- The paper introduces ReSAM, a self-prompting segmentation framework that refines point-supervised masks in remote sensing imagery.
- It employs a recursive Refine–Requery–Reinforce loop to progressively improve mask quality and mitigate annotation challenges.
- Experimental results show significant performance gains over baseline methods, demonstrating effective domain adaptation.
Self-Prompting Point-Supervised Segmentation for Remote Sensing: The ReSAM Framework
Introduction and Motivation
Remote sensing imagery (RSI) segmentation remains encumbered by high annotation cost and pronounced domain shift, stalling the adoption of foundation segmentation models like SAM in practical geospatial intelligence applications. Dense mask supervision is prohibitively expensive for high-resolution satellite images containing a plethora of intricate objects, while point-level annotation offers a cheaper but weak supervisory signal that typically fails to deliver fine-grained segmentation. Existing adaptation approaches for SAM in RSI scenarios struggle especially with spatial ambiguity and mask fragmentation due to prompt sparsity and inadequate semantic alignment, leading to pixel leakage and inconsistent object delineation.
ReSAM Methodology
ReSAM is introduced as a point-supervised, self-prompting adaptation pipeline, designed to both leverage and transcend sparse point annotation. Unlike vanilla SAM, which is constrained by manual prompting and limited adaptation capacities, ReSAM employs a recursive Refine–Requery–Reinforce (R³) loop to progressively enhance the quality of pseudo-labels, thereby reducing reliance on dense supervision and mitigating confirmation bias. This loop is comprised of three core stages:
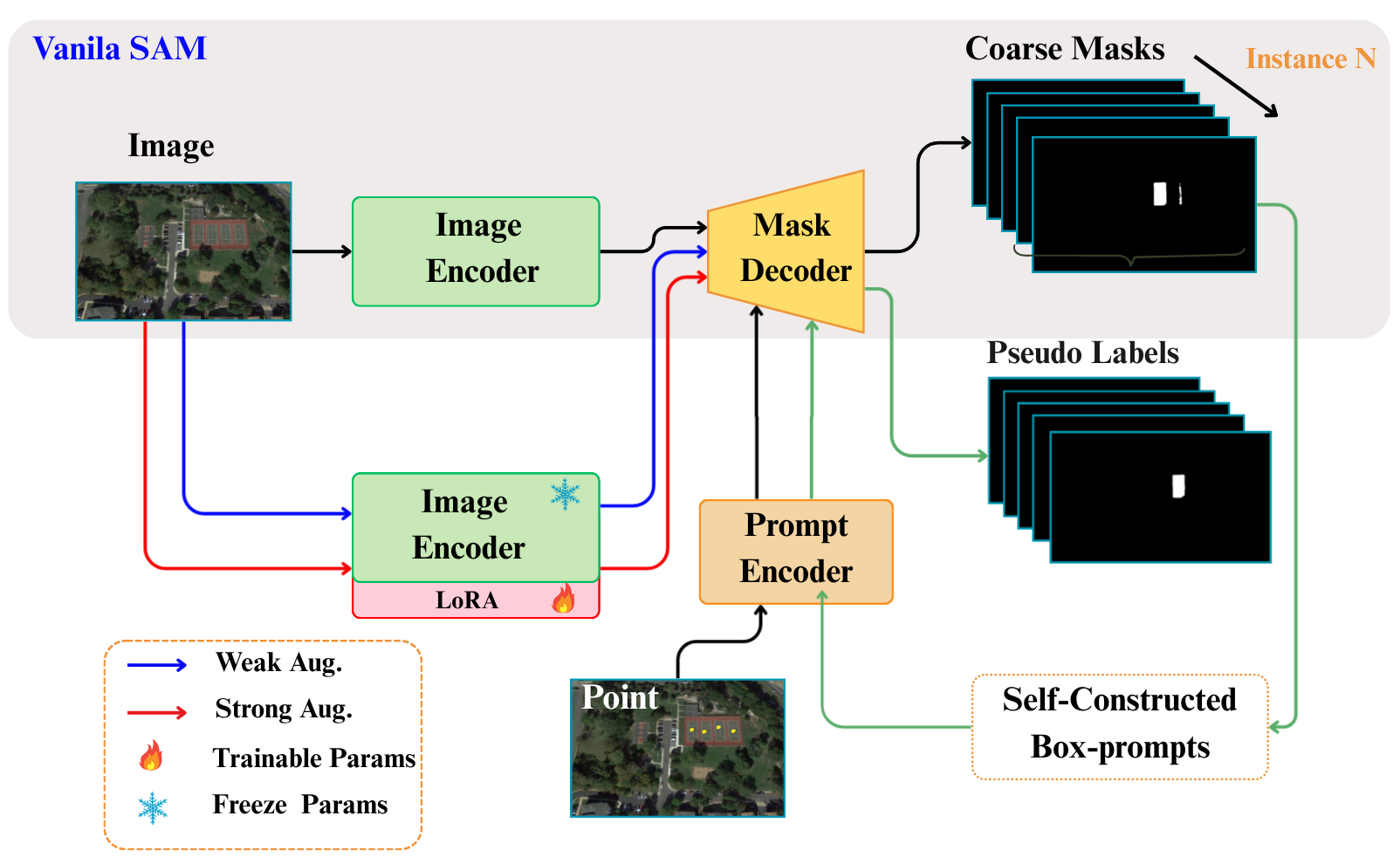
Figure 1: While Vanilla SAM depends on manual prompts (point and box), ReSAM introduces a self-prompting Refine–Requery–Reinforce (R³) loop that progressively refines coarse masks into prompted boxes and generates corresponding pseudo labels, enabling robust point-level adaptation without dense supervision.
