- The paper introduces CaFlow, a framework that employs causal counterfactual regularization to disentangle true action scores from contextual confounders.
- It features Bidirectional Time-Conditioned Flow (BiT-Flow) for stable, cycle-consistent temporal refinement that enhances long-term video assessment.
- Experimental results demonstrate significant accuracy gains and error reductions across multiple benchmarks, confirming robustness to domain shifts.
CaFlow: Causal Counterfactual Flow for Robust Long-Term Action Quality Assessment
Introduction
Long-term Action Quality Assessment (AQA) is a salient problem in video understanding, aiming to regress fine-grained execution scores for extended actions, e.g., figure skating or complex gymnastics, under varying, context-rich environments. Existing state-of-the-art methods suffer from two key deficiencies: vulnerability to contextual confounders (such as background or camera viewpoint) entangling with target scores, and unstable temporal modeling due to unidirectional or shallow temporal refinement, resulting in degraded performance under domain shift and a lack of robustness. The CaFlow framework (2511.21653) addresses both problems via explicit counterfactual de-confounding and bidirectional time-conditioned flow refinement, resulting in significant advances in accuracy, error stability, and interpretability on multiple AQA benchmarks.
Causal Counterfactual Regularization (CCR)
The CCR module is architected to disentangle pure causal cues from confounding contextual features within input video representations, all in a self-supervised, mask-free manner. It achieves this via three mechanisms:
- Causal Structure Modeling: The pipeline represents each video as an initial feature sequence, separated into score-causal and score-confounding components. A Structural Causal Model (SCM) underpins this factorization, with causal and non-causal pathways explicitly parameterized (Figure 1).
- Causal Feature Separator (CFS): Guided by the “desired feature” (extracted with a transformer backbone), the CFS employs cross-attention, with per-clip attention weights sampled via the Gumbel-Softmax. The soft mask induces a differentiable partition of the sequence into causal and confounding subsets, without manual annotation effort.
- Counterfactual Intervention and Triplet Loss: Counterfactual samples are synthesized in the feature space by swapping causal/confounding segments across batch samples. The CCR loss enforces that confounder-swapped samples result in similar score predictions (invariance to context), while causal swaps induce large predictive distances. This triplet-style loss ensures that the learned representation focuses exclusively on causal information.
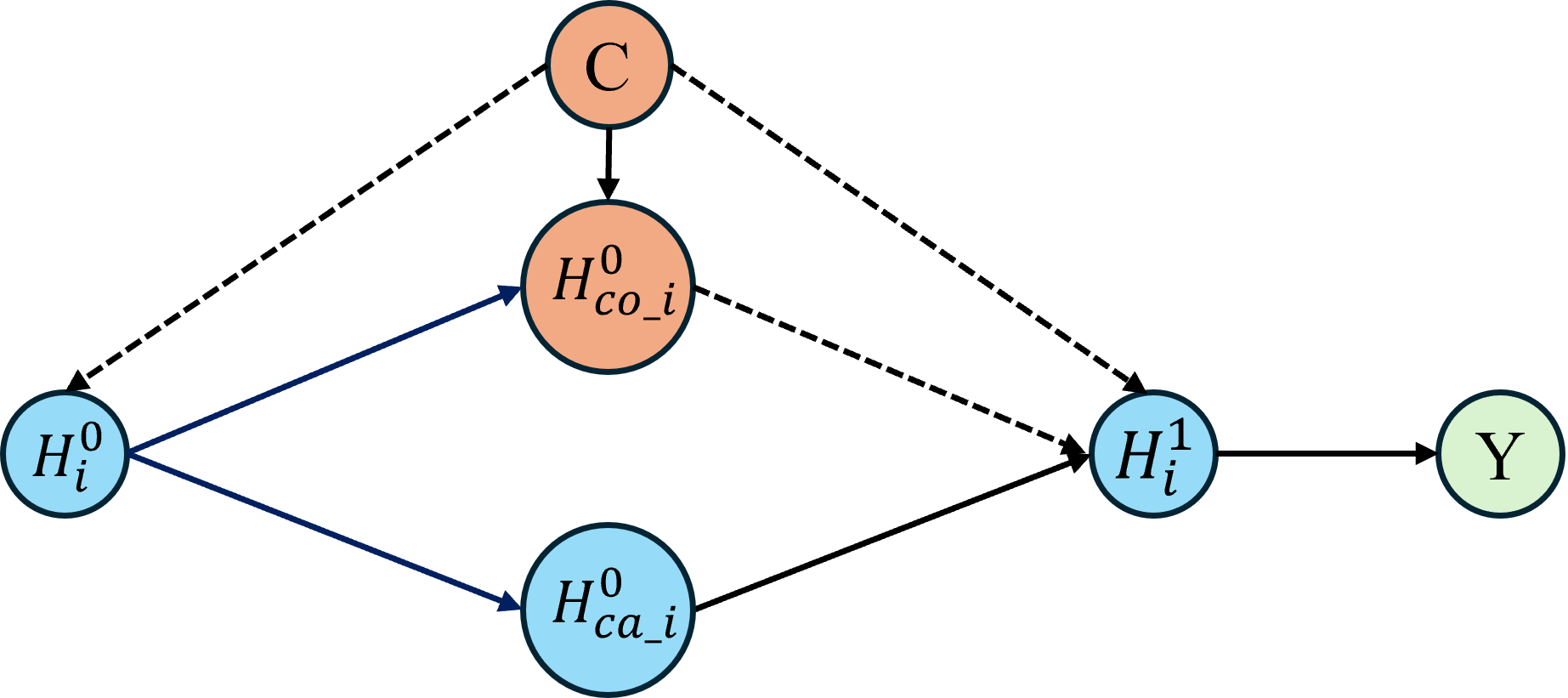
Figure 1: The SCM for CaFlow delineates direct (solid) and spurious (dashed) influences among features, confounders, and AQA scores, with front-door intervention blocking non-causal paths.
