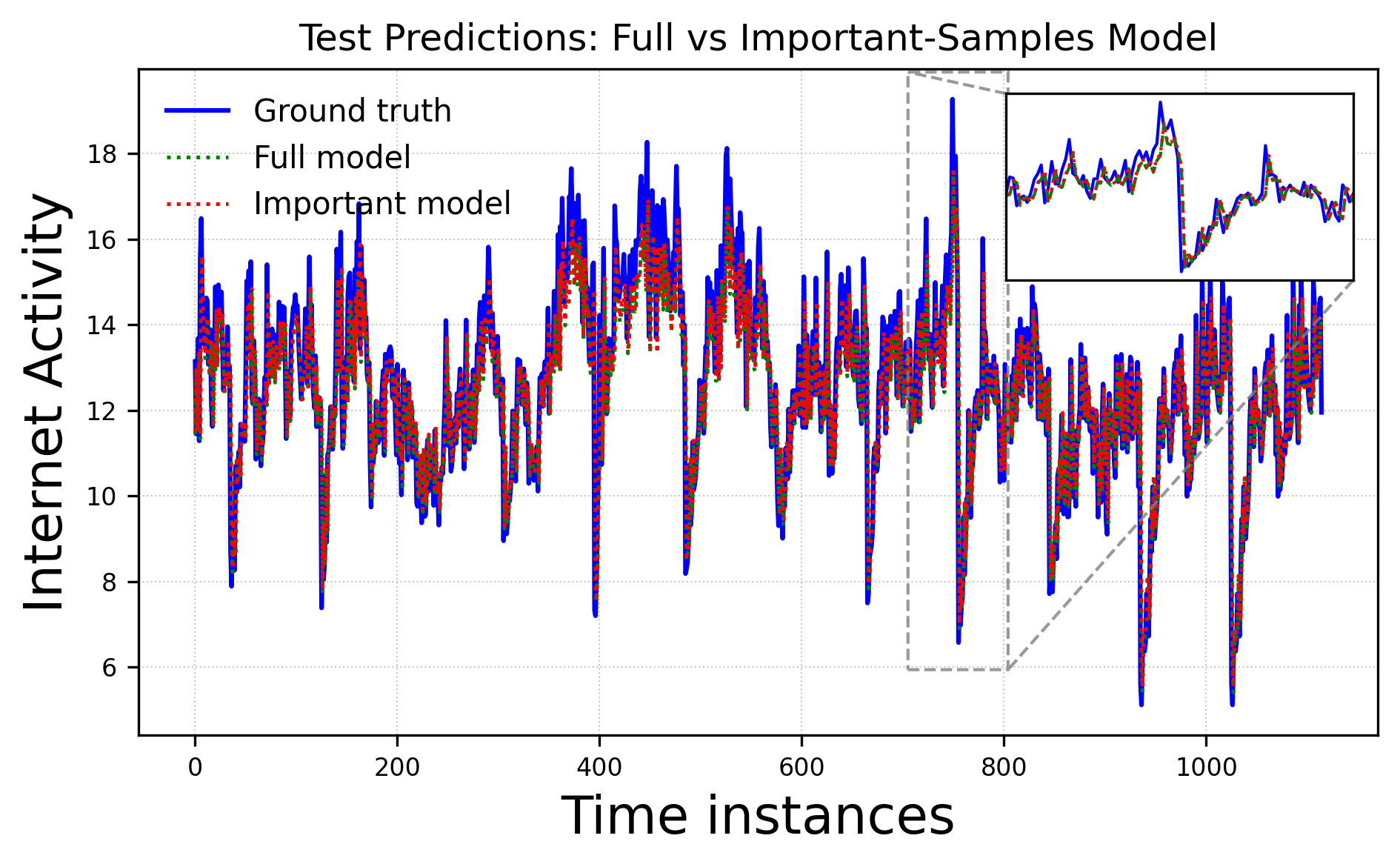
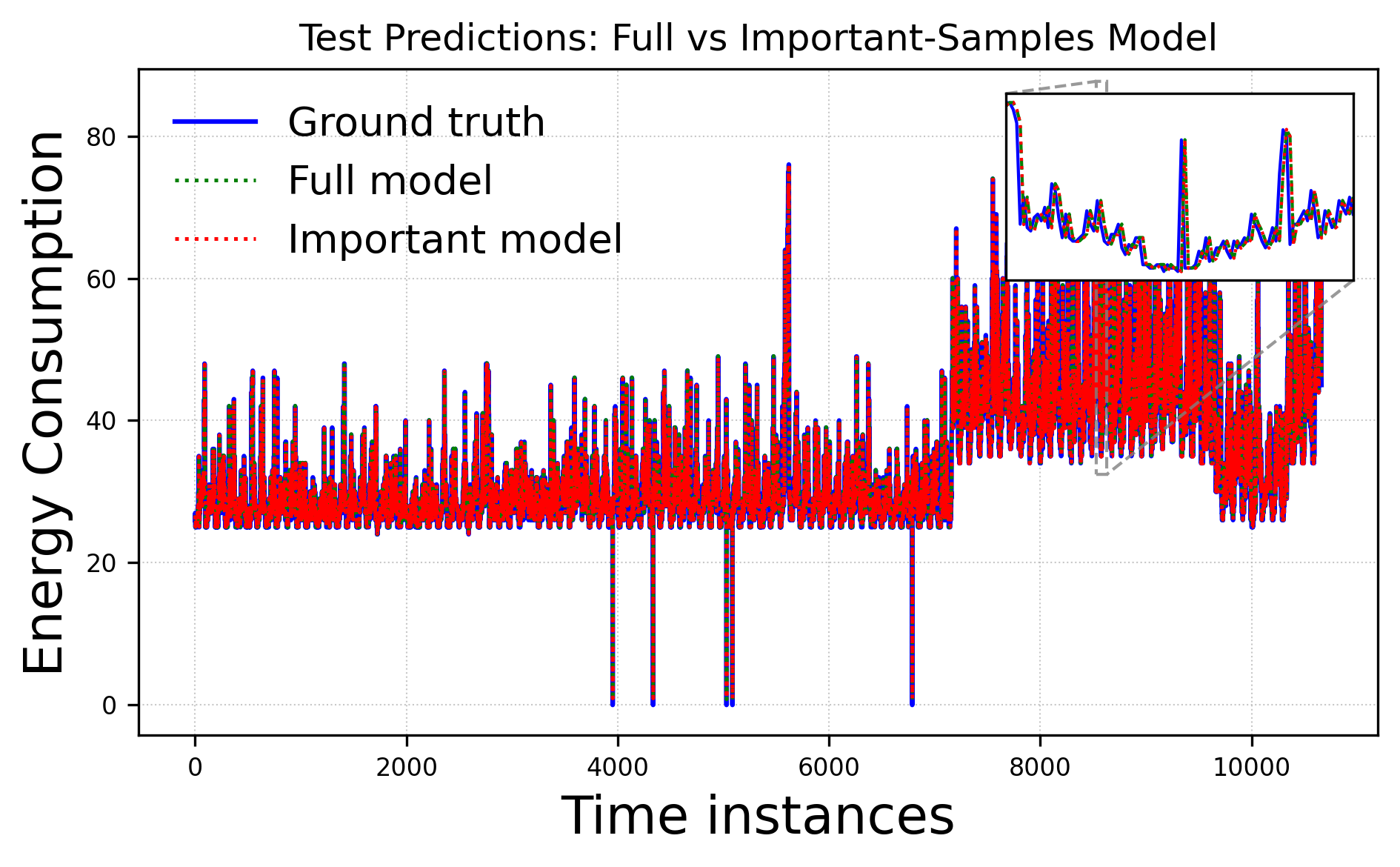
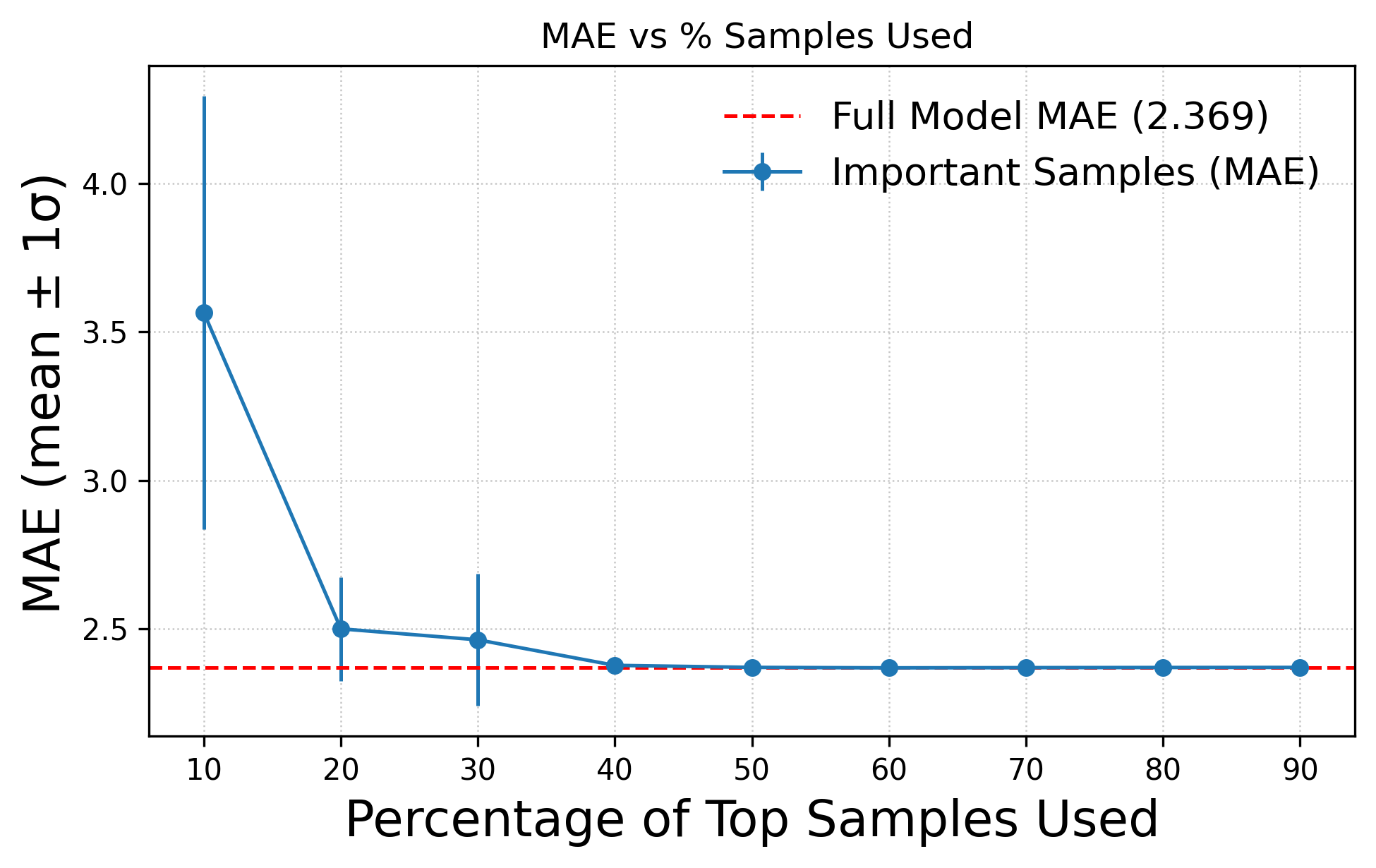
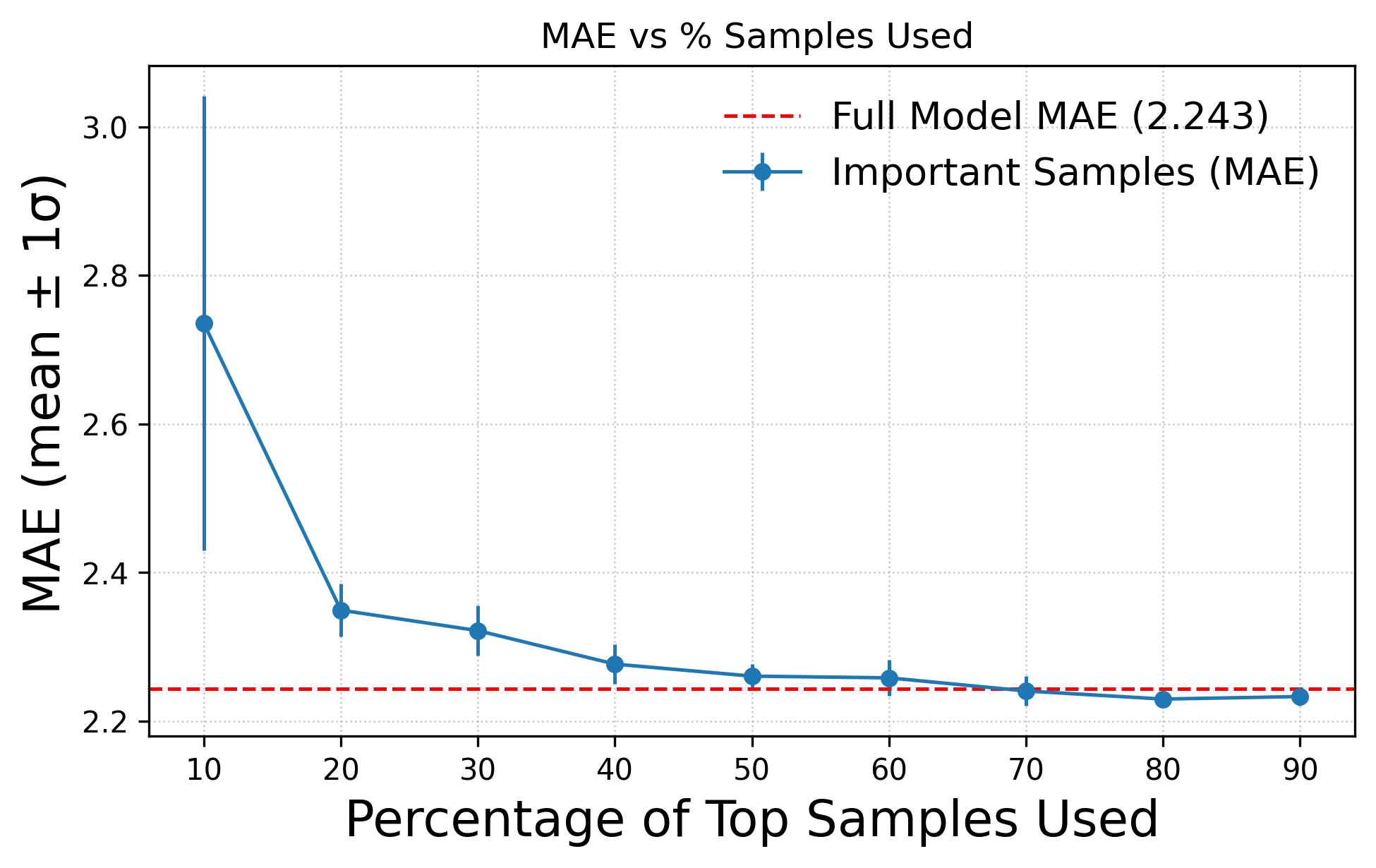
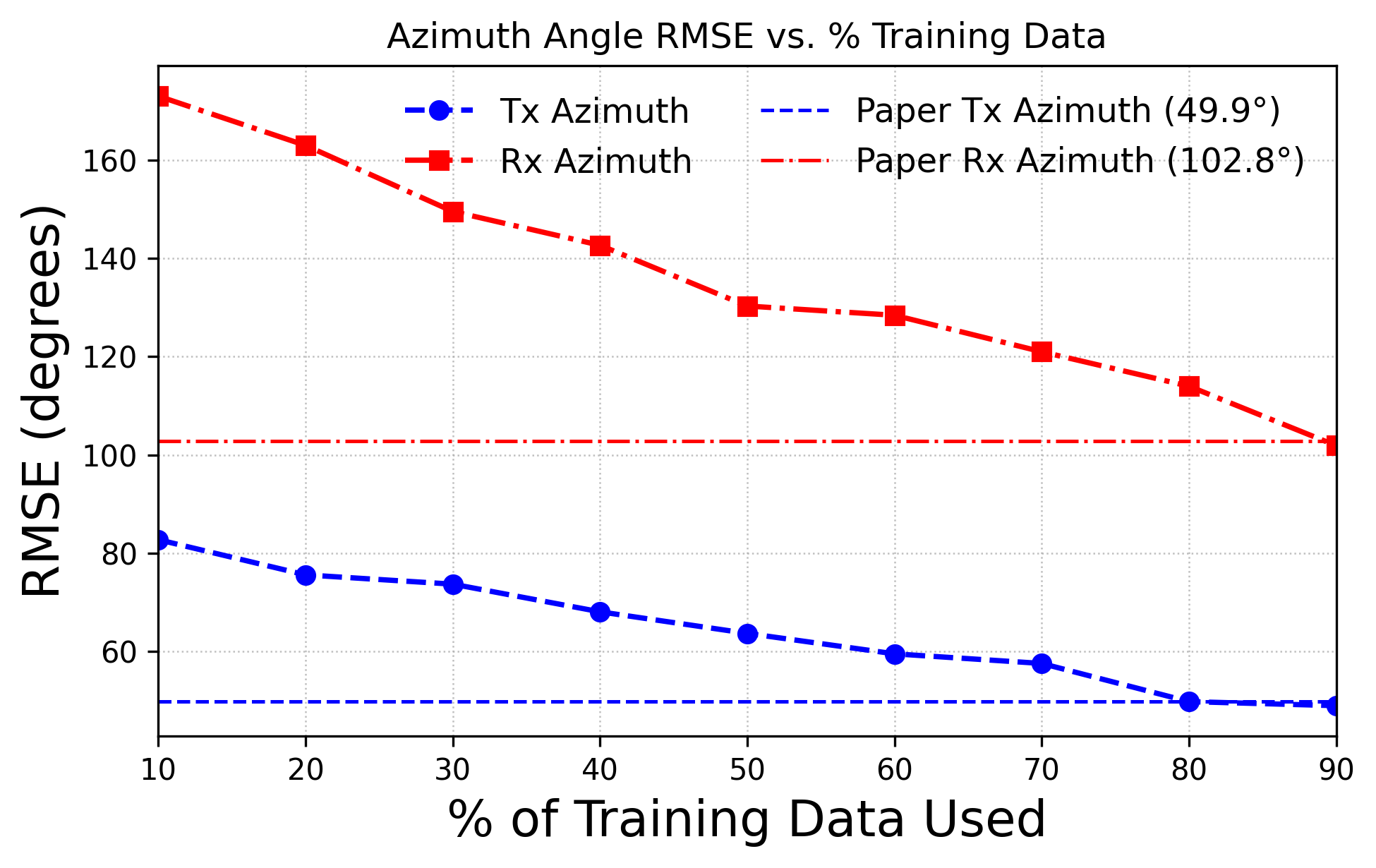
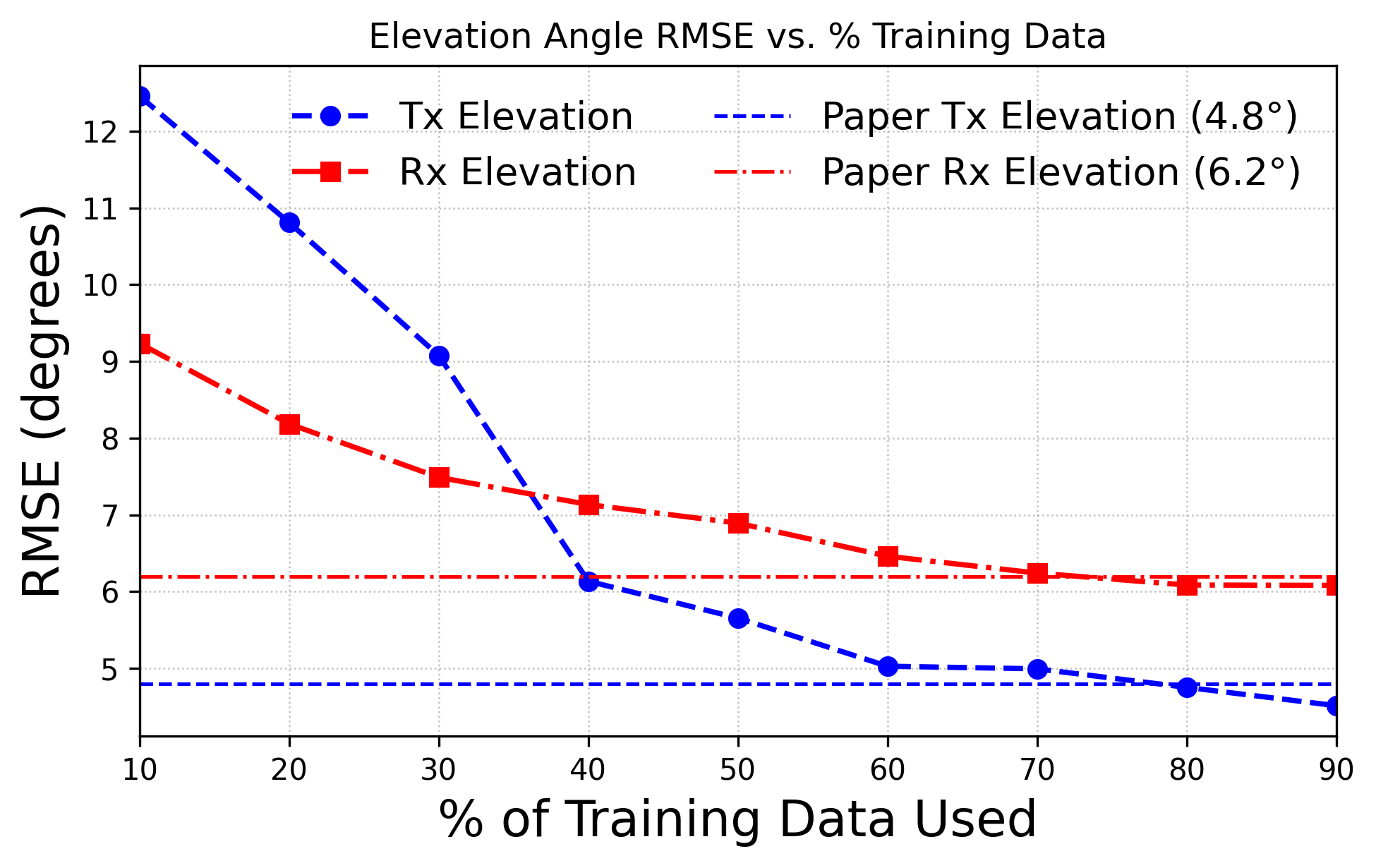
Results indicate that substantial portions of training data—between 23–35%—can be discarded without compromising test accuracy. On the Telecom Italia dataset, only 68% of the data suffices for matching full-set performance; this proportion is 74% on the vendor dataset. In 5G beam selection, 75% of the data yields lower error on elevation angle predictions versus the baseline, and 90% suffices for azimuth.
