Evaluation of Multimodal Integration Capabilities in Large Models: Insights from MM-Vet
The paper, "MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities," presents a comprehensive benchmark framework designed to evaluate Large Multimodal Models (LMMs) with a focus on their ability to handle integrated multimodal tasks. These tasks encompass visual and textual inputs and necessitate a convergence of diverse vision-language capabilities. The work is performed in the context of ongoing advances in LMMs, which aim to enhance AI systems' cognitive abilities by combining visual processing with linguistic understanding.
Core Contributions
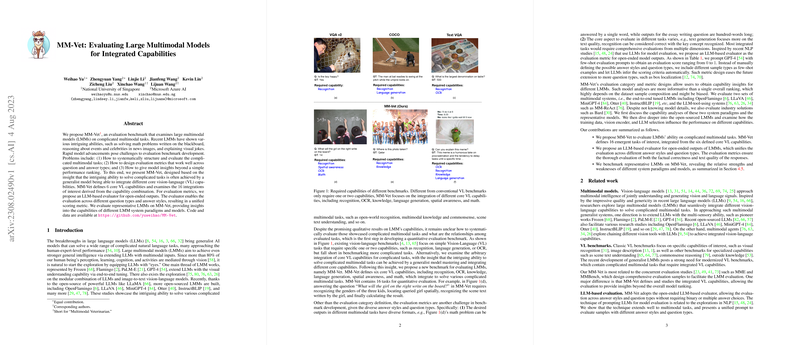
The authors introduce MM-Vet, a novel evaluation benchmark that emphasizes the integration of six core vision-language (VL) capabilities: recognition, optical character recognition (OCR), knowledge processing, language generation, spatial awareness, and mathematical computation. This benchmark assesses LMMs over 16 task integrations, which demand various combinations of these capabilities.
Significant challenges addressed in this work include the structuring and systematic evaluation of complex multimodal tasks, the development of evaluation metrics applicable across diverse question and answer types, and providing insights beyond mere performance rankings. A notable aspect of the methodology is the employment of a LLM-based evaluator, which facilitates a unified scoring metric across open-ended outputs, enhancing the consistency and applicability of the evaluation process.
Experimental Insights
The benchmark evaluates several representative LMMs, including OpenFlamingo, BLIP-2, LLaVA, MiniGPT-4, and MM-ReAct, among others, thus revealing diverse performance profiles across different capability integrations. The results indicate stark differences in performance based on the model architecture, underlying vision, and language components, as well as the volume and nature of the training data.
For instance, LLaVA models show prowess in recognition tasks, largely due to advanced vision encoders like the CLIP ViT-L/14 coupled with robust LLMs such as LLaMA-2. Equally, MM-ReAct benefits significantly from leveraging external tools for OCR and math tasks, showcasing how modular tool integration can remedy deficits in end-to-end trained LMMs.
Evaluation and Tooling
The LLM-based evaluation provides a nuanced assessment of model outputs that extend beyond simple correctness, incorporating qualitative measures of response coherence and relevance. GPT-4 serves as the benchmark evaluator, outperforming simpler methods such as keyword matching, while offering lower deviation from human evaluation.
Implications and Future Directions
This work highlights several theoretical and practical implications for the future development of LMMs. It underscores the importance of integrated capability development, going beyond isolated task performance. Models achieving high efficacy in MM-Vet tasks are poised to offer more generalized intelligence across an array of practical applications, from automated document processing to interactive AI-driven content creation.
The insights into multimodal system paradigms suggest that future developments could emphasize enhancing core vision-language integration within models or refining models with auxiliary tools to supplement native capabilities. There's a clear path forward to not only refine the architecture of LMMs but also to optimize training datasets that cover more diverse real-world scenarios.
Finally, as LMMs continue to evolve, there's a significant opportunity to enhance AI's generalist capabilities, improving its interaction in human-like contexts through refined multimodal understanding, potentially paving the way for more intricate and nuanced interactions in artificial intelligence systems.