1. Refine Stage
Initial segmentation masks are generated from sparse point prompts using the pretrained SAM. To address ambiguity, overlap analysis is conducted and ambiguous pixels—those predicted to belong to multiple objects—are suppressed based on coarse entropy thresholding and instance overlap elimination. This ensures region-specific, high-confidence initial pseudo-masks.

Figure 2: Visualization of overlap regions where pixel leakage occurs across each instance; inference on SAM model.
2. Requery Stage
Automatic box prompts are derived from the refined instance regions by computing minimal bounding boxes for confident mask segments. These box prompts, being spatially more informative, are then used to re-query SAM, thereby yielding higher-quality masks with improved boundary adherence and reduced spatial ambiguity. This self-prompting mechanism recursively refines pseudo-labels using progressively structured spatial priors.
3. Reinforce Stage
To stabilize learning and avoid confirmation bias during pseudo-label propagation, ReSAM introduces Soft Semantic Alignment (SSA). Here, instance-level embeddings are accumulated in a compact rolling queue across subsequent training steps. SSA then enforces semantic consistency by minimizing cosine dissimilarity between embeddings of similar instances across views, regulated via temperature-scaled similarity weighting. This approach elegantly circumvents the memory overhead associated with explicit prototype clustering while robustly regularizing feature drift.
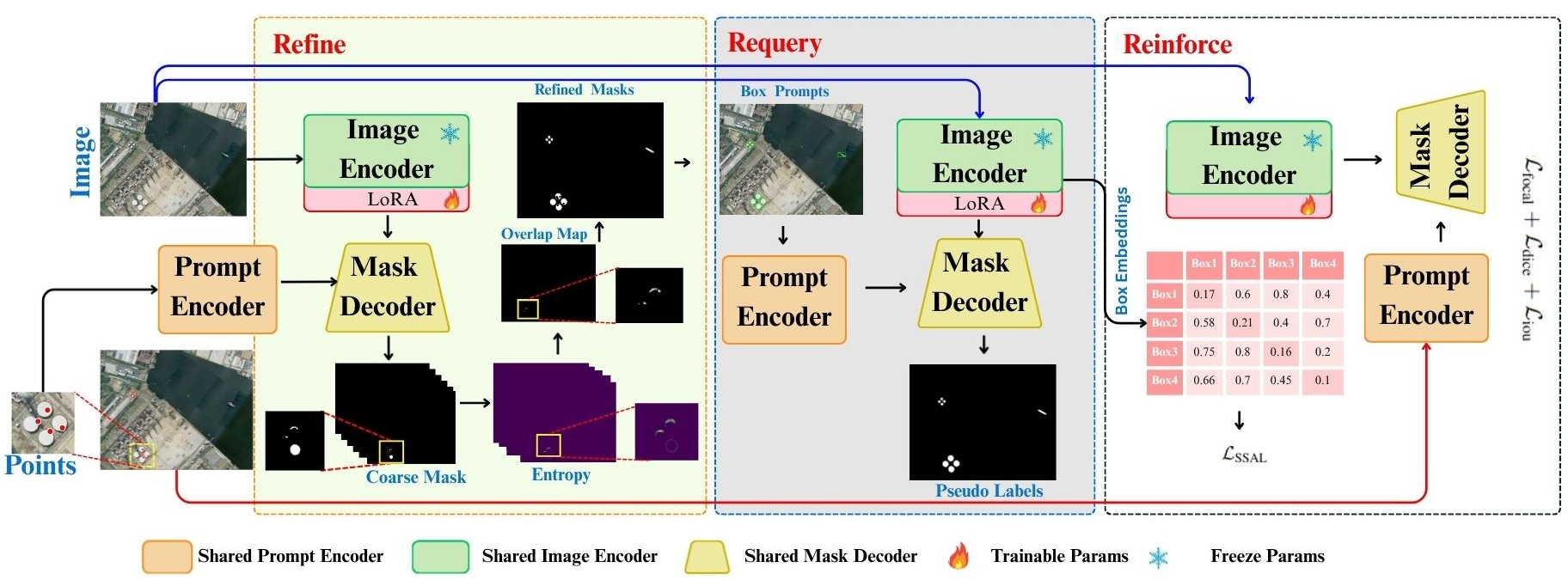
Figure 3: Overview of ReSAM. Weak and strong views generate pseudo masks and self-prompts to iteratively refine SAM outputs. The pipeline includes Refine (clean instance masks), Requery (self-prompting), and Reinforce (Soft Semantic Alignment) with LoRA adaptation for domain-specific learning.