Figure 3: Test prediction trajectories comparing ground truth, full-sample LSTM baseline, and the proposed important-sample model for the Telecom Italia dataset.
MAE and RMSE statistics across reduced sample fractions consistently demonstrate that critical information is concentrated in a minority of samples, and that redundancy is pervasive in larger datasets.
Computational and Sustainability Impact
The approach yields pronounced reductions in both compute time and emissions. For instance, training on 68% of samples delivered a 28% reduction in time and a 38% reduction in carbon footprint on the Telecom Italia task. On larger datasets, efficiency gains are more pronounced, affirming that redundancy scales with data volume.
Empirical measurements using CodeCarbon substantiate average emissions reductions of approximately 31% across datasets, strengthening the case for gradient-driven selective training as a green AI intervention, especially in energy-intensive telecom contexts.
Theoretical and Practical Implications
The work exposes the fallacy of equal sample utility in real-world telecom domains, highlighting that traditional ML practices—such as uniform mini-batching and indiscriminate data utilization—are suboptimal for dynamic, high-variance, and nonstationary time series. The formulation is agnostic to architecture and loss, enabling adaptation to a wide scope of telecom tasks.
From a sustainability viewpoint, the findings directly inform operational ML pipeline optimization within telecom networks, where data labeling, transmission, storage, and model retraining are cost drivers. By filtering redundant samples during periodic retraining, pipeline latency, operational expenditures, and environmental impact can be jointly optimized.
On a theoretical level, the method opens an avenue for relating sample-level gradient norms to generalization, learning efficiency, and model robustness, going beyond empirical heuristics such as curriculum learning or active data pruning.
Limitations and Directions for Future Research
While the framework demonstrates consistent empirical utility, its conceptual foundation rather than algorithmic novelty limits theoretical generalization claims. Potential extensions include:
Linking gradient norm statistics to out-of-sample generalization and overfitting behavior,
Integrating dynamic and curriculum-driven sampling based on temporal or situational data shifts,
Systematic benchmarking against stronger core-set selection and influence-based approaches under identical resource constraints,
Extending validation to diverse neural architectures and online/continual learning settings,
Translating empirical trade-offs into operational criteria for telecom network management, including retraining frequency and cost/latency thresholds.
Conclusion
The proposed gradient-based sample importance methodology for telecom applications demonstrates that selective training on high-impact samples maintains or even improves performance while dramatically reducing computation and carbon emissions. These insights challenge the prevailing assumption of uniform sample utility and advocate for more resource-conscious, adaptive ML workflows in telecommunications. The results and methodology set the stage for more granular, theoretically grounded analyses of data efficiency and sustainability in large-scale AI training pipelines.