This design ensures robust performance under domain shift, without reliance on fragile external mask annotation pipelines as in prior AQA methods.
Bidirectional Time-Conditioned Flow (BiT-Flow)
The BiT-Flow module extends representation refinement via continuous-time, bidirectional flow matching – moving beyond the instability and error accumulation of unidirectional methods (e.g., PHI [zhou2025phi]). The design is motivated by the Schrödinger Bridge problem, enforcing matching of initial and final feature distributions via cycle-consistent forward and backward temporal flows.
- Time Conditioning: Time embeddings are injected at each refinement step, producing temporally modulated representations sensitive both to current context and progression.
- Bidirectional Update: Two flow predictors run forward and backward, their outputs linearly blended to enforce a symmetrical, time-consistent trajectory through representation space.
- Cycle Consistency: An explicit regularizer penalizes mismatch between forward and backward refinement paths, enforcing that refinement is smooth, invertible, and robust to misalignment.
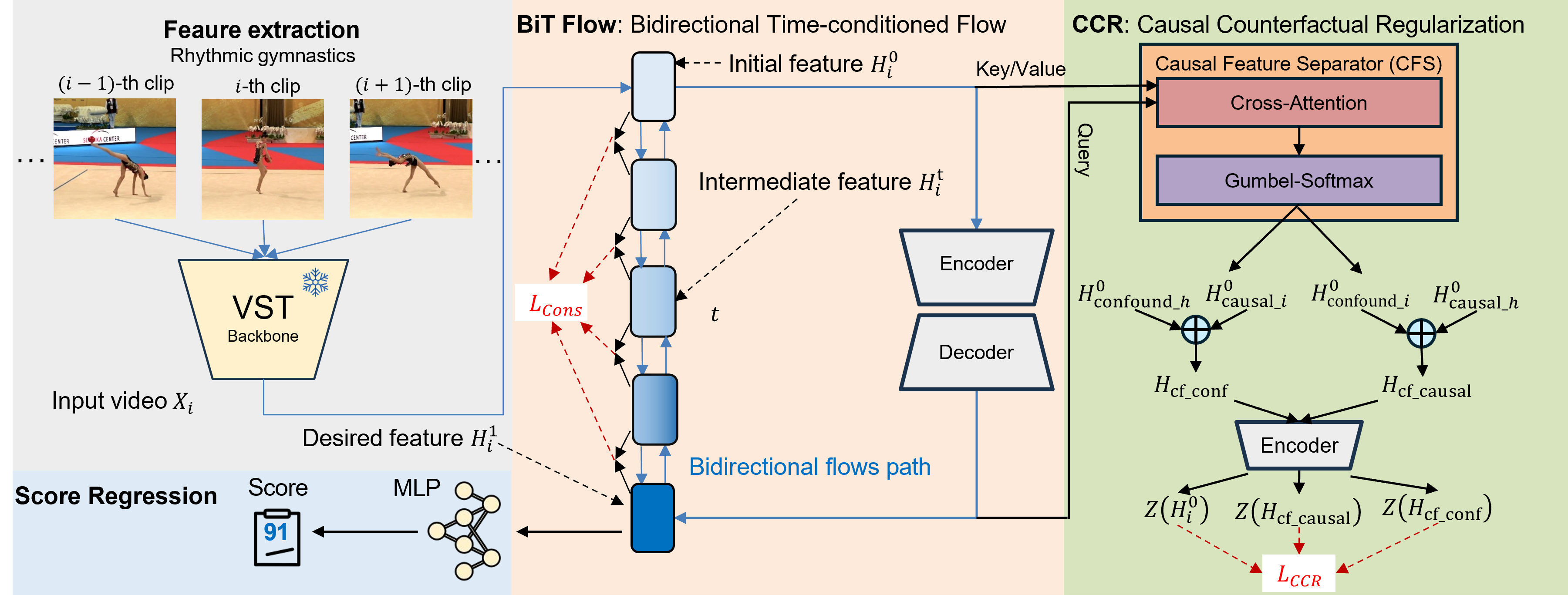
Figure 2: CaFlow integrates Causal Counterfactual Regularization (CCR) and Bidirectional Time-conditioned Flow (BiT-Flow), with the final score regressed from fully deconfounded, temporally refined representations.