For all stages, only LoRA parameters in the SAM encoder are fine-tuned, further improving domain adaptation efficiency and preserving low memory and computational footprints.
Experimental Results
ReSAM is quantitatively evaluated on three RSI benchmarks: NWPU VHR-10, HRSID-Inshore, and WHU. Only point annotations (1–3 points per instance) are provided—no dense or box annotations are supplied during training. Empirical results demonstrate that ReSAM consistently surpasses vanilla SAM, domain-adapted variants, and recent point-supervised methods (e.g., PointSAM, WeSAM), for both mIoU and F1 metrics.
Notably, on NWPU VHR-10, ReSAM achieves up to +2.0 IoU and +1.8 F1 improvement over PointSAM. On WHU, gains are particularly marked under 2-point prompting, with mIoU exceeding 77%, narrowing the gap to fully supervised finetuned baselines to within 12 points. On HRSID-Inshore, ReSAM shows greater robustness in cluttered scenes compared to direct test and self-training baselines.

Figure 4: Qualitative results on the NWPU, WHU and HRSID remote sensing dataset. The column from left to right shows the input image with points, full labeled ground truth, direct test on SAM and with baseline methods. Our proposed method ReSAM demonstrates boundary accuracy and continuity compared to baselines, especially in complex and detailed regions.
Ablation Studies
Component analysis isolates contributions from the requery mechanism, SSA, and LoRA adaptation. Removing the SSA or requery loop leads to notable degradation in mIoU, confirming that semantic alignment is crucial for maintaining instance consistency, while spatial requerying is vital for mask precision. The incremental benefit of LoRA-based fine-tuning over other adapters is likewise established.
Performance tracking across initial training epochs reveals that SSA not only improves convergence speed but yields a consistently higher mIoU, particularly in datasets with more severe domain shift (e.g., HRSID), underscoring its efficacy for stabilizing weak self-training pipelines.
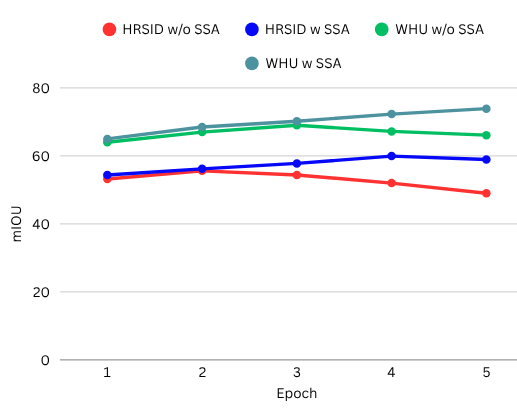
Figure 5: Ablation results of the proposed Soft Semantic Alignment (SSA) module on HRSID and WHU. SSA consistently improves mIoU across epochs, showing better feature alignment and more stable performance compared to the w/o SSA.
Implications and Future Directions
ReSAM demonstrates that prompt engineering, when embedded within a robust, self-correcting adaptation framework, can close much of the performance gap between point-level and dense annotation supervision in segmentation foundation models. This approach substantially reduces annotation burden for RSI and likely generalizes to other domains characterized by high object density and annotation scarcity, e.g., biomedical imagery or industrial inspection.
The incorporation of queue-based SSA suggests promising avenues for future weakly supervised adaptation: utilizing memory-efficient feature alignment as a substitute for costly prototype clustering, and combining recursive pseudo-label refinement with principled regularization. Moreover, future research could investigate the explicit modeling of uncertainty to further improve pseudo-label reliability, or the dynamic weighting of self-prompts in scenes of heterogeneous object scale and density. Application to time-series imagery or multispectral domains also appears straightforward given the model's prompt-centric design.
Conclusion
ReSAM establishes a highly effective framework for adapting segmentation foundation models like SAM to remote sensing imagery under severe annotation constraints. By tightly integrating self-prompting refinement, region-centric requerying, and lightweight semantic alignment, ReSAM achieves substantial improvements over current state-of-the-art weakly supervised methods, reducing pixel ambiguity, boundary errors, and domain drift. The proposed paradigm simultaneously advances practical annotation efficiency and offers a blueprint for scalable, domain-robust adaptation across vision tasks characterized by annotation scarcity and dense object composition.