This approach yields temporally coherent, less noisy feature trajectories, critical for accurate long-term action quality regression over multi-minute sequences.
Experimental Results
CaFlow achieves new state-of-the-art results on all long-term AQA benchmarks considered, including RG (rhythmic gymnastics), FIS-V (figure skating), and LOGO (longest-form group action). Notably:
- RG: Average SRCC 0.841 (↑3–5.5% over PHI, the previous best), with up to 40% reduction in relative ℓ2 error versus single-directional or confounder-aware baselines.
- FIS-V: Average SRCC 0.805, minuscule gain over PHI yet with tangible error reduction (↓5.9% in average R).
- LOGO: Average SRCC 0.856, boosting correlation while slashing error by ~48% compared to the strongest previous method.
Ablation studies confirm the necessity of both modules: CCR alone improves correlation and error, particularly under confounding shift; BiT-Flow further stabilizes error and aligns representations; their joint action is strictly additive.
Error and Qualitative Analysis
Boxplots and cumulative accuracy curves on RG highlight substantial reductions in median and mean absolute error, standard deviation, and improved area under the curve, indicating not only higher median accuracy but also far fewer outliers and lower dispersion (Figure 3).
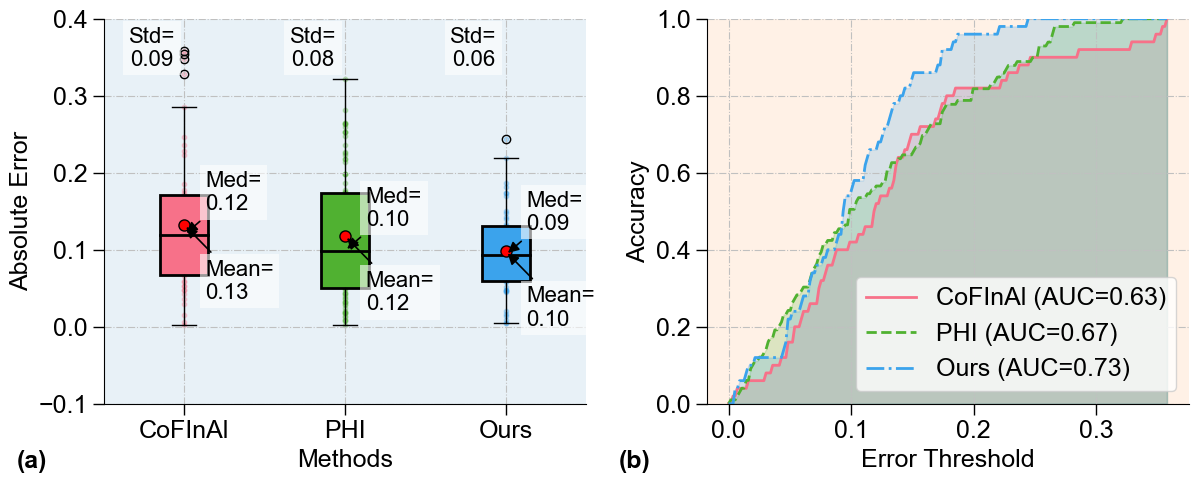
Figure 3: Boxplots and AUC curves demonstrate reduced error magnitude and variance for CaFlow relative to baselines, especially at stringent error thresholds.
Case studies on LOGO and RG reveal better generalization in challenging, confounder-rich routines and lower bias, with only rare failures in highly ambiguous edge-cases (Figure 4).

Figure 4: Examples from RG showing CaFlow consistently predicts closer to ground-truth scores than baseline systems under confounded and complex routines.
Practical and Theoretical Implications
The explicit use of counterfactual feature synthesis for self-supervised de-confounding in AQA establishes a scalable recipe for learning causal representations in absence of manual annotation. This is immediately applicable in any domain with context-sensitive scoring protocols, e.g., medical rehabilitation, skill assessment in education, or even other video analytics settings. Bidirectional flow matching, adapted here for sequential video analysis, provides a route for stable, error-resilient temporal refinement – suggesting further applicability in other long-horizon, non-stationary signal modeling tasks.
The approach aligns with the broader trajectory of integrating causal inference techniques (front-door intervention, counterfactual reasoning) directly into self-supervised deep video architectures, moving towards representations that are both robust and, crucially, interpretable. Future directions will likely include: more lightweight or structured flow modules, adaptive regularization schemes to further reduce computational overhead, and transfer of CaFlow principles to other complex sequence evaluation domains, including multi-agent settings and semi-supervised learning regimes.
Conclusion
CaFlow (2511.21653) presents a unifying, interpretable, and robust framework for long-term AQA, achieving substantial gains in both accuracy and stability by explicitly factoring and regularizing away context-driven confounding via counterfactual intervention, while ensuring temporally consistent modeling through bidirectional ODE-based flows. The framework offers general strategies for causal, robust video understanding with significant implications for future scalable AI assessment systems.